](https://deep-paper.org/en/paper/2411.05663/images/cover.png)
想象一辆自动驾驶汽车正在学习如何在你的城市中导航。它首先掌握了高速公路,然后是市中心的网格状道路,最后是蜿蜒的郊区小路。现在再想象一下,当它学习识别一种新型人行横道时,却忘记了停车标志长什么样。这样的失误将是灾难性的。
这种现象被称为灾难性遗忘 (catastrophic forgetting) ,是构建稳健人工智能系统的主要障碍之一。它引出了一个根本性问题: 模型如何才能在不抹去已有知识的情况下,从新数据中持续学习? 这一挑战正是持续学习 (Continual Learning, CL) 的核心。
这种困难在一种被称为无任务在线持续学习 (task-free online continual learning) 的现实场景中更加突出。“在线” (Online) 意味着模型像人类一样,每个数据点只看一次。“无任务” (Task-free) 意味着没有预定义的边界或标签来指示任务的开始或结束——数据持续流动,分布变化不可预测地发生。
最近的一篇论文《Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation》为这一问题提出了一个极为有效的解决方案。作者们引入了 Online-LoRA , 这是一个结合了预训练视觉 Transformer (ViT) 的强大能力与一种名为低秩自适应 (LoRA) 的轻量化适应方法的框架。这两者结合,使模型能够持续、高效地学习,同时超越了以往的最先进方法。
在这篇文章中,我们将剖析 Online-LoRA 背后的关键洞见,探索其工作原理,回顾其令人印象深刻的实验结果,并讨论它对人工智能终身学习的未来影响。
奠定基础: 持续学习的全景
在深入探讨 Online-LoRA 之前,理解持续学习的整体格局将更有帮助。
持续学习的两难困境
持续学习旨在让模型在一系列随着时间演变的数据分布上进行训练。持续学习方法通常可以根据两个维度进行分类:
- 基于任务 vs. 无任务:
- 基于任务的方法知道一个任务何时结束、另一个任务何时开始 (例如,“先学猫,再学狗”) 。
- 无任务的方法没有这样的信息——数据流是连续的,常常将旧分布与新分布混合。
- 离线 vs. 在线:
- 离线方法可以在同一任务数据上进行多轮 (epoch) 训练。
- 在线方法只能对数据流进行一次遍历,需要即时更新。
最具挑战性也最现实的配置是在线、无任务的场景——这对于机器人、自动驾驶车辆和自适应医疗系统等动态环境至关重要。缺乏明确的任务边界与有限的数据访问使传统训练方案在此完全失效。
预训练模型与 LoRA 的崛起
大型预训练模型如视觉 Transformer (ViT) 通过在海量数据集上学习通用、可迁移的特征表示,彻底革新了计算机视觉领域。如今,研究者通常不再从零开始训练,而是将这些预训练模型微调到新任务上,这既高效又性能优越。
然而,完全微调一个庞大模型 (例如超过 8600 万参数) 的计算成本仍然很高,并可能导致灾难性遗忘。为此,提出了参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT) 方法。
其中一种强大的 PEFT 技术是低秩自适应 (Low-Rank Adaptation, LoRA) , 它允许模型只更新部分参数。LoRA 会冻结原始权重 \( W_{init} \),并学习一个由两个低秩矩阵 \( B \) 和 \( A \) 构成的紧凑偏移量 \( \Delta W \):
\[ \Delta W = BA \]其中,\( B \in \mathbb{R}^{d \times r} \),\( A \in \mathbb{R}^{r \times k} \),秩 \( r \ll \min(d, k) \)。只有 \( A \) 和 \( B \) 参与训练,这在保留模型表达能力的同时显著降低了计算负担。
LoRA 已在离线、基于任务的持续学习中取得成功,但将其应用于无任务在线场景——即系统需自行检测分布变化——仍是未解难题。这正是 Online-LoRA 大显身手的地方。
