](https://deep-paper.org/en/paper/2502.09838/images/cover.png)
引言
在人工智能快速发展的格局中,大型语言模型 (LLM) 因其通过医师执照考试和充当诊断助手的能力而频频登上头条。然而,医学不仅仅是关于文本;它本质上是一个视觉领域。放射科医生解读 X 光片,病理学家分析组织切片,外科医生依赖 MRI 重建图像。
虽然最近的“视觉-语言”模型可以看懂 X 光片并撰写报告 (理解) ,但它们往往缺乏反向操作的能力: 即根据指令创建或增强医学图像 (生成) 。现有的试图兼顾两者的模型往往面临“样样通,样样松”的问题——学习生成图像会降低模型理解图像的能力,反之亦然。
HealthGPT 应运而生,这是一个由浙江大学、阿里巴巴和新加坡国立大学的研究人员联合开发的突破性统一医疗大型视觉-语言模型 (Med-LVLM) 。HealthGPT 旨在单一框架内同时处理医疗视觉理解 (如从扫描图中诊断疾病) 和生成 (如将低质量扫描图重建为高分辨率 MRI) 。
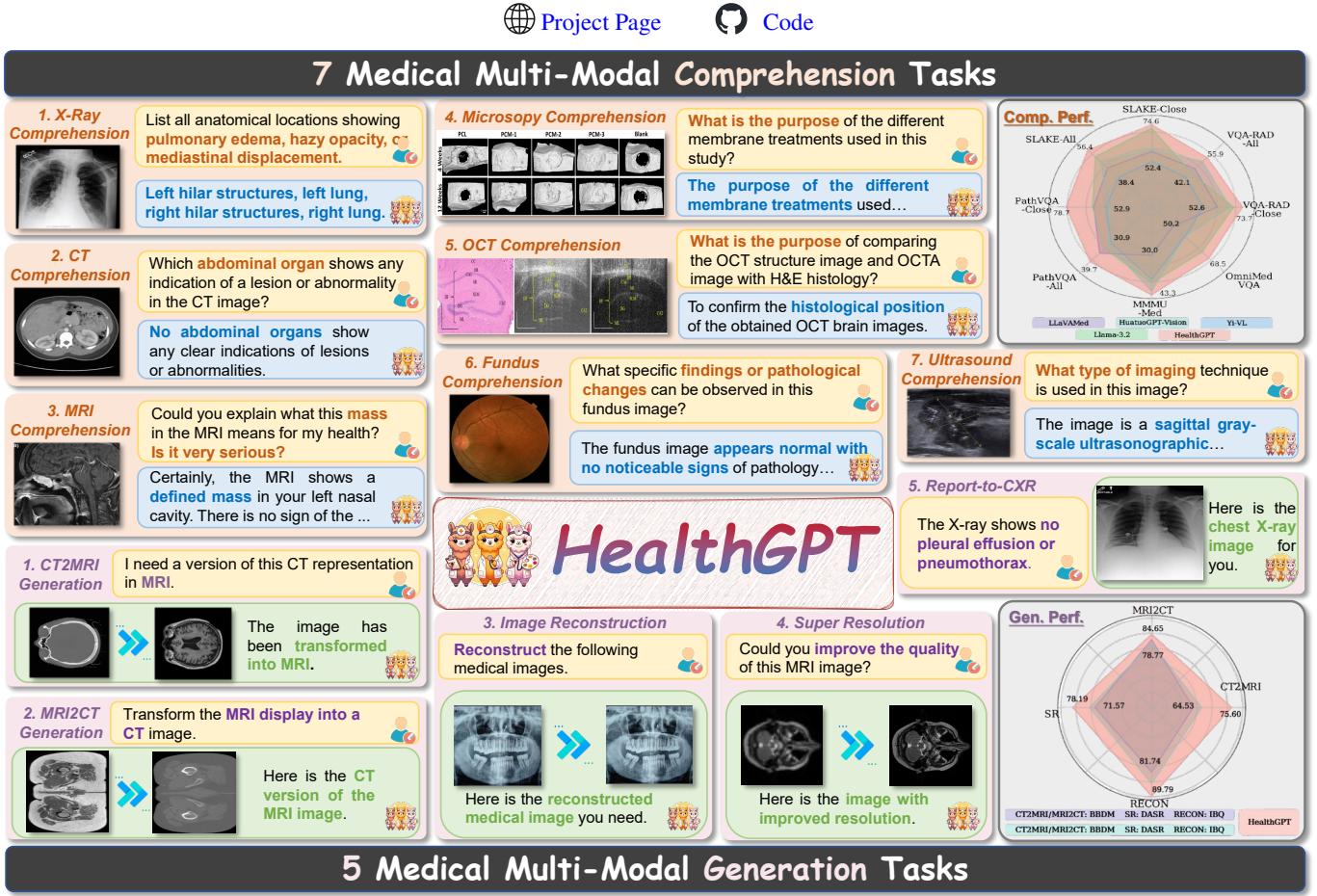
如上图 1 所示,HealthGPT 涵盖了从 X 光和 MRI 理解到复杂的生成任务 (如将 CT 扫描转换为 MRI 扫描) 等广泛任务。在这篇文章中,我们将深入探讨 HealthGPT 的架构,解释它如何使用一种名为 异构低秩适应 (H-LoRA) 的新技术来解决理解与生成之间的冲突。
核心问题: 理解与生成的冲突
要理解 HealthGPT 的重要性,首先需要了解构建“统一”模型的难度。
在通用领域 (非医疗领域) ,像 GPT-4V 或 Gemini 这样的模型正开始处理混合模态。然而,将其应用于医疗领域面临着独特的挑战。与互联网数据相比,医疗数据不仅稀缺,而且要求极高的精确度。
研究人员指出了两个主要目标之间的一个关键冲突 :
- 理解任务 (例如,“有肿瘤吗?”) 要求模型抽象掉视觉噪声,专注于高层语义。
- 生成任务 (例如,“重建这张图像”) 要求模型保留每一个像素细节。
这两个目标在本质上是相悖的。如果你训练一个模型对生成所需的像素细节过度敏感,它就会失去诊断所需的泛化能力。如果你训练它为了诊断而抽象概念,它在生成细节丰富的图像时就会表现糟糕。
