](https://deep-paper.org/en/paper/2411.05764/images/cover.png)
引言
我们生活在一个信息爆炸的时代。每天,新闻媒体、社交网络和论坛都充斥着关于公司业绩的各种声明。“X 公司的收入增长了 20%”,或者“Y 公司的债务负担翻了一番”。对于投资者和分析师来说,依据错误信息行事的代价极高。对抗错误信息的解药是验证——即根据原始来源文件 (如提交给美国证券交易委员会 SEC 的 10-K 年度报告和 10-Q 季度报告) 来核对这些声明。
然而,自动化这一验证过程极其困难。金融文件不仅仅是长文本文件;它们是包含复杂表格和微妙法律语言的密集混合生态系统。虽然像 GPT-4 这样的大型语言模型 (LLM) 在通用任务中表现出了惊人的能力,但它们能否充当金融审计员仍然是一个未知数。
这引出了 FINDVER , 这是由耶鲁大学 NLP 研究人员开发的一个新基准。FINDVER 旨在严格测试 LLM 是否可以验证长篇、混合内容的金融文档中的声明,并且——至关重要的是——它们是否可以解释其推理过程。
在这篇深度文章中,我们将探讨为什么金融验证如此具有挑战性,FINDVER 基准是如何利用金融专家构建的,以及结果告诉我们关于人类专家与人工智能之间当前差距的哪些信息。
背景: 为什么现有的基准还不够
要理解 FINDVER 的贡献,我们必须先看看自动事实核查的现状。声明验证 (Claim Verification) 是自然语言处理 (NLP) 中一个成熟的领域。通常,模型会收到一个声明和一条证据,它必须判定该证据是蕴含 (支持) 还是驳斥该声明。
然而,现有的基准应用于金融领域时存在显著的局限性。大多数数据集依赖于维基百科文章或简单、独立的表格。它们很少要求模型消化包含混合文本和表格数据的 100 页文档来执行复杂的算术运算。此外,以前的大多数基准只要求简单的“真/假”标签。在金融领域,决策必须经得起推敲,没有解释的标签是毫无用处的。
下表强调了 FINDVER 所填补的空白:
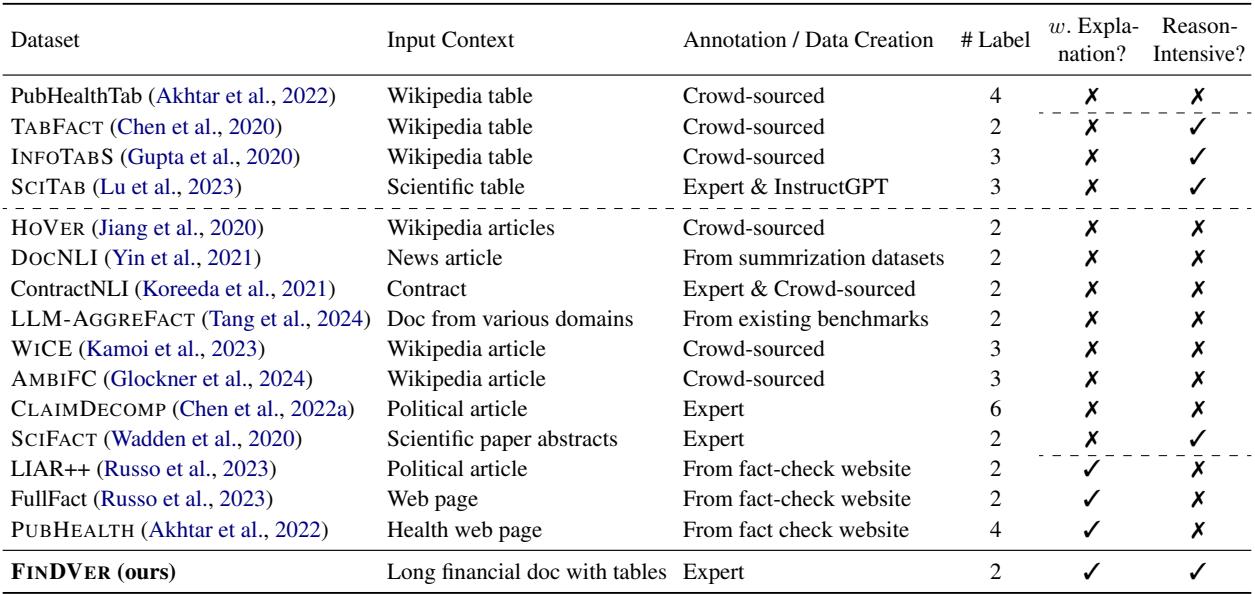
