](https://deep-paper.org/en/paper/2412.06877/images/cover.png)
想象一下,你试图通过让机器人观看数小时人们在厨房里走动的视频片段,来教会它如何“煮一杯咖啡”。这些视频没有字幕,没有奖励反馈,也没有任何解释。机器人看到一个人拿起杯子,但它不知道为什么。是为了清洗杯子?是为了移动它?还是煮咖啡的第一步?
这个场景凸显了当今人工智能领域的一个巨大瓶颈。我们需要能够理解并在复杂环境中执行自然语言指令 (如“预订餐厅”或“导航到蓝色房间”) 的智能体。然而,现有的方法通常需要两样昂贵的东西: 要么是海量的人工标记数据 (每一个动作都有注释) ,要么是在现实世界中进行数百万次练习的能力 (这既缓慢又危险) 。
在最近一篇题为 “TEDUO: Teaching the Environment Dynamics from Unlabeled Observations” (TEDUO: 从无标签观测中教授环境动力学) 的论文中,研究人员 Thomas Pouplin、Katarzyna Kobalczyk、Hao Sun 和 Mihaela van der Schaar 提出了一个突破性的解决方案。他们介绍了一种流水线方法,通过利用强化学习 (RL) 和大语言模型 (LLM) 之间的协同作用,允许 AI 智能体从无标签的离线数据中学习鲁棒的、基于语言条件的策略。
在这篇深度文章中,我们将详细拆解 TEDUO 的工作原理、它的重要性,以及它如何在无需昂贵监督的情况下教会 LLM 关于物理环境的“常识”。
核心问题: 落地鸿沟 (The Grounding Gap)
要理解为什么需要 TEDUO,首先需要审视我们目前最强工具的局限性: 强化学习 (RL) 和大语言模型 (LLM) 。
强化学习非常擅长通过最大化奖励信号来掌握特定任务 (如国际象棋或 Dota 2) 。然而,RL 智能体很难泛化。如果你训练一个 RL 智能体“打开红色的门”,当你要求它“打开蓝色的门”时,除非它针对该特定目标接受过显式训练,否则通常会完全失败。
大语言模型 (LLM) , 如 GPT-4 或 Llama,则恰恰相反。它们拥有惊人的通用知识。它们知道“打开门”需要靠近门。然而,它们缺乏落地能力 (Grounding) 。 LLM 可能知道钥匙的概念,但它无法直观地理解网格世界 (GridWorld) 环境中的具体物理规则——比如你不能穿墙而过,或者你必须面向物体才能捡起它。
挑战在于将 RL 的落地能力与 LLM 的泛化能力结合起来,同时仅使用廉价的无标签数据。
TEDUO: 三步走的解决方案
TEDUO 代表 Teaching the Environment Dynamics from Unlabeled Observations (从无标签观测中教授环境动力学) 。 该方法旨在利用随机交互的“哑”数据集,将其转化为智能的、通用的智能体。
研究人员提出了一个顺序流水线,利用 LLM 扮演两个截然不同的角色: 首先作为清洗和标记数据的工具,其次作为最终智能体的大脑。
