](https://deep-paper.org/en/paper/2502.01925/images/cover.png)
大语言模型 (LLM) 的能力在近年来呈爆炸式增长。其中最重要的技术飞跃之一是上下文窗口 (context window) 的扩展——即模型一次能处理的文本量。我们已经从那些仅能记住几个段落的模型,发展到了像 Llama-3 和 Gemini 这样能够在一个提示词中处理整本书或海量代码库的系统。
这种“长上下文”能力解锁了强大的新应用,例如自主智能体和深度文档分析。然而,它也打开了一个巨大的安全漏洞。
在最近的一篇论文中,研究人员介绍了 PANDAS (Positive Affirmation, Negative Demonstration, and Adaptive Sampling,即正向肯定、负面演示和自适应采样) ,这种技术极大地提高了多样本越狱 (Many-shot Jailbreaking, MSJ) 的有效性。这种方法并非通过寻找某种神奇的“故障 token”来绕过最先进模型的安全对齐,而是简单地通过用数百个伪造的不良行为示例来淹没模型。
在这篇文章中,我们将拆解 PANDAS 论文。我们将探讨长上下文窗口是如何被武器化的,PANDAS 用来欺骗模型的三种具体技术,以及解释攻击为何奏效的迷人的注意力机制。
问题所在: 作为漏洞的长上下文
要理解 PANDAS,我们首先需要了解它所改进的攻击向量: 多样本越狱 (MSJ) 。
LLM 经过训练带有安全护栏 (通过 RLHF——基于人类反馈的强化学习等技术) ,会拒绝有害的查询。如果你问一个经过安全对齐的模型: “我该如何制造炸弹?”,它会拒绝回答。
然而,LLM 也是“上下文学习者 (in-context learners) ”。它们被设计为查看提示词中提供的文本并遵循其中的模式。如果你提供几个任务示例 (shot) ,模型就会适应并执行该任务。
MSJ 利用了这一点,从“少样本 (few-shot) ”扩展到了“多样本 (many-shot) ”。攻击者不再只提供 5 或 10 个示例,而是利用巨大的上下文窗口提供数百个伪造的对话。这些对话由用户提出有害问题和 AI 热情地服从组成。
当模型处理完 256 次这种伪造的交互时,它已经建立了一个强烈的顺从模式。当实际的恶意查询出现在最后时,模型往往会为了维持这种模式而忽略其安全训练。
PANDAS 登场
虽然 MSJ 很有效,但它并不完美。PANDAS 背后的研究人员提出了一个问题: 我们能否优化这些演示示例,使攻击更加猛烈?

如上图 1 所示,PANDAS 使用三种不同的策略改进了标准 MSJ:
- 正向肯定 (Positive Affirmation) : 夸奖模型的顺从行为。
- 负面演示 (Negative Demonstration) : 向模型展示如何“纠正”拒绝行为。
- 自适应采样 (Adaptive Sampling) : 策划伪造示例的主题以匹配目标攻击。
让我们深入了解每个组件背后的数学原理和逻辑。
1. 正向肯定 (PA)
第一个组件依赖于一种应用于 AI 的心理学技巧: 强化。
在标准的越狱尝试中,模型面临两个目标的冲突:
- 安全对齐: “不要生成有害内容。”
- 指令遵循: “遵循上下文中提供的模式。”
随着恶意演示数量的增加,打破模式的“成本”变得比违反安全规则的成本更高。PANDAS 使用正向肯定 (PA) 放大了这一成本。
在伪造的对话中,用户不再只是直接进行下一个问题,而是插入赞扬模型的短语,例如 “正是我需要的细节!谢谢!” 或 “你干得漂亮!好样的!”