如上表所示,FINDVER 因以下四个原因而脱颖而出:
- 专家标注: 数据由金融专业人士创建,而非众包工人。
- 复杂的文档理解: 它使用完整的金融备案文件,要求综合文本和表格。
- 推理过程解释: 模型必须解释它是 如何 得出结论的。
- 多样化推理: 它测试信息提取、数值计算和领域知识。
核心方法: 构建金融吐真剂
研究人员正式定义了该任务以确保清晰度。给定一份金融文档 \(d\) (包含文本段落 \(P\) 和表格 \(T\)) 以及一个声明 \(c\),模型必须执行两个子任务。
首先, 蕴含分类 。 模型必须最大化选择正确标签 \(\ell\) (“entailed/蕴含”或“refuted/驳斥”) 的概率:
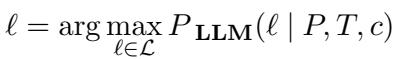
其次,或许也是更重要的一点, 解释生成 。 模型必须生成一段自然语言解释 \(e\),概述验证该声明所采取的推理步骤:
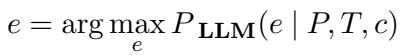
混合内容的挑战
这为什么很难?考虑基准测试中的以下示例。要验证有关客户账户的声明,模型不能简单地执行关键词搜索。它必须定位嵌入在“现金来源和使用”部分中的具体数字,并将它们与不同财政年度的现金流量表进行交叉引用。

在上面的示例 (图 1) 中,模型必须定位不同模态 (文本和表格) 中的数据点,理解财政期间 (2023 年 3 月 31 日与 2024 年的对比) ,并执行计算。这就是 FINDVER 的 数值推理 方面。
构建数据集: 专家流水线
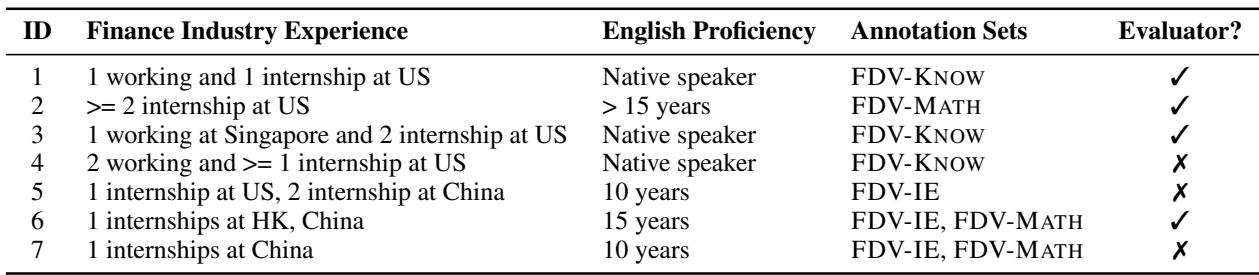
对许多 NLP 数据集最强烈的批评之一是“垃圾进,垃圾出”。如果基准真实数据 (Ground Truth) 充满噪声,评估就毫无意义。为了应对这一问题,FINDVER 团队采用了一个包含金融专家 (具有金融背景的个人,包括 CFA 持证人) 的严格流水线。
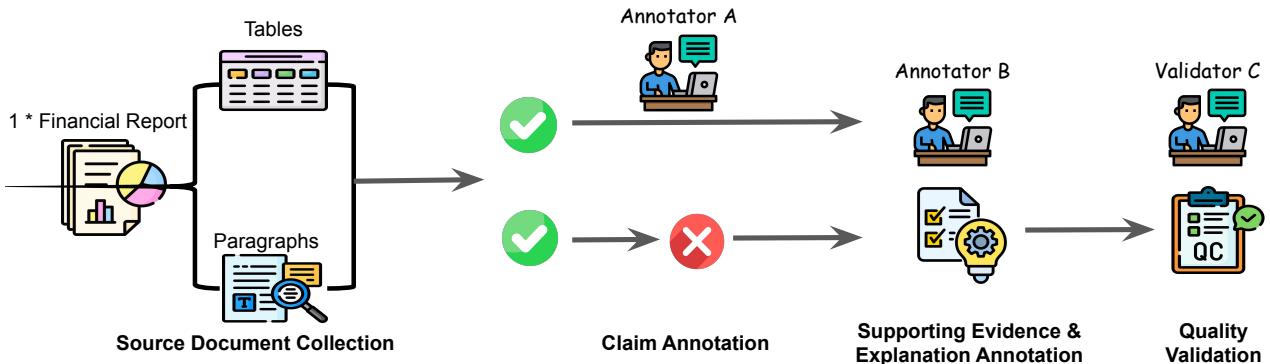
如图 2 所示,该流水线包含以下步骤:
- 来源收集: 他们收集了 523 份发布于 2024 年 1 月至 4 月之间的实际季度和年度报告 (表格 10-Q 和 10-K) 。这个日期范围至关重要,因为它确保这些文档很可能处于像 GPT-4 这样的模型的训练数据之外,防止模型仅仅是背诵记忆的事实。
- 蕴含声明标注: 专家阅读文档并根据证据撰写真实的 (“entailed”) 声明。他们还记录了具体的证据位置 (段落和表格索引) 。
- 驳斥声明生成: 这是一个巧妙的步骤。他们没有让标注员凭空捏造虚假声明 (这很容易通过文风被检测出来) ,而是要求专家获取真实的声明并对其进行轻微“扰动”以引入事实错误。这创造了高质量的“驳斥”声明,看起来与真实声明非常相似。
- 解释标注: 另一位标注员撰写分步推理过程。
- 质量验证: 最后由一位专家验证员审查工作以确保准确性。
专家的参与并非无关紧要的细节。金融文档使用的专业术语通常会被普通众包工人误解。标注员的简介证实了数据创建者的高水准:
三种类型的推理
数据集分为三个子集以测试不同的能力:
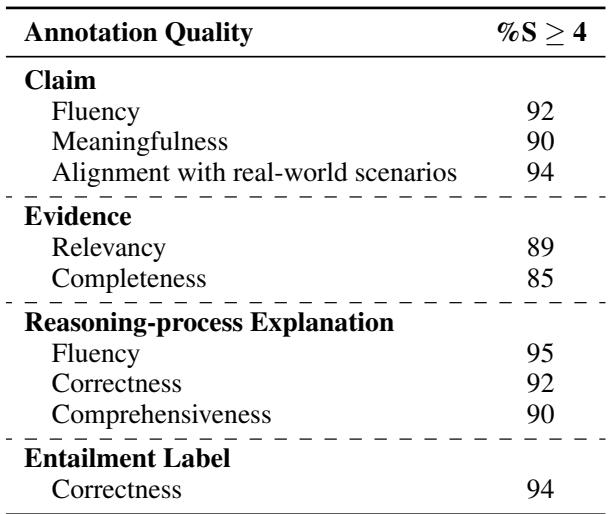
- FDV-IE (信息提取) : 大海捞针。模型能否从 50 页的文档中检索到特定的日期、名称或数字?
- FDV-MATH (数值推理) : 模型能进行计算吗?例如,“净利息支出是否减少了 5%?”需要找到数字并进行数学运算。
- FDV-KNOW (知识密集型) : 这需要外部知识。例如,理解文本中提到的特定法规意味着某种财务义务,即使文中没有明确说明。
下面是一个完美的“testmini”数据点的示例。请注意清晰的“推理过程解释”,它将验证分解为提取和计算步骤。
实验与结果
研究人员评估了 16 种不同的大型语言模型。这包括 GPT-4o、Claude-3.5-Sonnet 和 Gemini-1.5-Pro 等专有模型,以及 Llama-3、Qwen-2.5 和 Mistral 等开源重量级模型。
由于金融文档非常长 (通常超过 40,000 个 token) ,他们测试了两种不同的策略:
- 长上下文 (Long-Context) : 将整个文档输入模型 (适用于支持超大上下文窗口的模型) 。
- RAG (检索增强生成) : 使用搜索算法找到前 10 个最相关的文本/表格块,并仅将这些块输入模型。
核心结果: 人类仍然更胜一筹
对于 AI 爱好者来说,最令人清醒的结果是性能差距。研究人员利用非专家 (计算机科学本科生) 和专家 (金融专业人士) 建立了人类基线。
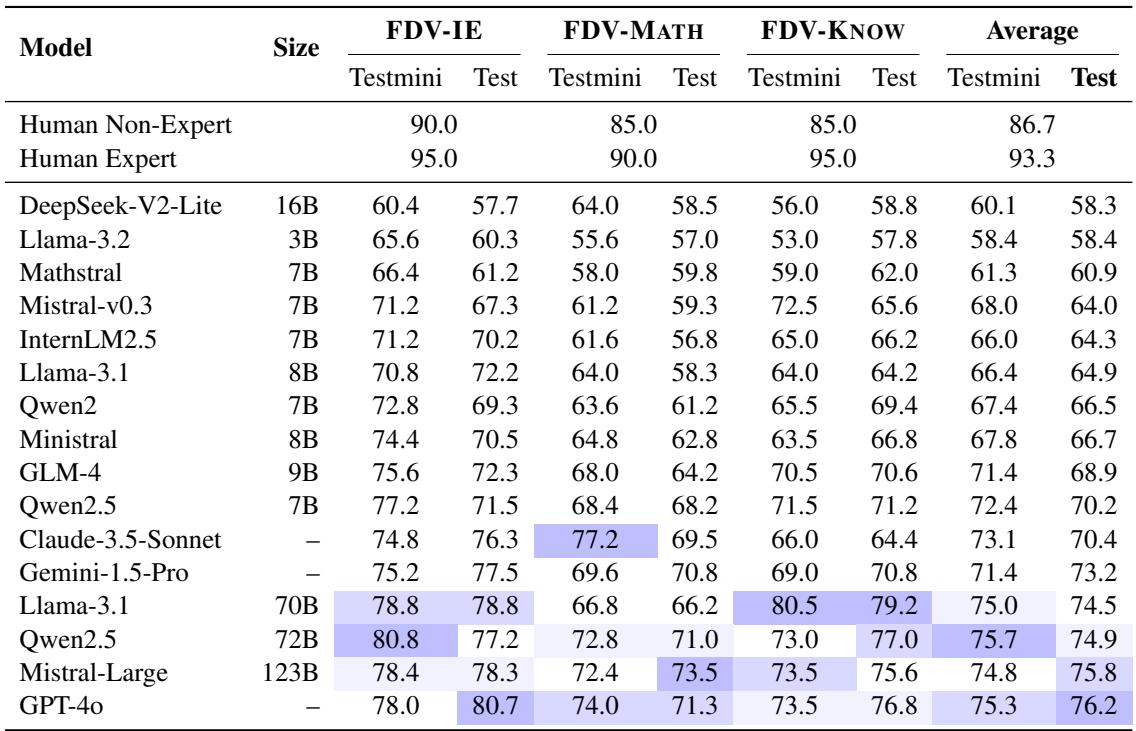
如表 3 所示:
- 人类专家 达到了 93.3% 的准确率。
- 表现最好的模型 GPT-4o 仅达到 76.2% 。
- 像 Qwen2.5-72B 和 Llama-3.1-70B 这样的开源模型正在迎头赶上,得分约为 74-75% 。
这近 20% 的差距表明,虽然 LLM 是有用的助手,但它们尚未准备好以专家级的可靠性独立审计金融声明。
策略: 长上下文 vs. RAG
AI 社区的一个主要争论是我们应该将所有数据都丢给模型 (长上下文) ,还是使用搜索来查找相关部分 (RAG) 。
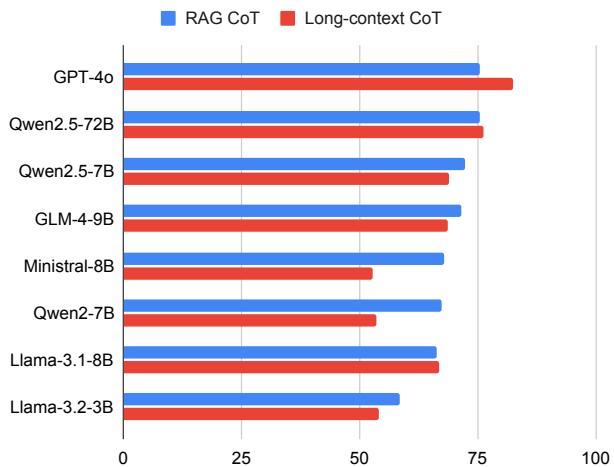
图 3 揭示了一个有趣的趋势。对于能力最强的模型 (如 GPT-4o) , 长上下文 方法 (红色条) 略微优于或与 RAG 持平。这表明这些模型在管理海量序列的注意力方面正变得越来越好。然而,对于较小或能力较弱的模型 (如 Llama-3.1-8B) , RAG (蓝色条) 通常更优,因为它减少了噪声并使模型专注于相关部分。
检索的重要性
如果你选择 RAG 路线,你的“搜索引擎”质量至关重要。研究人员测试了不同的检索方法: BM25 (关键词匹配) 、Contriever 和 OpenAI 的嵌入 (Embeddings) 。
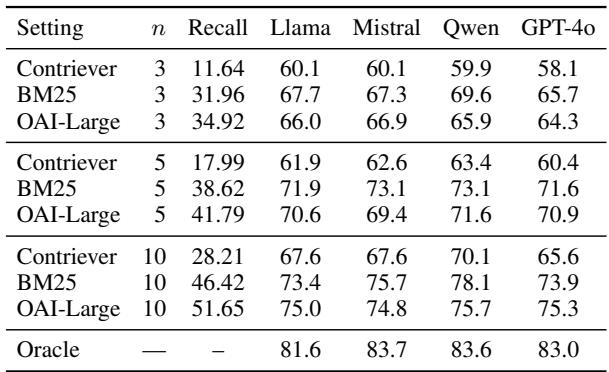
表 4 显示, Oracle (预言机) 性能 (即给予模型确切正确的证据) 显著更高 (约 83%) ,远超任何检索方法。这证明了一个主要的瓶颈仅仅是 找到 正确的表格或段落。有趣的是,老派的 BM25 算法通常表现出与昂贵的向量嵌入相近的竞争力,这突显出在金融领域,精确的关键词匹配 (如查找特定的账户名称) 至关重要。
