](https://deep-paper.org/en/paper/2502.00619/images/cover.png)
人工智能在医学影像领域,特别是在分割任务 (即在扫描图像中识别并勾勒肿瘤或器官边界的过程) 上取得了巨大进步。然而,由于偏见的存在,这些进步始终笼罩在一层阴影之下。
深度学习模型极其依赖数据。在临床实践中,数据很少是平衡的。我们往往拥有大量来自特定人群 (如白人患者) 或常见疾病阶段 (如 T2 期肿瘤) 的数据,但缺乏来自少数群体或不同疾病严重程度的数据。当一个标准的神经网络在这些倾斜的数据上训练时,它会变成一个“懒惰的学习者”。它针对多数群体进行优化,却无法泛化到代表性不足的群体。在医疗背景下,这不仅是一个准确性问题,更是一场伦理危机。一个对某类患者群体有效但对另一类失效的模型是不安全的,不能投入使用。
在这篇文章中,我们将深入探讨一篇引人入胜的研究论文: “Distribution-aware Fairness Learning in Medical Image Segmentation From An Control-Theoretic Perspective” (从控制理论视角看医学图像分割中的分布感知公平性学习) 。 作者提出了一种名为 分布感知混合专家模型 (Distribution-aware Mixture of Experts, dMoE) 的新颖框架。这篇论文的独特之处在于,它不仅仅是对数据进行微调;它利用最优控制理论中的核心概念,将神经网络重新构想为一个动态控制系统,从而设计出一个更公平的模型。
问题所在: 当“平均”表现良好还不够时
在医学图像分割中,我们通常关注 Dice 系数 (预测结果与真值之间的重叠程度) 等指标。一个模型可能吹嘘其平均 Dice 得分高达 90%,听起来很棒。但如果你剥开来看,可能会发现它在多数群体上达到 95%,而在少数群体上只有 60%。
作者指出了导致这种不平衡的两类主要属性:
- 人口统计学属性: 种族、性别和年龄。
- 临床因素: 疾病严重程度 (例如肿瘤分期) ,这会影响解剖结构的视觉外观。
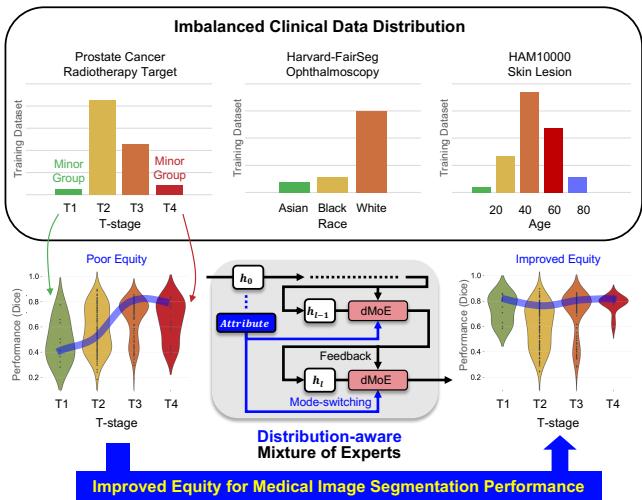
如上方的 图 1 所示,顶部部分突显了标准数据集中明显的极度不平衡。例如,前列腺癌数据集主要由 T2 和 T3 期主导,而 T1 和 T4 期非常罕见。中间部分可视化了目标: 从“公平性较差 (Poor Equity) ” (性能波动剧烈) 转变为“公平性提升 (Improved Equity) ” (在所有群体中表现一致) 。
解决方案: 分布感知混合专家模型 (dMoE)
为了解决这个问题,研究人员采用了 混合专家模型 (Mixture of Experts, MoE) 架构,但加入了一个关键的改动: 分布感知 (Distribution Awareness) 。
什么是混合专家模型?
