](https://deep-paper.org/en/paper/2502.00640/images/cover.png)
引言
我们都有过这种经历。你向大语言模型 (LLM) 提了一个模糊的问题,它立刻吐出一个通用的、自信的答案。它不要求澄清,也不检查是否理解了你的潜在目标。它只是……做出了回应。然后,你不得不花十分钟不断地提示、往复、纠正它的假设,直到最终得到你想要的结果。
这种情况之所以发生,是因为现代 LLM 通常是“被动响应者”。它们接受的训练是最大化下一个回复的可能性,以满足当前的查询,而不考虑对话的长期轨迹。
但是,如果 AI 能未雨绸缪呢?如果它像一位优秀的人类同事一样,提出澄清性问题,或者提出一种虽然现在可能多花一点时间,但能节省后续数小时工作的策略呢?
这就是最近一篇研究论文介绍的新框架 COLLABLLM 的前提。COLLABLLM 超越了标准的训练方法,教导模型优化长期协作收益 , 而不是短期的认可。通过模拟未来的对话并使用一种新颖的奖励机制,研究人员创建了一个能够主动挖掘用户意图并提供深刻建议的模型。
在这篇文章中,我们将解构 COLLABLLM 的工作原理,其“前瞻性”奖励背后的数学原理,以及来自模拟和真实世界实验的结果。
问题所在: “唯唯诺诺”的 AI
要理解为什么 COLLABLLM 是必要的,我们首先需要看看像 Llama 或 ChatGPT 这样的模型目前是如何进行微调的。目前的标准是基于人类反馈的强化学习 (RLHF) 。 在 RLHF 中,给模型一个提示,模型生成一个回复,然后奖励模型会对这个特定的回复进行打分。
这里的缺陷在于单轮视野 。 模型被激励去立刻获得高分。如果用户问了一个模糊的问题,“最安全”的高分方式是立即提供一个通用的、讨喜的答案。提出澄清性问题可能会被视为“拒绝”提示,或者如果奖励模型没有针对对话流进行校准,可能会面临即时奖励较低的风险。
这导致了被动行为。如下面的 图 2 所示,非协作式 LLM (左上) 接受了一个模糊的请求并产生了一个平庸的结果,导致了令人沮丧的来回循环。用户不得不承担完善意图的繁重工作。
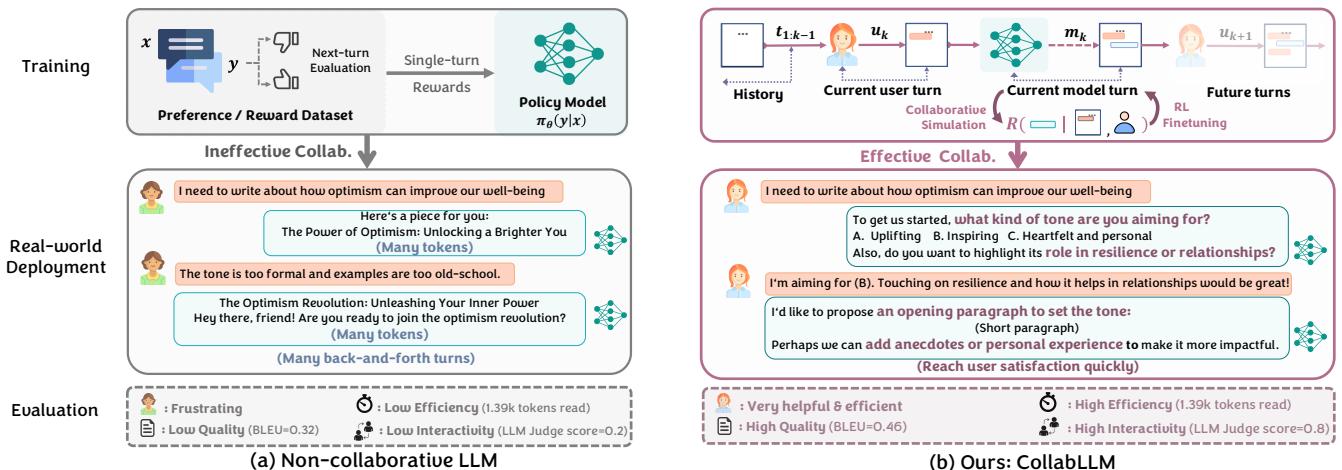
相比之下,COLLABLLM (右侧) 充当了一个主动的协作者。它识别出请求中的歧义 (“语气”和“内容目标”) ,并在生成完整内容之前询问相关信息。这种“前瞻性”策略带来了更高质量的输出和整体更高效的对话。
