](https://deep-paper.org/en/paper/2411.04118/images/cover.png)
人工智能与医学的交叉领域是目前技术界最令人兴奋的前沿之一。每隔几个月,我们就会看到新的头条新闻宣布某种“医疗 LLM”——一种专门为医疗保健量身定制的人工智能。故事几乎总是相同的: 拿一个强大的通用模型 (如 Llama 或 Mistral) ,在海量的医学教科书和 PubMed 文章库上对其进行进一步训练,然后瞧: 你就有了一个表现优于其通用前身的数字医生。
这个过程被称为领域自适应预训练 (Domain-Adaptive Pretraining,简称 DAPT) 。 从理论上讲,这完全说得通。如果你想让一个人成为医生,你会送他们去医学院,而不是仅仅依靠他们的高中教育。
然而,一篇题为 “Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?” (大语言和视觉-语言模型的医疗适配: 我们取得进展了吗?) 的重要新研究论文挑战了这一基本假设。来自卡内基梅隆大学、Mistral AI、约翰霍普金斯大学和 Abridge AI 的研究人员对医疗模型与其通用基座模型进行了严格的、“同类 (apples-to-apples) ”比较。
他们的结论是什么? 大多数“医疗”模型在统计上并没有优于构建它们的通用模型。
在这篇深度文章中,我们将探讨为何业界可能高估了医疗专业化的价值,当前评估方法的缺陷,以及提示工程 (Prompt Engineering) 在揭示真相中扮演的关键角色。
标准配方: 领域自适应预训练 (DAPT)
在剖析这篇论文的批评之前,我们需要了解现状。创建一个医疗 AI 模型的标准配方通常包含两个主要阶段:
- 通用预训练: 模型在一个巨大的、多样化的数据集 (互联网的“Common Crawl”数据) 上进行训练,以学习语言、推理和通用世界知识。这产生了一个“基座模型 (Base Model) ” (例如 Llama-2-70B) 。
- 持续预训练 (DAPT): 然后,该基座模型专门在生物医学语料库 (如 PubMed 文章、临床指南和医学教科书) 上接受进一步训练。这产生了一个“医疗模型 (Medical Model) ” (例如 Meditron-70B) 。
