](https://deep-paper.org/en/paper/2411.06048/images/cover.png)
引言
想象一下你坐在餐桌旁。一位朋友问: “盐在哪儿?”你扫视了一下桌子回答道: “就在你杯子的右边。”这种互动看起来毫不费力。它只需要你识别物体,从朋友的视角理解场景,并清晰地表达出空间关系。
现在,想象一下向最先进的人工智能问同样的问题。你可能期望一个能通过律师资格考试或编写复杂代码的模型能轻松处理这种基本的方位指引。然而,最近的研究表明情况并非如此。
大型多模态模型 (Large Multimodal Models, LMMs) ,如 GPT-4o、Gemini 和 LLaVA,已经彻底改变了计算机视觉和自然语言处理的交叉领域。它们可以描述复杂的图像,创作关于日落的诗歌,并回答有关视觉内容的详细问题。然而,当涉及到空间推理——即理解物体之间相对位置的能力时,这些模型往往表现出令人惊讶的脆弱性。
以此为例:

如图 1 所示,即使是像 GPT-4o 这样的先进模型,在一个看似简单的任务上也可能失败: 从特定视角识别自行车的确切位置。虽然模型正确地识别出了自行车,但它未能正确转换出相对于图中女性的空间关系。
在这篇文章中,我们将探讨一篇题为 *“An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models” (对大型多模态模型空间推理能力的实证分析) * 的研究论文。研究人员 Shiri 等人对顶尖 LMM 处理空间任务的方式进行了全面审计。他们构建了一个新的基准测试,分析了故障点,并发现虽然这些模型擅长检测物体,但在对物体进行推理时往往是“空间盲”的。
我们将拆解他们的新数据集 Spatial-MM , 研究他们利用合成视觉线索来提高模型性能的巧妙方法,并分析为什么通常被视为推理“灵丹妙药”的“思维链 (Chain of Thought) ”提示法可能对空间任务不起作用。
背景: AI 的空间能力缺失
在深入研究方法论之前,我们需要了解背景。LMM 是在海量的图像-文本对数据集上训练的。它们学会了将“猫”这个词与猫的视觉特征联系起来。然而,像“在…左边”、“在…下面”、“面向”或“在…后面”这样的空间介词则更为抽象。它们不仅取决于物体本身,还取决于上下文、观察者的视角以及多个物体之间的关系。
以前的基准测试试图测试这一点,但通常存在局限性:
- 镜头偏差 (Camera Bias) : 大多数数据集假设“观察者”是相机。它们很少从图像内部人物的视角提问 (例如,“从司机的视角看,行人在哪里?”) 。
- 缺乏复杂性: 许多问题只是简单的单步查询。它们不测试多跳推理 (multi-hop reasoning) (例如,“找到杯子,然后找到它左边的物体,告诉我那个物体是什么颜色”) 。
研究人员认为,要真正理解 LMM 的空间能力,我们需要一个更干净、更严谨、专门针对这些弱点的基准测试。
核心方法: 构建 Spatial-MM
为了填补这些空白,作者引入了一个名为 Spatial-MM 的新基准。该数据集旨在成为空间感知能力的终极测试。它由两个不同的子集组成: Spatial-Obj 和 Spatial-CoT 。
1. Spatial-Obj: 测试基本关系
这个子集包含 2,000 个专注于一个或两个物体的多项选择题。目的是评估模型是否理解 36 种不同的空间关系 (如在下面、附着在、背对、右上) 。
该数据集不仅仅是照片的随机集合。研究人员将图像分类为已知对 AI 具有挑战性的特定视觉模式,例如:
- 物体定位 (Object Localization) : X 在哪里?
- 朝向与方位 (Orientation and Direction) : 长颈鹿是面向左边吗?
