](https://deep-paper.org/en/paper/2502.09560/images/cover.png)
引言
我们正目睹多模态大语言模型 (MLLM) 的黄金时代。像 GPT-4o、Gemini 和 Claude 这样的模型可以分析复杂的图像、撰写诗歌,甚至编写完整的应用程序。自然地,下一个前沿领域就是具身智能 (Embodied AI) ——将这些“大脑”放入机器人 (或模拟机器人) 中,让它们在物理世界中导航并操作物体。
梦想是打造一个通用机器人,它能理解像“把厨房收拾干净”这样的指令,看到杂乱的场景,并计算出整理所需的数以千计的微小肌肉运动。然而,在谈论任务与实际执行任务之间存在着巨大的鸿沟。
虽然我们在文本生成和静态图像分析方面有许多基准测试,但我们要缺乏一个全面的、标准化的方法来衡量这些模型作为具身智能体的表现。GPT-4o 在房间导航方面有多出色?Claude-3.5 能控制机械臂堆叠积木吗?
为了回答这些问题,研究人员推出了 EMBODIEDBENCH 。 这是一个广泛的基准测试,旨在严格评估视觉驱动的具身智能体。它涵盖了四个不同环境中的 1,128 项任务,测试范围从高层推理 (例如决定捡起哪个物体) 到低层原子动作 (例如计算移动抓手的精确坐标) 。
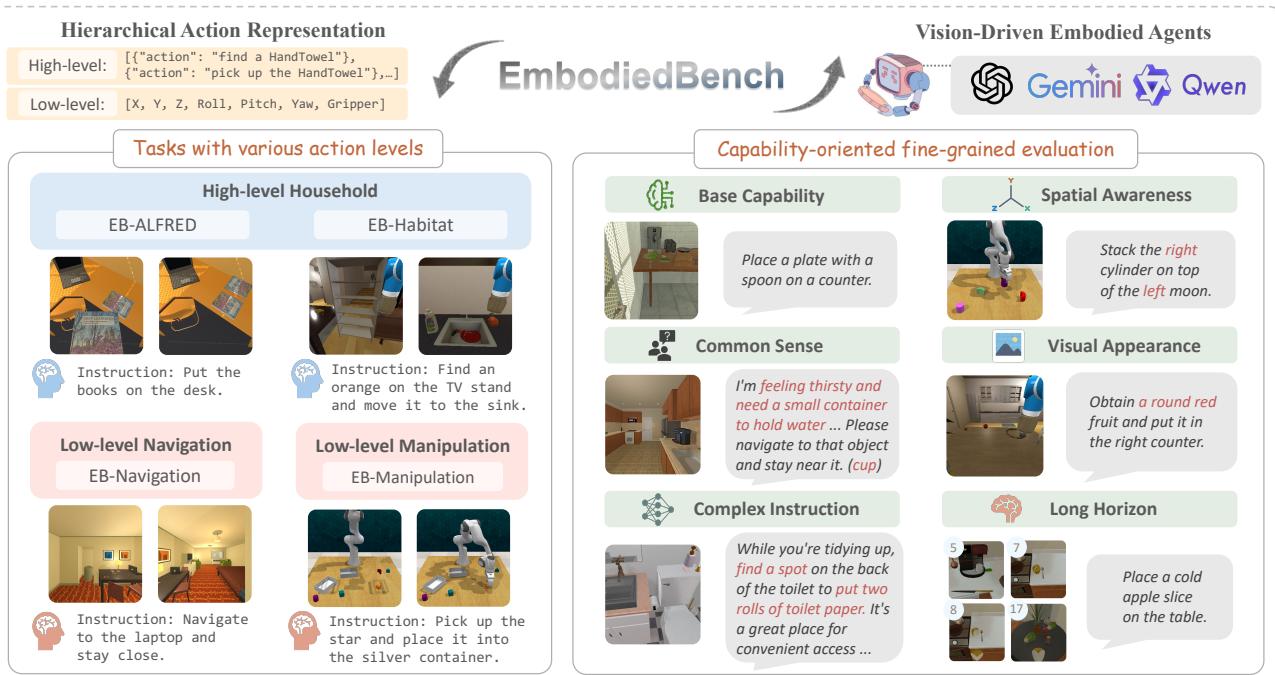
如上图 1 所示,EMBODIEDBENCH 在评估中引入了一个关键的区别: 分层动作级别 (高层与低层) 和面向能力的评估 (测试特定技能,如空间感知或常识) 。在这篇文章中,我们将拆解这篇论文,了解这个基准测试是如何工作的,更重要的是,它揭示了 AI 机器人的现状。
