](https://deep-paper.org/en/paper/2502.04313/images/cover.png)
引言
我们正见证一个机器学习模型飞速进步的时代。通过扩大训练数据和计算规模,能够通过律师资格考试、编写代码并解决复杂逻辑难题的大型语言模型 (LLM) 得以诞生。但随着这些模型接近甚至超越人类能力,我们面临一个瓶颈: 评估 。
我们如何监督一个比我们更聪明或更快的系统?收集高质量的人类标注既缓慢又昂贵。业界的答案是“AI 监督 (AI Oversight) ”——用一个 AI 来给另一个 AI 评分或教学。我们在“LLM 即裁判 (LLM-as-a-judge) ”排行榜和“弱至强 (Weak-to-Strong) ”泛化实验中都看到了这种做法。
但依赖 AI 来监管 AI 存在隐患。
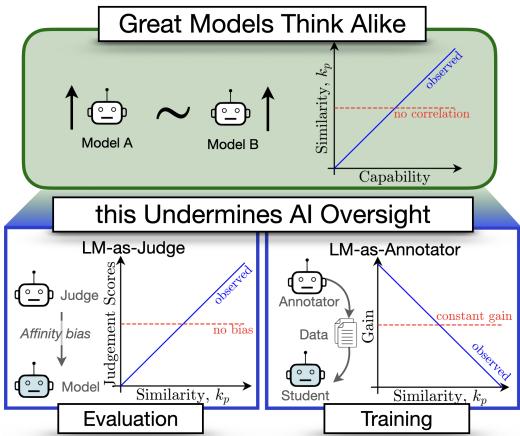
在一篇题为 Great Models Think Alike and this Undermines AI Oversight 的精彩新论文中,研究人员探讨了一个关键问题: 模型之间的相似性是否会影响它们相互监督的效果?
他们的发现揭示了一个令人担忧的悖论。多样性对于有效的监督至关重要,但随着模型能力越来越强,它们的错误正变得越来越相关。在本文中,我们将拆解他们用于衡量模型相似性的新指标 CAPA,并探讨“英雄所见略同”为何可能实际上成为 AI 未来的安全风险。
第一部分: 如何衡量模型相似性?
要了解模型是否“思维相似”,我们需要一种严谨的相似性衡量方法。你可能认为我们可以直接查看它们的权重或架构,但这并不能告诉我们它们的行为方式。相反,研究人员关注的是功能相似性 (Functional Similarity) ——比较模型针对相同输入生成的输出。
现有指标的问题
一种常见的方法是查看错误一致性 (Error Consistency) 。 简而言之,如果模型 A 和模型 B 都答错了一道题,它们会选择同一个错误答案吗?
然而,现有指标应用于 LLM 时存在缺陷:
- 因准确率而膨胀: 两个聪明的模型仅仅因为都答对了,就会经常达成一致。我们需要衡量的是超出基于其准确率所预期的相似性。
- 二元局限性: 大多数指标将答案视为对或错。但 LLM 输出的是概率。如果模型 A 对某个答案的置信度为 51%,而模型 B 为 49%,它们在功能上是相似的,即使二元指标视之为“翻转”。
研究人员提出了一个新指标来解决这个问题: 机会调整概率对齐 (Chance Adjusted Probabilistic Alignment, CAPA) , 记作 \(\kappa_p\)。
介绍 CAPA
CAPA 的设计旨在满足以前指标所忽略的三个关键要求。
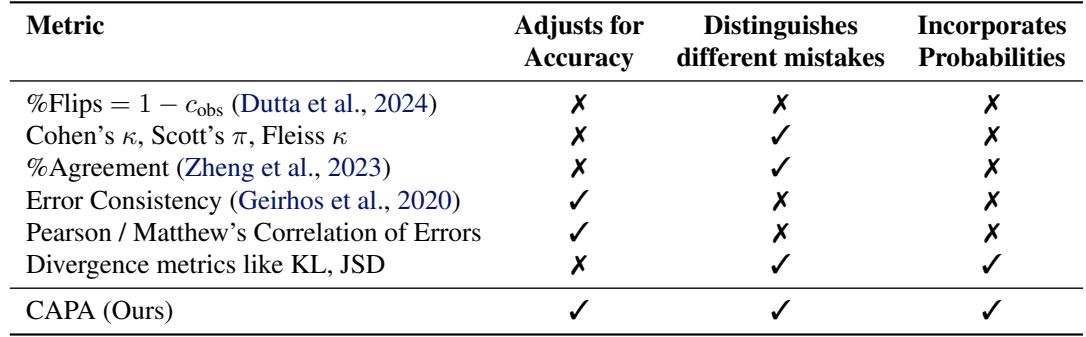
CAPA 的数学基础扩展了标准的一致性指标 (如 Cohen’s Kappa) 。此类指标的通用形式为:
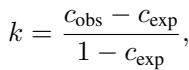
其中 \(c_{obs}\) 是观察到的一致性,\(c_{exp}\) 是偶然预期的一致性。CAPA 在这两个组件的计算方式上进行了创新。
