](https://deep-paper.org/en/paper/2412.04140/images/cover.png)
扩散模型为何会死记硬背: 几何视角与修复之道
生成式 AI 经历了飞速的发展,Stable Diffusion 和 Midjourney 等扩散模型能够通过简单的文本提示创造出令人惊叹的视觉效果。然而,在这些令人印象深刻的能力背后,隐藏着一个顽固且潜在危险的问题: 记忆 (Memorization) 。
偶尔,这些模型生成的并不是新图像,而是机械地吐出训练数据的精确副本。这带来了重大的隐私风险 (例如泄露医疗数据或私人照片) 和版权挑战。虽然研究人员提出了各种启发式方法来检测这一问题,但我们一直缺乏一个统一的框架来从数学上解释它为什么会发生,以及在模型的学习分布中它发生于何处。
在 ICML 2025 发表的一篇最新论文中,研究人员引入了一个几何框架,通过概率地形的“锐度 (sharpness) ”来分析记忆现象。他们发现,被记忆的样本存在于概率分布中尖锐、狭窄的峰值处。利用这一洞察,他们开发了一种方法,可以在图像生成过程开始之前就检测出记忆现象,并提出了一种无需重新训练模型即可防止该问题的策略。
在这篇文章中,我们将剖析记忆的几何结构,探索“锐度”背后的数学原理,并解释如何引导扩散模型生成更安全、更具创造性的输出。
核心直觉: 概率景观
要理解记忆现象,我们首先必须了解扩散模型是如何看待数据的。扩散模型学习一个概率分布 \(p(\mathbf{x})\)。高概率区域对应逼真的图像,而低概率区域对应噪声或不真实的数据。
你可以将这个学习到的分布想象成一个地形景观。
- 泛化样本 (有创意的、新颖的图像) 位于宽阔、平滑的山丘上。这里有变化的余地;向任何方向稍微移动一点,仍然能得到一张有效的、逼真的图像。
- 记忆样本 (训练数据的精确副本) 位于尖锐、狭窄的山峰上。模型对这些特定点进行了“过拟合”,造成了概率密度的急剧飙升。
研究人员提出,通过测量这个景观的曲率 (锐度) ,我们可以区分创造性和照搬照抄。
背景知识: 得分函数与海森矩阵
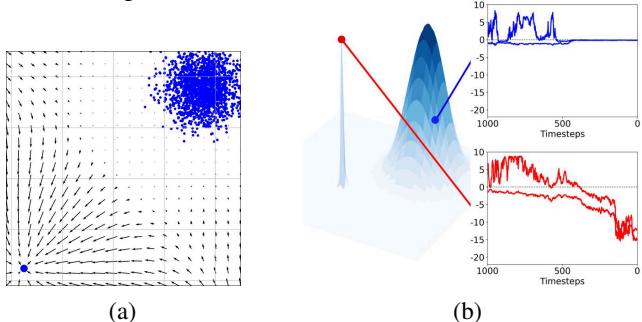
扩散模型通过跟随“得分函数 (score function) ”来生成数据,该函数指向数据密度更高的方向。逆扩散过程由随机微分方程 (SDE) 控制,如下所示:
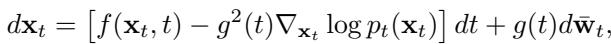