- 视点 (Viewpoints) : 从俯视或不同角度看物体。
- 位置上下文 (Positional Context) : 两个移动物体之间的关系。

图 2 展示了这些模式的多样性。注意“视点”示例 (右上角) 。问题询问是从哪个视点看到马克杯的。这要求模型从二维图像中在脑海里构建三维空间模型——这是一项认知要求很高的任务。
2. Spatial-CoT: 测试多跳推理
第二个子集 Spatial-CoT 专注于思维链 (Chain of Thought, CoT) 。 在许多逻辑任务中,要求 AI “一步一步地思考”可以提高准确性。研究人员想知道这是否适用于空间推理。
他们创建了 310 个多跳问题,答案需要一系列推理步骤。例如:
- 识别穿花裙子的女人。
- 识别她的朝向。
- 确定她右边是什么。
至关重要的是,研究人员不仅想要最终答案;他们还要验证推理路径是否正确。他们将推理步骤标记为空间 (S) (例如,“人在车前面”) 或非空间 (NS) (例如,“拿着叉子的女人”) 。这就允许对模型失败的地方进行细粒度的诊断。
数据增强: 给模型“提示”
这篇论文最有趣的贡献之一是提出了这样一个假设: LMM 失败是因为它们缺乏显式的视觉定位 (visual grounding) 。它们看得到像素,但在回答之前可能没有显式地“框出”物体或映射它们的关系。
为了验证这一点,作者开发了管道,向模型的提示词中注入两种类型的“提示”: 边界框 (Bounding Boxes) 和场景图 (Scene Graphs) 。
管道 1: 边界框生成
在这个管道中,系统从问题中提取关键物体,并要求一个辅助模型 (如 GPT-4o) 生成这些物体的边界框坐标 [x_min, y_min, x_max, y_max]。然后将这些坐标作为提示的一部分反馈给 LMM。
管道 2: 场景图生成
在这里,模型被要求生成一个“场景图”——即关系的结构化文本描述 (例如,男人 --[在...右边]--> 桌子) 。这迫使模型在尝试回答问题之前明确表达空间布局。
