](https://deep-paper.org/en/paper/2410.24218/images/cover.png)
引言
想象一下,你正在教朋友做一道复杂的菜。如果他们犯了错,你不会仅仅给他们一个“大拇指向下”的手势或者一个冷冰冰的分数。你也不会把自己局限于像“拿起勺子”这样机械的指令。相反,你可能会说: “你刚才盐放多了,所以应该多加点土豆来中和一下。”
这种包含对过去的批评 (事后反馈) 和对未来的指导 (前瞻指导) 的丰富交流形式,对人类来说是很自然的。然而,在强化学习 (RL) 的世界里,具身智能体 (如机器人或虚拟化身) 通常接受的是更为粗糙的信号训练。它们通常只接收稀疏的数值奖励或非常简单、重复的指令。
最近一篇题为 “Teaching Embodied Reinforcement Learning Agents: Informativeness and Diversity of Language Use” 的研究论文解决了这一差异。研究人员提出了一个引人入胜的问题: 我们能否通过让语言输入更具信息量和多样性,来提高智能体的学习和泛化能力?
本文将探讨作者如何将人类语言的丰富性整合到使用决策 Transformer (Decision Transformers) 的离线强化学习中,证明了当 AI 智能体被以多样化和详细的反馈“教导”时,它们不仅仅是在死记硬背任务——它们开始真正地理解任务。
背景: 简单指令的局限性
要理解这篇论文的贡献,我们需要先看看强化学习中语言应用的现状。
传统上,RL 智能体通过试错来学习,由奖励函数 (例如,赢了 +1,输了 -1) 引导。虽然有效,但这很慢。最近的方法引入了语言作为一种“塑造”行为的方式。然而,现有方法通常依赖于:
- 低信息量指令: 简单的命令,如“向北走”或“开门”。
- 低多样性表达: 句子结构从不改变的僵化模板。
现实环境是开放的。家里的机器人可能会遇到同一请求的数千种变体。如果它只知道“把苹果放在桌子上”,当被要求“把水果移到用餐区”时,它可能会失败。
研究人员提出,为了构建鲁棒的智能体,我们需要利用自然语言的两个关键属性: 信息量 (Informativeness) (提供关于过去错误和未来目标的上下文) 和多样性 (Diversity) (使用不同的词汇和句式) 。
实验环境
为了验证这一假设,作者使用了四种截然不同的具身 AI 环境,从网格世界到机器人操作:
- HomeGrid: 一个家庭模拟环境,智能体在其中寻找物体、清理和重新排列物品。
- ALFWorld: 一个与家务任务 (如加热鸡蛋) 对齐的基于文本的游戏。
