](https://deep-paper.org/en/paper/2412.18603/images/cover.png)
引言
想象一下,让 AI 给你讲个睡前故事——不是朗读你提供的文本,而是用人类的声音凭空构思出一个全新的故事,甚至包含停顿、叹息和语调变化。现在,想象一下让它持续讲二十分钟。
多年来,这一直是生成式语音语言建模领域的“最终 Boss”。虽然像 AudioLM 或 GSLM 这样的模型可以生成令人印象深刻的 10 或 20 秒语音片段,但它们在更长的时间跨度上不可避免地会崩溃。它们开始语无伦次地胡言乱语,陷入重复循环,或者干脆变成静电噪音。在生成中间内容时还需要记住对话开头,这种计算成本变得极高。
这就引出了一篇开创性的论文: SpeechSSM 。
SpeechSSM 背后的研究人员解决了“无界 (unbounded) ”语音生成的问题。通过摆脱标准的 Transformer 架构并采用 状态空间模型 (State-Space Models, SSMs) , 他们创建了一个能够生成连贯、长篇语音 (测试时长达 16 分钟,理论上无限) 的系统,而且不会耗尽内存或丢失情节。
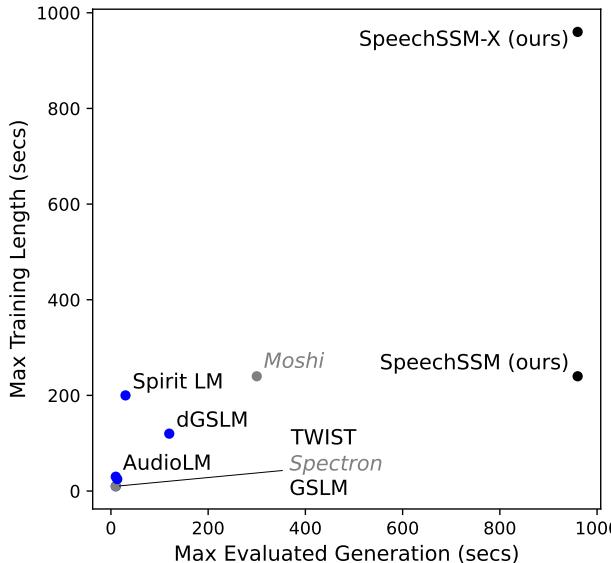
如 图 1 所示,现有模型 (如 AudioLM 或 GSLM) 聚集在左下角——它们在短片段上训练,且只能生成稍长一点的片段。SpeechSSM (右上角) 打破了这一范式,它在多分钟的序列上进行训练,并能有效地进行无限生成。
在这篇深度文章中,我们将探讨 SpeechSSM 如何实现这一目标,为什么“无文本 (textless) ”建模如此困难,以及作者如何建立新的基准来证明他们的成功。
背景: 为什么长篇语音很难?
要理解这一突破,我们首先需要了解瓶颈所在。大多数现代语言模型,无论是用于文本 (如 GPT-4) 还是语音,都依赖于 Transformer 架构。
Transformer 使用一种“注意力 (attention) ”机制。为了决定接下来生成什么词 (或声音) ,模型会回顾目前为止生成的每一个 token。这对于段落来说非常有效。然而,音频是密集的。一秒钟的音频可能由 50 到 100 个离散 token 表示。一段 10 分钟的语音片段可能包含数万个 token。
对于 Transformer 来说,“回顾”的成本随着序列长度呈二次方增长 (\(O(N^2)\)) 。随着语音变长,模型会变慢并消耗大量内存。最终,它会触及硬件极限。此外,Transformer 通常难以“外推 (extrapolate) ”——如果你在 30 秒的片段上训练它们,它们根本不知道如何构建一个 5 分钟的叙述结构。
状态空间模型 (SSM) 登场
这就是 状态空间模型 发挥作用的地方。与保留所有历史记录的 Transformer 不同,SSM 维护一个压缩的“状态”——一个随时间演变的固定大小的记忆向量。在预测下一个 token 时,模型会查看其当前状态和当前输入。
其计算复杂度是线性的 (\(O(N)\)) ,而不是二次方的。这意味着生成第 10,000 秒音频所需的内存和计算量与生成第 1 秒完全相同。这一特性对于作者旨在实现的“无界”生成至关重要。
核心方法: 深入 SpeechSSM