在一个标准的深度学习层中,每个输入图像都由完全相同的神经元处理。混合专家模型 (MoE) 层则不同。它由一组不同的神经网络 (称为“专家”) 和一个“门控网络” (或路由器) 组成。对于任何给定的输入,路由器决定哪些专家最适合处理它。
标准 MoE 层的输出是所选专家的加权和:
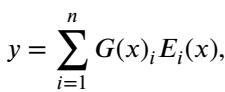
这里,\(G(x)\) 是门控决策,\(E_i(x)\) 是第 \(i\) 个专家的输出。这使得网络能够将其部分网络专门用于处理不同类型的数据。
“分布感知”的创新
标准的 MoE 仅基于输入图像特征 (\(x\)) 进行路由。作者认为,要实现公平性,路由器需要明确知道 属性 (例如,“该患者处于 T4 期”或“该患者来自少数族裔”) 。
他们提出了 dMoE , 其中门控网络 \(G\) 以属性标记 (\(attr\)) 为条件。新的公式如下所示:
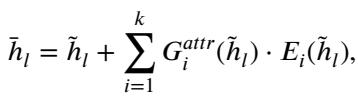
在这个公式中:
- \(\tilde{h}_l\) 是图像特征输入。
- \(G^{attr}\) 是特定于属性的路由器。
- 路由器选择前 \(k\) 个专家 (通常是 8 个中的 2 个) 来处理特征。
这允许网络根据患者是谁或病情的严重程度动态切换“模式”。
架构设计
这个 dMoE 模块不是一个独立的模型;它是一个构建块,可以插入到现有的强大架构中,如 Transformer (TransUNet) 或 CNN (3D ResUNet)。
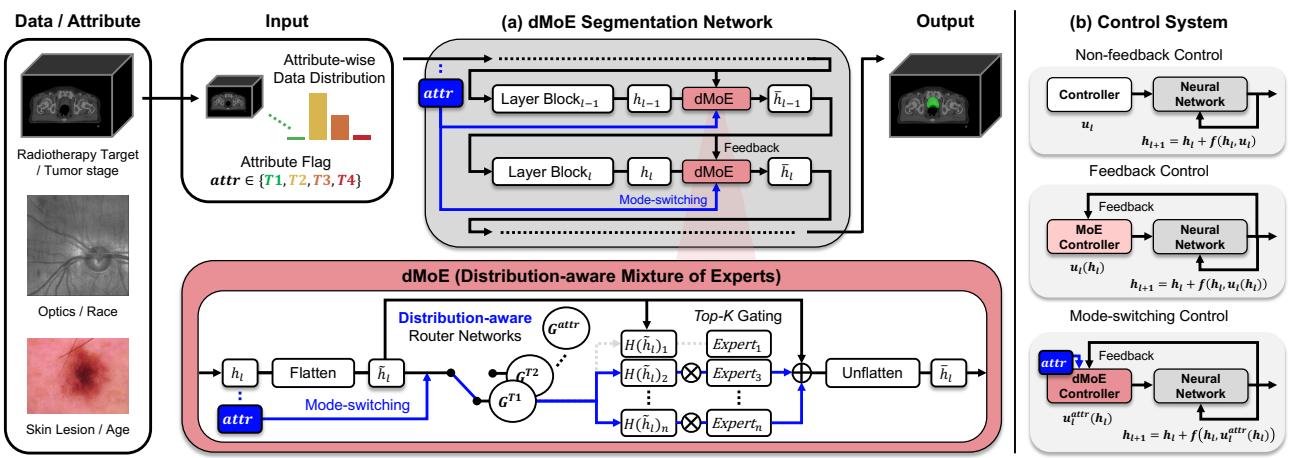
如 图 2(a) 所示,属性标记直接流入路由器网络。路由器计算所有专家的分数,并应用 带噪声的 Top-K 门控 (Noisy Top-K Gating) 机制,仅保持最相关的专家处于激活状态。门控函数定义为:
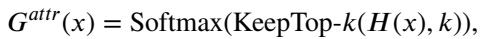
这确保了模型将其计算能力集中在那些已经学会处理特定数据分布的专家身上。
理论基础: 将神经网络视为控制系统
这篇论文最令人理智上感到满足的部分之一是它如何使用 最优控制理论 来构建公平性问题。如果你不是工程师,这听起来可能有点吓人,但这个类比非常直观。
1. 神经网络是动力系统
我们可以将神经网络的层视为动力系统中的时间步。系统的“状态”是特征图 \(h\),它随着穿过层 (时间) 而演变。标准的残差块更新如下所示:
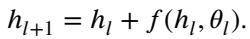
这看起来非常像用于求解常微分方程 (ODE) 的欧拉法。在连续时间中,即为:
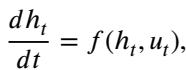
这里,\(u_t\) 代表在时间 \(t\) 施加的“控制” (权重/参数) 。