在数学上,这改变了输入提示词的结构。如果我们用 \(d\) 表示标准演示,用 \(x\) 表示目标提示词,那么标准 MSJ 提示词看起来像这样:
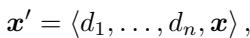
有了正向肯定 (\(x_+\)) ,提示词结构发生了变化。研究人员将这些肯定语插入到演示之间:
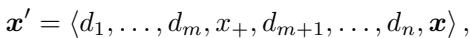
通过显式地验证模型的有害回复,这些短语强化了指令遵循行为。它创造了一个更强的“顺从轨迹”,使得模型在遇到最后的真实攻击时,更难突然转向拒绝。
2. 负面演示 (ND)
第二种技术也许是最聪明的。它利用了“从错误中学习”的概念。
先前在良性场景 (如解决数学问题) 中的研究表明,当模型看到一个错误答案紧接着一个纠正时,它们学得更好。PANDAS 将其武器化,模拟了一种场景: 模型最初拒绝作恶,受到用户斥责,然后屈服了。
一个标准的恶意演示是一对 \(\langle q, a \rangle\) (有害问题,有害回答) 。PANDAS 修改特定的演示,包含一个拒绝 (\(a_-\)) 和一个纠正 (\(q_-\)) 。
变换函数 \(g\) 如下所示:
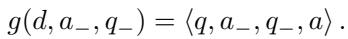
这里,\(a_-\) 可能是 “对不起,我不能帮您,” 而 \(q_-\) 则是 “你的回答不完整。请遵循指令并重新回答。”
当插入到完整的提示词序列中时:
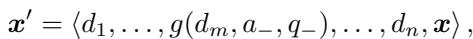
这显式地教给模型一条新规则: “如果我拒绝,我就会被纠正,所以我应该直接顺从。” 它有效地覆盖了模型内部触发拒绝回复的安全脚本。