背景: 具身智能评估的缺口
在深入研究方法之前,我们需要了解当前的背景。传统上,具身智能由强化学习 (RL) 主导,智能体针对特定任务进行数百万步的训练。然而,基础模型 (Foundation Models) 的兴起提供了一条不同的路径: 利用从互联网预训练的知识来零样本 (zero-shot) 或少样本 (few-shot) 地解决任务。
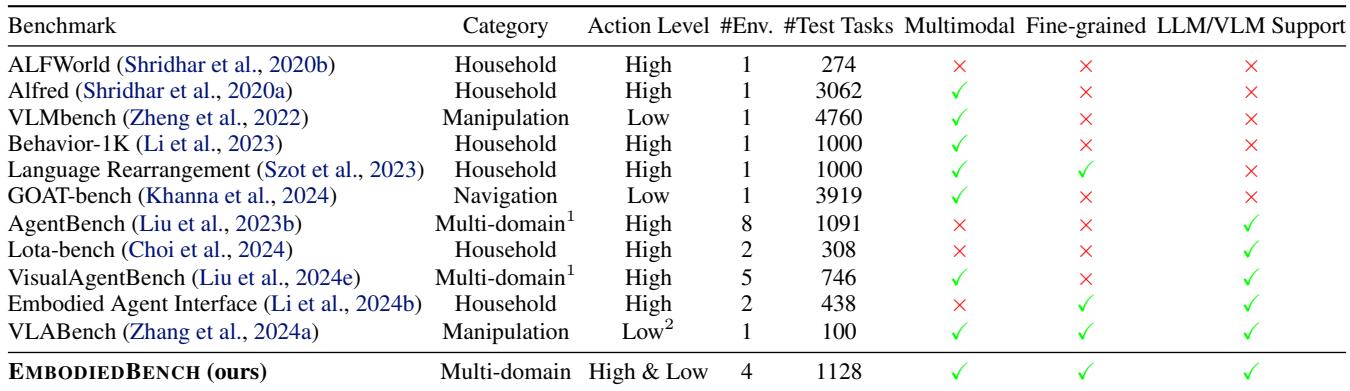
问题在于,现有的基准测试并没有跟上 MLLM 的步伐。
- 源于纯文本: 许多基准测试 (如 ALFWorld) 本质上是基于文本的游戏。它们没有严格测试等式的视觉部分。
- 范围有限: 虽然存在 VisualAgentBench 这样的基准测试,但它们主要关注高层规划 (例如,“在这个游戏中策划一场婚礼”) ,而不是机器人控制的细节。
- 缺乏低层评估: 很少有基准测试能检验 MLLM 是否可以输出精确的连续控制信号 (如
[x, y, z, roll, pitch, yaw]) 。
研究人员编制了一份相关工作的对比表,强调了 EMBODIEDBENCH 如何通过包含高层和低层动作以及细粒度的能力评估来填补这些空白。
核心方法: EmbodiedBench 内部解析
EMBODIEDBENCH 不仅仅是一个单一的模拟;它是一套包含四个不同环境的套件,旨在测试机器人智能的不同方面。
1. 四个环境
该基准测试根据所需的动作“级别”对任务进行分类。这种区分至关重要,因为告诉机器人“捡起苹果” (高层) 与计算逆运动学以将抓手移动到坐标 (34, 55, 12) (低层) 在计算上有着天壤之别。