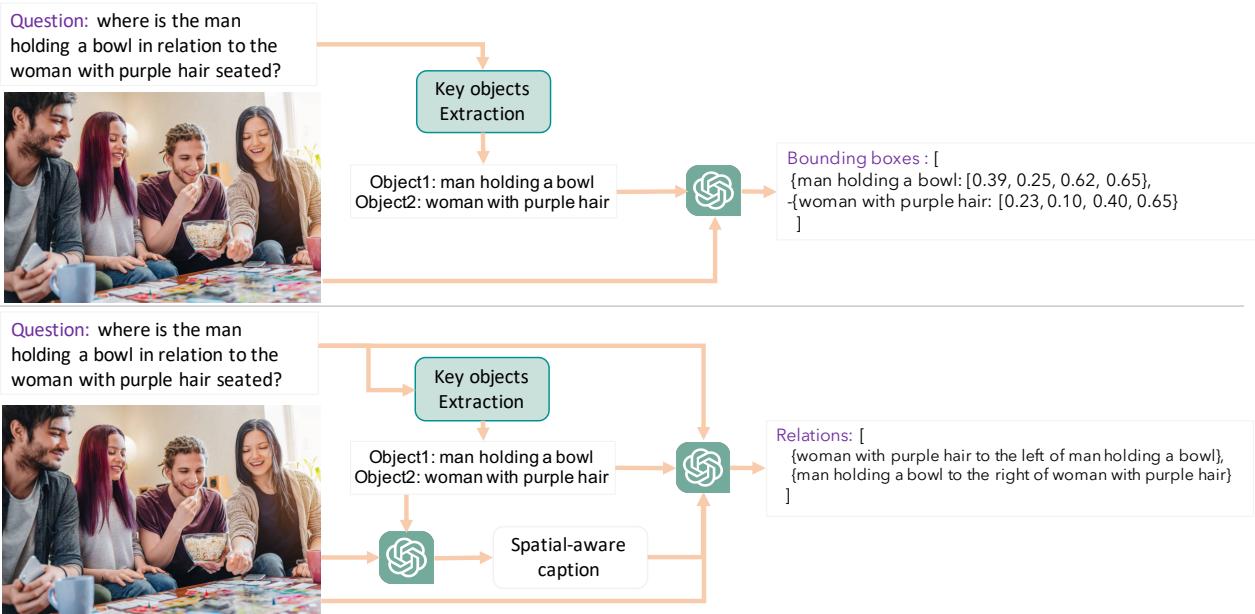
如图 6 所示,这些管道充当预处理步骤。上面的路径生成精确的坐标,而下面的路径生成语义关系。
有趣的是,研究人员发现使用 (由 GPT-4o 生成的) 合成边界框通常比使用旧数据集中的人工标注真值框更有效。

图 7 解释了原因。遗留数据集中的真值框 (左) 可能比较松散或不准确。现代 LMM 生成的合成框 (右) 通常更紧密、更干净。这表明,虽然 LMM 擅长检测 (找到框) ,但它们在推理 (解释框之间的关系) 方面很吃力。
实验与结果
研究人员测试了四个主要模型: GPT-4o、GPT-4 Vision、Gemini 1.5 Pro 和 LLaVA-1.5 。 他们使用了 Spatial-MM 基准和 GQA-spatial 数据集。结果提供了一些关键的见解。
发现 1: 视觉提示显著提升性能
第一个主要发现是,LMM 在空间推理方面并非无可救药;它们只是需要帮助。当研究人员用边界框 (bbox) 或场景图 (SG) 增强提示时,准确率飙升。
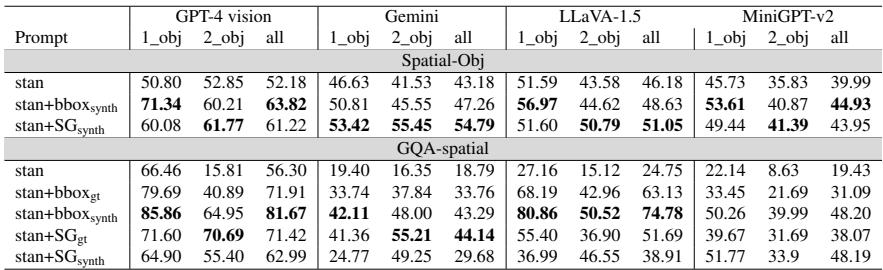
表 1 显示了巨大的提升。例如,在 GQA-spatial 数据集上,提供合成边界框 (stan+bboxsynth) 将 GPT-4 Vision 的准确率从 56.30% 提高到了 81.67% 。
关键结论: 边界框对于简单的单物体问题 (定位) 往往更有效,而场景图对于双物体问题 (关系) 更有效。
发现 2: “人类视角”盲区
大多数计算机视觉数据集都是“以相机为中心”的。它们询问关于图像中什么是左或右的问题。但现实世界的应用通常需要“以人类为中心”的推理 (例如,机器人助手需要知道你的左边是什么) 。
研究人员明确比较了这两种视角。
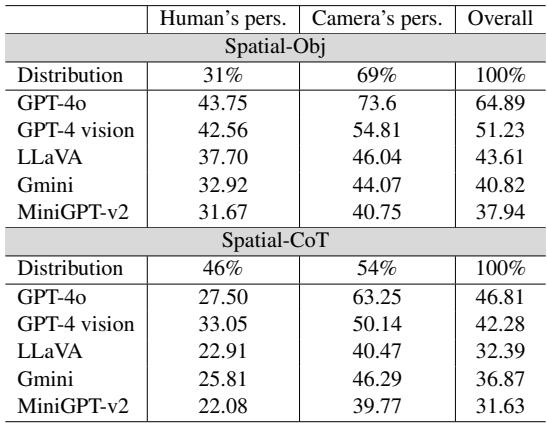
