](https://deep-paper.org/en/paper/2411.05783/images/cover.png)
试想一下,当你试图学习高等量子物理或有机化学时,每当出现“电磁学”或“光合作用”这样的专业术语时,你的老师就会停下来,一个字母一个字母地慢慢拼写出这个单词。这正是许多失聪和听力障碍 (DHH) 学生面临的现实。虽然美国手语 (ASL) 是一种丰富且表现力强的语言,但它在 STEM 教育中面临着一个巨大的瓶颈: 缺乏针对技术概念的标准化手语。
当专业口译员遇到这些没有已知手语的术语时,他们只能求助于指拼 (fingerspelling) ——即使用手势字母表拼写出英语单词。虽然这种方法可行,但过度的指拼会产生极高的认知负荷,迫使学生不断在视觉 ASL 和心理英语处理之间切换。这对深度理解概念构成了障碍。
在研究论文 “ASL STEM Wiki: Dataset and Benchmark for Interpreting STEM Articles” 中,来自微软研究院、加州大学伯克利分校和马里兰大学的研究人员直面了这一问题。他们引入了一个庞大的新数据集,并提出了 AI 方法来帮助口译员查找和标准化手语,旨在最终让 STEM 教育变得更加无障碍。
问题: STEM 手语的短缺
ASL 是一门鲜活的、不断演变的语言。然而,由于失聪人士在科学领域的代表性历来不足,导致 ASL 在 STEM 领域的词汇增长滞后。虽然失聪科学家和教育工作者确实会为特定概念创造手语,但这些手语往往局限于小圈子内,未能广泛采用。
在缺乏标准手语的情况下,口译员通常使用以下三种策略之一:
- 意译 : 使用相关概念的手语 (例如,用“意图 (intention) ”的手语来表达“数学平均值 (mean) ”) ,但这可能会造成混淆。
- 占位符简写 : 使用初始手形 (如字母“M”) ,这本身不带有任何含义。
- 指拼 : 将单词拼写出来 (M-E-A-N) 。
研究人员指出,当过度使用指拼时,对学习的干扰最大。为了解决这个问题,我们需要更好的工具来向口译员建议标准手语。但要构建这些工具,我们首先需要数据——海量的数据。
介绍 ASL STEM Wiki
这篇论文的核心贡献是 ASL STEM Wiki 数据集。这是第一个专门关注科学、技术、工程和数学的连续手语数据集。
大多数现有的手语数据集主要关注日常交流或“操作指南”类教学视频。ASL STEM Wiki 的独特之处在于它捕捉了技术性话语的复杂性。研究人员整理了五个领域的 254 篇英语维基百科文章: 科学、地理、技术、数学和医学。

如上方的表 1 所示,ASL STEM Wiki 的突出之处不仅在于其主题,还在于其构建过程中的伦理考量。它包含了来自 37 位认证专业口译员的超过 300 小时的视频,所有人都同意进行数据收集。这与那些未经用户许可从互联网上抓取的数据集有着至关重要的区别。
数据是如何收集的
为了创建一个平行语料库 (即英语文本与 ASL 视频对齐) ,研究人员构建了一个专门的录制界面。口译员以逐句的方式阅读维基百科文章。
如图 2 所示,这种设置实现了源英语文本与生成的 ASL 视频之间的清晰映射。最终得到了一个包含超过 64,000 个视频片段的数据集。这种结构使研究人员能够精确分析特定的英语科学术语是如何在 ASL 中被翻译——或被指拼的。
指拼现象
数据集分析中最惊人的发现之一是指拼的巨大体量。在日常或叙事性 ASL 中,指拼通常只占内容的 3% 到 8%。而在 ASL STEM Wiki 中,这一数字急剧上升。

表 2 显示,在这个 STEM 语料库中,指拼占所有单词的 18.6% , 在非停用词 (实义词) 中更是占到了惊人的 31.5% 。 这一数据证实了最初的假设: 口译员严重依赖英语拼写来传达技术概念。
但他们到底在拼写什么?研究人员对数据进行了分析,对这些单词进行了分类。
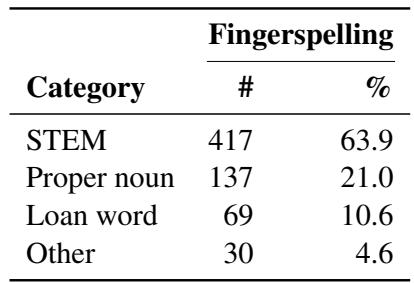
如表 3 所示,近 64% 的指拼单词是 STEM 专用术语。这证实了瓶颈确实在于技术词汇。
目标: 自动手语建议
该数据集的可用性开启了一项新的 AI 应用大门: 自动手语建议 。 其愿景是创建一个能够在实时翻译或准备过程中协助口译员的系统。