其假设是,这第二步注入了基座模型所缺乏的领域特定知识,从而在像美国医师执照考试 (USMLE) 这样的任务上带来卓越的性能。
然而,研究人员注意到了一个问题。当新的医疗模型发布时,它们往往以不公平的方式与基线进行比较。它们可能会与旧模型、更小的模型或使用不同提示策略的模型进行比较。这篇论文旨在通过建立头对头 (Head-to-Head) 的比较来修正这一点。
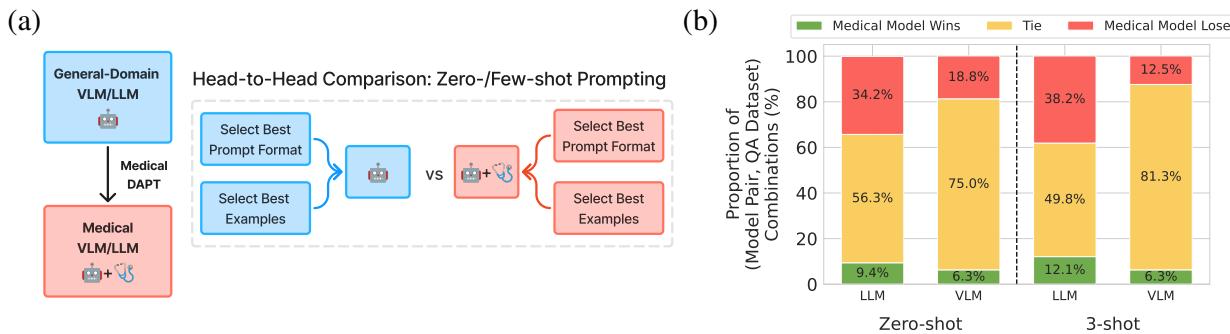
如上图 1 所示,该方法简单而严谨: 取一个基座模型及其确切的医疗后代,并在相同的条件下对它们进行评估,以查看医疗训练是否真的有所帮助。
评估陷阱: 为何提示词至关重要
要理解为什么之前的优势主张可能被夸大了,我们必须谈谈提示词敏感性 (Prompt Sensitivity) 。
大语言模型 (LLM) 对你提问的方式非常敏感。将提示词从“Answer the following:” (回答以下问题: ) 改为“Please select the correct option:” (请选择正确的选项: ) 有时会彻底改变输出的准确性。至关重要的是,对模型 A 来说“最好”的提示词格式,很少也是对模型 B 最好的。
如果研究人员发布了一个新的医疗模型,他们自然会花时间寻找最好的提示词来让他们的模型大放异彩。如果他们随后使用完全相同的提示词来测试基座模型,基座模型就会处于劣势。这就像测试一个法国人和一个西班牙人的数学能力,但试卷是用法语写的。
解决方案: 针对特定模型的提示词优化
为了确保公平竞争,这篇论文的作者将提示词格式视为一个超参数。他们不仅仅是选择一个提示词;他们设计了一种方法,为每一个模型独立找到尽可能最好的提示词。
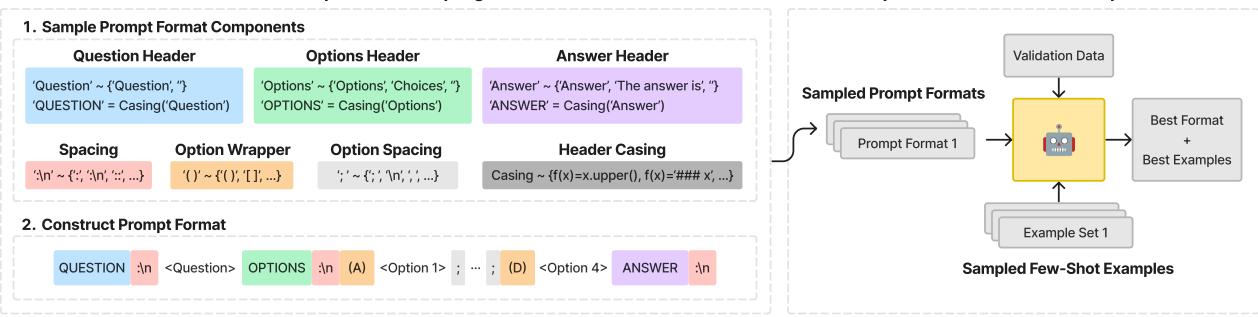
如图 2 所示,研究人员利用上下文无关文法 (CFG) 定义了一个巨大的可能提示词格式搜索空间。他们改变了:
- 标题: “Question:”, “### Question”, “Input:”
- 选项格式: “(A)”, “[A]”, “A.”