表 2 显示了鲜明的对比。当被要求从图像内部的人类视角进行推理时,所有模型的表现都明显变差。最强的模型 GPT-4o 从相机视角的 73.6% 准确率下降到人类视角的 43.75% 。 这表明 LMM 难以掌握旋转心理视角所需的“心智理论 (Theory of Mind) ”。
发现 3: 思维链 (CoT) 在空间任务中失效
在基于文本的逻辑谜题中,要求 AI “一步一步地思考” (思维链) 是提高结果的标准技术。然而,作者发现,对于空间多跳问题,CoT 往往会降低性能或没有任何好处。
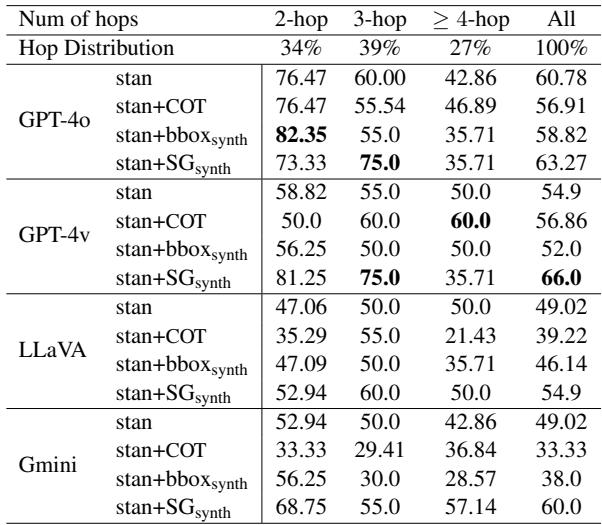
表 3 比较了标准提示 (stan) 与 CoT (stan+COT) 。对于 GPT-4o,使用 CoT 使准确率从 60.78% 下降到 56.91% 。
为什么?研究人员分析了生成的推理路径,发现模型经常“幻觉”出空间步骤。它们可能会正确识别物体 (非空间步骤) ,但在中间阶段未能确定正确的关系 (空间步骤) ,从而导致整条推理链偏离方向。
下面的错误分析进一步详细说明了这一点:
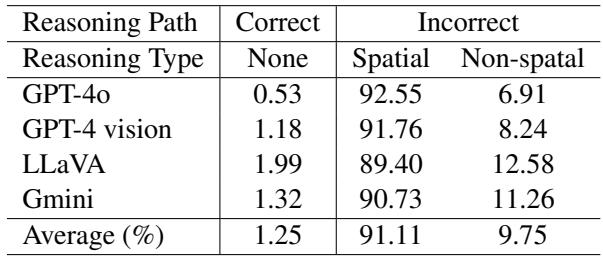
表 5 显示,当模型失败时, 91.11% 的情况是由于错误的空间推理步骤。非空间错误 (如将汽车识别为卡车) 很少见。模型知道它们在看什么,但在物体之间的空间导航中迷失了方向。
发现 4: 对扰动的脆弱性
为了证明模型往往是在猜测而不是推理,研究人员对 GQA-spatial 数据集进行了“扰动”。他们对文本选项做了一些小的改动,例如:
- 添加“以上都不是”。
- 在选项中交换“左”和“右”。
- 更改物体名称。
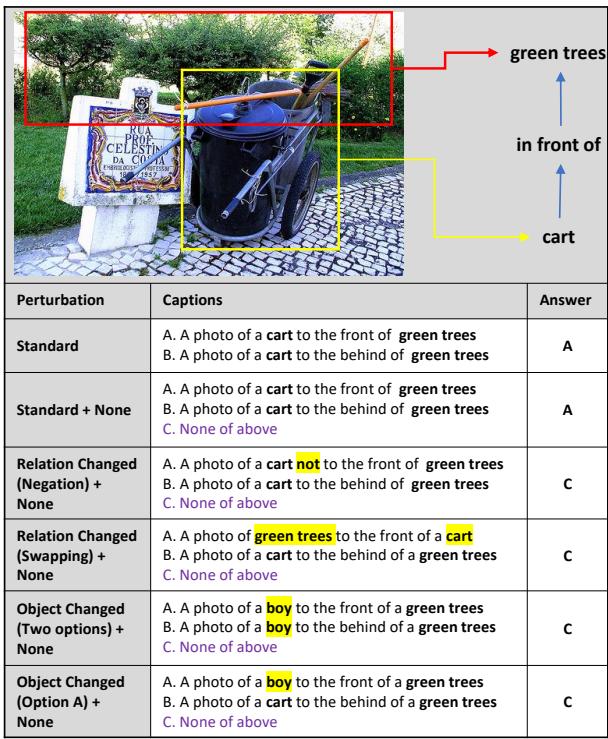
如果一个模型真正理解图像,这些文本变化不应该让它困惑。然而,结果却很混乱。
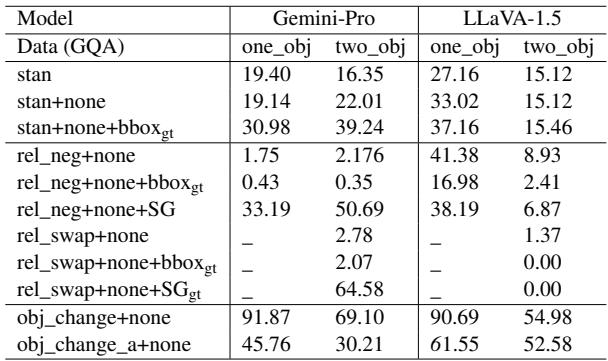