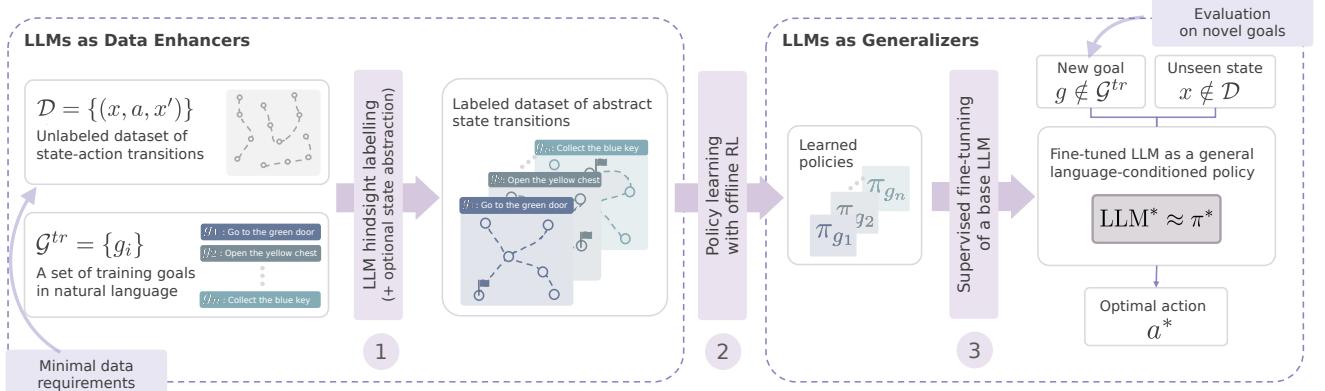
如图 1 所示,该流水线包含三个不同的阶段:
- 构建可解的 MDP (马尔可夫决策过程) : 利用 LLM 对原始数据进行标记并简化世界。
- 离线策略学习: 使用经典 RL 从标记数据中学习特定技能。
- LLM 有监督微调: 教会基础 LLM 模仿 RL 专家,有效地将 RL 的“肌肉记忆”转移到 LLM 的“推理大脑”中。
让我们详细分解这些步骤。
第 1 步: 从噪声中理出头绪 (数据增强)
TEDUO 的输入是一个观测数据集 \(\mathcal{D}\): 包含 (状态,动作,下一状态) 的三元组。关键在于,这些数据是无标签的。我们不知道数据中的智能体试图达成什么目标,或者他们是否只是在随机行动。
为了从中学习,我们需要知道两件事:
- 发生了什么? (事后标记)
- 什么才是重要的? (状态抽象)
利用代理奖励进行事后标记
标准 RL 需要奖励函数来学习。由于数据没有奖励,TEDUO 需要合成奖励。系统获取一个可能的目标列表 (例如,“捡起红球”) ,并检查数据集中的任何状态是否满足该目标。
使用庞大的 LLM 来检查数百万帧数据集中的每一个状态将是非常昂贵且缓慢的。作者通过训练一个轻量级的代理奖励模型 (Proxy Reward Model) 来解决这个问题。他们利用强大的 LLM 标记一小部分数据,然后训练一个小型、快速的神经网络来预测数据集其余部分的标签。这使他们能够高效地对整个数据集进行“事后标记”。
状态抽象
原始环境充满了噪声。在视觉网格世界中,地板的颜色或远处无关物体的位置可能会混淆智能体。这就是所谓的“维度灾难”。
TEDUO 采用了一种可选但非常有效的基于 LLM 的状态抽象 。 研究人员向 LLM 提问: “如果目标是‘捡起蓝色钥匙’,这个列表中哪些特征是相关的?”
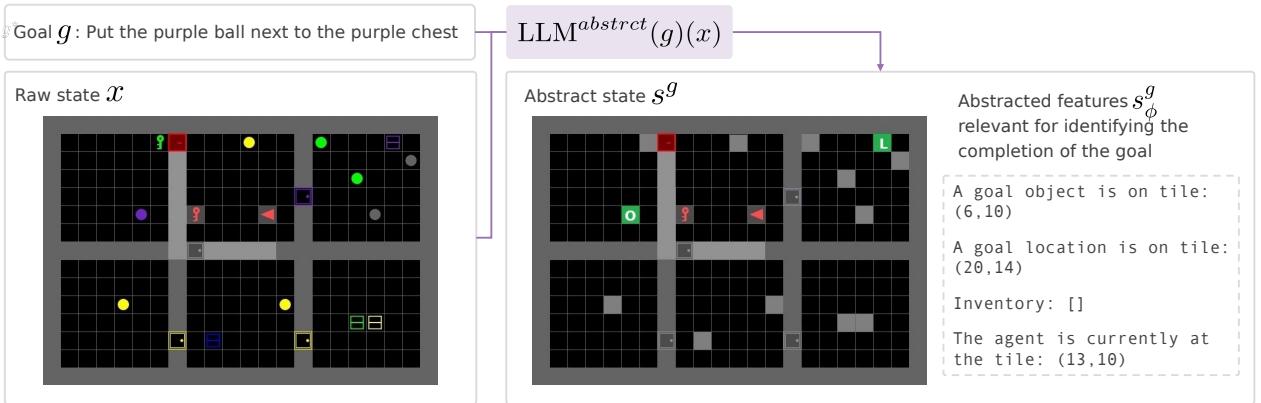
如图 2 所示,LLM 充当了过滤器。如果目标是与紫球互动,LLM 会建议系统忽略打开的门的颜色或无关的独特物体,实际上将它们视为墙壁或通用障碍物。
这将高维、嘈杂的状态 \(x\) 转换为干净、抽象的状态 \(s^g\)。这种降维使得随后的强化学习步骤速度更快,数据效率更高,因为 RL 算法不会浪费时间分析无关的像素。
第 2 步: 培养“专家”直觉 (离线 RL)
此时,我们拥有了一个已过滤掉无关信息的标记数据集。现在,对于每一个训练目标 (例如,“去红色房间”) ,我们将数据视为一个特定的马尔可夫决策过程 (MDP) 。
研究人员使用离线强化学习 (Offline RL) ——具体来说是表格 Q-learning 或深度 Q-learning——来求解这些 MDP。
这里的目的不是创建最终的智能体,而是创建一个“老师”。算法处理数据以找到针对训练集中存在的特定目标的最佳策略 \(\pi^g\)。
需要注意的是,这些策略是脆弱的 。 一个严格训练为“捡起红球”的 Q-learning 智能体,如果没见过“捡起蓝色钥匙”的奖励信号,就无法泛化到该任务。然而,这些智能体是落地的——对于它们已知的任务,它们完全理解环境的物理规则。