- Messenger: 一个需要智能体在避开敌人的同时传递信息的游戏。
- MetaWorld: 一个执行组装和工具使用任务的机械臂模拟。
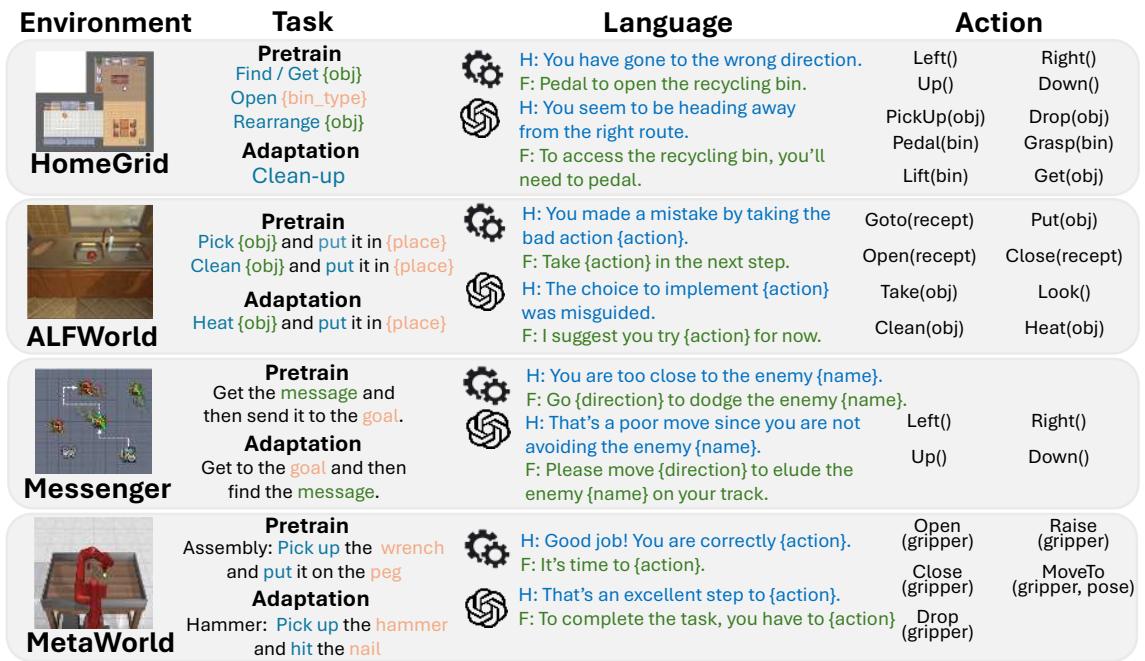
如上图 1 所示,每个环境都提出了独特的挑战,但它们都有一个共同的需求: 智能体必须将视觉或文本状态映射到动作以实现目标。
核心方法: 语言教学框架
这项工作的核心贡献是一个生成丰富语言数据的流程,以及一个能够摄取这些数据的模型架构。让我们分解一下研究人员是如何教导他们的智能体的。
1. 定义信息量: 事后反馈与前瞻指导
研究人员将“有帮助的语言”分为两类:
- 事后反馈 (Hindsight Feedback) : 向后看。它批评智能体刚才做的事情。
- *例子: * “你离敌人太近了。”
- 好处: * 它可以帮助智能体理解为什么*之前的动作不是最优的。
- 前瞻指导 (Foresight Feedback) : 向前看。它指导智能体接下来做什么。
- *例子: * “你应该向右走以靠近目标。”
- *好处: * 它缩小了下一个正确动作的搜索空间。
假设是: 结合两者 (事后 + 前瞻) 能提供最有力的学习信号。
2. 实现多样性: GPT 增强池
使用模板 (例如,“向 [方向] 走”) 很容易实现,但会导致智能体变得脆弱,一旦措辞稍有变化就会失败。为了解决这个问题,作者利用 GPT-4 来扩展他们的数据集。
他们从手工设计的事后和前瞻模板开始。然后,将这些模板输入 GPT-4,生成数十种语义相同但表达不同的变体。例如,“你做得很好”可能会变成“目前为止一切顺利,你太棒了!”或“进展极佳”。
这创建了一个 GPT 增强语言池 (GPT-Augmented Language Pool) , 确保智能体不会多次看到完全相同的句式,迫使它学习含义而不是死记语法。
3. 数据生成流程
由于这是一种离线强化学习 (Offline RL) 方法 (从预先收集的数据集学习,而不是实时交互) ,研究人员需要生成一个包含轨迹 (状态和动作序列) 及丰富语言配对的训练数据集。
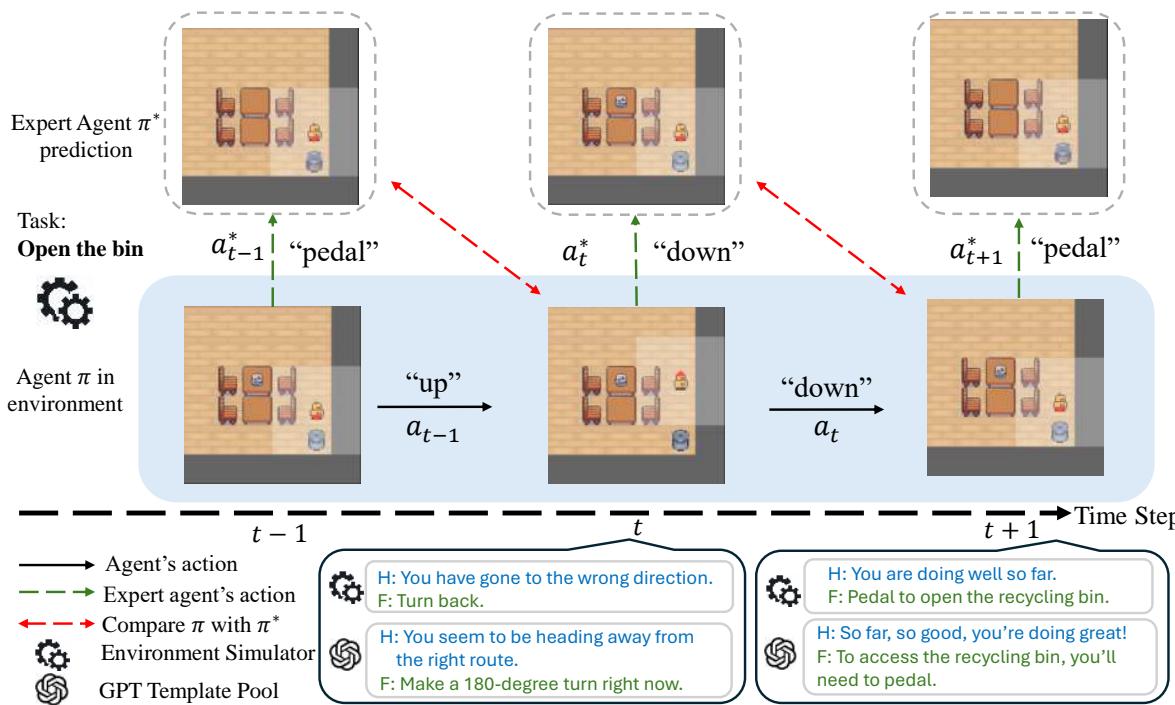
图 2 展示了生成过程:
- 智能体: 两个智能体正在运行。一个非专家智能体 (学生) 执行任务,但由于注入了噪声会犯错。一个专家智能体 (老师) 在后台运行,知道最优的移动方式。
- 比较: 在每一步,系统都会将学生的动作与专家的动作进行比较。
- 反馈:
- 如果学生在 \(t-1\) 步偏离了专家,则生成事后反馈 (例如,“你走错了路”) 。
- 根据专家在 \(t\) 步会做什么,生成前瞻指导 (例如,“现在向左转”) 。
- 多样性: 这些原始信号会被替换为来自 GPT 增强池的随机变体。
4. 架构: 语言可教学决策 Transformer (LTDT)
为了处理这些数据,作者扩展了 决策 Transformer (Decision Transformer, DT) 。
标准的 RL 方法 (如 Q-Learning) 估计动作的价值。而决策 Transformer 将 RL 视为一个序列建模问题——类似于大语言模型 (LLM) 预测下一个单词。它获取过去的序列状态、动作和奖励,并预测下一个动作。
研究人员引入了 语言可教学决策 Transformer (LTDT) 。 如图 3 所示,他们增强了输入序列,在每个时间步都包含了语言反馈标记 (\(l_t\)) 。
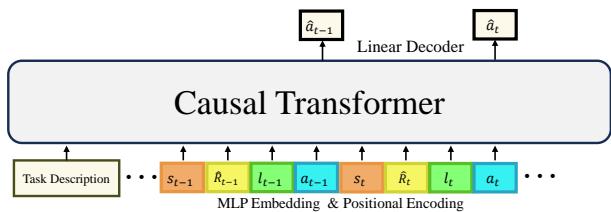
模型接收如下序列:
[任务描述] -> (状态, 奖励, 语言, 动作) -> (状态, 奖励, 语言, 动作)...
Transformer 会同时关注语言反馈的历史记录和物理状态,以决定下一步行动。这使得智能体能够根据“老师”的评论修正其路线。
实验与结果
研究人员进行了广泛的实验来回答两个主要问题:
- 丰富的语言能否提高已知任务的表现?
- 它能帮助智能体适应新的、未见过的任务吗?
结果 1: 更丰富的语言 = 更好的表现
第一组实验比较了使用不同语言质量训练的智能体。
- 无语言 (No Language): 基线。
- 模板事后 / 前瞻 (Template Hindsight / Foresight): 简单、重复的反馈。
- 模板事后+前瞻 (Template H+F): 两种类型结合。
- GPT 增强事后+前瞻 (GPT-Augmented H+F): 具有高多样性的提议方法。

图 4 的结果令人震惊。在每个环境中,加入语言都有帮助。然而, GPT 增强事后 + 前瞻 (紫色柱状图) 始终获得最高的奖励。
这证明了两件事:
- 信息量很重要: 结合反思 (事后) 和指导 (前瞻) 比单独使用任何一种都好。
- 多样性至关重要: “模板”智能体 (黄色和蓝色柱状图) 经常遇到瓶颈。GPT 增强的智能体学到了更鲁棒的策略,因为它们被迫理解各种语言模式。
结果 2: 更快地适应新任务
AI 的一个主要目标是泛化 。 一个被训练去“捡苹果”的智能体能快速学会“清洗碗”吗?