核心方法: Online-LoRA 的工作机制
Online-LoRA 引入了两项关键创新,使 LoRA 能够在在线、无任务的持续学习中发挥作用:
- 损失引导的模型自适应 —— 自动检测数据分布何时变化。
- 在线权重正则化 —— 以极小的内存开销高效地保护旧知识。
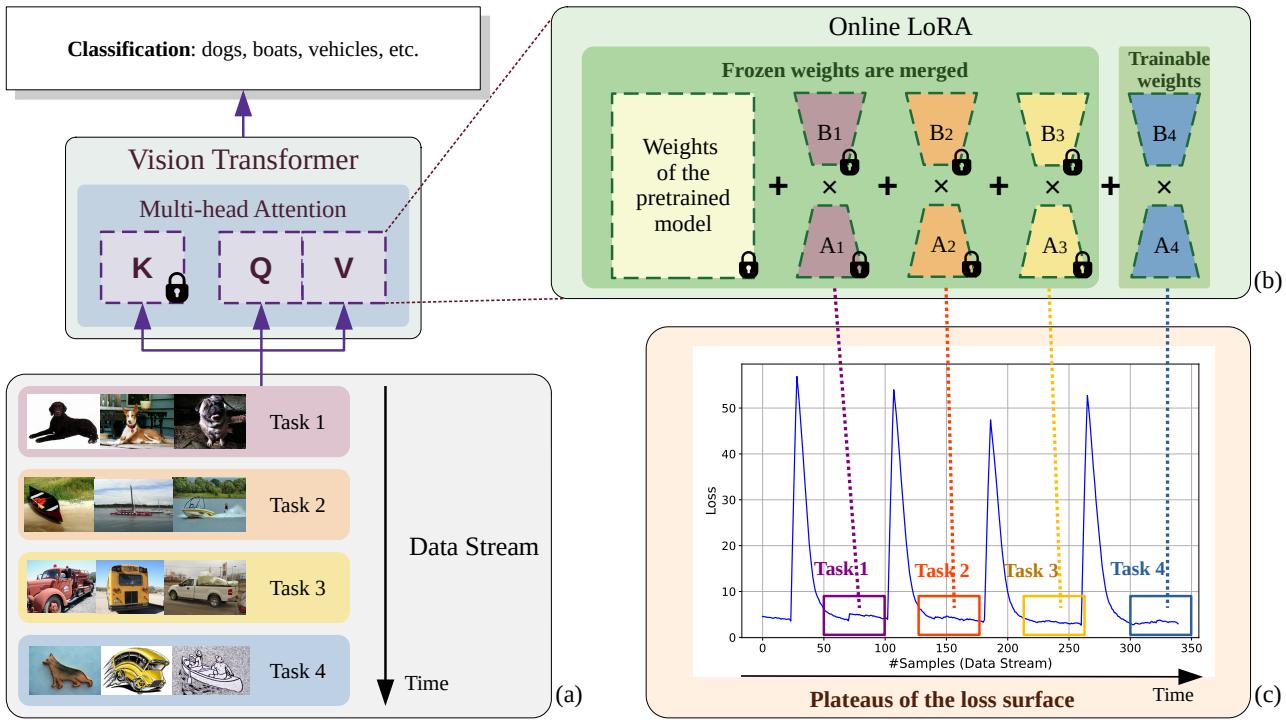
图 1. Online-LoRA 概览。随着数据的持续输入,损失曲面上的每个平稳阶段都会促使生成新的 LoRA 模块,而之前的模块则被冻结并合并到 ViT 权重中。
1. 损失引导的模型自适应: 打破任务边界的学习
模型应该何时开始学习新的知识,何时巩固已有的知识? Online-LoRA 的答案来自模型的损失曲面——一条反映学习效果随时间变化的曲线。
- 损失下降: 模型正在有效地学习当前数据。
- 损失突增: 数据分布可能发生了改变。
- 损失平坦且较低 (平稳期) : 模型已收敛,是进行知识整合的时机。
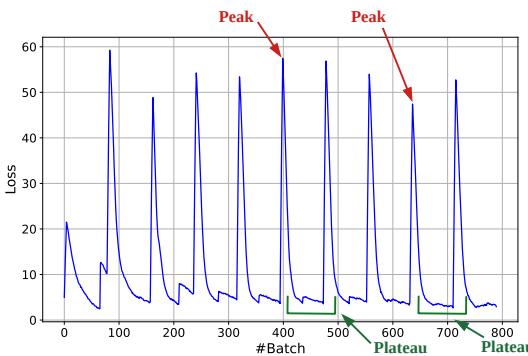
图 4. CIFAR-100 上的 Online-LoRA 损失曲面可视化。峰值表示数据分布变化,稳定的平稳期则指示适应时刻。
为此,Online-LoRA 通过滑动窗口持续监控训练损失。 当窗口内损失的均值与方差低于设定阈值时,系统检测到一个平稳期 。 此刻:
- 当前的可训练 LoRA 矩阵 \( (A_t, B_t) \) 被冻结 ;
- 它们被合并到 ViT 主权重中,永久保留已学习到的知识;
- 创建新的、随机初始化的矩阵 \( (A_{t+1}, B_{t+1}) \),用于学习新的数据。
通过将适应机制与训练过程中的内在动态而非任务边界相联系,Online-LoRA 实现了真正的自我调节和动态响应。
2. 在线参数重要性估计: 高效防遗忘
即使有了自适应模块,新的学习仍可能干扰旧知识。为减轻此问题,Online-LoRA 引入了一种轻量化的在线正则化机制,用于识别并保护关键参数。