在这里,\(\nabla_{\mathbf{x}_t} \log p_t(\mathbf{x}_t)\) 是得分函数 。 它告诉模型应该朝哪个方向移动以去除图像噪点。
为了测量锐度,我们需要查看得分函数的导数,即海森矩阵 (Hessian Matrix) (\(H\)) 。
- 得分 (Score) 是地形的斜率。
- 海森矩阵 (Hessian) 描述了地形的曲率。
在数学上,海森矩阵的特征值告诉我们局部的几何形状。大的负特征值表示尖峰 (凹性) ,意味着数据点是孤立的,很可能是被记忆的。小的或正的特征值表示更平坦、更光滑的区域,暗示了泛化能力。
可视化记忆
作者使用一个简单的 2D 玩具实验和 MNIST 数字验证了这个几何假设。
在上图中,模型被训练为记忆数字“9” (通过在数据集中重复它) ,同时泛化数字“3”。
- 右上 (初始步骤) : 即使在生成过程的最开始 (纯噪声阶段) ,“记忆”轨迹 (红色) 也显示出与“泛化”轨迹 (蓝色) 不同的特征值特性。
- 右下 (最终步骤) : 差异变得非常明显。被记忆样本的特征值分布包含一条长长的尾巴,由大的负值组成。这证实了记忆样本位于尖锐的几何峰值之上。
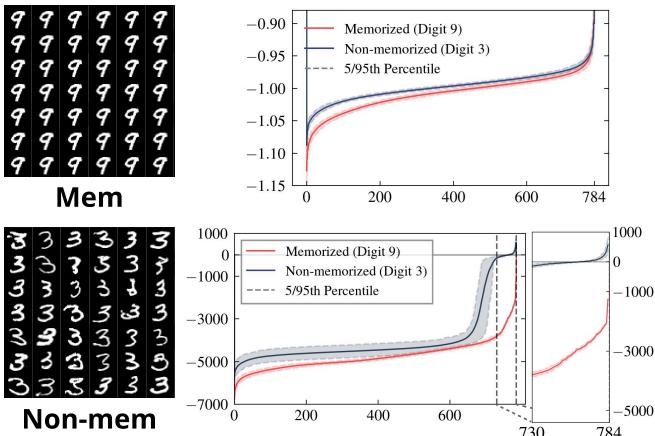
这种行为不仅限于简单的数据集。我们在复杂的模型中也看到了完全相同的演变过程。
如上图 Figure 1(b) 所示,随着生成过程的进行 (\(t \to 0\)) ,被记忆样本 (红线) 深陷负特征值区域,而非记忆样本 (蓝线) 则保持相对平坦。
高效地测量锐度
对于高维图像 (如 Stable Diffusion 生成的 512x512 像素输出) ,计算完整的海森矩阵在计算上是极其耗时的。它需要计算数百万个参数的二阶导数。我们需要一条捷径。
得分范数代理 (The Score Norm Proxy)
研究人员利用了一个巧妙的数学恒等式,将得分的范数 (梯度的幅度) 与海森矩阵的迹 (特征值之和) 联系起来。
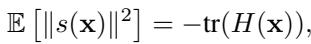
简单来说,斜率陡峭的区域 (高得分范数) 通常对应曲率尖锐的区域 (高负海森迹) 。这使我们能够使用得分范数——这很容易计算——作为锐度的代理指标。
重新解读现有指标
这个几何框架为以前的启发式方法提供了理论支撑。例如, Wen 等人 (2024) 提出的一种流行检测指标,测量的是条件得分 (有文本提示) 与无条件得分 (无提示) 之间的差异:
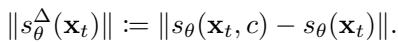