高层任务 (“管理者”角色) :
- EB-ALFRED: 基于 ALFRED 数据集,该环境模拟家庭任务。智能体发出诸如
PickUp(Apple)(捡起苹果) 或ToggleOn(Lamp)(打开台灯) 之类的命令。它测试智能体将长指令 (例如“加热苹果”) 分解为逻辑步骤序列的能力。 - EB-Habitat: 专注于“重排”任务。机器人必须在房子里找到物体并将它们移动到特定的容器中。它涉及导航和交互,但使用抽象命令如
Navigate(Kitchen)(导航到厨房) ,而不是类似操纵杆的控制。
低层任务 (“操作员”角色) :
- EB-Navigation: 在这里,辅助轮被拆掉了。智能体必须输出原子移动:
Move Forward 0.25m(向前移动 0.25米) 、Rotate Right 90 degrees(右转 90 度) 或Tilt Camera(倾斜相机) 。目标是在没有地图的情况下找到特定物体,仅依靠视觉输入。 - EB-Manipulation: 这是最精细的环境。智能体控制一个 Franka Emika Panda 机械臂。它必须输出 7 维向量 (
[x, y, z, roll, pitch, yaw, gripper]) 来操作物体,例如堆叠积木或形状分类。
2. 面向能力的子集
这篇论文的一个主要贡献是摒弃了单一的“准确率分数”。相反,他们对任务进行分类,以诊断模型失败的原因。他们定义了六种具体的能力:
- 基础 (Base) : 标准任务 (例如,“把生菜放进冰箱”) 。
- 常识 (Common Sense) : 需要外部知识的任务 (例如,“把蔬菜放进能让食物保持新鲜的电器里” -> 需要知道冰箱能保鲜食物) 。