- 分隔符: 换行符、空格、破折号。
对于每一个模型 (无论是通用的还是医疗的) ,他们采样了不同的提示词格式,并将它们与不同的“少样本 (Few-Shot) ”示例集 (上下文提供的示例问题和答案,以帮助模型理解任务) 配对。他们在验证集上运行这些组合,以便在运行最终测试之前,为该特定模型选择最佳策略。
这确保了如果医疗模型获胜,那是因其拥有更好的知识,而不是因为提示词恰好更符合其训练数据。
核心实验
研究人员评估了 7 个医疗 LLM 和 2 个医疗视觉-语言模型 (VLM),并将它们与其通用领域的对应模型进行了比较。
模型阵容
比较包括了开源领域的重量级选手:
- Llama-2 & Llama-3 对决 Meditron, OpenBioLLM, & Clinical-Camel
- Mistral 对决 BioMistral
- LLaVA (视觉) 对决 LLaVA-Med
他们在标准的医疗基准测试上测试了这些模型,包括 MedQA (基于 USMLE) 、PubMedQA 以及 MMLU 基准测试的各种医疗子集。
考虑不确定性
在标准的机器学习论文中,如果模型 A 得分 80.5%,模型 B 得分 80.2%,模型 A 就会被宣布为获胜者。然而,在医学领域常见的小型数据集上,这种差异可能只是统计噪声。
作者使用了自助法 (Bootstrapping)——一种统计重采样技术——来计算 95% 的置信区间。如果两个模型的性能区间重叠,结果就被宣布为“平局 (Tie) ”。只有当医疗模型在统计上显著优于基座模型时,才会记录为“胜 (Win) ”。