传统方法如 弹性权重整合 (EWC) 需要通过费雪信息矩阵计算所有参数的重要性——这对于拥有数千万参数的 ViT 而言运算量巨大。
Online-LoRA 实现了两项效率上的突破:
a) 仅对 LoRA 参数进行正则化。 Online-LoRA 仅追踪少量可训练的 LoRA矩阵。在 ViT-B/16 (LoRA 秩为 4) 中,这一策略将需要追踪的参数数从约 8600 万降至仅约 15 万 (约 0.17%) ,可以实时更新。
b) 使用极小的硬缓冲区。 为了估计参数的重要性,模型需利用一些样本来衡量敏感度。Online-LoRA 不使用大型重放缓冲区,而会维护一个仅包含 4 个高损失样本 的硬缓冲区——这些样本是模型认为最具挑战性的。该紧凑集合能提供强信号来指示哪些知识需要被保留,同时保证隐私和内存高效。
综合以上方法,每个 LoRA 参数的重要性计算如下:
\[ \Omega_{ij}^{A,l} = \frac{1}{N} \sum_{k=1}^{N} \nabla_{W_{ij}^{A,l}} \log p(x_k|\theta) \circ \nabla_{W_{ij}^{A,l}} \log p(x_k|\theta) \]\[ \Omega_{ij}^{B,l} = \frac{1}{N} \sum_{k=1}^{N} \nabla_{W_{ij}^{B,l}} \log p(x_k|\theta) \circ \nabla_{W_{ij}^{B,l}} \log p(x_k|\theta) \]基于这些权重,整体学习目标为:
\[ \min_{W^A, W^B} \mathcal{L}(F(X;\theta), Y) + \mathcal{L}(F(X_B;\theta), Y_B) + L_{\text{LoRA}}(W^A, W^B) \]其中三部分分别代表:
- 当前批次的损失;
- 硬缓冲区样本的损失;
- 用于保护关键参数免受剧烈更新的 LoRA 正则化惩罚项。