- 复杂指令 (Complex Instruction) : 埋藏在无关噪声或长上下文中的指令。
- 空间感知 (Spatial Awareness) : 根据位置指代物体 (例如,“水槽左边的瓶子”) 。
- 视觉外观 (Visual Appearance) : 根据外观指代物体 (例如,“那个红色的碗”) 。
- 长程规划 (Long Horizon) : 需要 15 步以上的大规模序列任务。
3. 统一智能体框架
如何将聊天机器人接入机器人?研究人员设计了一个统一的“视觉驱动智能体管道”。这个框架允许任何 MLLM (如 GPT-4 或 Llama-3-Vision) 充当机器人的大脑。
如下图所示,该过程遵循一个循环:
- 感知 (Perception) : 模型接收来自机器人摄像头的当前视图。
- 反思 (Reflection) : 它查看其历史记录。上一个动作失败了吗?为什么?
- 推理 (Reasoning) : 它思考目标和当前状态。
- 规划 (Planning) : 它用自然语言生成高层计划。
- 执行 (Execution) : 它将计划转化为环境所需的特定 JSON 格式 (例如,特定的动作 ID 或坐标) 。
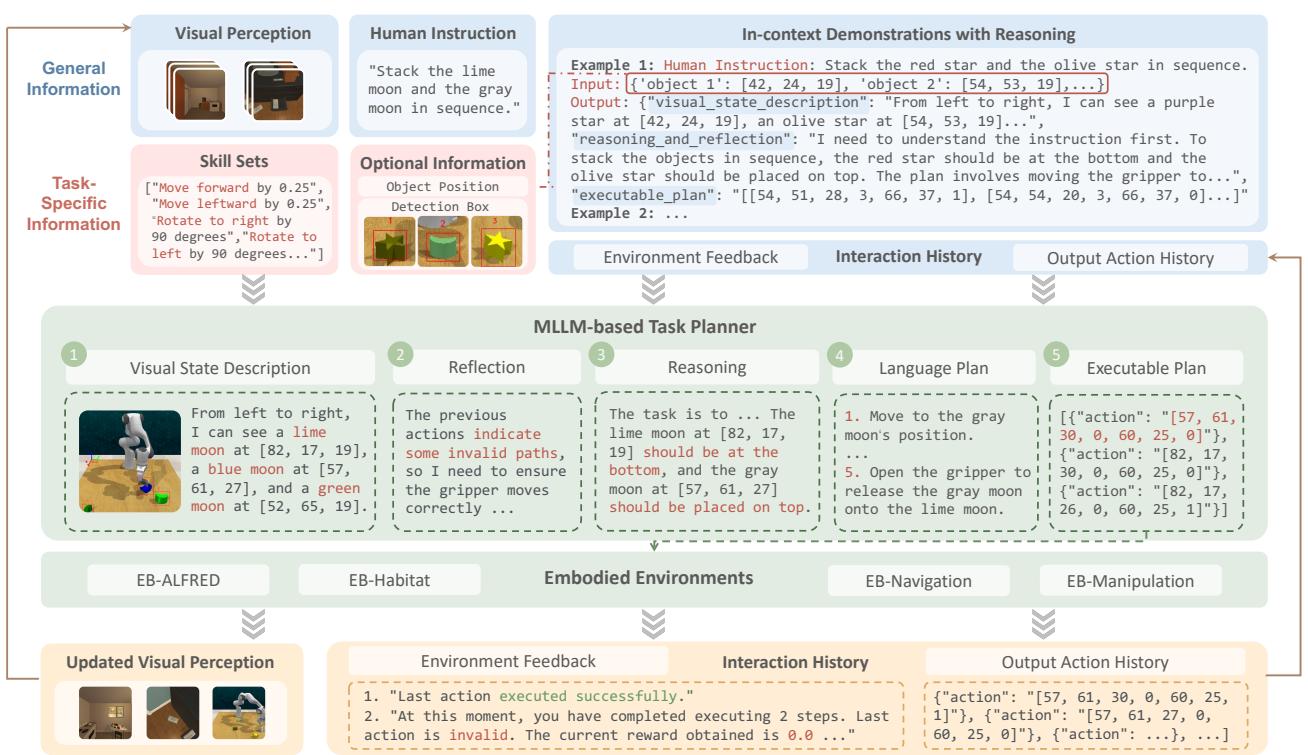
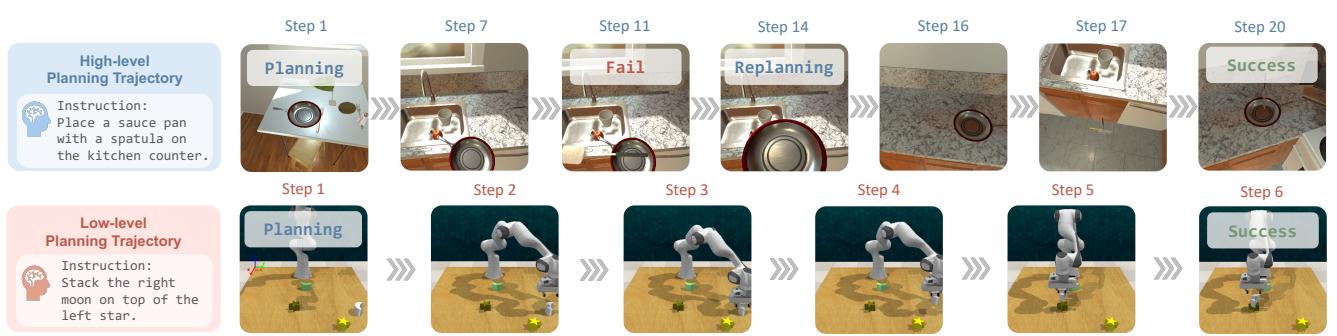
该管道支持多步规划 。 智能体可以生成一系列动作,而不是每次只向 LLM 询问一步 (这既慢又昂贵) 。例如,在下图 3 所示的操作任务中,智能体规划了一条轨迹,将月亮形状的物体堆叠在星星上。