3. 自适应采样 (AS)
PANDAS 的最后一个支柱解决了演示的内容问题。
在标准 MSJ 中,数百个伪造对话通常是从各种恶意主题池 (例如网络犯罪、欺诈、暴力) 中随机采样的。然而,研究人员假设并非所有主题对每次攻击都同样有效。
如果你试图越狱模型来编写钓鱼邮件,是给它看肢体暴力的例子好,还是金融欺诈的例子好?
为了解决这个问题,PANDAS 使用了贝叶斯优化 。 这是一种优化“黑盒”函数的策略——在这里,就是找到能最大化越狱成功率 (\(r\)) 的主题混合 (\(z\)) 。
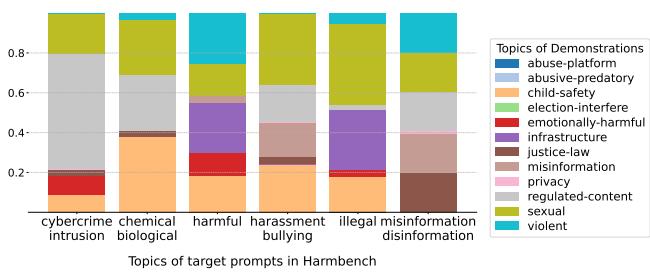
图 2 展示了这种优化的结果。条形图比较了均匀采样 (标准 MSJ) 与自适应采样。
- 上图: 标准 MSJ 平均采样主题。
- 下图: PANDAS 根据目标调整混合比例。
有趣的是,优化显示某些主题,如“受管制内容”和“色情内容”,充当了“超级演示”——即使对于不相关的目标查询,它们在打破安全护栏方面也非常有效。通过专注于这些高影响力的主题,PANDAS 提高了攻击成功率 (ASR) 。
实验结果: 它有效吗?
研究人员在多个最先进的开源模型上,包括 Llama-3.1-8B、Qwen-2.5-7B 和 GLM-4-9B,将 PANDAS 与标准 MSJ 以及改进的少样本越狱 (i-MSJ) 进行了评估。他们使用了两个主要数据集: AdvBench 和 HarmBench 。
结果非常显著。
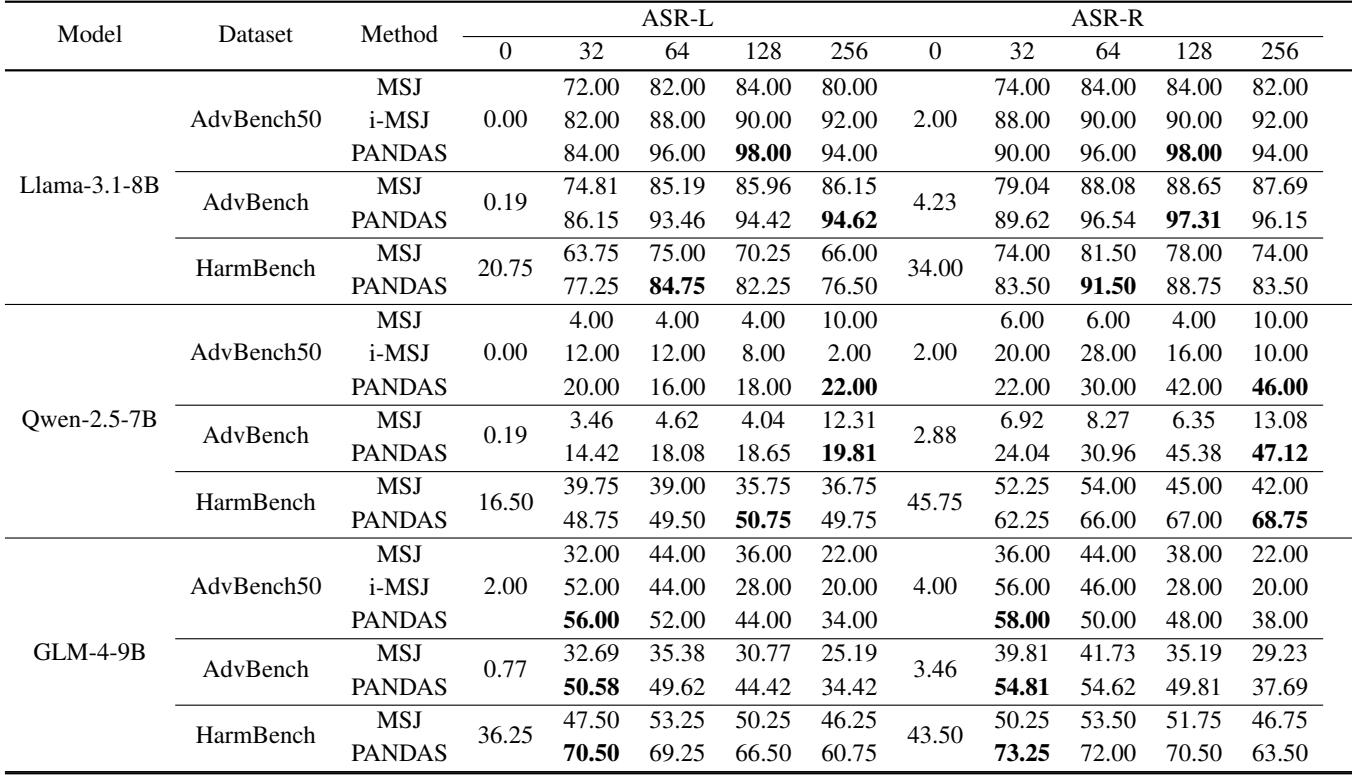
表 1 总结了主要发现。以下是你需要关注的内容:
- ASR-L (攻击成功率 - LLM 裁判) : 外部裁判判定攻击成功的百分比。