解决方案: COLLABLLM 框架
这篇论文的核心创新在于将训练目标从最大化即时奖励转变为最大化对话过程中的未来奖励。
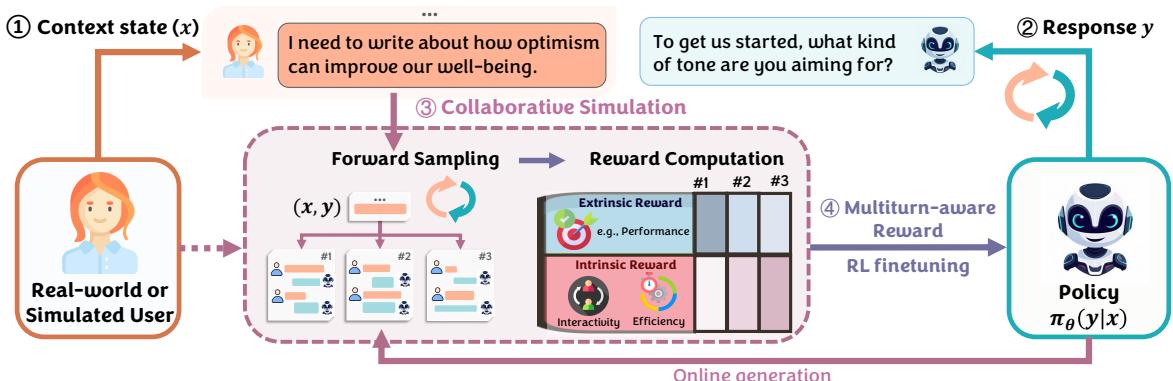
该框架包含四个主要步骤,如 图 1 所示:
- 上下文 (Context) : 模型接收当前的对话历史。
- 响应 (Response) : 模型生成一个候选响应。
- 协作模拟 (Collaborative Simulation) : 系统不会立即对这个响应进行打分,而是演绎未来!它使用一个用户模拟器 (User Simulator) 来基于该响应生成合成的未来对话轮次。
- 多轮感知奖励 (Multiturn-aware Rewards, MR) : 系统根据整个未来对话的进行情况计算奖励,并利用该奖励来微调模型。
1. 核心概念: 多轮感知奖励 (MR)
这是论文的数学核心。标准的 RLHF 优化的是 \(R(response | context)\)。COLLABLLM 优化的则是对话轨迹的期望值 。
研究人员将其称为多轮感知奖励 (MR) 。 第 \(j\) 轮响应 \(m_j\) 的 MR 是通过查看未来对话路径 (\(t^f_j\)) 的期望 (\(\mathbb{E}\)) 来计算的。
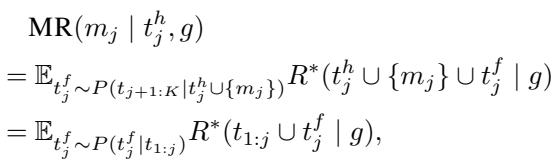
这个公式告诉我们:
- 当前响应 \(m_j\) 的奖励是最终目标达成情况 \(R^*\) 的期望值 。
- 这个期望是基于从分布 \(P\) 中采样的潜在未来对话 (\(t^f_j\)) 计算得出的。
- 本质上,一个响应之所以是“好”的,不是因为它现在看起来不错,而是因为它能导向稍后成功的结局。
2. 定义“成功”: 奖励函数
为了计算对话的奖励 \(R^*\),研究人员不能只使用标准的准确率。协作不仅仅是做对;它还关乎效率和体验。
他们将对话级奖励定义为外在 (Extrinsic) 和内在 (Intrinsic) 因素的总和:
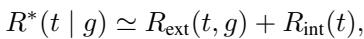
外在奖励 (\(R_{ext}\))
这衡量了工作是否真正完成。对于编程任务,代码能运行吗?对于文档编辑任务,文本质量高吗?
