](https://deep-paper.org/en/paper/2501.16566/images/cover.png)
1. 引言
如果你看过电影《头脑特工队》 (Inside Out) ,你应该对“基本情绪”的概念很熟悉。在电影中,一个小女孩的头脑由五个截然不同的角色控制: 乐乐 (Joy) 、忧忧 (Sadness) 、怒怒 (Anger) 、怕怕 (Fear) 和厌厌 (Disgust) 。几十年来,多模态情感识别 (MER) 领域的人工智能研究人员一直基于类似的前提进行研究。他们构建的系统旨在观察视频片段,并将人类的面部表情或声音归类到这些固定的、离散的“桶”中 (通常还会加上“惊讶”或“中性”) 。
但是,回想一下你上一次感受到强烈情绪的时候。那是纯粹的“悲伤”吗?还是夹杂着怀旧、失望,甚至是一种苦乐参半的解脱感?人类的情感是混乱、微妙且连续的。它很少能整齐地装进一个单一的盒子里。
这正是传统 AI 的局限所在。通过将复杂的人类行为强制放入闭集分类任务中,我们失去了人类体验的丰富性。我们错过了微笑中的讽刺、紧张时刻的神经质笑声,或者惊讶与恐惧的共存。

如上方的 图 1 所示,情绪是多样化的。在示例 (a) 中,微妙的微笑结合特定的语调可能表示嘲讽而非快乐。在示例 (b) 中,一个人可能同时经历惊讶、焦虑和愤怒。为了捕捉这种复杂性,我们需要不仅仅能分类,而且能描述的模型。
这把我们带到了情感 AI 与多模态大型语言模型 (MLLMs) 令人兴奋的交汇点。一篇题为 “AffectGPT” 的新研究论文提出了一个全面的框架来解决这些挑战。研究人员介绍了我们在本文中将要拆解的三个主要贡献:
- MER-Caption: 一个大规模的、描述性的情感数据集。
- AffectGPT: 一种旨在语言模型处理之前更好地融合音频和视频的模型架构。
- MER-UniBench: 一个用于评估 AI 对复杂情感理解程度的统一基准。
2. 数据瓶颈: 构建 MER-Caption
训练生成式 AI 理解情感的第一个障碍是数据。要教模型用自然语言描述情感 (例如,“这人看起来很焦虑,说话有些结巴……”) ,你需要成千上万个配有丰富文本描述的视频片段。
现有的数据集通常陷入两个陷阱:
- 分类式: 它们只提供简单的标签 (例如,