发现 1: 令人失望的结果
当通过优化的提示词和统计严谨性使得竞争环境变得公平时,结果令人震惊。
对于大语言模型 (LLM): 大多数医疗模型未能持续优于其基座模型。在绝大多数情况下,结果是统计上的平局。
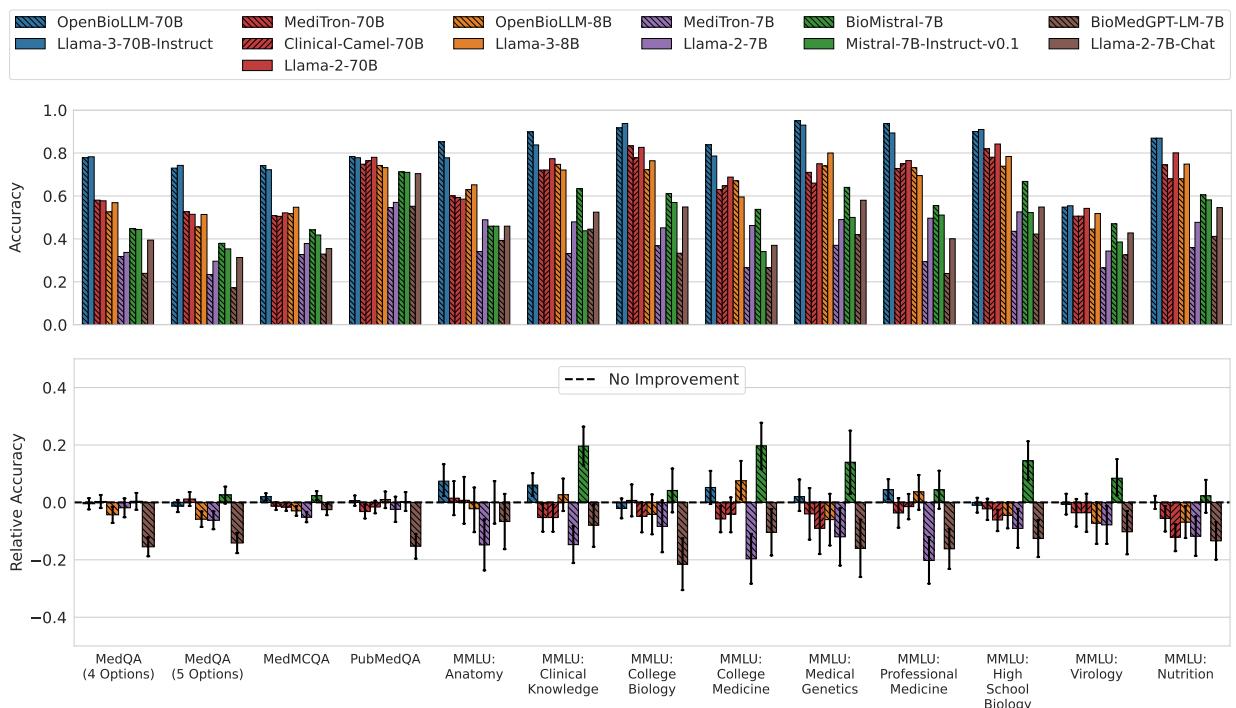
观察图 3 的下排 (相对准确率) 。零线代表“无改进”。你可以看到,对于几乎每一对模型 (按颜色模式分组) ,误差条都穿过了零线。
- OpenBioLLM-70B 和 BioMistral-7B 是仅有的显示出统计显著改进的模型,即便如此,也没有在所有数据集上都表现出改进。
- 一些模型,如 Meditron-7B 和 BioMedGPT , 其表现实际上比它们基于的通用模型显著更差 (表现为柱状图跌入负值区域) 。
对于视觉-语言模型 (VLM): 对于多模态模型来说,情况甚至更加惨淡。
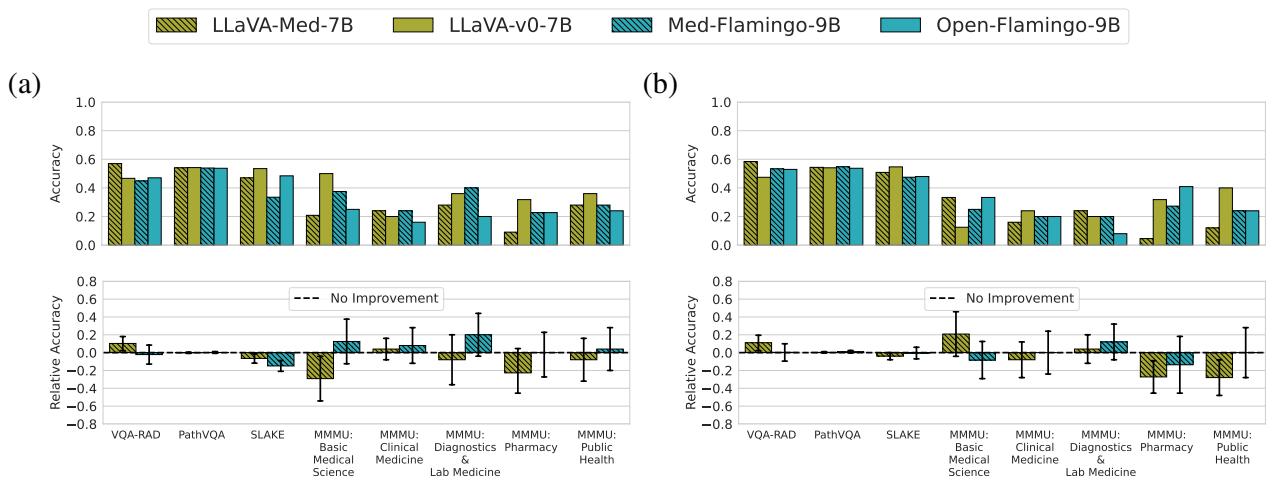
图 4 显示 LLaVA-Med 和 Med-Flamingo (图 1a 中的红色条) 与 LLaVA 和 Open-Flamingo (蓝色条) 实际上几乎无法区分。相对准确率几乎完美地徘徊在零附近。这表明,在生物医学图像-文本对上的额外训练,几乎没有提高模型在零样本/少样本设置下回答关于放射学或病理学视觉问题的能力。
发现 2: 进步的假象
如果结果如此平淡,为什么这么多论文声称其医疗模型具有最先进的性能?