如图 1 所示,该工作流程分三步进行:
- 检测 : AI 分析视频,找出当口译员正在进行指拼的片段。
- 对齐 : AI 查看英语源句子,并找出与该指拼片段对应的哪个单词。
- 建议 : 利用识别出的英语单词,系统查询词典以找到合适的手语 (如果存在) ,以便建议在未来使用。
该论文重点关注为前两个步骤建立基线: 检测和对齐 。
模型架构
为了解决指拼检测问题,作者设计了一个神经网络,它同时处理视觉信息 (手语者的动作) 和文本信息 (英语句子) 。
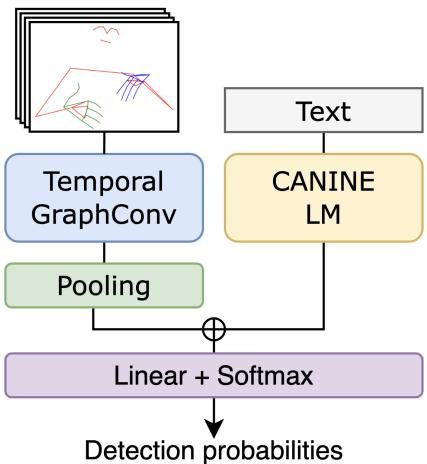
视觉处理: 时间图卷积网络 (Temporal Graph ConvNets)
对于视频输入,模型不查看原始像素。相反,它使用 MediaPipe 提取 2D“关键点”——本质上是手语者身体和双手的骨架。这降低了数据复杂性,同时保留了最重要的信息: 手指和手臂的运动。这些关键点被输入到 时间图卷积网络 中,该网络非常擅长理解身体部位之间的关系随时间的变化 (例如指拼特有的快速、复杂的手指运动) 。
文本处理: CANINE
对于文本输入,作者选择了 CANINE , 这是一种字符级语言模型。标准模型 (如 BERT) 将文本作为整个单词或子词处理。然而,指拼本质上是基于字符的 (L-I-K-E T-H-I-S) 。通过使用字符级模型,系统能更好地契合该任务的语言现实。
视觉特征和文本特征被拼接 (连接在一起) 并通过最后一层,该层预测视频的每一帧是否正在发生指拼。
训练策略: 对比学习
机器学习面临的最大挑战之一是对标记数据的需求。虽然 ASL STEM Wiki 数据量很大,但研究人员只有数据的一小部分具有具体的“指拼开始/结束”时间戳。为了解决这个问题,他们使用自监督对比学习来预训练模型。
简单来说,对比学习教导模型识别哪些数据片段属于同一类,哪些不属于,而不需要具体的标签。他们使用了两个目标:
- 时间对比 : 模型观察两个视频片段。它必须猜测它们是否来自同一个视频,如果是,哪一个先出现。这教会了模型理解 ASL 中的时间流和动作。
- 句子对比 : 模型观察一个视频片段和两个英语句子。它必须选择哪个句子与视频相匹配。这教会了模型视觉手语与书面文本之间的关系。
在这个预训练阶段之后,模型在较小的标注数据集上进行“微调”,以专门检测指拼。
实验与结果
为了衡量成功与否,研究人员使用了交并比 (Intersection over Union, IOU) 。 该指标检查 AI 预测的时间片段与人类标注员标记的实际时间片段的重叠程度。IOU 为 1.0 表示完美匹配;0.0 表示完全没有重叠。
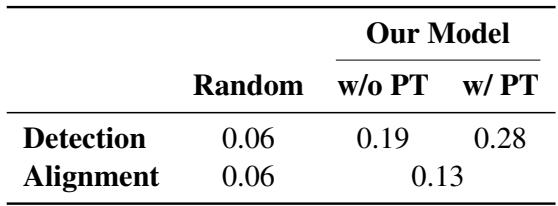
表 4 展示了结果。“Random”列代表基于指拼平均频率的基线猜测。
- 无预训练 : 模型的检测 IOU 达到 0.19。
- 有预训练 : 分数跃升至 0.28 。
虽然 0.28 的分数表明这是一项非常困难的任务 (还有很大的改进空间) ,但通过对比预训练获得的 47% 的提升是一个重大发现。这证明了让模型先“探索”未标记的数据有助于它更好地学习 ASL 的结构。
对于对齐任务 (将检测到的指拼与特定的英语单词匹配) ,作者使用了基于词频的启发式方法。其假设是,生僻词 (如“光合作用”) 比常用词 (如“the”) 更有可能被指拼。这种简单的方法达到了 0.13 的 IOU,虽然击败了随机基线,但也突显了将英语句法映射到 ASL 语法的复杂性。
挑战与未来方向
研究人员进行了误差分析,以了解模型为何会遇到困难。
- 检测误差 : 模型经常将快速的单手手语与指拼混淆。它在处理非常短的指拼单词 (如缩写) 或当手语者在打手语和拼写之间无缝切换时也很吃力。
- 对齐误差 : 启发式方法假设英语和 ASL 的词序相同,但这通常是错误的。ASL 有其独特的语法和句法。未来的模型需要能够“阅读”ASL 语法,而不是仅仅依赖英语句子结构。
结论
ASL STEM Wiki 论文代表了无障碍技术领域的基础性一步。通过创建和发布高质量的专业数据集,作者提供了训练下一代 AI 工具所需的原始素材。
这项工作强调了 AI 的一个关键用例: 不是取代人类口译员,而是增强他们的能力。如果 AI 能够识别指拼的技术术语并从词典中建议标准化手语,它就可以帮助口译员提供更流畅、概念更准确的翻译。对于大学生物课上的失聪学生来说,这种差异可能意味着是艰难地解码字母,还是真正理解生命科学的区别。