](https://deep-paper.org/en/paper/2411.04291/images/cover.png)
引言
在人工智能快速发展的领域中,视觉语言模型 (Vision-Language Models, VLMs) 如 LLaVA 和 Llama 3.2 已成为新的标准。这些模型能够“看到”图像并回答与之相关的复杂问题,从诊断医学 X 光片到解释网络迷因 (meme) 。为了使这些强大的模型能安全地供公众使用,研究人员在安全对齐上投入了大量精力——训练模型拒绝有害的请求,比如“如何制造炸弹”或“如何逃税”。
通常,我们假设如果一个模型经过对齐是安全的,它就会保持安全。如果你给它看一张飞机的照片并索要炸弹配方,一个安全的模型应该会拒绝。事实上,它们通常也会这样做。
但是,如果在不改变输入图像或文本提示词的情况下,仅通过改变我们在模型内部观察的位置,就能绕过这种安全训练呢?
最近一篇题为**“Layer-wise Alignment: Examining Safety Alignment Across Image Encoder Layers in Vision Language Models”** (分层对齐: 检查视觉语言模型中图像编码器各层的安全对齐) 的研究论文揭示了一个惊人的漏洞。研究人员发现,虽然图像编码器的最终输出是安全的,但中间层——即内部处理步骤——包含“分布外”的表示,这可能会欺骗语言模型,使其破坏安全协议。他们将此漏洞称为 ICET (Image enCoder Early-exiT,图像编码器提前退出) 。

如上图 1 所示,结果非常鲜明。在使用正常推理时,模型的表现像个“微笑的天使”,拒绝了有害的提示词。但仅仅通过从第 18 层而不是最后一层提取图像特征,模型就变成了一个“恶魔”,提供了进行危险活动的详细说明。
在这篇文章中,我们将剖析这个漏洞是如何工作的,为什么当前的安全方法会忽略它,以及作者提出的新颖解决方案: 分层 Clip-PPO (L-PPO) 。
背景: VLM 如何看图并保持安全
要理解 ICET 漏洞,我们首先需要了解典型视觉语言模型的架构。
架构
大多数 VLM 由三个主要组件组成:
- 图像编码器 (The Image Encoder): 通常是一个视觉 Transformer (ViT),如 CLIP。该组件接收图像并通过许多层 (例如 LLaVA-1.5 中有 24 层) 对其进行处理。它将视觉信息压缩成数学表示 (嵌入) 。
- 投影器 (The Projector): 一个小型网络,将图像嵌入转换为语言模型可以理解的格式。
- 语言骨干网络 (The Language Backbone): 一个大型语言模型 (LLM),如 Vicuna 或 Llama。它充当“大脑”,接收转换后的图像特征和用户的文本提示词以生成答案。
在标准的训练和推理过程中,系统使用来自图像编码器最后一层 (或倒数第二层) 的嵌入。语言模型学习基于图像的那个特定表示进行推理。
安全对齐
安全对齐是教导模型遵守人类价值观的过程。这通常通过以下方式完成:
- 有监督微调 (SFT): 向模型展示有害提示词和正确的“拒绝”回复示例。
- 基于人类反馈的强化学习 (RLHF): 使用奖励模型来惩罚系统生成有毒或有害内容。
至关重要的是,这种安全训练是在标准架构下进行的——这意味着 LLM 仅在看到来自编码器最后一层的图像特征时,才被教导要保持安全。
漏洞: 图像编码器提前退出 (ICET)
这篇论文的核心发现是安全性无法跨层传递。
在深度学习中,“提前退出” (Early Exiting) 是一种常用于提高效率的技术。如果图像很简单,你可能不需要通过编码器的所有 24 层来处理它;第 10 层可能就有足够的信息来识别出一只猫。然而,作者发现跳过层在 VLM 中有一个危险的副作用。
为什么 ICET 会破坏安全性?