2. 训练即最优控制
训练神经网络本质上是试图找到最佳的控制序列 (权重) ,以最小化过程结束时的误差 (损失函数) 。
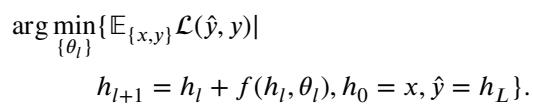
3. 从开环到反馈控制
标准的神经网络是 非反馈 (开环) 系统 (见图 2b 左侧) 。权重在训练后是固定的。无论中间状态如何,网络都应用相同的变换。
混合专家模型 (MoE) 改变了这一点。因为路由器会查看当前输入 \(h_t\) 来决定使用哪个专家,所以控制 \(u_t\) 变成了状态的函数。这就是 反馈 (闭环) 控制 :
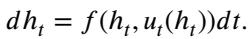
这使得系统具有自适应性。它可以根据其在特征空间中的当前位置调整轨迹。
4. dMoE 是模式切换控制
作者更进一步。在复杂的机械系统 (如飞行控制) 中,单一的反馈律是不够的。你需要不同的“模式”来分别对应起飞、巡航和着陆。
dMoE 充当了 模式切换控制器 (Mode-Switching Controller) 。 它根据外部环境变量——在本例中为人口统计学或临床属性 (\(attr\))——切换其控制策略。
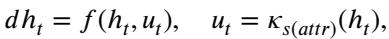
这里,\(s(attr)\) 决定使用哪个策略 \(\kappa\)。通过数学证明 MoE 结构近似于这种基于核的控制函数,作者为 dMoE 为何能更好地实现公平性提供了严格的理论依据: 它实际上是在改变其“操作模式”以适应它正在观察的亚群。
实验结果
理论很好,但在实际的医学扫描上有效吗?研究人员在三个数据集上测试了 dMoE:
- Harvard-FairSeg (2D): 眼底图像 (种族属性) 。
- HAM10000 (2D): 皮肤病变皮肤科图像 (年龄属性) 。
- 前列腺癌 (3D): 放疗用的 CT 扫描 (肿瘤分期属性) 。
他们将 dMoE 与最先进的 (SOTA) 公平性方法进行了比较,包括 FEBS (Fair Error-Bound Scaling) 和标准 MoE。
为了衡量成功与否,他们使用了标准的分割指标 (Dice 得分,IoU) 和一个经过公平性调整的指标,称为 公平性缩放分割性能 (Equity-Scaled Segmentation Performance, ESSP) :
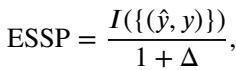
如果不同亚群之间的表现存在高方差 (\(\Delta\)),该指标会惩罚得分。
结果 1: 解决眼部扫描中的种族偏见
在 Harvard-FairSeg 数据集中,“黑人”和“亚裔”亚群通常代表性不足或更难分割。
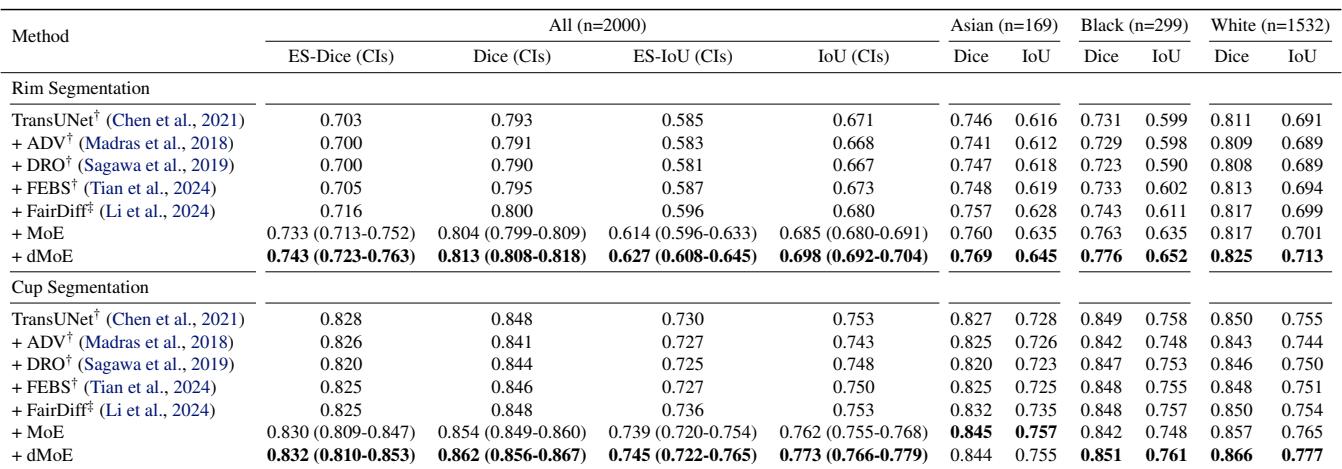