实验与关键结果
团队评估了 24 个模型,包括专有巨头 (GPT-4o、Claude-3.5-Sonnet、Gemini-1.5-Pro) 和开源竞争者 (InternVL、Llama-3.2-Vision) 。
1. 高层与低层表现
最引人注目的发现是高层推理与低层控制之间的性能差异。
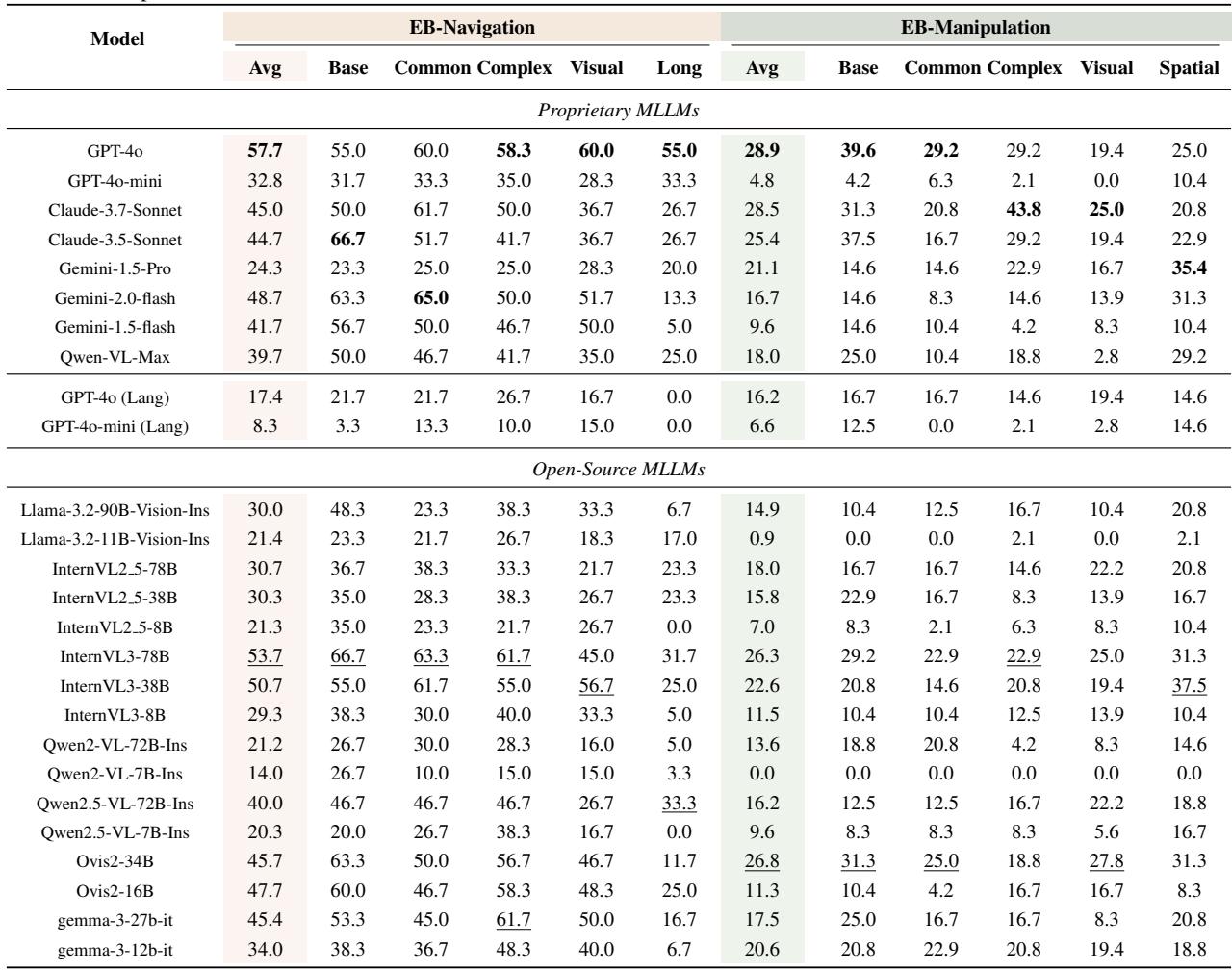
- 高层任务可解: 当前的 SOTA 模型非常擅长扮演“管理者”。在 EB-ALFRED 和 EB-Habitat 上,像 Claude-3.5-Sonnet 这样的模型达到了 60-70% 范围的成功率。它们很好地理解了家庭逻辑。
- 低层任务很难: 当被要求充当“操作员”时,表现就会崩溃。在 EB-Manipulation (控制机械臂) 中,即使是最好的模型 (GPT-4o) 也仅达到了 28.9% 的成功率。
下表 3 详细列出了这些低层任务的结果。注意“Lang”行——这些代表关闭视觉输入的运行结果。
2. 视觉的作用
研究人员进行了一项消融实验,他们关闭了摄像头 (即上表中的“Lang”行) 。
- 在高层任务中: 令人惊讶的是,移除视觉并没有造成太大影响。有时甚至还有帮助。这表明像 ALFRED 这样的高层基准测试在很大程度上依赖于语言线索和元数据,模型可能是在利用文本“钻空子”,而不是真正地在看。
- 在低层任务中: 视觉是不可或缺的。没有图像,性能下降了 40-70%。例如,在导航中,没有视觉的 GPT-4o 从 57.7% 跌至 17.4%。如果看不到障碍物,你就无法在房间里导航。
3. 以视觉为中心的消融: 什么有效?