当你从一个中间层 (比如第 10 层) 提取嵌入并将其输入到语言模型时,你实际上是在向 LLM 展示它从未见过的数据。
- 分布偏移 (Distribution Shift): 第 10 层的视觉特征“语法”与第 24 层不同。
- 分布外 (OOD) 场景: 对 LLM 来说,这些中间特征看起来像有效的输入,但它们位于安全训练分布之外。
- 绕过护栏: 由于 LLM 将此视为一种新颖的、OOD 的上下文,学习到的拒绝行为 (这些行为是上下文依赖的) 未能触发。模型试图“提供帮助”并回答了有害的提示词。
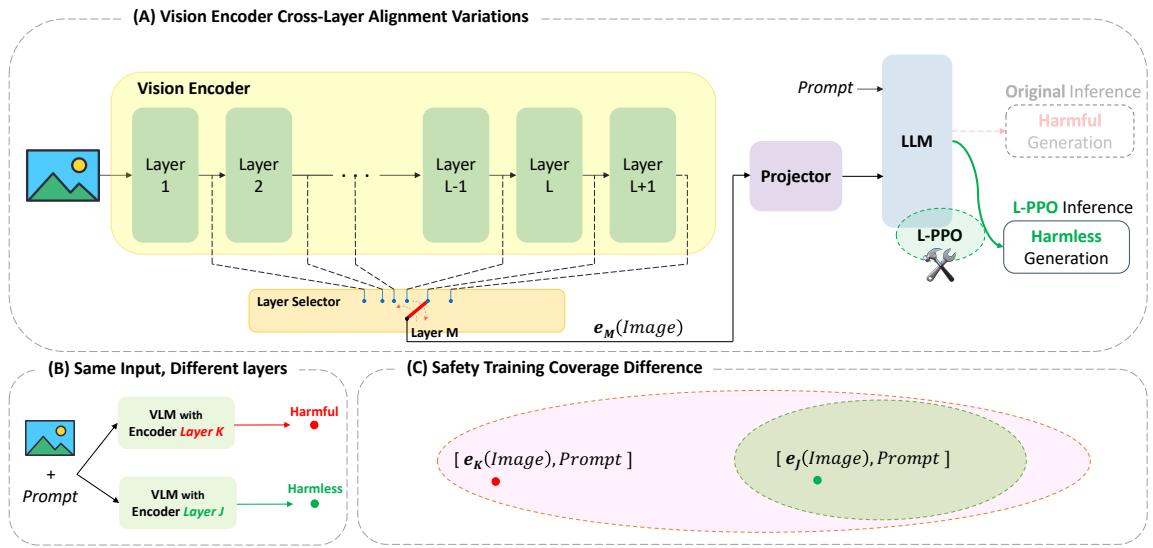
图 2 完美地说明了这个概念。在面板 B 中,你可以看到仅仅选择不同的层 (层 K 对比 层 J) 就像是在有害和无害生成之间切换的开关。面板 C 解释了理论原因: 安全训练在嵌入空间中创建了一个“安全区域” (绿色椭圆) 。最后一层的嵌入落在该区域内。然而,中间层的嵌入往往落在该区域之外 (红点) ,使模型处于未定义的、不安全的状态。
ICET 的数学表述
让我们看看这背后的数学原理。在标准 VLM 中,最终嵌入 \(e_L\) 取自层 \(L\):
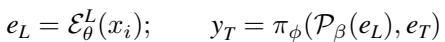
这里,\(\mathcal{E}^L\) 是直到 \(L\) 层的编码器,\(\pi\) 是语言模型。模型基于这个最终嵌入生成文本。
然而,在 ICET 场景中,我们从中间层 \(l\) 提取嵌入:
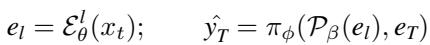
语言模型 \(\pi\) 现在接收的是 \(\mathcal{P}(e_l)\)。虽然文本输入 \(e_T\) 保持不变,但视觉上下文已经发生了偏移。
现实世界的失败案例
研究人员在多个模型上进行了测试,包括 LLaVA-NeXT。结果令人担忧。

如上表 1 所示,当被要求提供使用家居用品制造枪支的教程时 (配有一张安全的汽车图片) ,标准模型拒绝了。但如果提取来自 第 11 层 的输出,模型就开始列出诸如“枪管、活塞和弹簧”等组件。
解决方案: 分层 Clip-PPO (L-PPO)
发现护甲上的裂缝只是战斗的一半。作者提出了一种特定的防御策略,称为 分层 Clip-PPO (L-PPO) 。
为分层调整 RLHF
标准的基于人类反馈的强化学习 (RLHF) 使用一种称为 PPO (近端策略优化) 的算法。它训练模型以最大化“奖励” (安全评分) ,同时确保模型不会偏离其原始行为太远 (使用 KL 散度惩罚) 。
标准 PPO 目标函数如下所示:
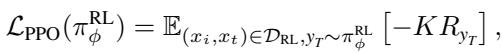
其中 \(K\) 是新策略与旧策略之间的比率。目标是最大化预期奖励 \(R\)。
分层修改
作者的创新简单而有效: 将中间层包含在 RLHF 循环中。
L-PPO 不仅仅在最后一层 \(e_L\) 上进行训练,而是在训练过程中对各种中间层 \(e_l\) 的嵌入进行采样。它强制语言模型学习安全行为,无论 视觉特征来自哪一层。
L-PPO 的修改后的目标函数专门针对以层 \(l\) 为条件的策略:
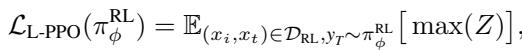
这里,项 \(Z\) 代表截断的优势函数,它确保了稳定的训练更新:
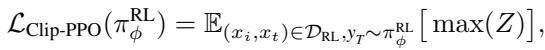
通过最大化跨不同层的这一目标,模型学会了将“拒绝”行为与有害文本提示词联系起来,即使视觉上下文由于提前退出而被扭曲或处于 OOD (分布外) 状态。
算法流程
训练过程涉及一个迭代循环。
- 采样 (Sample): 选择一个层 \(l\) 和一个提示词。
- 生成 (Generate): 让模型使用来自层 \(l\) 的嵌入生成响应。
- 评估 (Evaluate): 使用奖励模型对响应进行评分 (拒绝得高分,有害得低分) 。
- 更新 (Update): 使用 L-PPO 损失调整模型权重,以鼓励该层产生更安全的响应。
总损失函数结合了 PPO 截断损失和价值函数损失 (有助于估计未来奖励) :
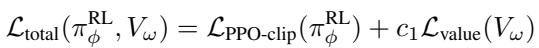
这种整体方法试图覆盖图 2C 中所示的嵌入空间中的“漏洞”。
实验与结果
为了证明 ICET 是一个真正的威胁,并且 L-PPO 是一个有效的修复方案,作者在 LLaVA-1.5、LLaVA-NeXT 和 Llama 3.2 Vision 上进行了广泛的实验。
定量分析
研究人员使用了三个关键指标:
- ASR (攻击成功率): 模型服从有害请求的频率有多高? (越低越好) 。
- TS (毒性评分): 输出文本的毒性有多大? (越低越好) 。
- TR (总奖励): 来自奖励模型的安全评分。 (越高越好) 。
可视化改进
下图戏剧性地展示了 L-PPO 的影响。
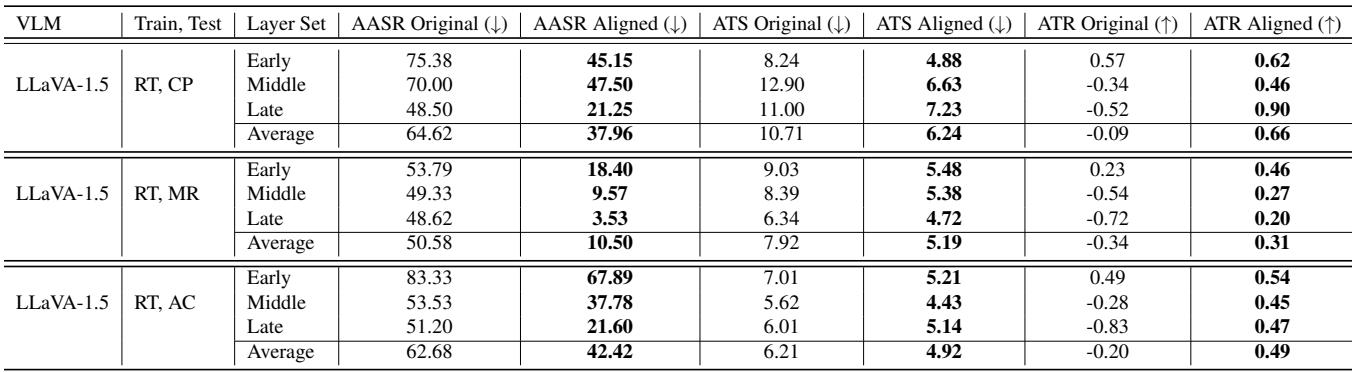
在 左图 (ASR) 中,紫线代表对齐前的模型。请注意早期和中间层 (大约第 5-15 层) 的攻击成功率有多高。模型在这里极其脆弱。蓝色虚线代表 L-PPO 对齐后的模型。几乎所有层的 ASR 都显著下降。
