](https://deep-paper.org/en/paper/2411.00623/images/cover.png)
想象一下,你教一个聪明的学生一门新课程,却发现他们把上周学的内容全都忘了。这种令人沮丧的现象被称为灾难性遗忘 (catastrophic forgetting) ,是人工智能领域最大的挑战之一。当我们部署像视觉 Transformer (ViT) 这样强大的模型时,我们希望它们能不断从新数据中学习,掌握新任务,而不需要从头进行耗时且昂贵的重新训练。这正是持续学习 (Continual Learning, CL) 的核心目标。
传统的持续学习方法通常依赖于重放旧数据,但由于存储、隐私或合规性限制,这并非总是可行。近期的策略转向了参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT) , 这是一种通过调整少量参数来适配大型模型的技术。在这些方法中, 低秩自适应 (Low-Rank Adaptation, LoRA) 表现尤为突出。然而,直接将 LoRA 应用于持续学习面临挑战——往往导致训练变慢,并且对旧知识的保持效果不佳。
最近的一篇论文《Replay-Free Continual Low-Rank Adaptation with Dynamic Memory》提出了一种名为 DualLoRA 的方法,使 ViT 能够高效且有效地学习一系列任务,显著减少灾难性遗忘。该方法通过巧妙的双适配器架构和一个能够在推理阶段智能调整模型的动态内存系统来实现这一目标。
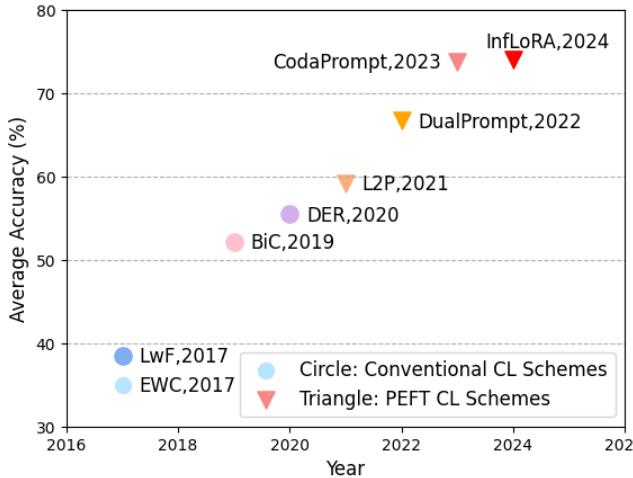
图 1. 过去十年间,基于 PEFT 的持续学习方法不断提升性能,DualLoRA 成为新的 SOTA (state-of-the-art) 。
背景: 稳定性–可塑性困境
持续学习的核心是一个被称为稳定性–可塑性困境 (stability–plasticity dilemma) 的基本权衡:
- 稳定性: 模型必须保留从先前任务中学到的知识。
- 可塑性: 模型必须保持足够的灵活性来学习新任务。
偏向任意一方都会破坏平衡——过于稳定的模型无法适应新任务,而过于可塑的模型则容易遗忘旧知识。挑战在于保持两者的平衡。
低秩自适应 (LoRA)
LoRA 通过冻结庞大的预训练权重 \( \mathbf{W}_0 \),并在每一层注入小型、可训练的“适配器”矩阵来高效微调模型。具体来说:
\[ \mathbf{W} := \mathbf{W}_0 + \mathbf{B}\mathbf{A} \]这里,\(\mathbf{B}\) 和 \(\mathbf{A}\) 是低秩矩阵,由于秩 \(r \ll d\),仅训练少量参数子集,使得 LoRA 相比完全微调更加轻量。