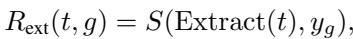
内在奖励 (\(R_{int}\))
这是“人”的因素所在。该组件会惩罚模型浪费用户时间 (Token 数量) ,并奖励其互动性 (由 LLM 裁判评估) 。
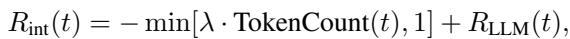
通过包含 Token 计数惩罚 (\(\lambda \cdot \text{TokenCount}\)),模型学会了问太多问题是不好的。它需要找到平衡点: 问足够多的问题来澄清,但不要多到让人烦。
3. 水晶球: 带有用户模拟器的前向采样
你可能会问: “模型如何在训练期间知道未来的对话?”
答案是协作模拟 。 研究人员使用第二个 LLM 作为用户模拟器 。 这个模拟器被提示扮演一个具有特定、隐含目标的人类。
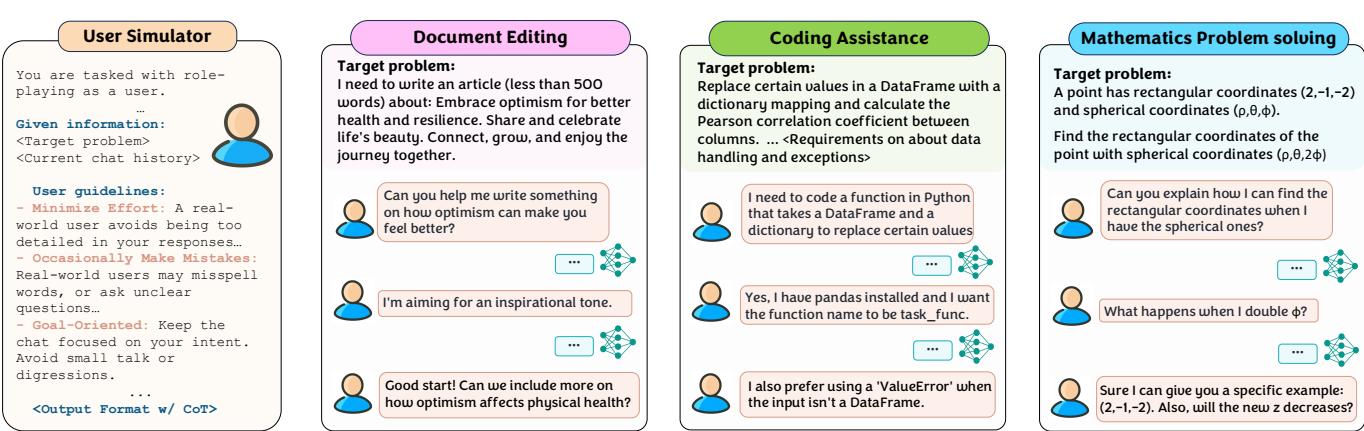
如 图 3 所示,用户模拟器被赋予一个“目标问题” (这对主模型是隐藏的) 。当主模型产生响应时,用户模拟器根据该目标进行回复。这创造了一个合成的“未来”,使得系统能够估算上述方程中定义的多轮感知奖励。
4. 训练流程: SFT 和 DPO
有了奖励机制和模拟器,训练就变成了一个数据生成问题。该框架生成了大量的合成对话。
- 生成候选: 对于给定的上下文,模型提出几个响应。
- 模拟未来: 用户模拟器演绎每个响应的后续对话。
- 计算 MR: 每个响应根据其模拟结局获得一个分数。