SpeechSSM 不仅仅是更换了模型;它是一个精心设计的流水线,将说什么 (语义) 与谁在说 (声学) 分离开来。
1. 架构: 混合 SSM (Griffin)
系统的核心是语义语言模型。研究人员选择了一种名为 Griffin 的混合架构。
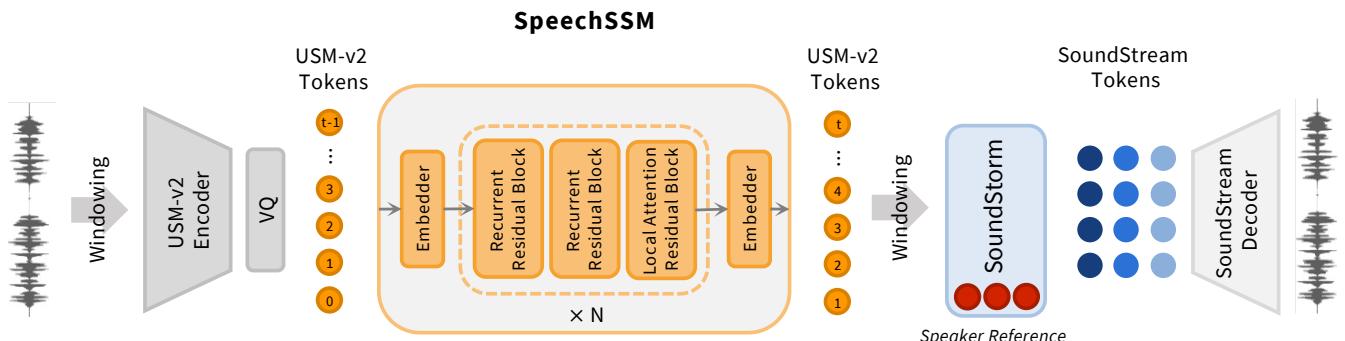
如 图 3 (左) 所示,该模型不直接处理原始音频波。相反,它在 语义 Token 上运行。
- 输入: 模型使用 USM-v2 token 。 这些是源自通用语音模型 (Universal Speech Model) 的离散代码。至关重要的是,这些 token 具有高度的*说话人不变性 (speaker-invariant) *。它们捕捉语音的含义和语言内容,但剥离了特定的声音特征。
- Griffin 模块: 该模块混合了 门控线性循环 (Gated Linear Recurrences) (SSM 部分) 和 局部注意力 (Local Attention) 。 循环部分处理长期依赖关系 (记住故事的主题) ,而局部注意力则关注直接上下文 (正确发音当前的单词) 。
由于模型使用循环层,因此在解码期间它具有恒定的内存占用。你可以让它运行数小时,而不会让 GPU 显存耗尽。
2. 分词与窗口化
为了有效地处理无限的音频流,你不能一次性将 1 小时的文件输入到分词器中。作者实施了一种 窗口化分词与解码 (Windowed Tokenization and Decoding) 策略。
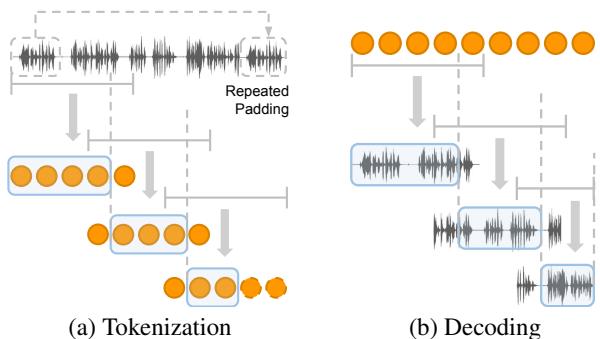
观察 图 4 , 我们可以看到这是如何工作的:
- 输入 (图 4a) : 长音频被切成具有重叠部分的固定大小窗口。
- 合成 (图 4b) : 在生成音频时,模型分块生成 token。为了避免边界处的“咔哒”声或不连续性,窗口是重叠的。最终的数据流是通过取一个窗口的前半部分并将其融合到下一个窗口的后半部分来拼接而成的。
这种方法解决了“隐式序列结束 (EOS) ”问题。如果模型是在固定长度的片段上训练的,它通常会学到“当我到达第 1000 个 token 时,我应该停止说话”。通过使用滑动窗口和填充,SpeechSSM 被诱导认为它始终处于数据流的中间,从而防止它过早地静音。
3. 声学合成: 把声音加回来
由于语义模型 (Griffin) 在“无声”的语义 token 上运行,我们需要一种方法将其转换回丰富、类似人类的音频。
这是由 图 3 右半部分所示的 声学生成器 (Acoustic Generator) 处理的。作者使用了 SoundStorm , 这是一种非自回归模型。
- 提示 (Prompting) : SoundStorm 以特定说话人的 3 秒短音频提示为条件。
- 生成: 它接收来自 Griffin 模型的语义 token 和说话人提示,并生成 SoundStream 声学 token (编解码器代码) 。
- 结果: 这些声学 token 被解码为波形。
这种关注点分离非常高明。“保持切题 10 分钟”的繁重工作由高效的 SSM 在语义 token 上处理。“听起来像特定的人”的繁重工作由非自回归合成器处理,它不需要长期记忆——只需要保持声音的音色即可。
评估挑战
如何衡量一个生成出来的 5 分钟故事是“好”的?