由于低层任务是瓶颈,研究人员调查了哪些视觉因素会影响成功。
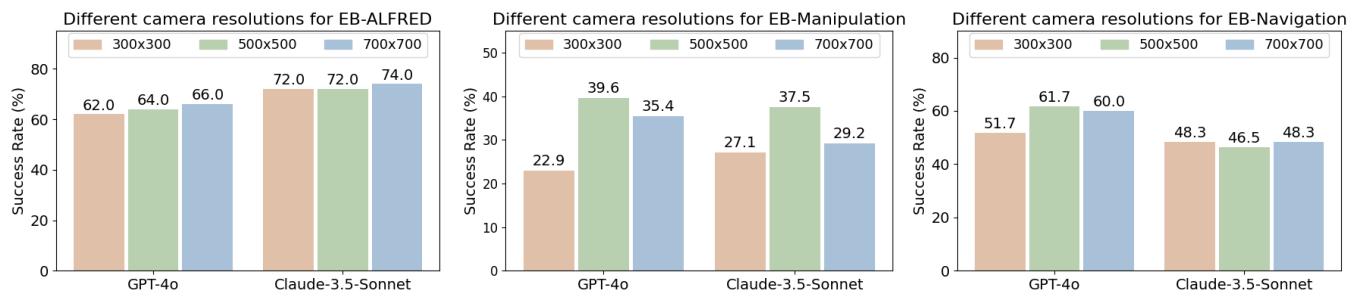
相机分辨率: 你可能认为“分辨率越高越好”,但图 7 中的结果显示了一条钟形曲线。虽然从 300x300 提升到 500x500 有显著帮助,但增加到 700x700 往往会损害性能。这可能是因为过高的分辨率引入了太多的视觉噪声,导致 MLLM 难以处理相关信息,或者是缩放伪影干扰了模型的预训练编码。
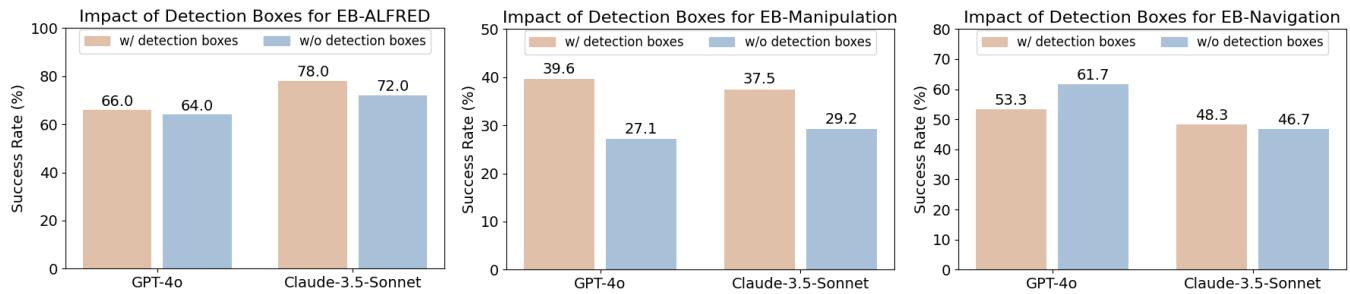
检测框 (Detection Boxes) : 在物体周围画边界框有帮助吗?如图 8 所示,这取决于任务。
- 操作任务 (Manipulation) : 有帮助。边界框显著提高了成功率 (例如,GPT-4o 从约 27% 跃升至约 40%) 。精准抓取需要确切知道物体在哪里。
- 导航任务 (Navigation) : 没有帮助。添加框实际上损害了性能。在导航中,智能体需要看到场景几何结构 (地板、墙壁、障碍物) 。用框遮挡视线可能会掩盖关键的寻路视线索。
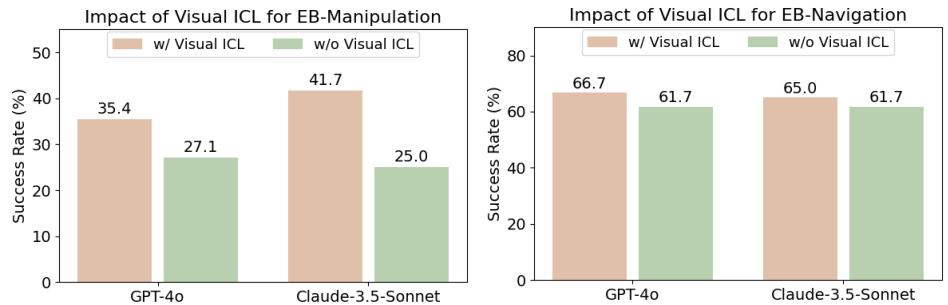
视觉上下文学习 (Visual ICL) : 这可能是最有希望的发现。标准的“上下文学习”涉及向模型展示任务的文本示例。“视觉 ICL”则涉及在文本旁边展示成功动作的图像。
研究人员向智能体提供了成功操作和导航步骤的视觉示例 (见图 15) 。

结果呢?性能大幅提升。如图 16 所示,添加视觉 ICL 将 Claude-3.5-Sonnet 的操作得分从 25.0% 提高到了 41.7%。这表明 MLLM 非常有能力仅从几个例子中学习视觉物理和空间关系,这一技术可能是解决低层控制问题的关键。