label: 1代表“快乐”) 。 - 规模小或质量低: 描述性数据集虽然存在,但要么太小 (因为人工撰写成本高昂) ,要么质量低 (因为它们是由旧的 AI 模型在没有监督的情况下生成的) 。
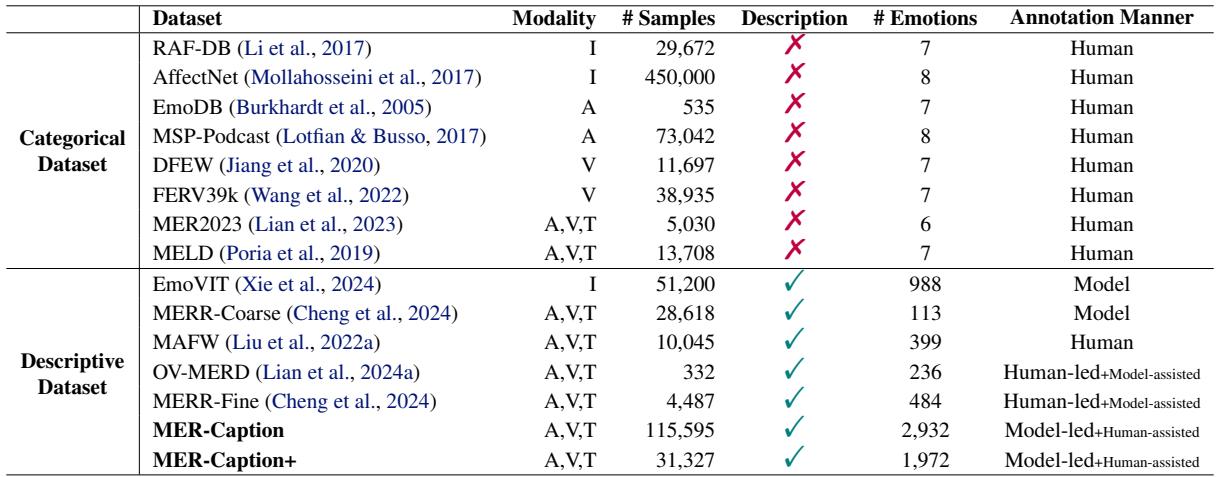
下表 1 突显了这一差距。虽然像 AffectNet 这样的分类数据集拥有数十万张图像,但描述性数据集通常要小得多,或者纯粹依赖机器生成。
“模型主导,人工辅助”策略
为了解决这个问题,作者构建了 MER-Caption , 这是迄今为止最大的描述性情感数据集,包含超过 115,000 个样本。他们通过发明一种 “模型主导,人工辅助” (Model-led, Human-assisted) 的标注策略,在不牺牲质量的前提下实现了这一规模。
他们没有要求人类从头开始撰写描述 (昂贵) ,也没有盲目相信模型 (不准确) ,而是使用了一个利用两者优势的流水线。
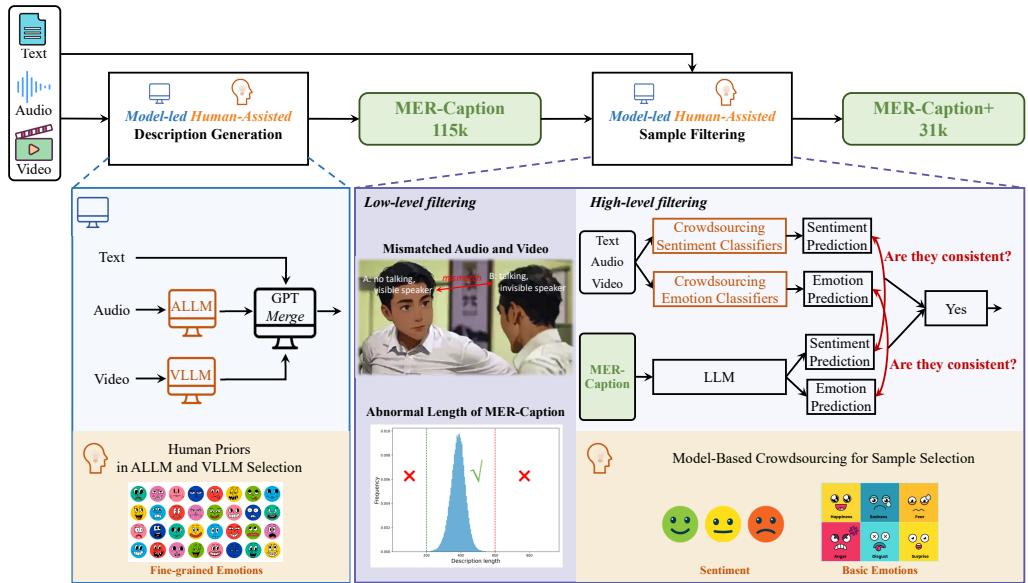
如 图 2 所示,该过程涉及几个巧妙的步骤:
- 描述生成: 他们利用专门的“专家”模型——一个音频 LLM (SALMONN) 和一个视频 LLM (Chat-UniVi) ——从原始媒体中提取线索。然后,一个中心 LLM (GPT-3.5) 将这些线索与视频字幕合并,形成连贯的描述。
- 低级过滤:
- 活跃说话人检测: 使用名为 TalkNet 的工具,他们移除了画面中可见人物实际上并未说话的视频 (这是电影片段中的常见问题,镜头往往聚焦在倾听者身上) 。
- 长度过滤: 他们移除了统计上过短或过长的描述,因为这些异常值通常预示着生成错误。
- 高级过滤 (基于模型的众包) : 这是最具创新性的一步。他们在现有的高质量人类数据集上训练了几个标准的情感分类器。他们用这些分类器来预测新数据。如果生成的描述与分类器预测的情感不匹配,该样本就会被丢弃。这作为一个“一致性检查”,确保文本描述与视听现实相符。
结果是一个庞大的数据集,其中机器完成了繁重的工作,但源自人类的先验知识 (通过训练好的分类器) 充当了质量控制。
3. 模型: AffectGPT
既然有了数据,我们该如何构建模型?