梯度投影: 无干扰地学习
为了保护旧知识,一些持续学习方法采用梯度投影技术。该技术会识别出对先前任务至关重要的“重要方向” (子空间) ,并将新任务的梯度约束为与这些方向正交。也就是说,模型仅在不会干扰已学知识的方向上进行学习。
虽然这种方法行之有效,但在高维 ViT 上应用时计算量很大。跨层计算和管理这些子空间变得难以处理。DualLoRA 的创新优雅地解决了这一效率瓶颈。
核心方法: DualLoRA 内部机制
DualLoRA 采用双适配器设计以协调稳定性与可塑性。ViT 的每一层都包含两个并行适配器: 用于保留旧知识的正交适配器和用于获取新知识的残差适配器 。 它们通过动态内存机制进行协作,实现了无需数据回放的自适应推理。
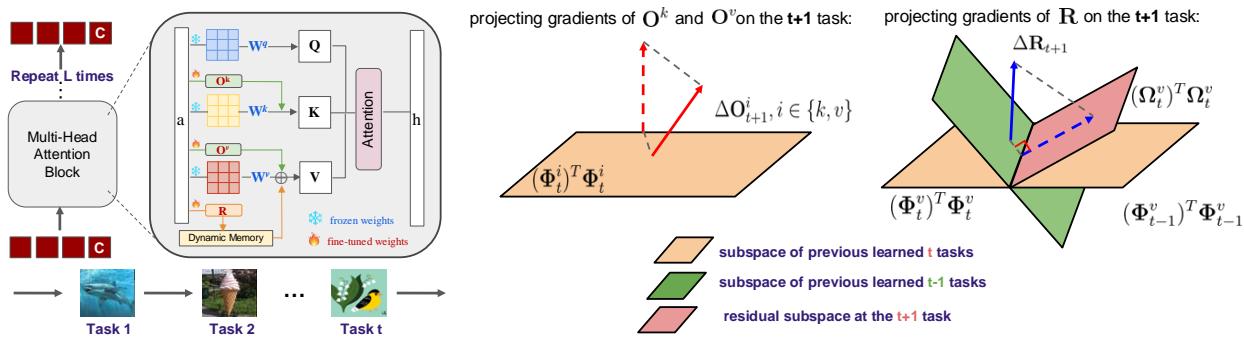
图 2. DualLoRA 框架概览。正交适配器保留已有知识,而残差适配器捕获新任务知识。
1. 正交适配器 (O) : 旧知识的守护者
正交适配器通过限制更新方向,使其不与已学任务干扰,从而保证稳定性。与如 InfLoRA 等需要在梯度空间进行投影且代价高昂的双重前向传播方法不同,DualLoRA 在特征空间中进行高效操作。
关键洞察是 ViT 的分类主要依赖于类别令牌 (class token) ——第一个嵌入表示。DualLoRA 专注于保留该令牌的行为。它通过从先前任务中取样少量数据点,构建一个代表这些任务关键方向的特征基 \((\Phi_t)\)。
在学习新任务 \(t+1\) 时,对正交适配器的更新 \(\Delta \mathbf{O}_{t+1}\) 被投影至与这些基正交:
\[ \Delta \mathbf{O}_{t+1}^{i} \leftarrow \Delta \mathbf{O}_{t+1}^{i} - (\mathbf{\Phi}_{t}^{i})^{\top}\mathbf{\Phi}_{t}^{i}\Delta \mathbf{O}_{t+1}^{i}, \quad \forall i \in \{k, v\} \]这种投影可防止覆盖旧类别令牌特征,从而减少遗忘。由于仅处理降维后的子空间 (\(m \ll d\)),计算 \(\Phi_t\) 所需的 SVD 操作比以往更快且更节省内存。
2. 残差适配器 (R) : 新学习的引擎
仅靠正交约束可能会过度限制模型,使其难以适应。为恢复可塑性,DualLoRA 引入了残差适配器 , 用于捕捉新任务引入的新特征。
该残差子空间 (\(\Psi_t\)) 表示未在先前任务中出现的新学习方向:
\[ \Psi_t := \Phi_t^v - \Phi_{t-1}^v \]残差适配器的更新被投影到这个子空间:
\[ \Delta \mathbf{R}_{t+1} \leftarrow \boldsymbol{\Psi}_t^{\top}\boldsymbol{\Psi}_t \Delta \mathbf{R}_{t+1} \]这种策略保证模型在获得新任务学习能力的同时维持旧知识的完整。
3. 动态内存: 即时自适应
推理阶段,模型需在没有任务标签的情况下进行预测。若同时启用所有残差适配器会导致互相干扰。 动态内存 (Dynamic Memory, DM) 通过根据任务相关性加权每个残差适配器的输出来解决这一问题。
处理测试图像时:
- 模型计算激活向量 \(\mathbf{v}^{(l)}\);
- 计算该向量与每个任务残差基 \(\Psi_{\tau}\) 之间的余弦相似度:
这些相关性分数动态调整各残差适配器的输出。相关性高的适配器权重更大,不相关的则被抑制。这使得 DualLoRA 在推理时具备上下文感知能力且无干扰。
4. 带置信度的任务识别
DualLoRA 进一步通过引入任务识别与置信度校准扩展了动态内存机制。对于每个测试样本,模型比较其相似度向量 \(\boldsymbol{\pi}^{*}\) 与存储的任务原型 \(\boldsymbol{\pi}_{\tau}\),预测最相似的任务:
\[ \hat{k} = \arg\max_{\tau} g(\boldsymbol{\pi}_{\tau}, \boldsymbol{\pi}^{*}) \]然后基于最佳与次佳匹配间的分数差计算置信度边际 \(\hat{\delta}\),并用于增强预测输出:
\[ f_{\hat{k}}(\mathbf{h}^{(L)}) \leftarrow (1 + \hat{\delta}) \cdot f_{\hat{k}}(\mathbf{h}^{(L)}) \]这种简单而有效的校准在任务标签未知时提升了模型预测的可靠性。
实验与结果
研究者将 DualLoRA 和 DualLoRA+ 与领先的基于 PEFT 的持续学习方法——如 LoRA、L2P、DualPrompt、CodaPrompt 和 InfLoRA——在 ImageNet-R、CIFAR100 和 Tiny-ImageNet 数据集上进行了比较。性能指标包括:
- 平均准确率 (ACC) — 越高越好;
- 遗忘率 (FT) — 越低越好。
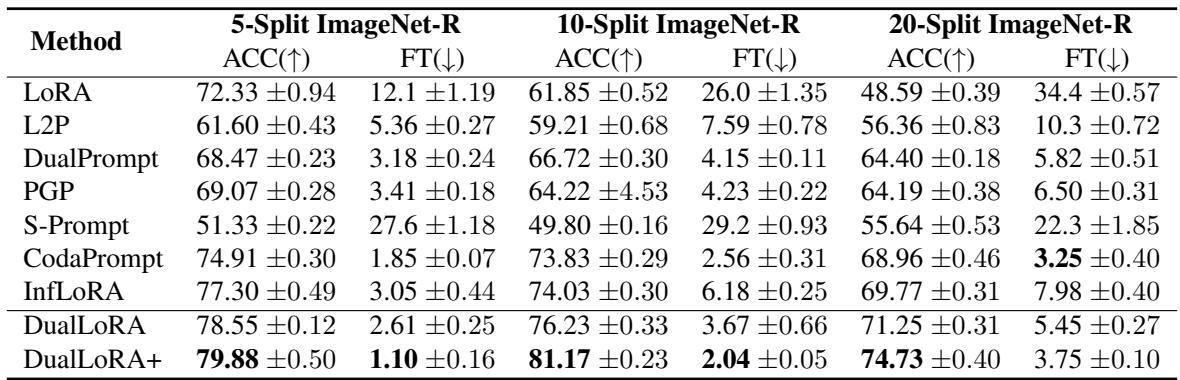