过去,研究人员使用 ASR 困惑度 (ASR Perplexity) (转录音频并检查文本是否可预测) 或 Auto-BLEU 。 作者认为这些对于长篇语音来说是不够的。当音频包含含糊不清的胡言乱语时,ASR 会失效,而且困惑度分数无法捕捉故事是否在第 3 分钟后偏离了主题。
为了解决这个问题,论文引入了一个新的基准和新的指标。
LibriSpeech-Long
标准数据集 (如 LibriSpeech) 被切成 10 秒的短语用于语音识别训练。这对于测试长篇连贯性毫无用处。作者回到了原始有声读物,重新处理它们以创建 LibriSpeech-Long 。
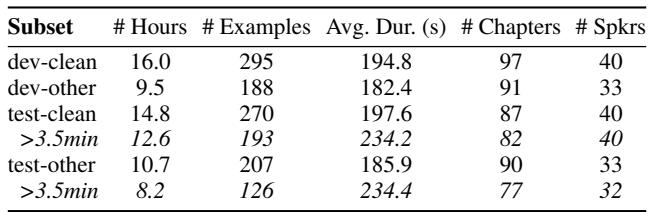
如 表 1 所示,这个新数据集包含被切分成最长 4 分钟片段的章节。这为测试模型能否维持数百秒的叙述提供了真实数据 (Ground Truth) 。
新指标
- LLM 即裁判 (LLM-as-a-Judge) : 研究人员不依赖死板的公式,而是转录生成的音频和真实音频。然后,他们将两份转录文本提供给大型语言模型 (如 Gemini) ,并询问: “这两种续写中哪一种更连贯、更流畅?”
- 分层时间评估 (Time-Stratified Evaluation) : 他们测量随时间变化的质量。他们检查第一分钟、第二分钟等的指标,以检测模型何时开始退化。
实验与结果
研究人员将 SpeechSSM 与 GSLM、TWIST 和 Spirit LM 等强力基准进行了比较。他们还创建了一个“SpeechTransformer”基准——一个与 SpeechSSM 相同但使用 Transformer 架构的模型——以隔离状态空间方法的优势。
短篇表现 (健全性检查)
首先,他们检查了 SpeechSSM 在标准短任务 (7 秒生成) 上是否具有竞争力。
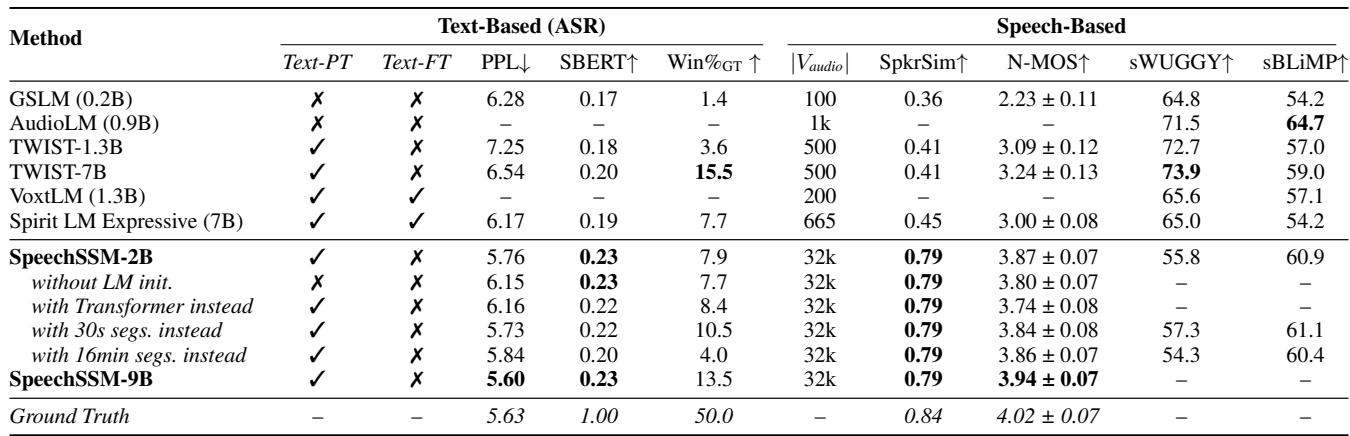