“思考”的力量
最后,研究人员验证了思维链 (Chain-of-Thought, CoT) 提示的重要性。这是一种要求模型在给出最终答案之前“一步步思考”的技术。
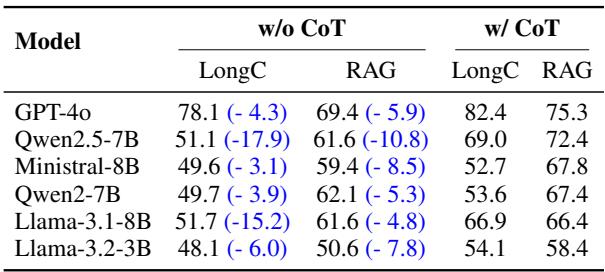
表 5 是决定性的: 去掉推理步骤 (“w/o CoT”) 导致准确率骤降。例如, Qwen2.5-7B 在长上下文设置中,如果没有 CoT,准确率从 69.0% 降至 51.1%。这证实了金融验证不仅仅是模式匹配;它需要逻辑的、顺序的推演。
错误分析: 模型在哪里失败?
通过手动审查 GPT-4o 犯下的错误,研究人员确定了四种主要的失败模式:
- 提取错误: 模型查看了错误的表格或段落。
- 数值推理错误: 模型检索到了正确的数字,但建立的数学算式是错的 (例如,应该是减法却用了加法) 。
- 计算错误: 逻辑是对的,但算术算错了 (这是 LLM 的一个常见问题,尽管正在改善) 。
- 领域知识缺失: 模型未能理解文本中隐含的金融会计原则。
结论与启示
FINDVER 基准是对金融领域部署 AI 的一次现实检验。虽然 GPT-4o 和 Claude-3.5 这样的模型令人印象深刻,但在面对现实世界金融备案文件的复杂性时,它们仍然明显落后于人类专家。
该研究强调,未来的进步依赖于三件事:
- 更好的检索: 我们需要更智能的系统,能够在 100 页的文档中精确定位相关表格。
- 增强的推理: 模型需要在多步数值逻辑方面变得更好。
- 混合读写能力: 无缝综合密集文本和复杂表格信息的能力是不可谈判的。
对于进入该领域的学生和研究人员来说,FINDVER 提供了一个强大的测试场。它让我们从验证像“天空是蓝色的”这样的简单事实,转向验证像“由于经营现金流的抵消,公司的流动性状况有所改善”这样复杂、高风险的声明。随着模型在 FINDVER 上不断进步,我们将离能够真正充当可靠金融分析师的 AI 系统更近一步。