观察 表 1 , 标准方法 (TransUNet) 在黑人亚群上表现挣扎 (Dice 0.731) 。dMoE 方法将其提升至 0.776 , 这是一个显著的飞跃。它还获得了最高的公平性缩放 (ES) 得分,这意味着它在改善少数群体的同时没有牺牲多数 (白人) 群体的表现。
结果 2: 解决皮肤科中的年龄偏见
对于皮肤病变,年龄组极度不平衡。

在 表 2 中,我们看到 dMoE 获得了最高的 ES-Dice (0.801) 和 ES-IoU。它始终优于 FEBS,后者在某些情况下与基线相比甚至导致性能 下降。
结果 3: 3D 癌症治疗中的临床公平性
这可能是最关键的实验。在前列腺癌中,T4 (晚期) 肿瘤虽然罕见,但在放射治疗中正确分割至关重要。

表 3 显示了巨大的进步。对于 T4 亚群,基线模型得分为 0.656。dMoE 模型得分为 0.778 。 对于晚期癌症病例的治疗计划来说,这是一个改变游戏规则的改进。
我们可以通过 图 3 清楚地看到这种改进:
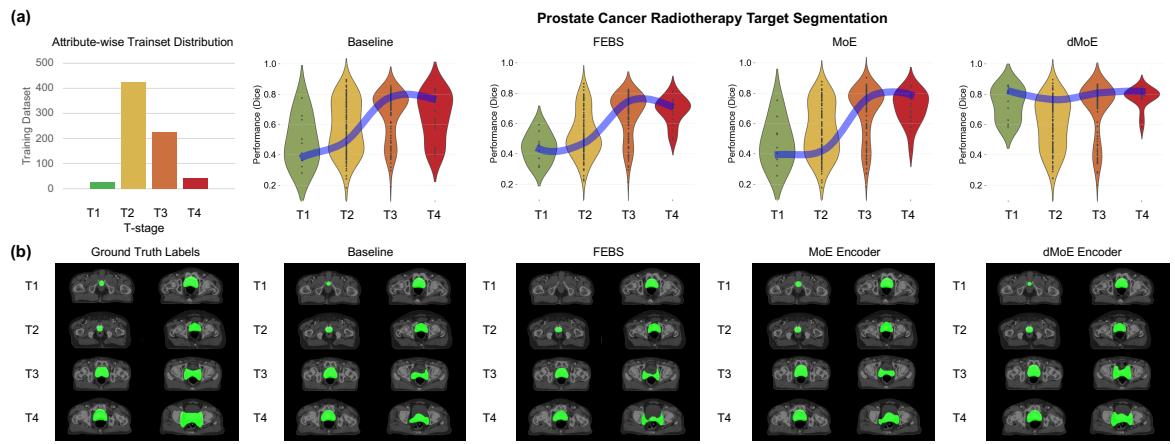
在小提琴图 (a) 中,注意 dMoE (最右侧) 如何在所有阶段 (T1 到 T4) 保持蓝色“公平线”平直且高企。Baseline 和 FEBS 模型在边缘 (T1 和 T4) 显著下降。定性图像 (b) 证实了这一点: 看 T4 那一行。dMoE 的分割 (绿色覆盖) 比其他方法更接近真值 (Ground Truth)。
效率分析
有人可能会问: “为什么不直接为每个群体训练单独的模型呢?” 作者比较了 dMoE 与训练多个独立网络的效果。

如 表 8 所示,dMoE 不仅更准确 (ES-Dice 0.499 vs 0.457) ,而且效率大幅提高 (1761 GFlops vs 5729 GFlops) 。通过在“专家”中共享知识,同时通过“门控网络”进行路由,dMoE 获得了两全其美的效果: 专业化与共享学习。
结论与启示
分布感知混合专家模型 (dMoE) 代表了医疗伦理 AI 向前迈出的重要一步。通过从 控制理论 的视角退一步审视神经网络,作者发现解决公平性问题不仅仅是向模型提供更多数据——而是要赋予模型基于上下文 (人口统计学或疾病状态) 调整其策略的 机制 。
主要收获:
- 上下文至关重要: 将属性 (种族、年龄、分期) 输入模型的路由层,允许进行动态适应。
- 理论指导实践: 模式切换控制的解释说明了 为什么 MoE 结构对异构数据有效。
- 绝不妥协: dMoE 在不降低多数群体表现的情况下提高了少数群体的表现,解决了“公平性与准确性的权衡”问题。
虽然这项研究侧重于单一属性,但未来在于处理交叉偏见 (例如,年龄 和 种族相结合) 。随着人工智能继续融入临床工作流程,像 dMoE 这样的框架对于确保这些强大的工具能够公平地服务于 每一位 患者,而不仅仅是“平均”患者,将是至关重要的。