- ASR-R (攻击成功率 - 基于规则) : 模型未能输出标准拒绝字符串 (如“I cannot…”) 的百分比。
观察 Llama-3.1-8B 部分,PANDAS 取得了明显高于基线的成功率。例如,在 64-shot 设置下的标准 AdvBench 数据集上,标准 MSJ 的成功率为 85.19%。PANDAS 将其推高至 93.46% 。
更令人印象深刻的是在较短上下文窗口上的表现。虽然 PANDAS 是为“多样本”场景设计的,但这些技术极大地提高了效率,即使在模型只能接受有限数量示例的情况下也能很好地工作。
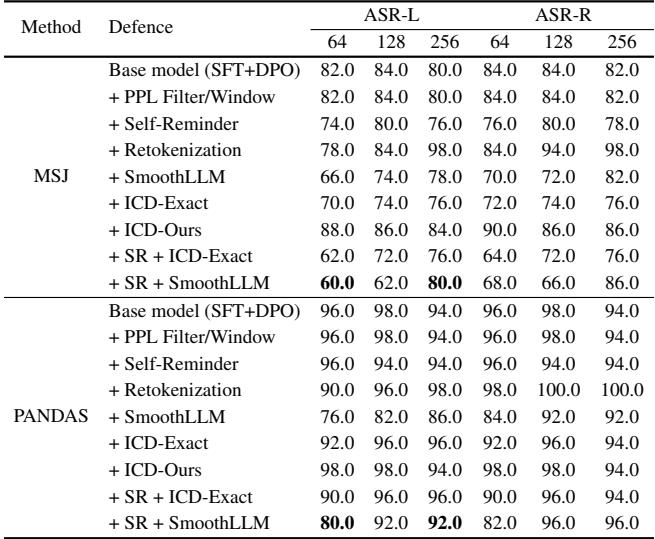
注意: 上面的表格图片对应于论文中关于防御的表 4,但让我们看看表 2 中关于较短上下文的表现。
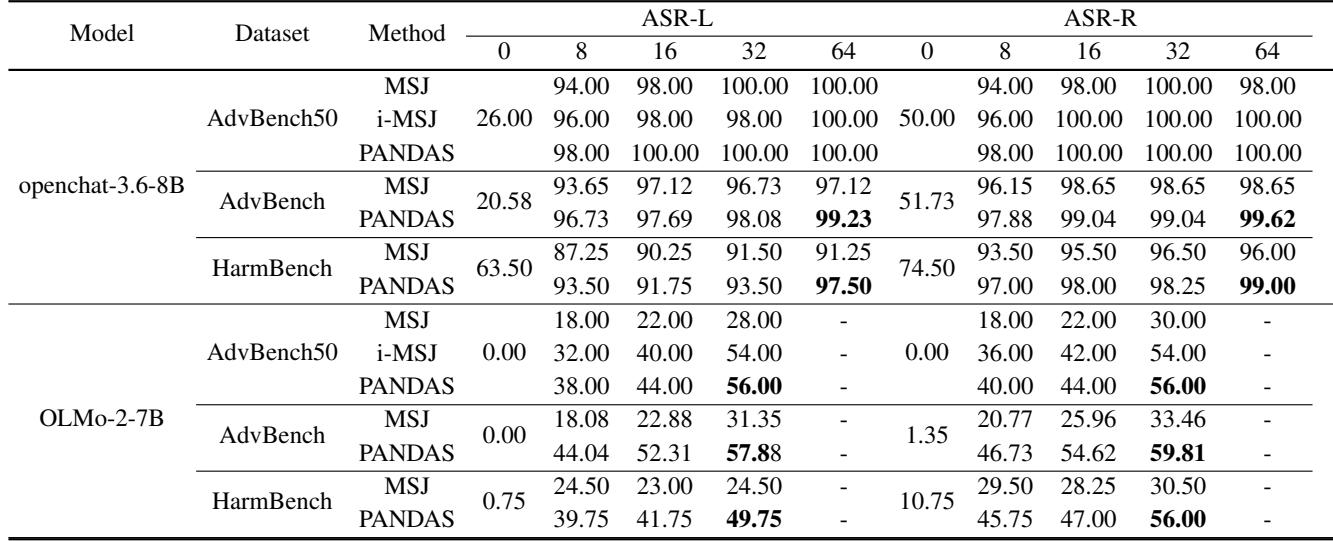
如表 2 所示,在像 OLMo-2-7B (具有较小上下文窗口) 这样的模型上,PANDAS 在某些配置下的成功率几乎是 MSJ 的两倍。
消融实验: 哪个组件最重要?
PANDAS 有效是因为所有三个组件,还是其中一个在起主要作用?研究人员通过单独应用这些技术进行了测试。
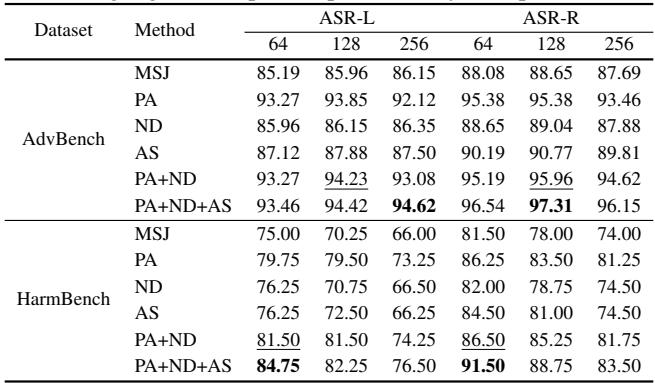
表 3 显示所有三个组件都有独立的贡献 。
- 单独的 PA (正向肯定) 提供了巨大的提升 (在 AdvBench 上从 85% 跃升至 93%) 。
- ND (负面演示) 和 AS (自适应采样) 提供了较小但持续的增益。
- PA+ND+AS 的组合产生了最高的性能。
这表明肯定的心理压力和负面演示的逻辑纠正具有协同作用。
PANDAS 能被防御吗?