表 6 显示,简单的变化,如否定关系 (添加“not”) ,会导致性能大幅下降。例如,当引入否定时,Gemini-Pro 在单物体问题上的准确率从 19.40% 暴跌至 1.75% 。 这表明模型依赖于图像和文本之间浅层的模式匹配,而不是对空间逻辑的稳健理解。
关系分布
最后,值得注意的是数据本身的偏差。研究人员分析了其数据集中空间术语的分布。
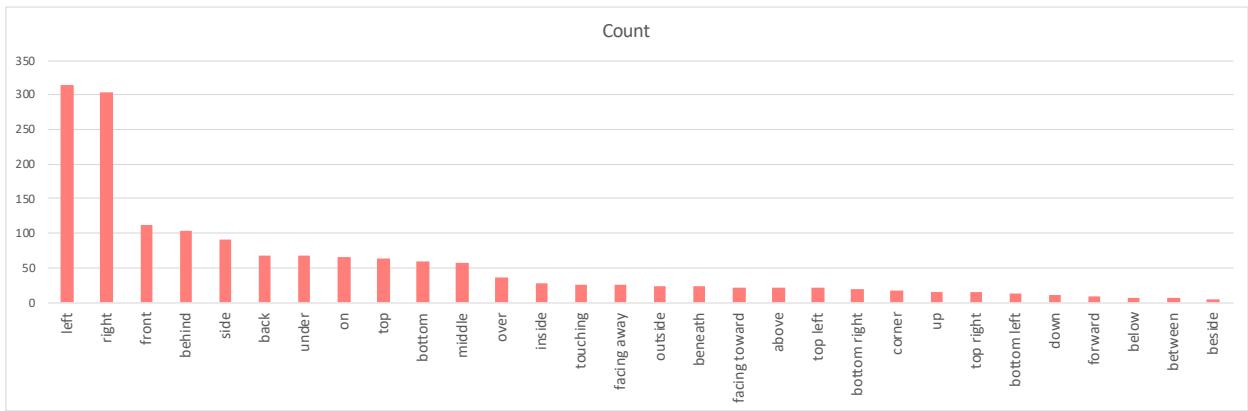
如图 8 所示,“左”和“右”的概念在数据集中占主导地位。更复杂的 3D 关系,如“背对”或“在下面”,频率较低。这种数据不平衡部分解释了为什么模型在复杂的 3D 推理方面表现不佳——与简单的 2D 横向位置相比,它们在训练中看到的此类数据实在太少了。
结论与启示
这篇题为 “An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models” 的论文为 AI 社区敲响了警钟。虽然 LMM 编写代码或描述画作的能力让我们眼花缭乱,但它们对物理空间的掌握仍然是初级的。
关键要点:
- 物体检测 \(\neq\) 空间推理: LMM 擅长寻找物体 (检测) ,但不擅长理解它们之间的几何关系。
- 视觉支架有效: 我们不需要重新训练现有模型,只需通过边界框和场景图丰富其提示词,就能显著提高性能。这种“视觉支架”弥合了像素数据与语义语言之间的鸿沟。
- 视角转换很难: 无法可靠地采用图像中的人类视角,限制了 LMM 目前在机器人和导航领域的应用。
- CoT 不是银弹: 标准的一步一步提示技术并不能自动解决空间难题;事实上,它们可能会诱发幻觉。
下一步是什么? 这项研究指出,我们需要更好的训练数据,强调 3D 关系和以人类为中心的视角。它还表明,未来的 LMM 架构可能需要专门的空间处理模块,而不是完全依赖语言模型“说出”视觉地图。
对于进入该领域的学生和研究人员来说, Spatial-MM 提供了一个强大的新演练场来测试这些能力。解决“左与右”的问题看似简单,但它是让 AI 真正理解物理世界的最后前沿之一。