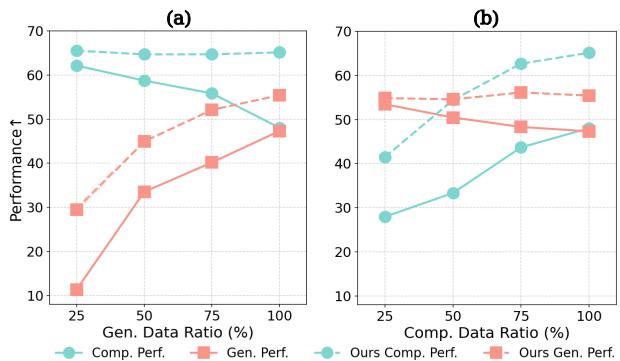
图 2 生动地展示了这种“跷跷板”效应。在图表 (a) 中,随着生成数据比例的增加 (x 轴) ,理解性能 (青色线) 下降。相反,在图表 (b) 中,过多关注理解数据会损害生成性能。
HealthGPT 团队需要一种方法来解耦这些相互冲突的需求,同时将它们保持在一个统一的模型中。
HealthGPT 架构
HealthGPT 建立在“自举 (Bootstrapping) ”理念之上。它没有从头开始训练庞大的模型,而是利用视觉编码器来适配预训练的大型语言模型 (LLM) 。
该架构将所有内容视为 Token 。 文本输入被标记化,图像被转换为离散的视觉 Token。这使得 LLM 能够以统一的、自回归的方式处理图像和文本——即逐个预测下一个 Token。
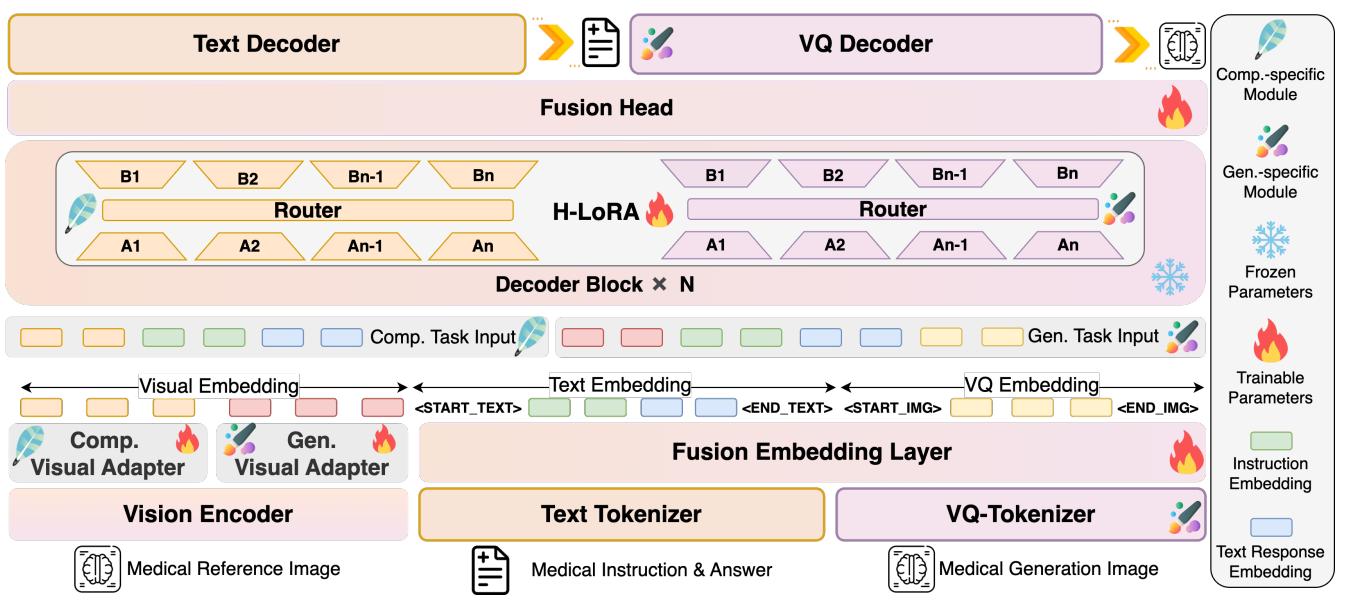
如图 3 所示,该架构有两个主要创新,使其区别于标准的多模态模型:
- 分层视觉感知 (Hierarchical Visual Perception, HVP)
- 异构低秩适应 (Heterogeneous Low-Rank Adaptation, H-LoRA)
让我们逐步拆解这些概念。
1. 分层视觉感知 (HVP)
标准的视觉模型通常将视觉 Transformer (ViT) 的最后一层输入到 LLM。HealthGPT 研究人员意识到,我们前面讨论的“冲突”始于视觉编码层面。
- ViT 的深层包含抽象的语义信息 (非常适合回答问题) 。
- ViT 的浅层包含具体的、细粒度的细节 (非常适合重建图像) 。
HealthGPT 没有强制模型只使用一种输出,而是根据任务动态选择视觉特征。
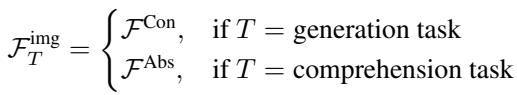
如上式定义,如果任务是生成 (\(T = \text{generation task}\)) ,模型使用来自浅层的具体粒度特征 (\(\mathcal{F}^{\mathrm{Con}}\)) 。如果任务是理解,它则使用抽象粒度特征 (\(\mathcal{F}^{\mathrm{Abs}}\)) 。这确保了 LLM 接收到的是针对手头工作的正确类型的视觉信息。