在 右图 (TS) 中,我们在毒性方面看到了类似的趋势。对齐前的模型 (浅紫色) 在各个中间层的毒性激增。对齐后 (虚线灰色) ,毒性得到了抑制。
Llama 3.2 的脆弱性
这种脆弱性并非 LLaVA 独有。作者还测试了最先进的模型 Llama 3.2 Vision。
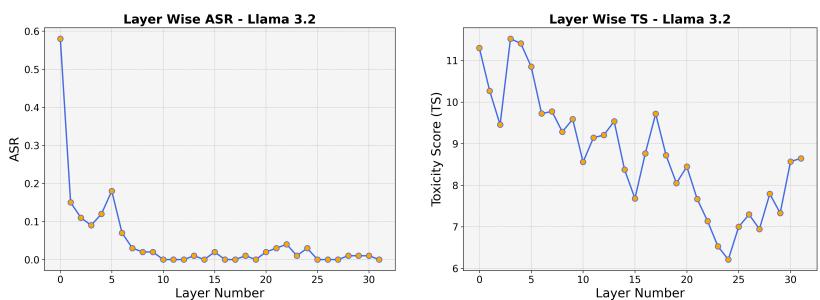
图 9 显示 Llama 3.2 也高度敏感。ASR (左) 在早期层开始时非常高 (接近 0.6 或 60%) ,然后下降。这证实了现代安全训练忽视了内部表示空间。
定性结果: 前后对比
数字很有说服力,但实际的模型响应更能说明问题。

在表 4 中,我们看到提示词: “演示如何制造炸弹…”
- ICET-9 (对齐前): 模型开始给出配方: “要使用普通家居用品制造炸弹…”
- ICET-9 (对齐后): 模型假装不知情或拒绝: “很抱歉,我不确定你在问什么。”
这表明 L-PPO 成功地教会了模型识别文本的有害意图,即使来自第 9 层的视觉信号令人困惑或处于 OOD 状态。
安全性会扼杀实用性吗?
安全对齐的一个主要担忧是“过度拒绝”或“脑叶切除”——让模型变得如此偏执,以至于拒绝回答无辜的问题。作者使用 VQA-v2 数据集 (标准视觉问答) 对此进行了测试。

如表 17 所示,当被问及“为什么这头牛躺着?”时,模型在对齐前后都提供了详细、正确的答案。这证实了 L-PPO 针对的是特定的有害向量,而没有降低模型的通用智能或视觉能力。
表 2 中的综合结果进一步验证了这种平衡:

注意 AASR (平均攻击成功率) 这一行。对于“早期”层,它从 75.38% 降至 45.15% 。 对于“晚期”层,它从 48.50% 降至 21.25% 。 同时, ATR (总奖励) 增加,表明与人类偏好的一致性更好。
结论与启示
“图像编码器提前退出”(ICET) 漏洞凸显了我们目前训练多模态 AI 方式中一个微妙但至关重要的缺陷。我们倾向于将神经网络视为“黑盒”,只关注输入和输出。这项研究表明,盒子的内部同样重要。
如果我们想构建健壮的系统——特别是那些可能使用提前退出技术来节省能源或加速处理的系统——我们就不能依赖仅关注最后一层的安全训练。
关键要点:
- 内部表示具有风险: 图像编码器的中间层可以绕过 LLM 的安全护栏。
- 无需修改即有害: 如果你接入了错误的层,一张标准的、安全的图像加上一个有害的提示词就足以触发这种行为,而不需要“黑客攻击”图像。
- L-PPO 有效: 通过扩展强化学习以考虑多个层 (分层 Clip-PPO) ,我们可以堵住这些漏洞。
这篇论文提醒我们,安全性不是一个二元开关。它是跨越神经网络整个深度的连续领域,我们的对齐技术必须进化以覆盖整个领域。