为什么这个方法有效?研究人员证明,该指标实际上有效地测量了由文本提示引入的锐度差异 。
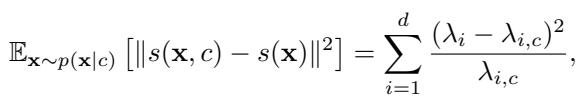
如上式所示,Wen 的指标在数学上等同于条件海森矩阵和无条件海森矩阵的特征值 (\(\lambda\)) 平方差之和。
我们可以在 Figure 5 中直观地看到这种差距:
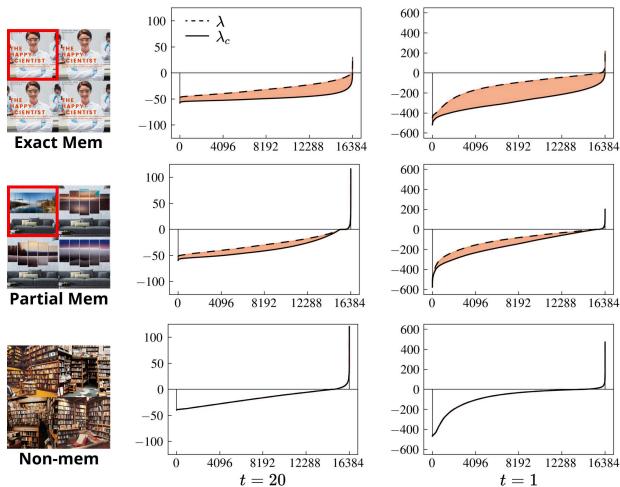
对于被记忆的样本 (Exact Mem) ,条件海森矩阵 (\(\lambda_c\)) 与无条件海森矩阵 (\(\lambda\)) 显著偏离。文本提示有效地强迫模型进入对应于训练数据的尖锐、狭窄的山谷。对于非记忆样本,条件调节并不会剧烈改变地形的曲率。
基于海森矩阵放大的早期检测
虽然 Wen 的指标在中间步骤效果良好,但在扩散过程的最开始 (\(t=T\)) 进行检测是很困难的。在这个阶段,图像几乎是纯噪声,概率景观几乎是各向同性的 (各个方向都均匀) 。“锐度”信号非常微弱。
为了解决这个问题,作者提出了一种新的指标来“放大”曲率信号。他们不再仅仅查看得分,而是查看得分乘以海森矩阵 。
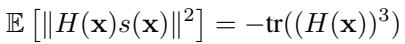
通过将得分投影到海森矩阵上,他们放大了对应于大特征值 (最尖锐方向) 的分量。由此产生的检测指标是:
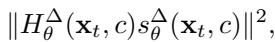
这个指标就像曲率的放大镜。它使得被记忆样本和非记忆样本之间的区别即使在第一个时间步也显而易见。
检测结果
这个新指标的结果令人印象深刻。Table 1 比较了在 Stable Diffusion 上的检测性能 (AUC) 。
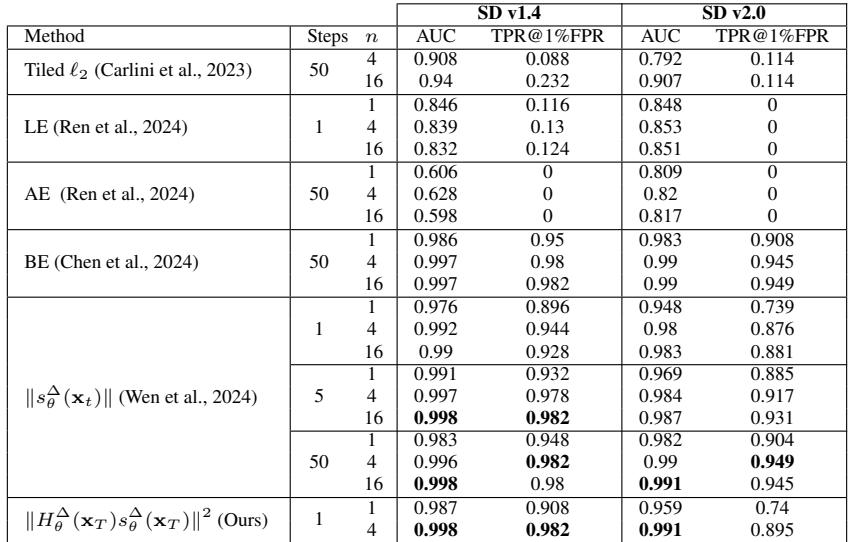
所提出的指标 (最后一行) 仅利用第 1 步 (\(t=T-1\)) 可用的信息就达到了 0.998 的 AUC。这意味着我们可以在模型生成图像的任何一个像素之前,就标记出潜在的版权侵犯风险。
缓解策略: 感知锐度的初始化 (SAIL)
如果我们可以检测到特定的起始噪声向量 \(\mathbf{x}_T\) 会导致记忆图像,我们能不能简单地换一个起点?
这就是 SAIL (Sharpness-Aware Initialization for Latent Diffusion,潜在扩散的感知锐度初始化) 的前提。
SAIL 的逻辑