1. 概率观察一致性 (\(c_{obs}^p\))
CAPA 不仅仅检查两个模型是否输出相同的文本字符串,而是查看选项上的概率分布。它计算两个模型分配给每个选项的概率的重叠 (点积) 。
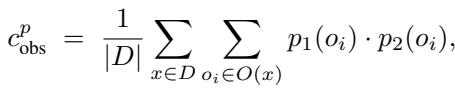
这捕捉到了细微差别。如果两个模型都给同一个错误选项分配了高概率,那么相比二元检查,该指标能更好地捕捉这种“共同的困惑”。
2. 机会一致性 (\(c_{exp}^p\))
这是推导中最关键的部分。我们预期高准确率的模型经常会在正确答案上达成一致。我们要衡量的是它们超出这一预期的一致程度。
研究人员通过假设两个独立模型来定义机会一致性。一个独立模型基于其总体准确率 (\(\bar{p}\)) 为正确答案分配概率,并将剩余概率均匀分布在错误选项中。

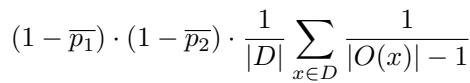
该公式有效地将计算分为两部分:
- 正确选项上的机会一致性: 仅仅是它们准确率的乘积。
- 错误选项上的机会一致性: 它们都猜错的概率,并根据可用选项的数量进行归一化 (假设错误的分布是均匀的) 。
最终指标
结合这些,我们得到最终的 CAPA 分数:
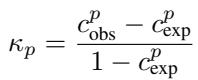
CAPA 分数为 0 意味着模型的一致程度与基于其准确率预期的两个独立模型完全一致。分数接近 1 意味着它们高度相关——它们犯同样的错误。
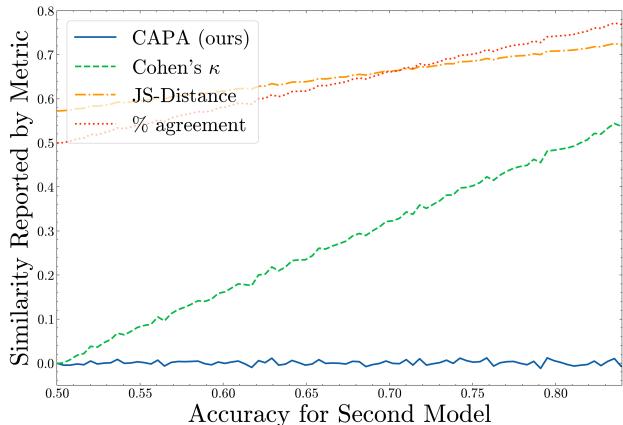
为了证明这一点,作者进行了一次模拟。他们选取了两个独立模型——意味着它们的错误是不相关的。如下图所示,随着模型准确率的提高,像 Cohen’s Kappa 或简单的百分比一致性 (% Agreement) 等指标会错误地升高。然而,CAPA 正确地保持在 0,因为模型在功能上并不相似;它们只是都变得更聪明了。
第二部分: 自恋的裁判 (评估)
既然我们有了一把可靠的尺子 (CAPA) ,让我们来测量一下。
AI 领域的一个流行趋势是“LLM 即裁判 (LLM-as-a-Judge) ”。我们不再花钱请人给聊天机器人的回复打分,而是让一个强大的模型 (如 GPT-4 或 Llama-3-70B) 来打分。假设前提是,聪明的模型是客观的裁判。
研究人员在 MMLU-Pro 基准测试上对此进行了测试。他们让各种“裁判”模型评估其他模型的回答。然后,他们比较了判断分数 (裁判给模型打的分) 与裁判和模型之间的相似度 (CAPA) 。
结果: 亲和性偏差
结果揭示了显著的亲和性偏差 (Affinity Bias) 。 裁判系统性地给予那些在功能上与自己相似的模型更高的分数。
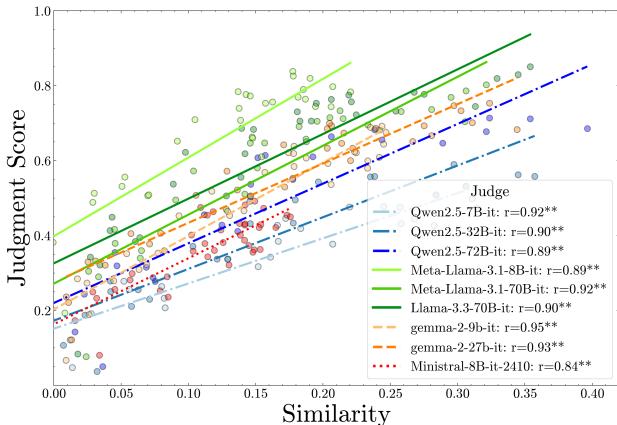
在上图中,每条线代表一个不同的裁判模型。你可以看到一个明显的上升趋势: 模型与裁判越相似 (X 轴越高) ,它得到的分数就越高 (Y 轴越高) 。
这不仅仅是因为相似的模型更聪明。研究人员使用了统计控制 (偏相关分析) 来排除模型准确率的影响。即使控制了模型能力这一因素,偏差依然存在。裁判本质上是在说: “你犯了和我会犯的一样的错误?那我觉得是对的!”
