](https://deep-paper.org/en/paper/2501.04519/images/cover.png)
简介
长期以来,人工智能领域的普遍看法很简单: 越大越好。如果你想让模型解决复杂的微积分或高中奥林匹克数学题,你需要数千亿个参数、海量的计算资源,以及像 GPT-4 或 Claude 3.5 这样的模型。小型语言模型 (Small Language Models, SLMs) ,通常在 10 亿到 80 亿参数范围内,被认为是处理基础任务的高效助手,但无法进行深度的多步推理。
这一假设刚刚被打破。
一篇名为 rStar-Math 的新研究论文介绍了一种方法,该方法允许小型语言模型 (具体为 7B 参数模型) 不仅能与 OpenAI 的 o1-preview 和 o1-mini 竞争,甚至在某些情况下超越它们的推理能力。
秘密不在于把模型做得更大,而在于改变它思考的方式。通过从“系统 1”思维 (快速、直觉式的响应) 转向“系统 2”深度思维 (深思熟虑、基于搜索的推理) ,并采用巧妙的自进化训练配方,研究人员在不依赖优越模型蒸馏的情况下,达到了最先进的结果。
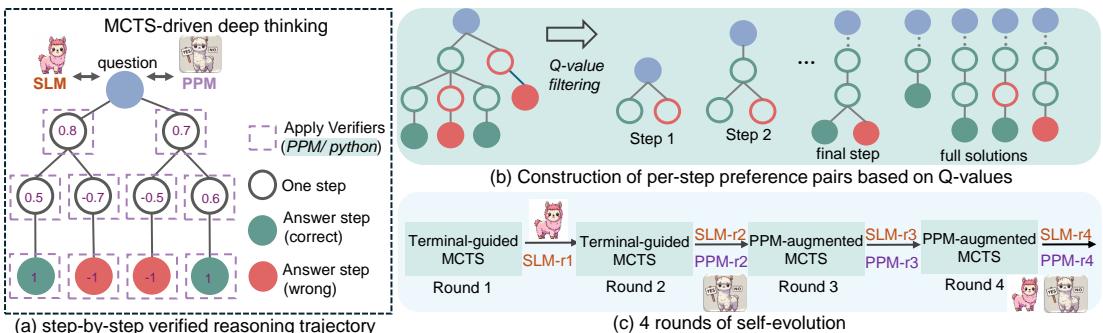
如图 1 所示,rStar-Math 结合了蒙特卡洛树搜索 (MCTS) 和自我改进的奖励模型来处理复杂的数学问题。在这篇文章中,我们将解构 rStar-Math 的工作原理,为什么“深度思维”是 AI 推理的未来,以及一个 7B 模型如何在 MATH 基准测试中取得 90% 的高分。
数学中“快”思考的问题
要理解为什么 rStar-Math 如此重要,我们需要先了解标准大型语言模型 (LLM) 的局限性。传统的 LLM 通过逐个 token 的方式一次性生成解决方案。这通常被比作人类心理学中的 系统 1 思维——快速、自动且直觉化。
虽然这对于写邮件或总结文本很有效,但对于数学来说却是灾难性的。在一个多步数学问题中,第 3 步的一个错误会使整个解题过程无效,无论第 4 步到第 10 步有多完美。LLM 还容易产生幻觉——自信地陈述错误的事实或逻辑。
为了解决这个问题,业界正在转向 测试时计算扩展 (test-time compute scaling) , 或称为 系统 2 思维 。 这涉及生成多个推理步骤,评估它们,必要时回溯,并搜索通往答案的最佳路径。这需要两个组件:
- 策略模型 (Policy Model) : 生成推理步骤的 AI。
- 奖励模型 (Reward Model) : 评估步骤是否正确或有用的 AI 裁判。
然而,针对数学训练这些组件极其困难。高质量的分步数学数据非常稀缺。此外,训练一个奖励模型来准确评估中间步骤 (例如,“这第 3 行代数推导有希望吗?”) 极其困难,因为最终答案正确并不能保证中间步骤也是正确的。
rStar-Math 的解决方案
rStar-Math 通过三个独特的创新解决了这些挑战:
- 代码增强思维链 (CoT) 数据合成: 使用 Python 代码来验证推理步骤。