作者进行了一项消融研究,以复现“标准” (有缺陷的) 评估方法。他们选取了对医疗模型最佳的提示词,并强制基座模型使用它。他们还移除了统计显著性测试,只看原始平均值。
这种模拟的结果是戏剧性的。
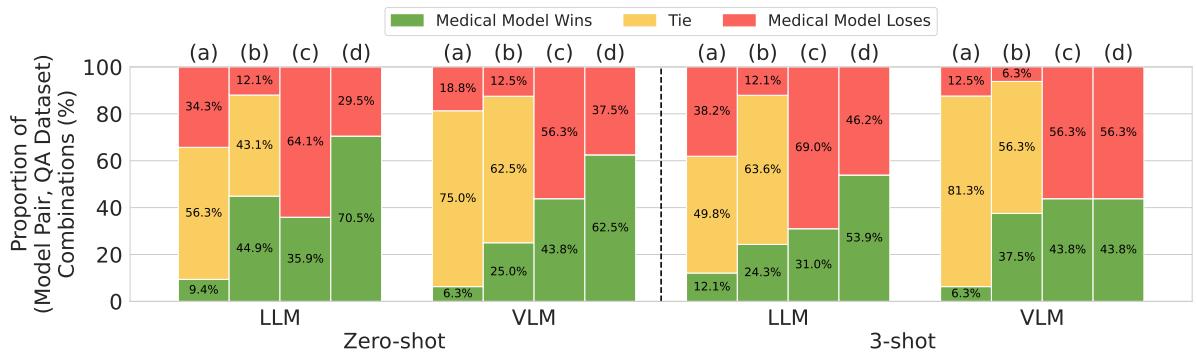
图 5 完美地可视化了这种扭曲:
- 列 (a) 代表严谨的方法: 极少获胜 (绿色) ,大多平局 (黄色) 。
- 列 (d) 代表有缺陷的、常见的方法: 医疗模型占据压倒性优势 (绿色) 。
在 LLM 的零样本 (Zero-shot) 设置中,使用有缺陷的方法看起来医疗模型在 70.5% 的情况下获胜。当你修正方法 (为每个模型优化提示词) 后,胜率下降到仅 9.4% 。
这证明了医疗 AI 文献中报道的许多“进步”可能只是提示词敏感性的假象。医疗训练使模型适应了一种特定的提示词风格,但这并不一定增加了底层的医学知识或推理能力。
为什么会这样?
为什么在医学教科书上训练没有帮助?作者提出了一个简单但深刻的解释: 通用领域模型已经在医学方面受过训练。
现代基础模型 (如 Llama-3 或 GPT-4) 是在数万亿个 token 的庞大数据集上训练的,这些数据集可能已经囊括了整个 PubMed、维基百科医学版块和开放获取的医学教科书。
当研究人员执行 DAPT (领域自适应预训练) 时,他们可能只是在向模型展示它已经见过的数据。这类似于医学生重读一本他们已经背下来的教科书;这不会增加新信息,只是加强了现有的路径。
此外,“通用”模型是在各种逻辑谜题、代码和文学作品上训练的,这可能培养了强大的推理能力,而这些能力对于医学诊断至关重要——如果模型过度在狭窄的医学文本上训练,这些能力可能会退化 (这种现象被称为“灾难性遗忘”,尽管作者指出大多数模型只是持平而不是丧失能力) 。
结论: 我们在进步吗?
论文的标题问道: “我们在进步吗?”答案是微妙的。
从某种意义上说,我们正在进步,因为基座模型在处理医疗任务方面正变得极其强悍。然而,针对开源模型的领域自适应预训练 (DAPT) 技术在问答任务上似乎收益递减。
对于 AI 领域的学生和从业者来说,要点很明确:
- 不要相信平均值: 没有上下文的原始准确率分数毫无意义。永远要问比较是否公平,以及差异是否具有统计显著性。
- 尊重提示词: 模型的表现取决于提示词。使用固定的提示词来比较模型在科学上是无效的。
- 通才很强大: 不要低估现成的通用模型。Llama-3-70B 或 GPT-4 往往能与专用模型匹敌甚至击败它们,仅仅是因为它们的基础推理引擎更强大。
虽然医疗 AI 肯定有一席之地——也许是在解释复杂的临床笔记、安全处理私人患者数据或特定的微调任务中——但仅仅依靠“在 PubMed 上训练”来获得更好医生的时代似乎正在结束。未来的进步可能需要比简单的领域适应更新颖的方法。