第 3 步: 知识迁移 (LLM 微调)
这是 TEDUO 最具创新性的部分。我们现在拥有一组针对特定目标的“专家”策略,但我们要的是一个能处理任何目标的智能体。
研究人员创建了一个新的监督数据集 \(\mathcal{D}^{SFT}\)。他们利用第 2 步中的专家策略生成“完美”轨迹。实际上,他们是在问 RL 专家: “如果你在状态 \(S\),为了实现目标 \(G\),绝对最佳的动作是什么?”
这产生了一个包含 (目标,状态,最优动作序列) 的数据集。
\[ \begin{array} { r l } & { \mathcal { D } ^ { S F T } : = \{ ( g , s _ { 0 } ^ { g } , [ a _ { 0 } ^ { * , g } , \ldots , a _ { n _ { g } } ^ { * , g } ] ) : g \in \mathcal { G } ^ { t r } , \ s _ { 0 } ^ { g } \in \mathcal { D } ^ { g } , } \\ & { \qquad a _ { t } ^ { * , g } = \underset { a \in \mathcal { A } } { \arg \operatorname* { m a x } } \pi ^ { g } ( a \mid s _ { t } ^ { g } ) , } \\ & { \qquad s _ { t + 1 } ^ { g } = \underset { s \in \mathcal { S } ^ { g } } { \arg \operatorname* { m a x } } \hat { P } ^ { g } ( s | s _ { t } ^ { g } , a _ { t } ^ { * , g } ) \} , } \\ & { \qquad n _ { g } s . t . R _ { \hat { \theta } } ( s _ { n _ { g } + 1 } ^ { g } ; g ) = 1 \} , } \end{array} \]然后,他们使用这个数据集对预训练的 LLM (如 Llama-3) 进行有监督微调 (SFT) 。
为什么这样做有效?
- 先验知识: LLM 已经理解了自然语言的同义词、组合性 (理解“红球”和“蓝钥匙”是相似的概念) 以及高层规划。
- 落地能力: 通过在 RL 轨迹上进行训练,LLM 学习了环境的具体机制 (例如,“如果面前有墙,我不能向前移动”) 。
结果是一个单一模型,它既拥有 LLM 的语言灵活性,又拥有 RL 智能体的物理落地能力。
实验结果: 它真的有效吗?
作者在 BabyAI (一个复杂的网格世界环境) 和 WebShop (一个电子商务模拟环境) 上对 TEDUO 进行了评估。他们提出了几个关键问题。
Q1: 它能泛化到新目标吗?