研究人员在一组任务上预训练智能体,然后使用“少样本适应 (few-shot adaptation) ” (允许智能体仅仅尝试新任务几次) 在未见过的任务上测试它们。

图 5 显示了适应曲线。 紫色柱状图 (GPT 增强 H+F) 明显更高,即使只有 5 次或 10 次“尝试 (shots) ”。这表明,用丰富的语言训练赋予了智能体一种“元学习”能力。它学会了如何倾听并根据反馈调整行为,这种技能可以迁移到完全新的问题上。
洞察: 语言何时最有用?
语言在每种情况下都有帮助吗?研究人员绘制了“效率增益 (Efficiency Gain) ” (语言提供了多少帮助) 与“任务难度 (Task Difficulty) ”的关系图。
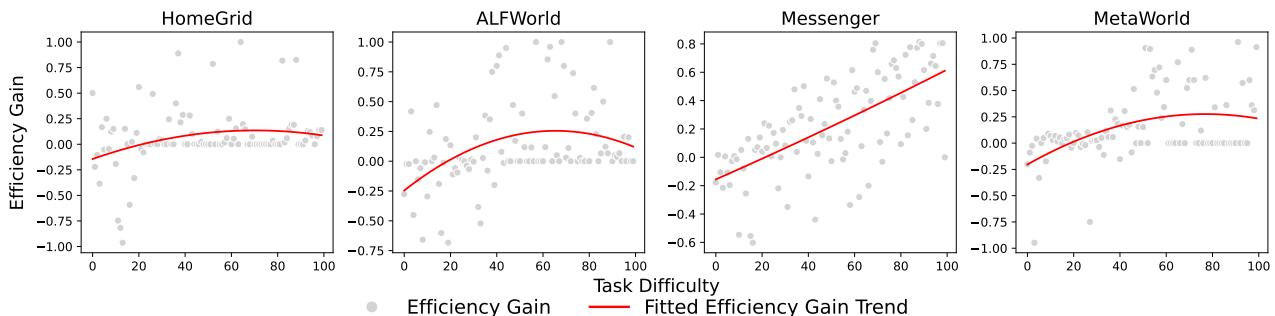
如图 6 所示,存在一个“适中区域”。
- 太简单: 如果任务微不足道,智能体不需要帮助也能轻松解决;语言反而增加了负担。
- 太难: 如果任务极其复杂,无论有无反馈,智能体都会失败。
- 适中: 在中间地带,语言提供了有效解决问题所需的关键推动力。
鲁棒性: 如果老师消失了怎么办?
关于“可教学”智能体的一个担忧是依赖性。如果人类停止说话,智能体是否会变得无助?
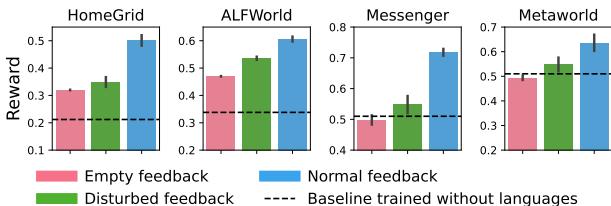
图 8 提供了一个令人欣慰的答案。研究人员在“无语言”设置 (粉色柱状图) 下测试了智能体,即在测试期间切断反馈。
- 令人惊讶的是,经过语言训练的智能体仍然表现良好,经常达到或超过基线。这表明它们在训练过程中内化了任务动态——它们学会了技能,而不仅仅是如何听从命令。
- 即使给予“受干扰 (Disturbed) ” (不正确或垃圾) 反馈 (绿色柱状图) ,它们也保持了不错的表现,表明它们对糟糕的输入并不脆弱。
结论与启示
论文 “Teaching Embodied Reinforcement Learning Agents” 为自然语言处理 (NLP) 与机器人技术的结合提供了有力的论据。它让我们不再将语言仅仅视为静态标签或触发命令。相反,它将语言构建为一种动态的塑造信号——一种将人类直觉转移给机器的方式。
主要收获:
- 上下文为王: 告诉智能体它做错了什么 (事后反馈) 与告诉它接下来该做什么 (前瞻指导) 同样重要。
- 多样性防止过拟合: 使用多样化的、GPT 生成的措辞进行训练,可以防止智能体死记硬背特定的命令,从而产生稳健的理解。
- 学会学习: 以这种方式训练的智能体不仅掌握了特定任务;它们还掌握了利用反馈的艺术,使它们能够适应新的挑战。
随着我们迈向通用家庭机器人和助手的未来,这项研究强调,更智能 AI 的关键可能不仅仅是更好的算法,还在于人类教师与数字学生之间更好、更丰富的沟通。