这种受贝叶斯思想启发的高效正则化使 Online-LoRA 能够在持续学习过程中有效防止遗忘。
实验与结果: 验证 Online-LoRA 的表现
作者在多个基准场景中进行了广泛实验,每个场景都测试了持续学习的不同方面。
实验设置
Online-LoRA 在三种关键场景下进行了评估:
- 不相交类增量: 任务拥有不同且不重叠的类别集合。
- 模糊边界类增量: 任务之间存在重叠,边界动态变化。
- 域增量: 类别保持不变,但输入风格或领域发生改变 (例如照片 → 素描) 。
基线方法包括重放类方法 (ER、DER++、PCR) 、正则化类方法 (EWC++) 以及提示类方法 (L2P、MVP) 。
不相交类增量学习结果
在这一设置中,无论是 ViT-B/16 还是 ViT-S/16 架构,Online-LoRA 都在多个数据集上 (CIFAR-100、ImageNet-R、ImageNet-S、CUB-200) 实现了最高最终准确率和最低遗忘率 。
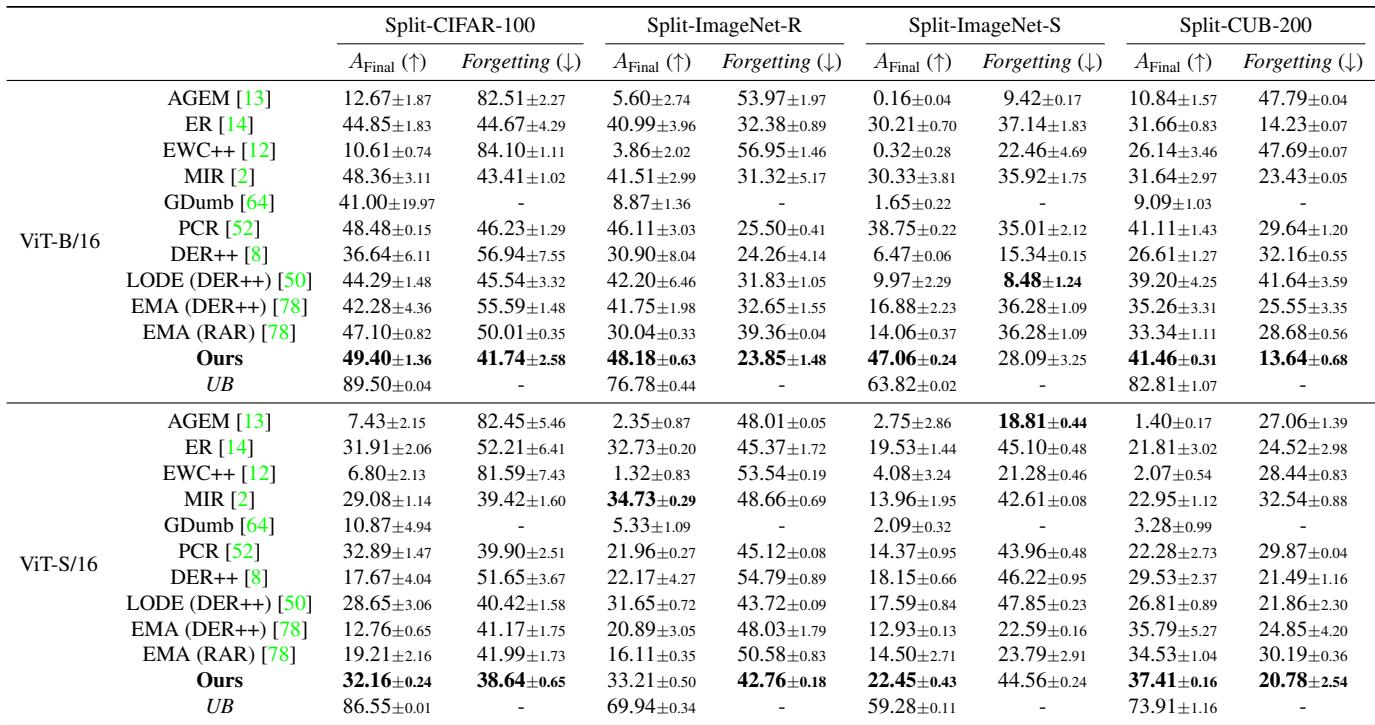
图/表 1. 不相交类增量学习结果。Online-LoRA 在不同数据集和架构上均优于现有所有方法。
模糊边界类增量学习结果
在更加动态的模糊边界场景中,Online-LoRA 仍然表现卓越。它显著优于提示类方法 (L2P、MVP) ,并在整个数据流中保持强大的即时推理准确率。
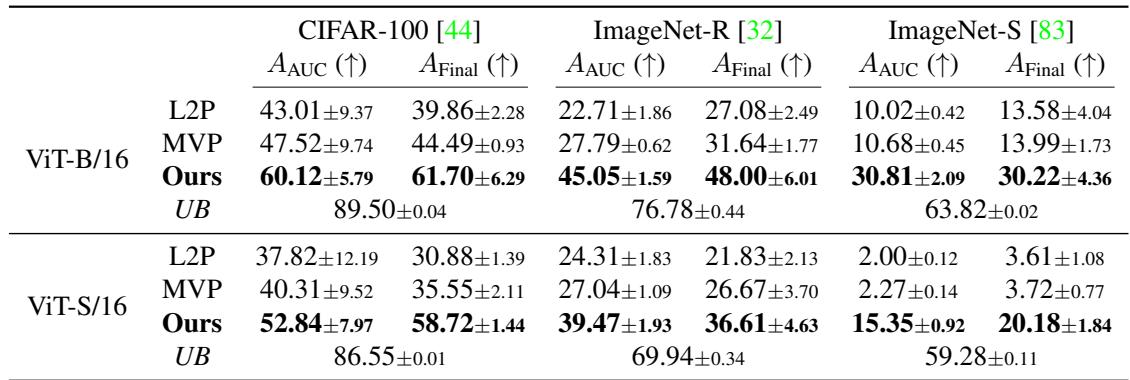
图/表 2. 模糊边界学习结果。Online-LoRA 在流式学习过程中展现出更高准确率与稳定性。
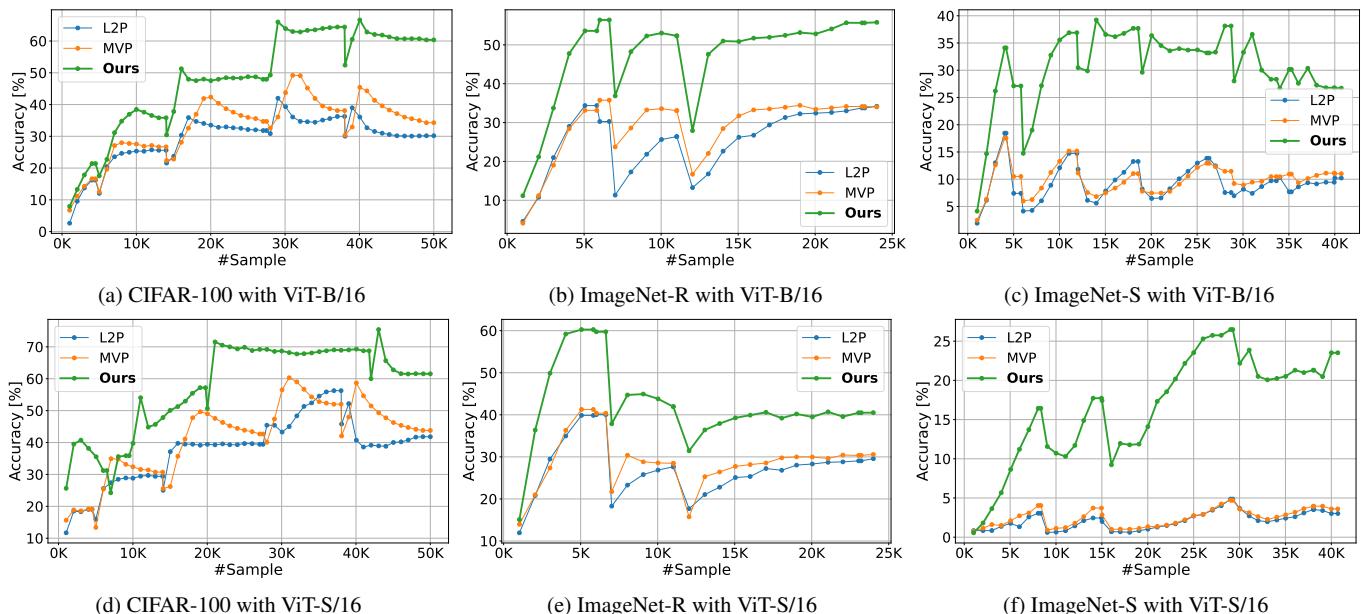
图 2. Online-LoRA 在整个训练阶段持续保持顶级表现,而不仅仅在训练结束时——这对于现实场景的持续推理至关重要。
域增量学习结果
在跨域适应方面,Online-LoRA 表现更加突出。在 CORe50 数据集上,其最终准确率达到 93.7% , 几乎完全弥合了与上限 (95.6%) 之间的差距,同时完全避免了灾难性遗忘。