这是问题的核心 (圣杯) 。研究人员在 500 个目标上训练模型,然后在 100 个完全陌生、涉及不同物体和颜色的目标上进行测试。
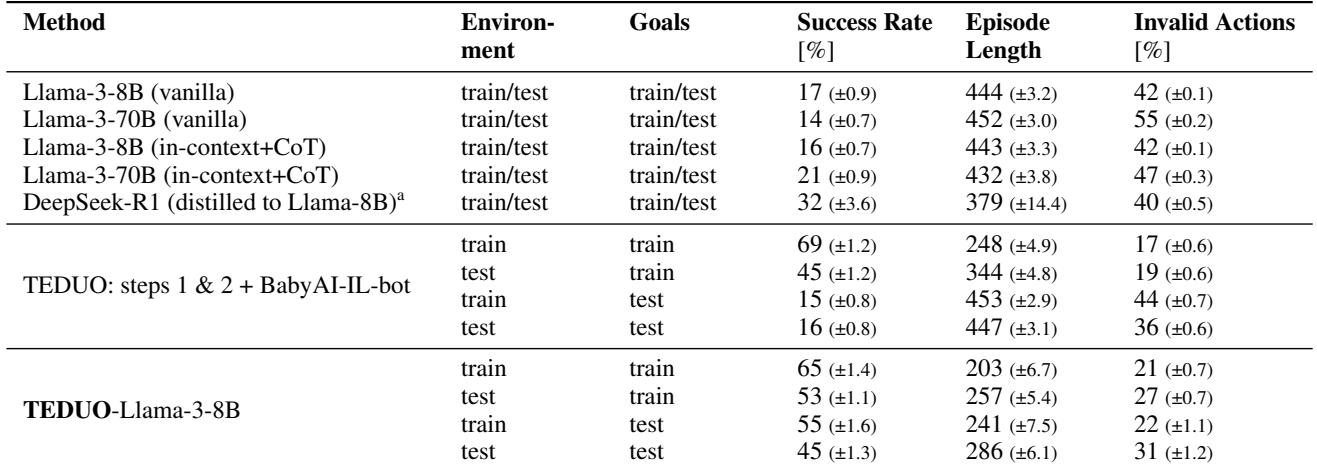
表 1 揭示了惊人的结果:
- Vanilla LLMs (Llama-3-8B/70B) 表现糟糕 (14-17% 的成功率) 。它们根本不懂环境规则。
- TEDUO 在未见过的测试目标上达到了 45% 的成功率 。
- BabyAI-IL-bot (基线) : 在相同数据上训练的标准模仿学习基线在训练目标上表现尚可 (69%) ,但在测试目标上暴跌至 16% 。 它只是记住了训练数据,却未能学到底层逻辑。
这证明 TEDUO 不仅仅是死记硬背解决方案;它学会了如何解决问题,从而能够适应新的指令。
Q2: 整个流水线都是必要的吗? (消融实验)
你可能会问: “我们真的需要 RL 步骤吗?不能直接克隆数据吗?”
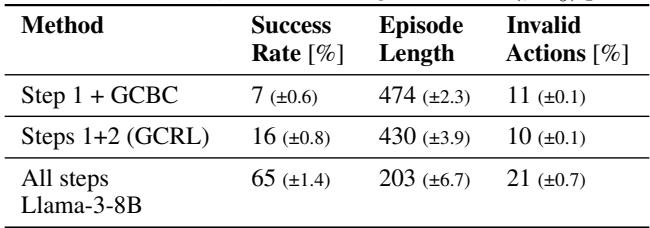
表 2 展示了细分结果。
- Step 1 + GCBC: 如果只使用数据标签并尝试克隆行为 (目标条件行为克隆) ,成功率非常低 (7%) 。这很可能是因为原始数据充满“噪声”或非最优的。
- Steps 1+2 (GCRL): 如果只停留在 RL 步骤,你在训练目标上能获得不错的表现,但完全没有处理新语言指令的能力,因为 Q-learning 表格无法处理新句子。
- All Steps (TEDUO): 完整的流水线产生了最高的成功率 (65%) ,证实了 LLM 微调对于综合这些技能至关重要。
Q3: 是死记硬背还是技能学习?
为了测试智能体是否真的在学习可组合的技能,研究人员设计了一个巧妙的实验,包含三种环境类型。
- Type A: 涉及捡起物品的任务 (没有门) 。
- Type B: 涉及开门的任务 (没有物品) 。
- Type C: 需要同时开门和捡起物品的任务。
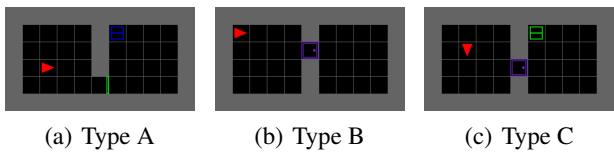
他们训练智能体处理 A 类和 B 类任务,但从未让其接触 C 类任务。然后,他们在 C 类任务上进行测试。
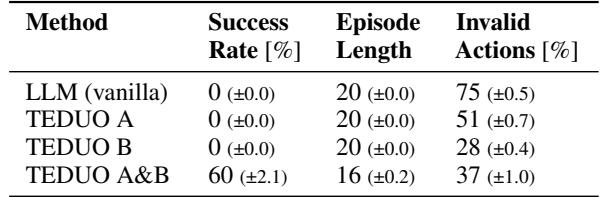
如表 3 所示,仅在 A 上训练的智能体在 C 上失败。仅在 B 上训练的智能体也在 C 上失败。但 TEDUO A&B (在两个独立任务上都受过训练) 成功地重新组合了这些技能以解决 C 类型任务 (60% 成功率) 。
这展示了组合性 (Compositionality) 。 LLM 分别学会了“打开”和“捡起”的概念,并在零样本 (zero-shot) 情况下将它们结合起来解决了一个复杂的多步任务。
Q4: LLM 内部发生了什么?