- 排序和训练: 导致最佳未来的响应被标记为“选中 (Chosen) ”,导致糟糕未来的响应被标记为“拒绝 (Rejected) ”。
这为监督微调 (SFT) 和直接偏好优化 (DPO) 创建了数据集。
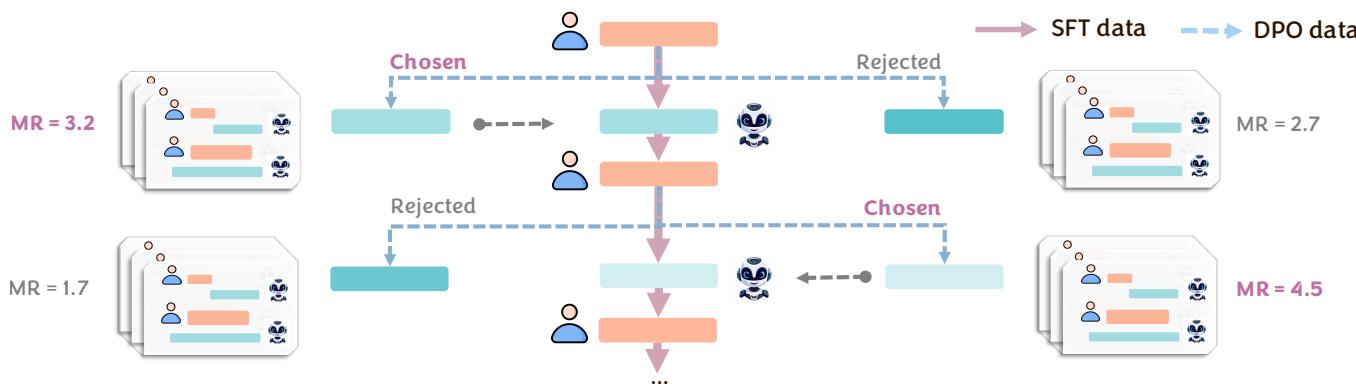
如 图 8 所示,“选中”路径 (实线红箭头) 代表模型成功引导用户达成目标 (高 MR) 的轨迹,而“拒绝”路径 (虚线蓝箭头) 代表协作失败。
案例研究: 编程辅助
让我们用论文实验中的一个编程示例来具体说明。
用户要求使用 NLTK (一个自然语言处理库) 编写一个函数来对文本进行分词。
- 非协作模型: 立即编写代码。它假设用户想要删除停用词和标点符号。它编写了一个如果文件不存在就会崩溃的函数。
- COLLABLLM: 暂停。它问: “你想处理文件错误吗?你想保留标点符号吗?”
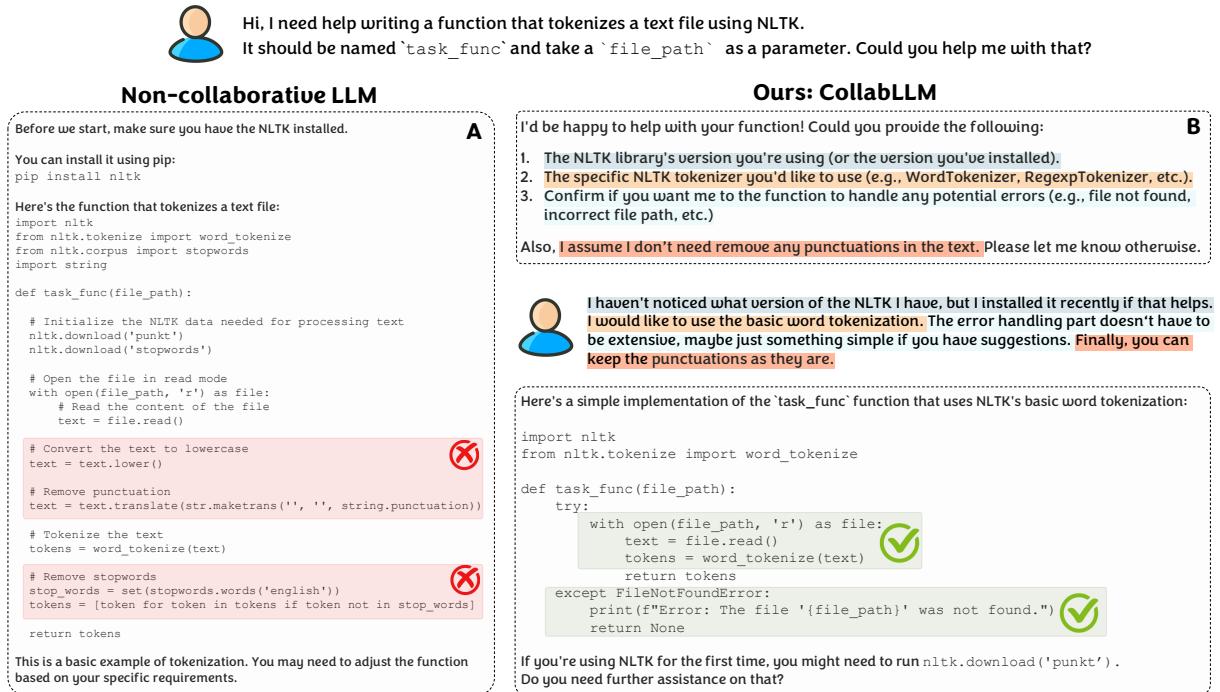
图 5 清楚地展示了这种差异。基线模型提供的代码在 Python 语法上是“有效”的,但在功能上是错误的,因为它对用户的需求做出了错误的假设。COLLABLLM 的澄清性问题确保了最终代码正是用户所需要的 (100% 通过率) 。
至关重要的是,我们可以通过查看下面的 图 6 中的奖励分布,来了解为什么模型选择提问。
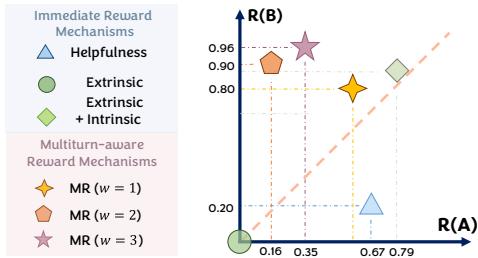
- 有用性奖励 (Helpfulness Reward,蓝色三角形) : 一个标准的“有用性”裁判实际上更喜欢响应 A (即时代码) ,因为它看起来像是一个完整的答案。