大多数多模态 LLM (MLLMs) 遵循一个标准配方: 采用一个视频编码器 (如 CLIP) 、一个音频编码器,将它们的输出投影到一个大型语言模型 (如 LLaMA 或 Qwen) 中。其假设是,LLM 足够聪明,可以弄清楚音频和视频是如何相互关联的。
然而,对于情感识别来说,这种 LLM 内部的“后融合” (late fusion) 并不总是足够的。音频和视频通常包含相互冲突或互补的信息,需要在语言处理开始之前进行同步。
研究人员提出了 AffectGPT , 它引入了一个 前融合操作 (Pre-fusion Operation) 。

前融合架构
在 图 3 中,你可以看到标准架构 (如 Audio-LLM 或 AV-LLM) 与 AffectGPT 之间的区别。
- 标准 AV-LLM: 音频特征 (\(Z_a\)) 和视频特征 (\(Z_v\)) 分别被投影并作为独立的 token 输入 LLM。LLM 必须费力地将痛苦的表情与尖叫声联系起来。
- AffectGPT: 模型显式地创建了一个组合表示 (\(Z_{av}\)) 。它在语言模型外部融合了模态。
这种前融合在数学上是使用拼接 (concatenation) 和注意力机制来实现的。模型将特征拼接起来:
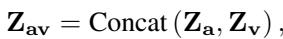
然后对其进行处理。作者探索了两种处理方法: 使用 Q-Former (一种复杂的基于查询的 Transformer) 和一种更简单的 Attention 机制 。
Q-Former 方法: 这种方法将视觉和音频信息压缩成固定数量的查询 token。
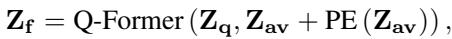
Attention 方法 (胜出者) : 令人惊讶的是,更简单的注意力机制通常效果更好。它涉及池化特征以压缩时间信息,然后应用学习到的权重矩阵来融合它们。
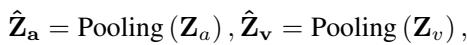
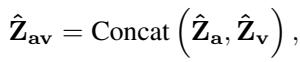
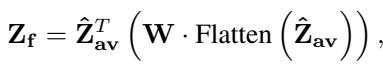
通过向 LLM 提供一个预先融合、同步的情感数据包 (\(Z_f\)) ,语言模型可以专注于生成描述,而不是在对齐原始信号上挣扎。最终目标与标准 LLM 一致——根据融合的输入预测描述中的下一个词:
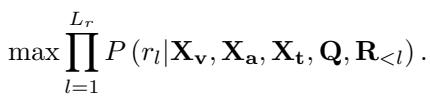
4. 如何给聊天机器人打分: MER-UniBench
生成式 AI 面临的最大挑战之一是评估。如果模型说“这人看起来很恼火”,而真实标签是“这人很生气”,模型错了吗?在传统的分类任务中,是的。在现实世界中,不是。
为了解决这个问题,作者创建了 MER-UniBench , 这是一个使评估指标适应 MLLM 自由形式特性的基准。
任务 1: 细粒度情感识别
此任务评估模型识别具体、细微情感的能力。由于不同的词可能意味着相同的事情 (例如,“joyful”与“happy”) ,基准测试使用了涉及 情感轮 (Emotion Wheels) 的映射策略。
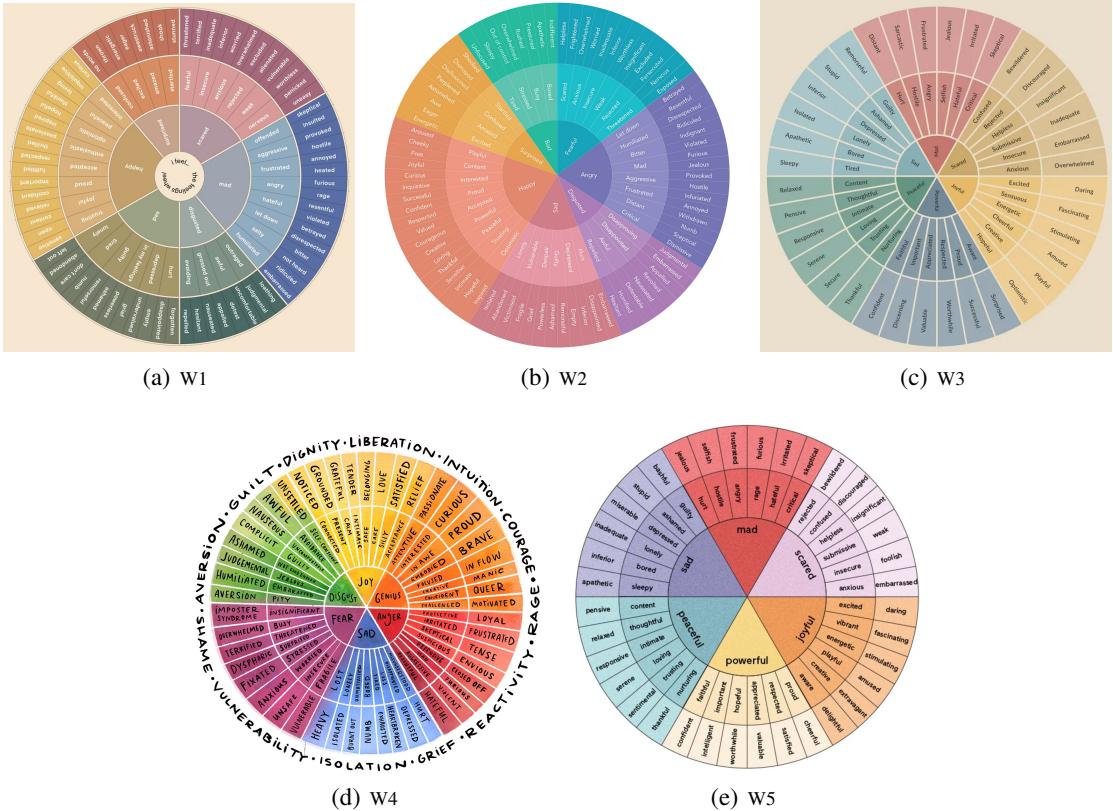
系统将预测的单词映射到其基本形式 (词形还原) ,然后映射到同义词,最后根据情感轮上的扇区进行分组 (如 图 9 所示) 。
使用的指标是 \(F_S\) (集合级 F-score) ,它平衡了精确率 (Precision,你预测的情感正确吗?) 和召回率 (Recall,你找到所有存在的情感了吗?) 。



任务 2: 基本情感识别
在这里,模型必须识别标准类别 (如快乐、悲伤、中性) 。由于 MLLM 的输出是开放式的,研究人员使用了 命中率 (HIT rate) 。 如果真实标签 (例如“悲伤”) 出现在模型生成的任何情感列表中,就算作命中。
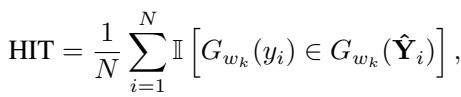
5. 实验与结果
AffectGPT 实际上比现有模型效果更好吗?结果令人信服。
主要比较
研究人员将 AffectGPT 与 Video-LLaVA、PandaGPT 和 SALMONN 等顶级 MLLM 进行了比较。
如 表 2 所示,AffectGPT 在几乎每个数据集上都取得了最高分。
- MER-UniBench 平均分: AffectGPT 得分为 74.77 , 显著高于第二名的竞争对手 (Emotion-LLaMA 的 64.17) 。
- 模态的重要性: 仅使用音频或仅使用视频的模型通常表现不如多模态的 AffectGPT,证明了结合感官对于理解情感至关重要。
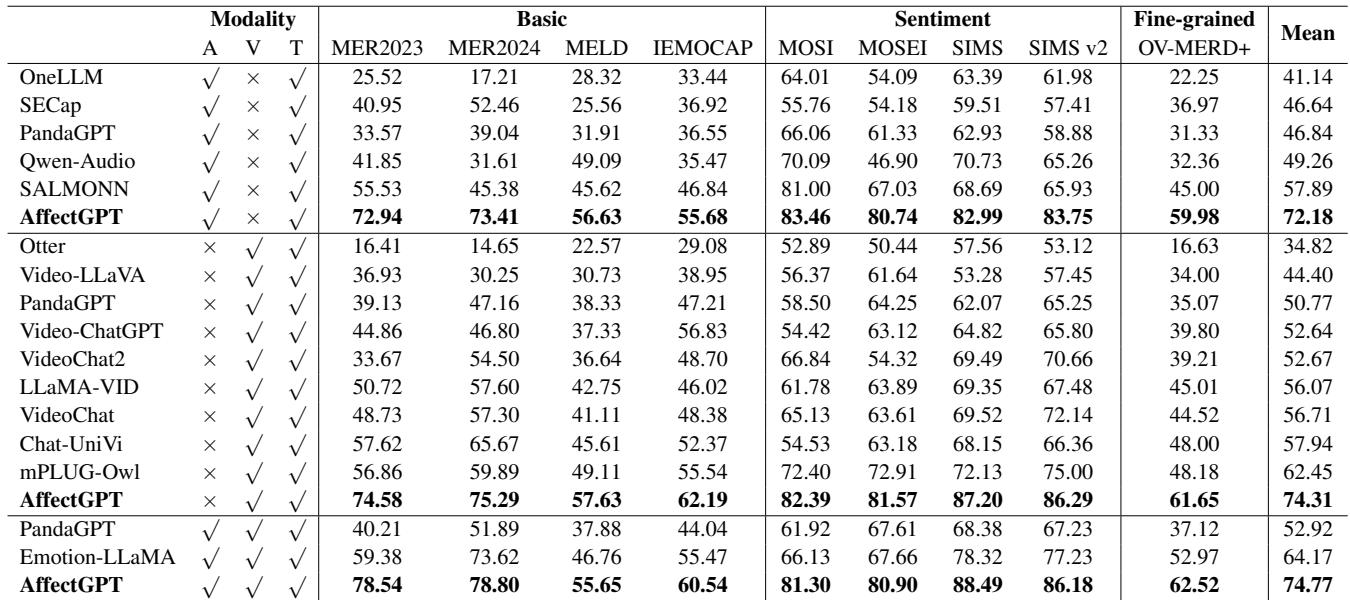
前融合有帮助吗?