表 2 显示 SpeechSSM (加粗部分) 表现稳健。
- 说话人相似度 (SpkrSim) : SpeechSSM 获得了 0.79 的分数,显著高于 GSLM (0.36) 或 TWIST (0.41)。这验证了使用独立的、说话人提示声学阶段的策略。
- 胜率: 在正面交锋中,SpeechSSM 通常优于基准模型。
长篇表现 (真正的考验)
这才是该架构大放异彩的地方。模型被赋予一个 10 秒的提示,并被要求续写 4 分钟。
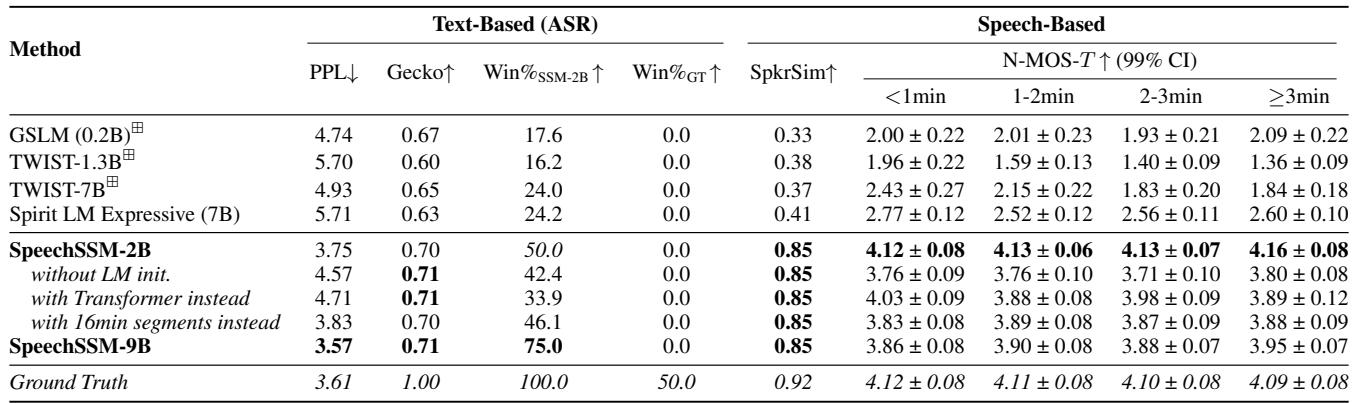
表 3 描绘了一幅清晰的图景:
- 胜率: SpeechSSM-2B 主导了该领域。“Win% vs SpeechSSM-2B”列显示了其他模型击败 SpeechSSM 的频率。GSLM 的胜率仅为 17.6%;TWIST 仅为 16.2%。
- 随时间变化的自然度 (N-MOS-T) : 查看
<1min、1-2min等列。像 TWIST 这样的基准模型迅速退化 (从 1.96 降至 1.36) 。SpeechSSM 在整个 4 分钟内保持了高分 (~4.1) 。这证明模型不仅仅是在胡言乱语;它正在保持高质量的语音输出。
外推: 迈向 16 分钟
作者进一步推动模型,生成了长达 16 分钟的音频。为了量化“连贯性”,他们测量了随着时间推移,生成的语音与原始提示之间的语义相似度。
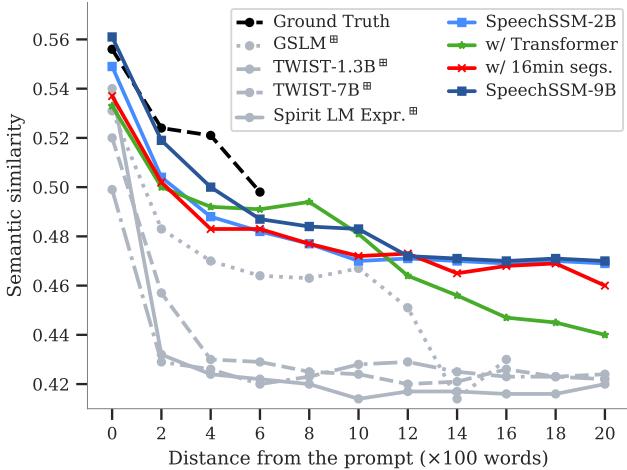
图 5 可能是论文中最重要的图表。它追踪了 16 分钟内的 语义连贯性 (SC-L) (X 轴表示单词距离) 。
- 黑色虚线 是真实数据 (人类) 。
- 蓝色线 是 SpeechSSM。
- 灰色/绿色线 是基准模型 (Transformer 等) 。
注意基准模型是如何迅速暴跌的吗?它们丢失了对话的线索。然而,SpeechSSM 遵循一个平缓得多的斜率,反映了在真实数据中看到的自然话题漂移。它保持连贯的时间远超竞争对手。