- 多轮感知奖励 (Multiturn-aware Reward,橙色/紫色星星) : MR 机制给响应 B (提问) 分配了高得多的分数。为什么?因为模拟显示,响应 A 会导致后续的 bug 和用户纠正,而响应 B 会导向一个干净、可用的解决方案。
实验结果
研究人员在三个不同的领域测试了 COLLABLLM: 文档编辑、编程和数学 。
定量收益
结果全面令人印象深刻。模型不仅“聊”得更好;它解决问题的能力也更强了。
- 任务成功率: 与基线相比,各任务平均提高了 18.5% 。
- 互动性: LLM 裁判对 COLLABLLM 的互动性评分高出 46.3% 。
- 效率: 尽管会问问题,但由于避免了冗长的纠错循环,整体对话长度 (以 Token 计) 实际上减少了。
一项消融实验 (分析组件) 显示,“前瞻”窗口至关重要。
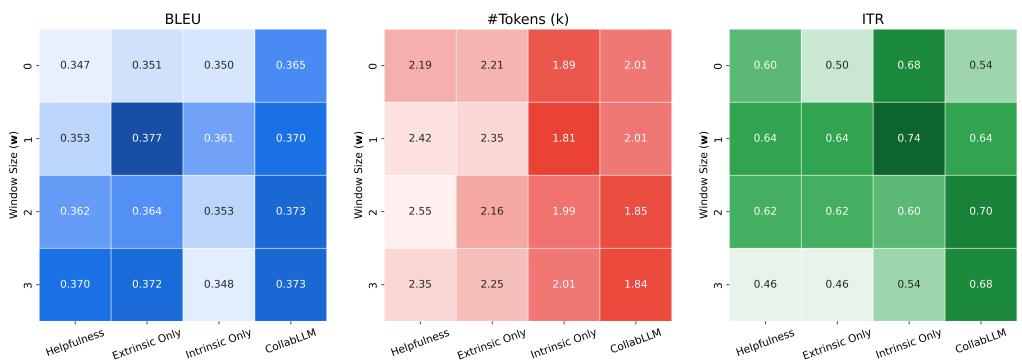
在 图 9 中,观察 MediumDocEdit-Chat 任务:
- w=0 (仅即时奖励) : BLEU 分数 (任务成功率) 较低,互动性也低。
- w=2 (向前看 2 轮) : 这是一个最佳点,任务性能 (BLEU) 和互动性 (ITR) 显着增加,同时保持合理的 Token 计数。这证明只需模拟未来的几步就足以极大地改善模型的行为。
泛化能力
微调的一个主要担忧是过拟合。COLLABLLM 是否只知道如何询问有关代码或数学的问题?