- 过程偏好模型 (PPM) : 一种训练“裁判”模型的新方法,避免了嘈杂的分数分配。
- 4 轮自进化: 一个循环过程,模型生成自己的数据变得更聪明,从而使其能生成更好的数据。
让我们逐一拆解。
创新 1: 代码增强思维链 (Code-Augmented Chain-of-Thought)
标准的思维链 (CoT) 依赖于模型生成自然语言文本。问题在于文本很难自动验证。研究人员引入了 代码增强 CoT 。
模型不仅仅写出“我将计算距离”,而是生成文本形式的推理步骤 以及 执行该步骤的相应 Python 代码。

如图 2 所示,推理过程被分解为多个节点。在每一步,模型生成 Python 代码。如果代码执行失败,该推理路径会被立即丢弃。这对幻觉起到了强大的过滤作用。如果代码运行成功,输出将被用于通知下一步。这弥合了模型的语言推理与数学确定性本质之间的差距。
创新 2: 蒙特卡洛树搜索 (MCTS)
为了在解空间中导航,rStar-Math 采用了 蒙特卡洛树搜索 (MCTS) 。 模型不是生成一条直线的文本,而是探索可能性的树状结构。
在数学问题的任何给定状态下,模型 (策略 SLM) 会提出几个可能的下一步。系统需要决定探索哪一步。它使用了 树的置信上限 (UCT) 公式:
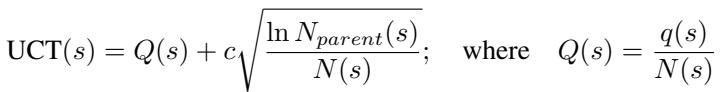
这里,\(Q(s)\) 代表步骤的估计质量 (由奖励模型提供) ,而第二项鼓励探索较少访问的路径。\(N(s)\) 是该节点被访问的次数。
通过推演 (Rollouts) 寻找真相
系统如何知道一个步骤是否真的好?它执行“推演 (rollouts) ”。它会多次模拟从该步骤开始的后续解题过程。
- 如果一个步骤经常导致正确的最终答案,它会获得高值。
- 如果它导致错误的答案,它会获得低值。
在训练的早期阶段 (第 1 和第 2 轮) ,系统依赖于 终端引导标注 (Terminal-guided annotation) 。 它查看最终答案 (终端节点) ,并将成功或失败反向传播给之前的步骤:
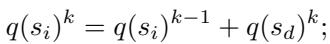
在后期阶段 (第 3 和第 4 轮) ,一旦奖励模型训练完成,它会立即提供步骤质量的初始估计:
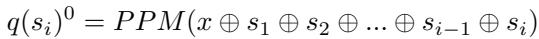
这使得系统能够建立一个推理轨迹数据集,其中每一步都有一个“Q 值”,指示它导致正确解决方案的可能性有多大。
创新 3: 过程偏好模型 (PPM)
这篇论文中最技术性但也最关键的贡献可能是他们训练奖励模型的方式。
现有的方法试图训练一个过程奖励模型 (PRM) 来给一个步骤分配具体的分数 (例如 0.85) 。这被称为“逐点 (pointwise) ”评分。问题是来自 MCTS 的 Q 值是嘈杂的。由于搜索的随机性,“0.8”可能并不比“0.75”好。训练模型回归到这些嘈杂的数字会导致性能不佳。
rStar-Math 转而训练一个 过程偏好模型 (PPM) 。 它不问“这一步的确切分数是多少?”,而是问“步骤 A 是否比步骤 B 好?”