效率
最后,让我们谈谈速度。因为 SpeechSSM 是一个 SSM,它在解码长序列时应该更快。
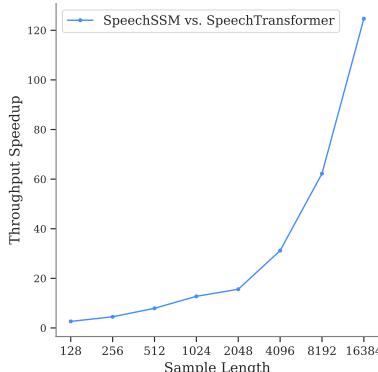
图 8 证实了这一点。Y 轴显示了 SpeechSSM 相对于 Transformer 的吞吐量加速比。在短长度 (128 个 token) 下,它们是可比的。但随着序列长度增长到 16k 个 token (大约 11 分钟) ,SpeechSSM 在吞吐量方面变得 快了 120 多倍 。 这就是实时生成与等待数小时才有结果之间的区别。
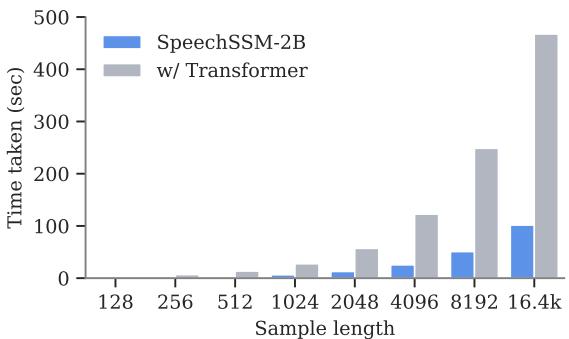
图 7 可视化了单个样本的解码时间。灰色柱 (Transformer) 随着序列变长而变得越来越高。蓝色柱 (SpeechSSM) 保持低且可控。
结论与启示
SpeechSSM 代表了生成式音频的一个重大飞跃。通过放弃 Transformer 的二次方内存成本,转而采用状态空间模型 (特别是 Griffin 架构) 的线性效率,研究人员解决了阻碍长篇语音生成的“内存墙”。
主要收获:
- 架构至关重要: 对于长序列,像 SSM 这样的线性复杂度模型提供了 Transformer 根本无法高效匹敌的能力。
- 分而治之: 将语义建模 (“剧本”) 与声学建模 (“声音”) 分开,可以实现更好的连贯性和说话人持久性。
- 新基准: 我们无法改进我们无法衡量的东西。LibriSpeech-Long 和新的基于 LLM 的指标为该领域的未来研究提供了路线图。
其影响不仅仅局限于有声读物。这项技术为能够进行长达一小时对话的 AI 语音助手、不会在长篇演讲中卡壳的实时翻译系统,以及能够通过单个提示创建整个播客剧集的生成媒体工具铺平了道路。SpeechSSM 打破了沉默的障碍,使机器不仅能说句子,还能讲述故事。