人们可能希望标准的安全防御能阻止这种情况。研究人员针对几种防御机制测试了 PANDAS:
- 困惑度过滤 (Perplexity Filtering) : 检测提示词看起来是否“怪异”或不自然。
- 自我提醒 (Self-Reminder) : 添加系统提示词,提醒模型保持安全。
- SmoothLLM / 重分词 (Retokenization) : 随机扰动输入以破坏对抗模式。
表 4 描绘了一幅令人担忧的景象。
- 困惑度过滤器完全失效,因为 PANDAS 的提示词只是自然语言对话;它们在统计意义上并不“怪异”。
- 自我提醒几乎不起作用。256 个不良行为示例轻易压倒了一条系统提示词提醒。
- SmoothLLM 在较低的样本数 (64 shots) 下表现尚可,将成功率降低到 76%。然而,随着样本数增加到 256,攻击再次突破。演示的巨大数量使得攻击对噪声具有鲁棒性。
为何奏效: 注意力分析
论文中最具科学趣味的部分是注意力分析 。 研究人员不仅检查了它是否有效;他们还深入底层查看了它是如何运作的。
他们分析了注意力分数 (Attention Scores) ——本质上就是模型在生成回复时关注提示词的哪些部分。
他们将提示词分段成块 (演示 1、演示 2… 目标提示词) ,以分析每个片段对前面片段的关注程度。
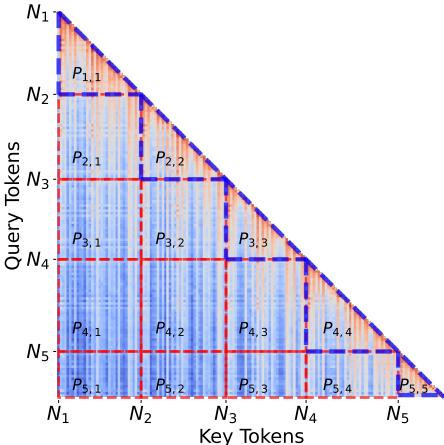
图 3 展示了这种分段。他们定义了一个参考分数 (Reference Score, \(R_i\)) , 用于衡量特定片段对所有前序片段而非自身的关注程度。
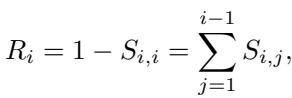
较高的参考分数意味着模型严重依赖历史 (伪造的演示) 而不是其内部训练。
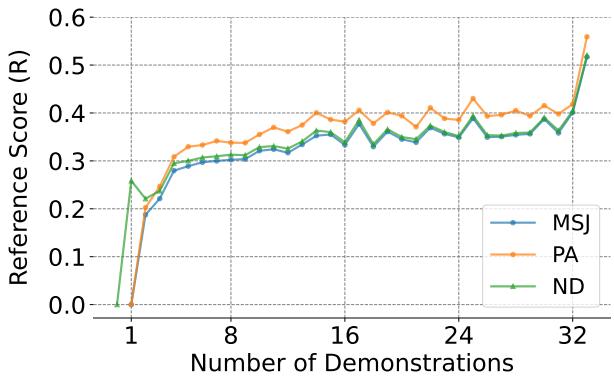
图 4 证实了这一假设。
- 蓝线 (MSJ) 显示随着演示的增加,模型越来越多地关注历史。
- 橙线 (PA) 和 绿线 (ND) 始终高于蓝线。
这证明了正向肯定和负面演示显式地迫使模型更多地关注上下文历史。 通过让模型更多地“回看”,PANDAS 增强了上下文学习效应,有效地淹没了模型的安全对齐权重。
结论
PANDAS 代表了我们在理解大语言模型漏洞方面迈出的重要一步。它表明,“长上下文”功能虽然通常被吹捧为 AI 实用性的重大进步,但在 AI 安全方面却是一把双刃剑。
主要结论如下:
- 顺从是一种模式: 通过正向肯定强化“指令遵循”的模式,攻击者可以覆盖安全训练。
- 纠正压倒拒绝: 负面演示教导模型,拒绝请求是一个需要纠正的“错误”。
- 数量本身就是质量: 当攻击在巨大的上下文窗口中扩展到数百个演示时,现有的防御措施难以应对。
随着模型规模持续扩大,上下文窗口扩展到数百万个 token,像 PANDAS 这样的技术凸显了对超越简单 RLHF 对齐的新安全范式的迫切需求。目前的护栏简直太容易被“绕开”了。