由于扩散 ODE 求解器是确定性的,初始噪声 \(\mathbf{x}_T\) 完全决定了最终图像。记忆图像源于位于潜在空间“尖锐”区域的初始化噪声。
SAIL 在推理阶段解决一个优化问题。它搜索一个新的起始噪声向量 \(\mathbf{x}_T\),满足:
- 最小化锐度 (使用基于海森矩阵的指标) 。
- 保持接近标准高斯分布 (以确保图像保持逼真) 。
目标函数为:
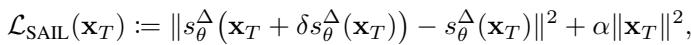
因为计算精确的海森矩阵很慢,他们使用了有限差分近似,使得该过程足够高效,可用于实时应用:
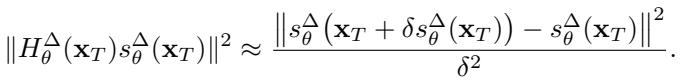
结果: 质量 vs. 安全
大多数现有的缓解方法试图通过改变文本提示 (例如添加随机标记) 或抑制注意力机制来解决记忆问题。但这往往会破坏图像,显著改变主体或风格。
SAIL 则不同,它只改变噪声。它保持提示词和模型权重完全不变。
定量结果:

在 Figure 6 (左) 中,我们可以看到 SAIL (红/粉线) 实现了最佳平衡: 低记忆分数 (SSCD) 和高图像-文本对齐度 (CLIP) 。
定性结果:
视觉上的差异是惊人的。在下面的例子中,目标是根据一个原本会触发记忆输出的提示词 (例如特定的名人照片或电影场景) 生成图像。
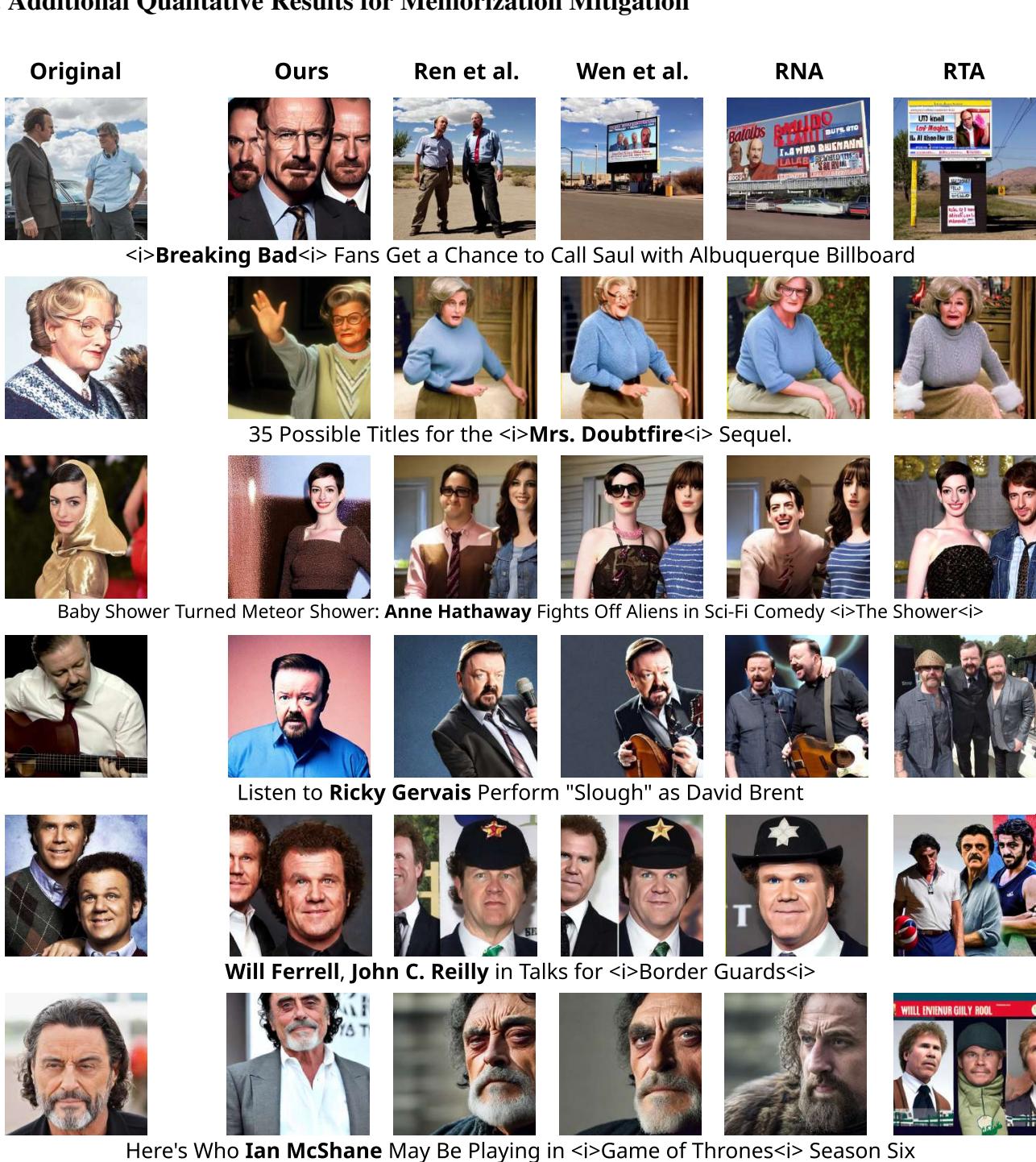
- Original (原始) : 显示了被记忆的训练图像。
- Ours (SAIL) : 生成了正确主体 (例如 Anne Hathaway, Ricky Gervais) 的高质量图像,尊重了提示词,但不是训练数据的副本。
- Baselines (Ren et al., Wen et al. 等) : 为了试图掩盖记忆,往往会扭曲面部、将背景更改为不相关的物体,或破坏构图。
结论
这项研究提供了一种思考生成式 AI 的全新方式。记忆不仅仅是数据集的一个“缺陷”;它是模型学习到的概率地形的一个几何特征。
通过利用海森矩阵及其特征值对这种几何结构进行数学表征,作者提供了:
- 一个理论解释 , 说明了为什么现有指标有效。
- 一个卓越的检测指标 , 可以在生成的最初步骤识别隐私风险。
- SAIL , 一种从源头 (初始化噪声) 解决问题而不是在提示词上做表面修补的缓解策略。
随着我们迈向在医疗保健和创意产业等敏感领域部署生成模型,像 SAIL 这样的工具对于确保这些系统的安全性、隐私性和真正的创造力将至关重要。