表 1. DualLoRA 在所有 ImageNet-R 任务划分上均取得顶级成绩,DualLoRA+ 变体更是树立了新的基准。
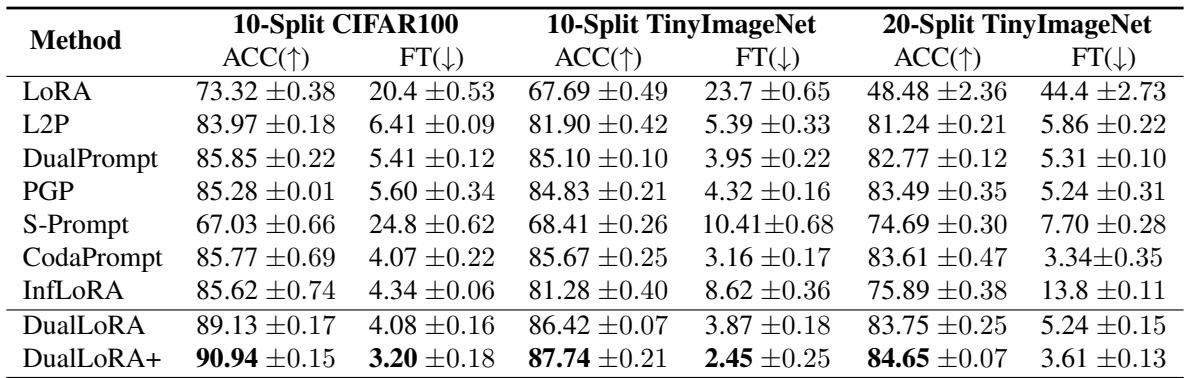
表 2. 在 CIFAR100 和 Tiny-ImageNet 上的一致性能提升验证了 DualLoRA 在不同数据集上的鲁棒性。
在所有基准测试中,DualLoRA 均处于最优秀行列。它在准确率上媲美或超越 InfLoRA,同时效率显著提升。加入增强任务识别模块的 DualLoRA+ 进一步拓展了性能上限。
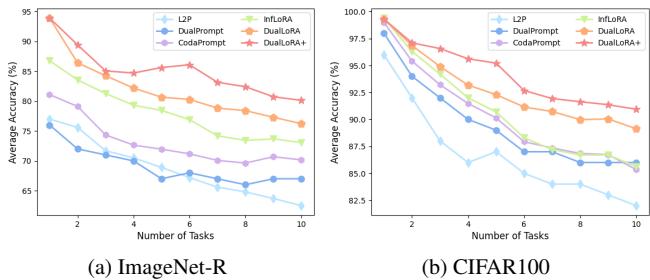
图 3. 随任务数量增加,DualLoRA+ 保持高准确率,展现出强大的抗遗忘能力。
为何有效: 消融研究洞察
为评估各组件贡献,作者进行了消融实验,逐步添加或移除 DualLoRA 的组成部分。
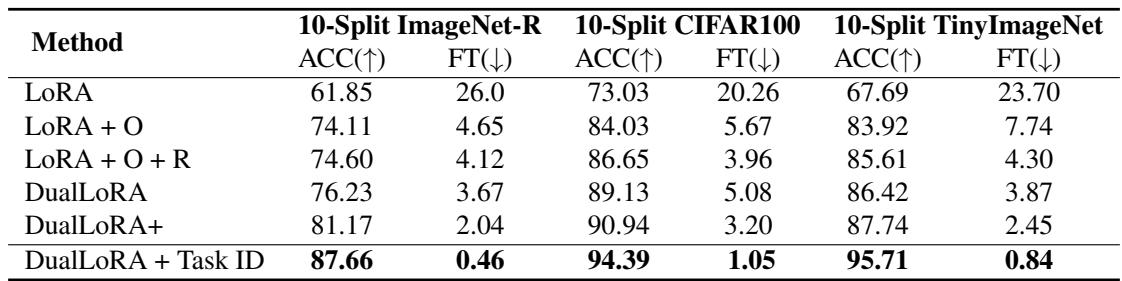
表 3. 各模块 (O 表示正交适配器,R 表示残差适配器,任务 ID 预测) 均带来显著提升,验证了设计的合理性。
研究结果表明:
- 仅使用原生 LoRA 会出现严重遗忘;
- 加入正交适配器显著增强稳定性;
- 加入残差适配器提升可塑性与准确率;
- 增添任务识别模块实现完整的 DualLoRA 效果,最大化性能与效率。
每一层设计都对最终成果发挥了实质作用。
效率: 更快的训练与推理
许多基于提示的持续学习方法由于需要双重前向传播,训练或推理时间加倍。InfLoRA 虽减少推理延迟,但训练成本仍高。DualLoRA 在两者间取得平衡——减少 FLOPs,并保持快速推理。
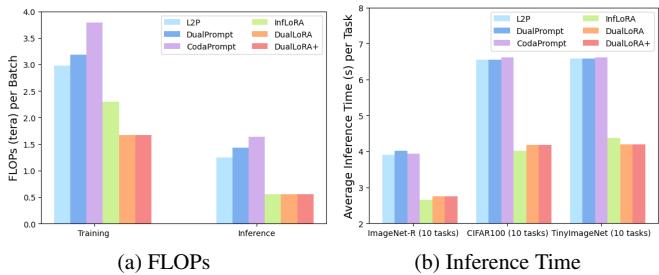
图 4. DualLoRA 实现最低训练 FLOPs 和出色的推理速度,优于慢速提示驱动方法。
它通过围绕类别令牌提取更小的子空间并去除冗余的双重传播来实现效率优化,使其既轻量又可扩展,适用于大型 ViT。
结论与启示
DualLoRA 是在无回放持续学习领域的一项重要突破。通过其优雅的双适配器设计和动态内存机制,它成功地平衡了稳定性与可塑性——这一挑战长期困扰着人工智能领域。
核心启示:
- 双适配器架构: 结合正交 (稳定性) 与残差 (可塑性) 适配器,实现高效、均衡的持续学习。
- 计算效率: 聚焦类别令牌子空间,避免昂贵的全模型投影,加速训练与推理。
- 动态内存与任务感知: 模型在推理时智能重用相关任务子空间,实现无任务标签情况下的精准预测。
DualLoRA 为大型视觉模型的高效、可扩展持续学习树立了新标杆——这是迈向能像人类一样持续学习而不遗忘过去的机器学习系统的鼓舞步伐。