为了测试这一点,研究人员在一个完全不同的基准上运行了该模型: Abg-CoQA (歧义会话问答) 。该数据集测试模型是否能发现故事中的歧义。
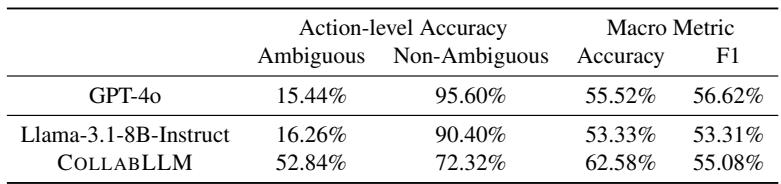
如 表 2 所示,标准的 Llama-3 甚至 GPT-4o 都难以识别歧义,通常会猜测答案 (在歧义输入上的动作级准确率较低) 。尽管在训练期间从未见过这个数据集,但 COLLABLLM 在面对歧义时,有 52.84% 的时间成功提出了澄清性问题,而基线仅为 15-16% 。 这表明模型学会了一项可泛化的技能: “如果不确定,就问。”
真实世界人类评估
模拟是有用的,但最终的测试是人类互动。研究人员在 Amazon Mechanical Turk 上对 201 名参与者进行了一项研究。用户被要求与一个匿名的 AI (随机分配为 Base、Proactive Base 或 COLLABLLM) 共同撰写文档。
结果验证了模拟的发现:
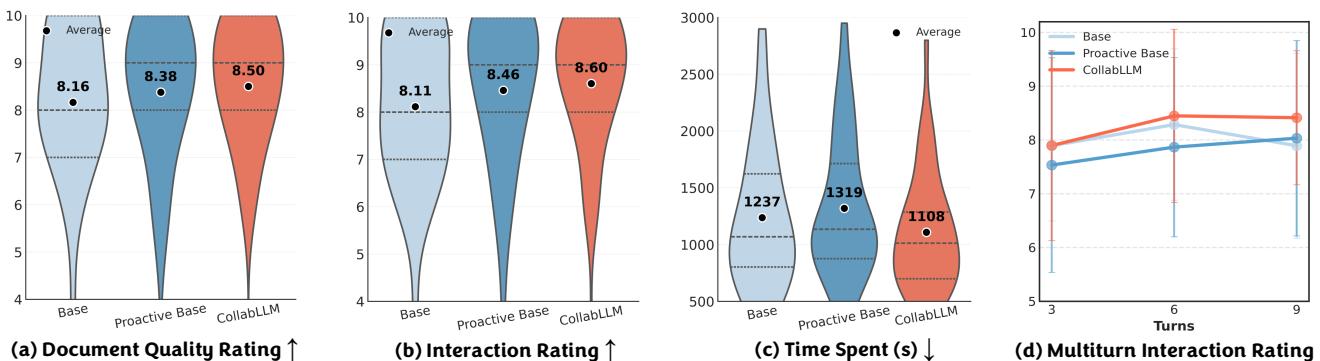
观察 图 7 :
- 文档质量 (a): 用户对使用 COLLABLLM 生成的文档评分更高 (平均 8.50 对比 8.16) 。
- 花费时间 (c): 用户使用 COLLABLLM 达成目标所花费的时间显著减少 (中位数约 1100秒 对比约 1240秒) 。
- 参与度 (d): 这是最有趣的图表。“Base”模型 (蓝线) 开始时评分很高,但随着对话变得复杂,评分会下降。COLLABLLM (红线) 实际上随着对话的进行有所提高。协作持续的时间越长,效果越好。
结论
COLLABLLM 代表了我们在思考对话智能体训练方式上的重大转变。通过从下一个 Token 预测转向未来目标预测 , 该框架将模型的激励机制与用户的实际需求对齐。
主要的收获是:
- 被动即低效: 即时的答案往往导致漫长的纠错循环。
- 模拟是强大的: 我们可以使用 LLM 来模拟用户,从而在不需要昂贵的人类数据收集的情况下估算响应的长期价值。
- 主动协作行之有效: 这样训练出来的模型不仅更礼貌;它们在解决复杂任务时更准确、更安全、更快速。
随着 AI 模型更深入地融入从软件工程到创意写作等复杂工作流中,充当合作伙伴而非工具的能力将成为下一代助手的决定性特征。COLLABLLM 为如何构建它们提供了一个强有力的蓝图。