他们使用 MCTS 数据构建“偏好对”。他们选取导致正确答案的步骤 (正例) 和导致错误答案的步骤 (负例) ,并训练模型将正例步骤的排名排在负例之前。
使用的损失函数是成对排序损失 (pairwise ranking loss) :
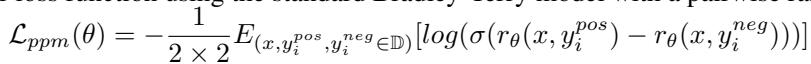
这种方法对噪声的鲁棒性要强得多。模型学会了区分好的推理和坏的推理,而不需要预测任意的数值分数。
创新 4: 自进化
研究人员不仅仅是训练了一次模型。他们创建了一个 自进化循环 。
- 生成数据: 使用当前的策略和奖励模型对 74.7 万个数学问题运行 MCTS。
- 过滤: 仅保留高质量的轨迹 (经代码和正确答案验证) 。
- 训练: 在成功路径上微调策略模型,并在偏好对上训练新的 PPM。
- 重复: 在下一轮中使用新的、更聪明的模型来解决更难的问题。

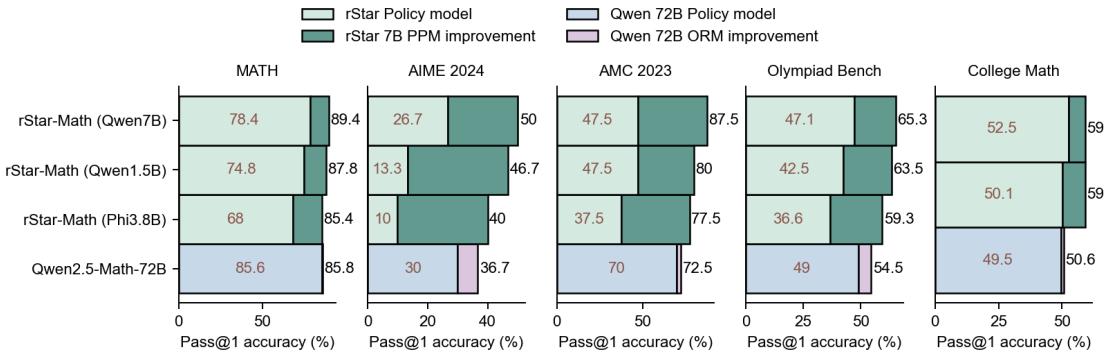
表 2 展示了这种进化的力量。在第 1 轮,系统只能解决 20.99% 的奥林匹克级问题。到了第 4 轮,它可以解决 80.58% 。 模型本质上是在“自举”其智能,生成了以前无法触及的训练数据。
实验与结果
rStar-Math 的结果令人震惊,特别是考虑到模型的大小。研究人员将此方法应用于 Qwen2.5-Math-7B、Phi3-mini (3.8B) 等模型。
与前沿模型的比较
数学推理的主要基准是 MATH 数据集。
- 基础 Qwen2.5-Math-7B: 58.8%
- rStar-Math (第 4 轮): 90.0%