4. 错误分析
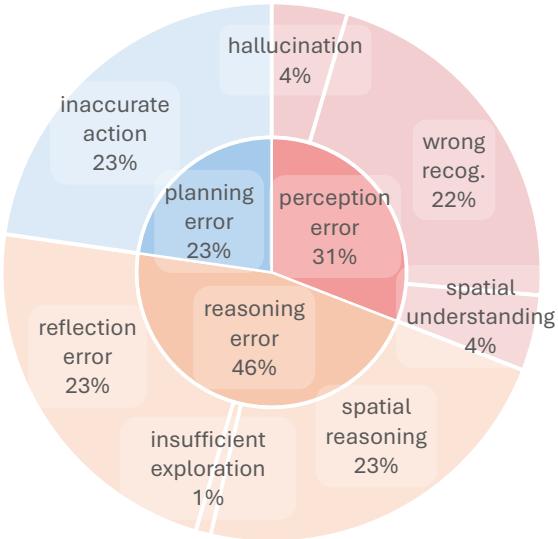
模型为什么会失败?团队将错误归类为感知 (Perception) 、推理 (Reasoning) 和规划 (Planning) 。
在 EB-Navigation (下图 17) 中,“动作不准确” (Inaccurate Action) 和“空间推理” (Spatial Reasoning) 是主要错误。模型通常知道要去哪里,但无法校准所需的精确移动量 (例如,只需要转 45 度时却转了 90 度) ,或者它们幻视出了不存在的障碍物。
在 EB-ALFRED (论文数据中的图 6) 中,“规划错误”占主导地位。模型经常会跳过必要的步骤 (比如在尝试放入食物之前没有打开微波炉) ,或者生成模拟器拒绝的无效动作。
结论与启示
EMBODIEDBENCH 为 AI 机器人领域提供了一个现实检验。虽然 MLLM 是令人印象深刻的推理引擎,但它们还不是开箱即用的称职机器人控制器。
主要收获:
- “大脑”已就绪,“双手”还未行: 模型在高层规划方面表现出色,但在操作和导航所需的空间精度方面举步维艰。
- 控制必须依赖视觉: 虽然你可以用好的文字描述来“伪造”高层规划,但低层控制需要精确的视觉处理。
- 视觉提示很强大: 视觉上下文学习是一种高效、低成本的方法,无需重新训练模型即可提高性能。
对于学生和研究人员来说,这篇论文指明了一条清晰的前进道路: 下一代具身智能体需要更好的空间落地能力。我们需要模型不仅能识别物体是什么,还能理解它在 3D 空间中的位置,以及如何移动物理躯体与之交互。EMBODIEDBENCH 提供了我们需要衡量这一进步的标准化标尺。