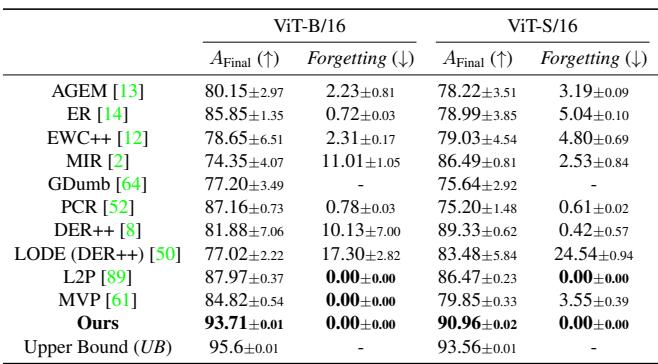
图/表 3. CORe50 上的域增量性能比较。Online-LoRA 以零遗忘率几乎达到了监督学习的上限性能。
更长任务序列下的扩展性
一个稳健的持续学习模型应能在任务数量增加的情况下保持稳定。如下图所示,当其他方法随任务增多而性能急剧下降时,Online-LoRA 凭借损失驱动的自适应与持续正则化保持了极高的稳健性。
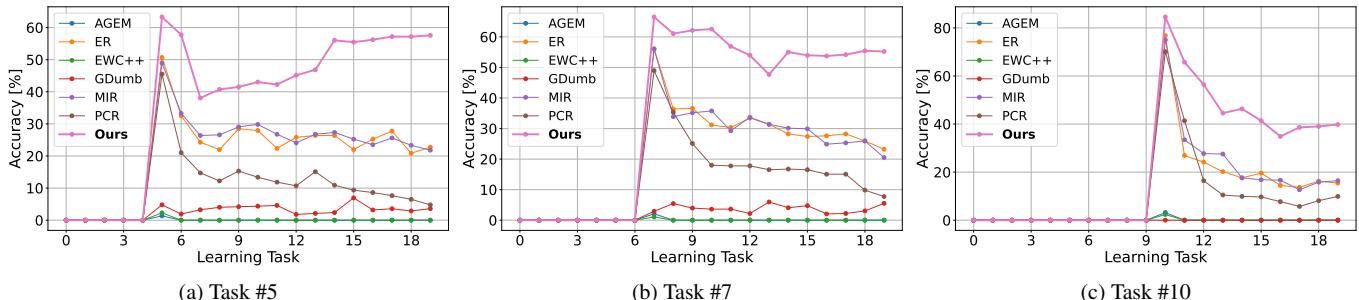
图 3. 多任务序列的验证准确率。Online-LoRA 随时间推移依然保持高性能与最低遗忘。
消融研究: 它为何有效
为了验证每个组件的贡献,作者进行了消融实验,分别移除了“增量 LoRA”机制和/或“硬损失”正则化。
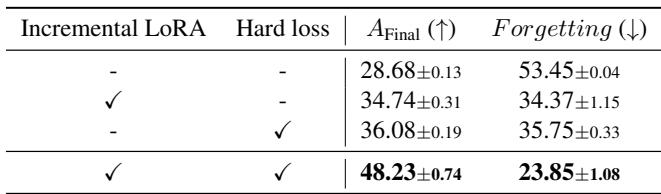
图/表 6. 消融实验结果,凸显各组件的重要性。
移除任何一个组件都会显著降低性能。唯有两者结合时,Online-LoRA 才能达到最佳效果——这验证了动态 LoRA 更新与在线正则化之间的强大协同。
结论与展望
Online-LoRA 是持续学习领域的一项重要突破。它通过将模型的损失信号转化为自适应触发机制,并利用低秩结构实现高效正则化,从而优雅地完成了无任务在线学习 , 无需重放缓冲区或任务边界。
核心启示:
- 自我调节的扩展性: 损失平稳期自然地指示何时巩固学习并开始适应新数据。
- 极致高效: 仅关注 LoRA 参数即可实现对大型 ViT 的在线正则化,所需内存与计算极低。
- 广泛稳健性: 在类别、领域及长任务序列等多方面均实现领先表现,展现出无与伦比的稳定与灵活。
随着人工智能系统在持续变化的环境中运行,像 Online-LoRA 这样的方法将愈发重要。这篇论文不仅展现了技术革新,也为实现终身学习——即智能体能无缝适应并永久记忆——描绘了切实可行的路径。