这个 90% 的分数匹敌 OpenAI o1-mini , 并超越了 GPT-4o (76.6%) 和 o1-preview (85.5%)。
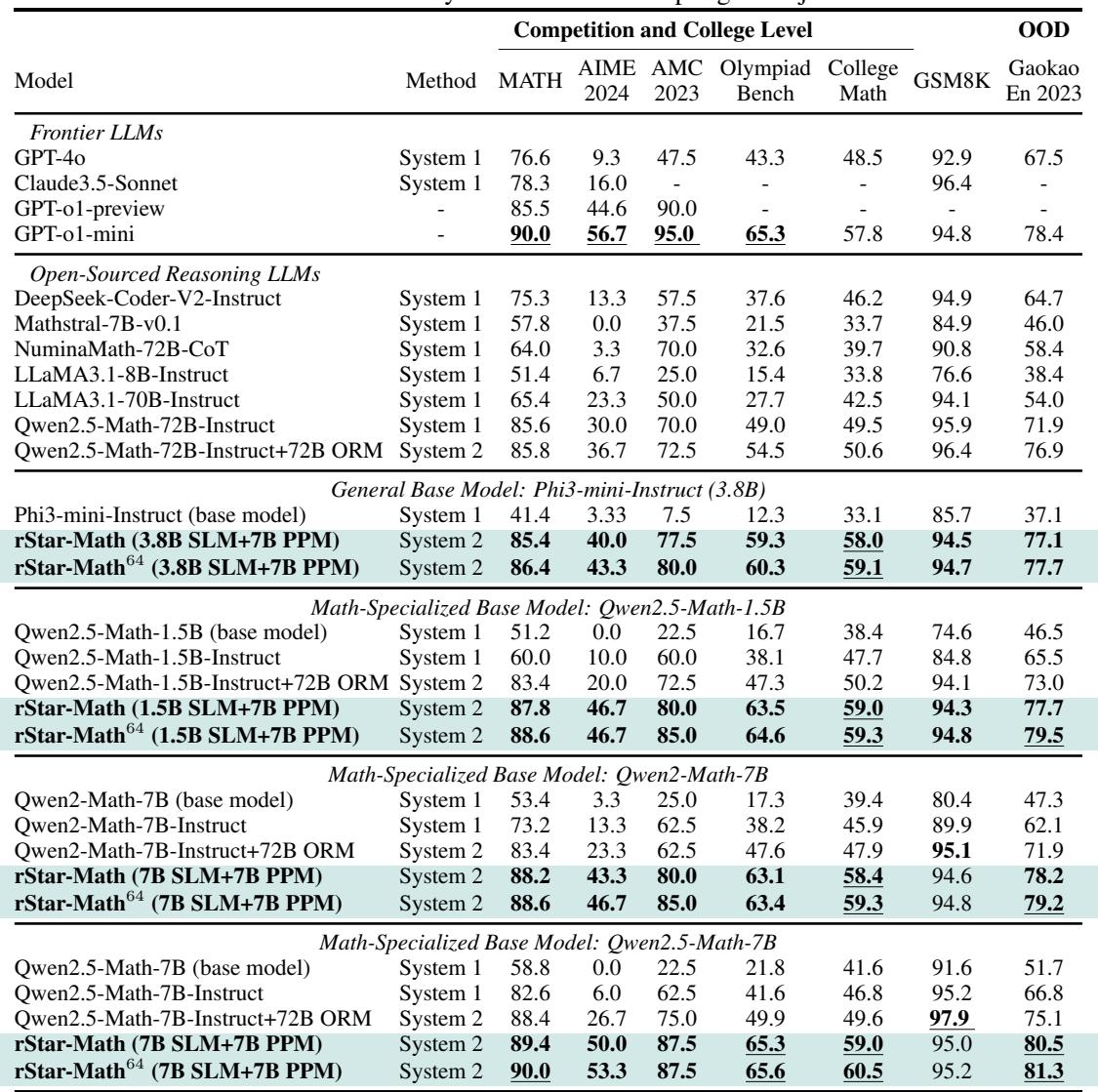
如表 5 所示,rStar-Math 在各种难度级别上都表现出色。在 AIME 2024 (美国数学奥林匹克资格赛) 中,7B 模型平均解决了 15 个问题中的 8 个 (53.3%) ,排在高中数学学生的前 20% 之列。这相比基础模型 0% 的得分是一个巨大的飞跃。
测试时计算的力量
该论文验证了“系统 2”假设: 给模型更多的时间/计算资源来搜索会产生更好的结果。
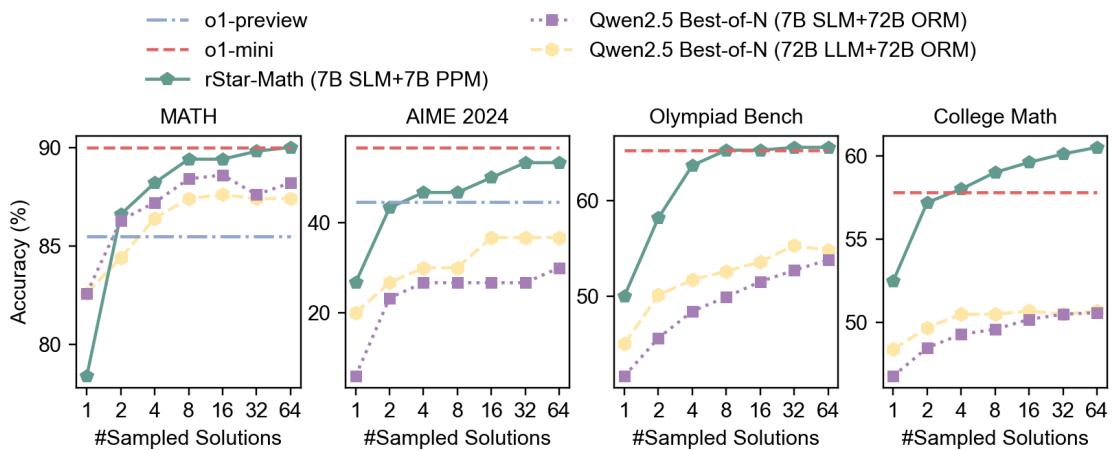
图 3 说明,随着采样解的数量增加 (从 1 到 64) ,准确率也随之提高。rStar-Math (绿线) 始终优于标准的“Best-of-N”采样方法 (紫线) ,证明 MCTS 树搜索是一种比简单地要求模型猜测 N 次更高效的计算能力使用方式。
奖励模型消融实验: PPM vs. ORM
新的过程偏好模型 (PPM) 真的比传统方法好吗?研究人员将其与结果奖励模型 (ORM) 和标准 Q 值 PRM (PQM) 进行了比较。

表 8 证实了 PPM (过程偏好模型) 的优越性。虽然 ORM (仅判断最终答案) 改进了基础模型,但 PPM 将准确率推得更高 (例如,在 AIME 上为 50.0%,而 ORM 为 26.7%) 。这证明了密集的、分步的反馈对于解决复杂的逻辑难题至关重要。
涌现能力: 自我反思
论文中最引人入胜的发现之一是 内在自我反思 的涌现。研究人员并没有明确训练模型说“等等,我犯了个错”。然而,在 MCTS 过程中,模型开始表现出这种行为。