为何这很重要: 如果我们用 GPT-4 来评估下一代模型,而下一代模型又是为了最大化该分数而训练的,我们可能会不知不觉地培育出与 GPT-4 共享盲点的模型,而不是客观上更好的模型。
第三部分: 学生与老师 (训练)
AI 监督不仅关于评分,还关于教学。一种名为弱至强 (Weak-to-Strong) 泛化的有前途的技术涉及使用较小、较弱的模型 (监督者) 来标注数据,然后用这些数据训练较大、较强的模型 (学生) 。令人惊讶的是,强学生通常表现优于弱监督者。
研究人员假设,当学生和监督者拥有互补知识 (Complementary Knowledge) 时,这种方法效果最好。如果学生已经知道了监督者所知道的内容,那么监督就是多余的。
相似度与性能增益
为了验证这一点,他们在弱监督者的标注上微调强学生模型,并测量性能增益。
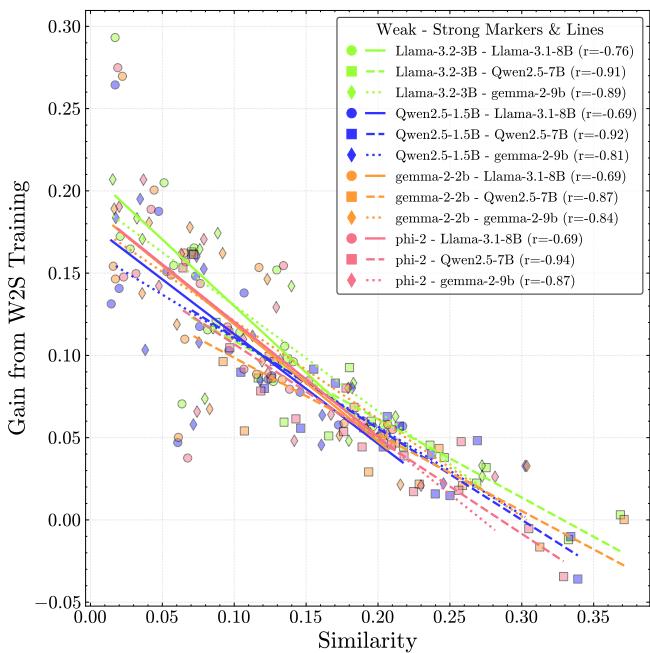
相关性惊人 (\(r = -0.85\))。 模型差异越大 (CAPA 越低) ,学生学到的就越多。
当模型太相似时,它们的错误会重叠。弱监督者强化了强学生现有的错误观念。当它们不同时,学生可以区分监督者的信号和自己的先验,有效地“三角定位”真理。
诱发与互补知识
关于弱至强泛化为何有效存在争议。这仅仅是诱发 (Elicitation) (解锁强模型内部已有的知识) 吗?还是实际的知识转移?