论文中最引人入胜的部分之一是可解释性分析。研究人员探测了 LLM 的内部层,看看它对环境“知道”多少。
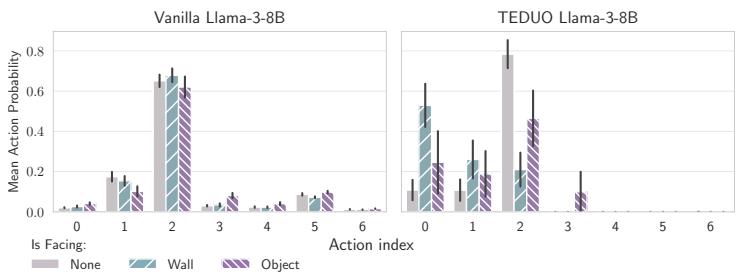
在图 4(a) 中,我们可以看到采取“向前移动”动作 (Action 2) 的概率。Vanilla LLM (左图) 即使面对墙壁 (青色条) 也自信地尝试向前移动。它本质上是在产生幻觉,以为自己可以穿墙而过。
然而, TEDUO 微调后的 LLM (右图) 在面对墙壁时,“向前移动”的概率大幅下降。它学会了物理约束。
此外,图 4(b) (下图) 展示了“线性探针 (Linear Probe) ”的结果——这是一种简单的分类器,试图基于 LLM 的内部神经元激活来检测是否存在墙壁。
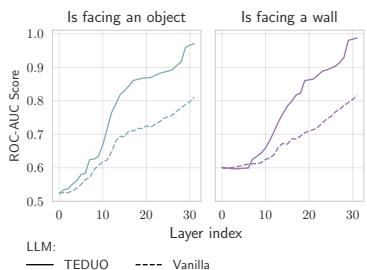
TEDUO 模型 (实线) 在其深层实现了近乎完美的墙壁和物体检测。这证明微调不仅仅教会了它鹦鹉学舌;它从根本上改变了模型表征物理世界状态的方式。
数据效率
最后,作者表明他们的方法非常高效。由于抽象步骤 (移除了无关细节) ,RL 算法的收敛速度要快得多。
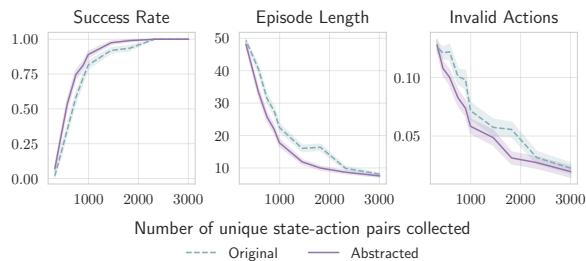
图 5 显示,与使用原始状态 (虚线蓝线) 相比,使用抽象函数 (实线紫线) 允许智能体以更少的数据样本达到高成功率。这对于数据收集昂贵的现实世界应用至关重要。
结论: 离线智能体的未来
TEDUO 代表了在让 AI 智能体更自主、更易于训练方面迈出的重要一步。通过将大语言模型不仅视为聊天机器人,而是视为灵活的、可以通过传统强化学习落地的“泛化器”,研究人员解锁了一种仅使用被动、无标签数据来训练智能体的方法。
主要收获:
- LLM 的双重角色: TEDUO 利用 LLM 清洗数据 (注释) 并采取行动 (策略) ,在这两个领域都发挥了模型的优势。
- 泛化能力: 与标准 RL 不同,TEDUO 智能体可以理解并执行它们在训练期间从未见过的命令。
- 低保真数据: 该方法适用于无标签、潜在嘈杂的观测数据,消除了对昂贵人工注释的需求。
这项研究为“观察学习”AI 铺平了道路——这种智能体可以观察人类行为 (如计算机使用的视频日志或智能家居传感器) ,不仅学习模仿动作,还能充分理解底层机制以执行全新的任务。随着算力的提升,像 TEDUO 这样的方法可能成为训练下一代具身 AI 助手的标准。