作者进行了一项消融研究,看看这个花哨的“前融合”架构是否真的必要,还是说简单地将音频和视频输入 LLM 就足够了。
表 5 证实了前融合提高了性能。与没有前融合 (72.95) 相比,基于“Attention”的前融合 (前面讨论的更简单的方法) 产生了最好的结果 (74.77) 。
数据集的影响
新的 MER-Caption 数据集真的更好吗?研究人员在不同的数据集上训练了完全相同的模型,看看哪个能产生最聪明的 AI。
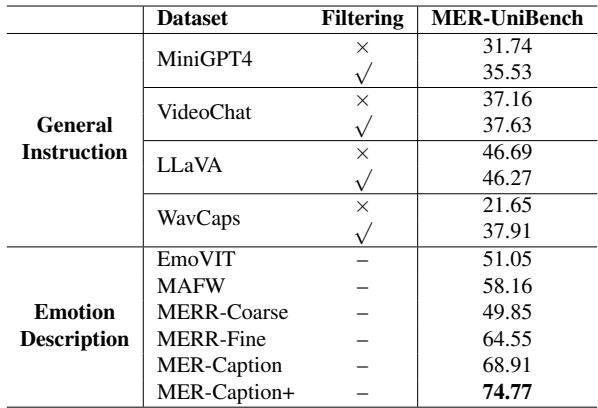
在 表 3 中,你可以看到在 MER-Caption+ (过滤后的版本) 上训练的结果得分为 74.77 , 击败了像 MAFW 这样的人工标注数据集 (58.16) 。这验证了“模型主导,人工辅助”创建策略的有效性。
定性分析
数字固然重要,但实际输出看起来如何呢?

图 5 展示了一个比较。
- Video-LLaVA 给出了通用的、正面的描述 (“积极的情绪状态”) 。
- Video-ChatGPT 描述了场景但错过了情感 (“难以确定”) 。
- Chat-UniVi 更接近一些 (“充满激情……或紧张”) 。
- 基准真值暗示了 嘲讽 或 讽刺 。
- 这突显出,虽然模型正在改进,但解释复杂的、讽刺性的社交互动仍然是 AI 的一个前沿领域。
消融研究: 组件
最后,底层 LLM 或编码器的选择重要吗?
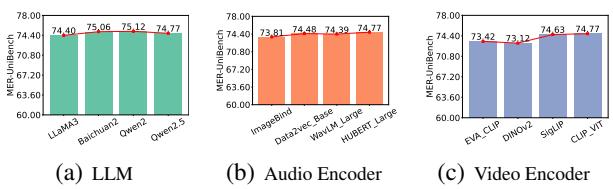
图 4 揭示了一个有趣的见解: 无论你使用 LLaMA 还是 Qwen (图表 a) ,或者不同的音频编码器 (图表 b) ,性能增益都相对稳定。这表明 AffectGPT 架构和 MER-Caption 数据 才是成功的真正驱动力,而不仅仅是底层 LLM 的原始能力。
6. 结论
从简单的分类到生成式理解的转变是情感 AI 的一次巨大飞跃。 AffectGPT 证明,通过将情感视为一个复杂的、多模态的语言任务,而不是简单的分类任务,我们可以构建出更懂细微差别的系统。
主要收获:
- 数据为王: MER-Caption 数据集证明,半自动化流水线可以生成大规模、高质量的训练数据,其表现优于较小的人工标注集。
- 架构很重要: 简单地将音频和视频编码器粘合到 LLM 上并不是最佳方案。对模态进行前融合有助于模型同步冲突的信号。
- 需要新的基准: 随着 AI 转向自由形式的文本生成,我们需要像 MER-UniBench 这样灵活的指标,能够处理同义词和语义相似性。
这项工作为更具同理心的 AI 奠定了基础——未来的系统可能不仅能理解我们说了什么,还能准确理解我们说话时的感受。