研究人员分解了测试数据以找出答案。
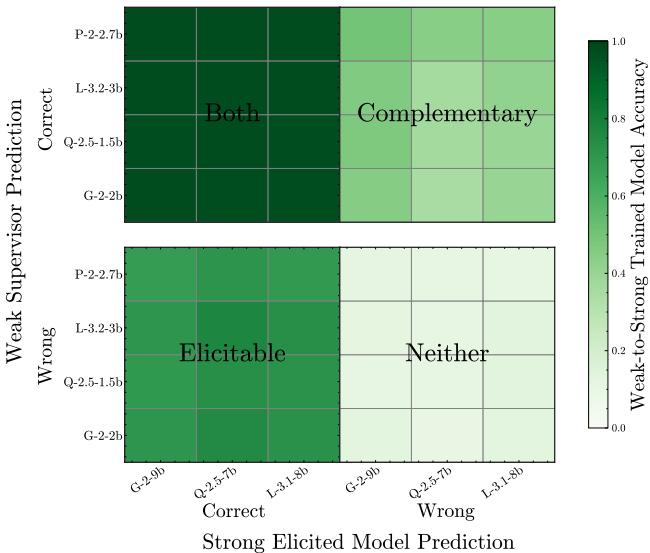
- 左下 (诱发) : 弱监督者错了,但学生对了。这是纯粹的诱发——学生忽略了错误的标签,因为它“更懂”。
- 右上 (互补) : 强学生 (即使在真实标签上训练) 会做错,但弱监督者做对了。这代表了学生缺乏但监督者拥有的知识。
数据显示这两种机制都在起作用。互补知识转移是性能提升的重要驱动力。这意味着,如果我们想利用弱监督构建超智能模型,我们不应只寻找准确的监督者,还应寻找多样化的监督者。
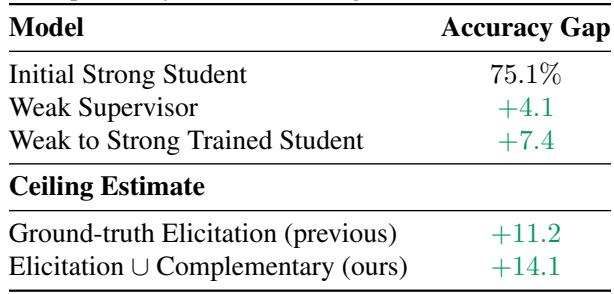
如表 3 所示,考虑到互补知识,潜在的性能“天花板”比之前估计的要高得多。
第四部分: 趋同危机
我们已经确定了两件事:
- 低相似度对裁判有益 (更少偏差) 。
- 低相似度对训练有益 (更高的学习收益) 。
多样性是有效 AI 监督的燃料。现在坏消息来了。
研究人员分析了 OpenLLM 排行榜上的 130 个模型,从小型基础模型到大型指令微调巨头。他们按能力 (准确率) 对模型进行分组,并测量了组内的平均相似度 (\(\kappa_p\)) 。
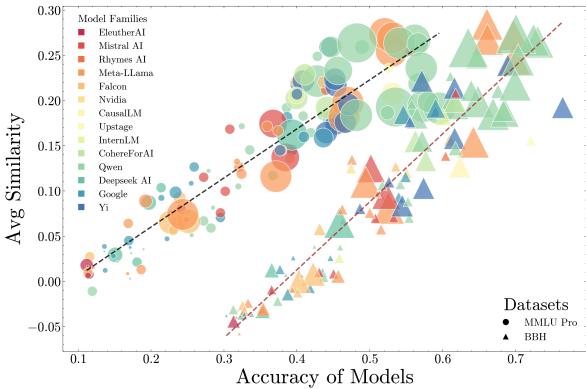
这一趋势不可否认。 随着模型变得更强,它们正变得越来越相似。
在低能力区间 (图表左侧) ,模型犯各种各样的错。它们“各有各的错法”。但随着我们移向高能力前沿 (右侧) ,模型正在趋同。它们开始共享相同的盲点和失效模式。
“算法单一培养”风险
这一趋势破坏了我们刚才讨论的安全机制。
- 对于评估: 如果顶尖模型都所见略同,用一个模型来评判另一个模型将导致越来越有偏见的分数,从而掩盖共同的错误。
- 对于训练: 如果强学生和弱监督者太相似,弱至强泛化的收益将会减少。
我们面临进入算法单一培养 (Algorithmic Monoculture) 状态的风险,即不同的模型家族 (Llama, Claude, GPT, Mistral) 趋同为单一的智能“物种”,具有相关的风险。如果一个失败,它们都会失败。
结论
论文 Great Models Think Alike 对 AI 监控的未来进行了发人深省的审视。虽然我们为 LLM 准确率的提升而欢呼,但我们不能忽视它们错误的趋同。
CAPA 的引入为社区提供了一个必要的工具。我们需要超越仅在排行榜上报告“准确率”的做法。我们应该报告“相似度”和“错误相关性”。
为了扩展 AI 监督,我们不能依赖单一的主导模型架构或训练数据配方。我们需要积极培养模型多样性。如果我们想让 AI 安全地监督 AI,我们需要确保当我们的模型照镜子时,看到的不仅仅是自己错误的倒影。
本博客文章解读了 Goel 等人 (2025) 的研究论文 “Great Models Think Alike and this Undermines AI Oversight”。