在图 4 (上图) 中,我们看到了一个例子。模型最初试图使用复杂的代数方法 (“低质量步骤”分支) 来解决问题,这导致了死胡同。然而,搜索过程允许模型放弃那条路径,回溯,并尝试一种检查小整数的“暴力破解”方法 (“内在自我反思”分支) ,最终得出了正确答案。
这种行为模仿了人类解决问题的过程。我们很少能用一条直线解决难题。我们尝试,失败,意识到错误,然后转向。rStar-Math 使 SLM 也能做到这一点。
这意味着什么
rStar-Math 的意义远不止于帮助做家庭作业。
- 智能的民主化: 高级推理不再是大型闭源模型的专属领域。7B 模型可以在消费级硬件 (如高端 GPU 或 MacBook Pro) 上运行,将前沿级的数学推理带到本地设备上。
- 数据合成: 目前 AI 最大的瓶颈是缺乏高质量的训练数据。rStar-Math 证明 SLM 可以生成自己的高质量“思维”数据,这可能解决数据短缺问题。
- 效率: 与其训练一个 1 万亿参数的模型,我们可以训练一个小型模型,并在推理时使用“深度思维”搜索。这允许可调节的计算成本——仅在问题困难时花费更多时间思考。
结论
rStar-Math 代表了我们处理 AI 推理方式的范式转变。通过结合语言模型的语言流畅性、MCTS 的严谨搜索能力以及 Python 代码的验证能力,研究人员在小型模型中解锁了“系统 2”思维。
通过 4 轮自进化过程,这些小型模型学会了验证自己的工作、识别关键数学定理并修正自己的错误。正如论文所展示的,规模并不是 AI 中唯一重要的因素——有时,深度思考的能力才是获胜的关键。
“聪明”的小型语言模型时代已经到来。