2. 异构知识适应 (H-LoRA)
这是论文的核心引擎。微调庞大的 LLM (如 Llama 或 Phi) 计算成本高昂。解决这个问题的常用技术是 LoRA (低秩适应) 。 LoRA 冻结主模型权重,并训练小型的低秩矩阵以注入新知识。
然而,单个 LoRA 模块难以同时容纳医疗绘图和医疗观察所需的相互冲突的知识。
研究人员引入了 H-LoRA , 它将理解和生成知识视为“异构的” (种类不同) 。它将这些知识存储在独立的“插件” (LoRA 参数集) 中,并动态地将输入路由到正确的插件。
H-LoRA 的数学原理
在标准 LoRA 中,对模型权重的修改计算为 \(\Delta W = AB\),其中 \(A\) 和 \(B\) 是小矩阵。
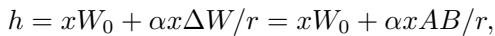
在 H-LoRA 中,模型不仅仅拥有一组 \(A\) 和 \(B\),而是拥有特定于任务的参数集。
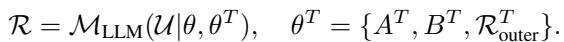
这里,\(\theta^T\) 代表特定于任务 \(T\) 的参数。但 HealthGPT 不仅仅是简单的任务切换。在特定任务内,它高效地使用了 混合专家 (Mixture of Experts, MoE) 方法。
通常,MoE 速度较慢,因为它需要计算许多不同的矩阵乘法。H-LoRA 通过将专家矩阵合并为一个大矩阵来优化这一点。
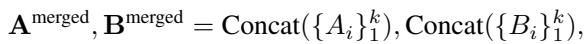
通过将专家 (\(A_i\) 和 \(B_i\)) 拼接到 \(\mathbf{A}^{\mathrm{merged}}\) 和 \(\mathbf{B}^{\mathrm{merged}}\) 中,模型可以在单次传递中完成计算。“路由器”决定哪些专家对输出做出贡献。
路由权重 \(\mathcal{W}\) 被计算出来,然后扩展以匹配合并矩阵的维度:
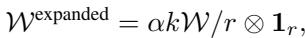
最后,H-LoRA 模块的输出通过逐元素乘法 (\(\odot\)) 和标准矩阵乘法计算得出,这比标准的 MoE 实现计算速度快得多:
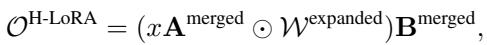
此输出被加到冻结的预训练权重 (\(W_0\)) 上,以获得最终结果:
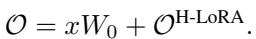
为什么 H-LoRA 更好?
研究人员将 H-LoRA 与标准 LoRA 和 MoE-LoRA (混合专家 LoRA) 进行了比较。
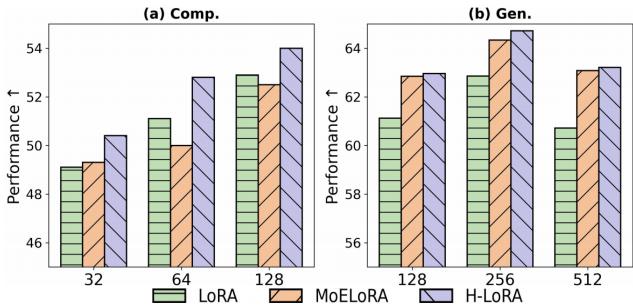
图 5 显示了结果。在不同模型大小 (秩) 下,H-LoRA (紫色条) 在理解 (Comp) 和生成 (Gen) 任务中均始终保持更高的性能。至关重要的是,它在实现这一点的同时,没有像通常的混合专家模型那样带来巨大的训练时间代价。
三阶段训练策略
为了有效地训练这个复杂的架构,团队采用了三阶段流水线:
- 多模态对齐: 他们分别为理解和生成训练了单独的适配器,以将视觉编码器与 LLM 对齐。此时 LLM 本身是冻结的。
- 异构 H-LoRA 插件适应: 他们冻结 H-LoRA 模块,仅使用混合数据训练嵌入层和输出头。这建立了一个“统一基础”,使文本和视觉 Token 可以共存。
- 视觉指令微调: 最后,他们在特定的下游任务 (如“将此 CT 转换为 MRI”) 上训练 H-LoRA 插件。
VL-Health 数据集
模型的好坏取决于数据。由于不存在结合医疗问答与医疗图像生成的数据集,研究人员构建了 VL-Health 。

如图 4 所示,VL-Health 非常全面。它聚合了像 VQA-RAD 和 SLAKE 这样的经典数据集用于理解,同时纳入了用于生成的超分辨率 (IXI) 和模态转换 (SynthRAD2023) 数据集。这种均衡的数据集使 HealthGPT 能够学习其双重特性。
实验结果
那么,效果如何呢?研究人员在多个基准上测试了 HealthGPT。
理解性能
首先,他们检查了模型是否仍然能够“看懂”并理解医学图像。
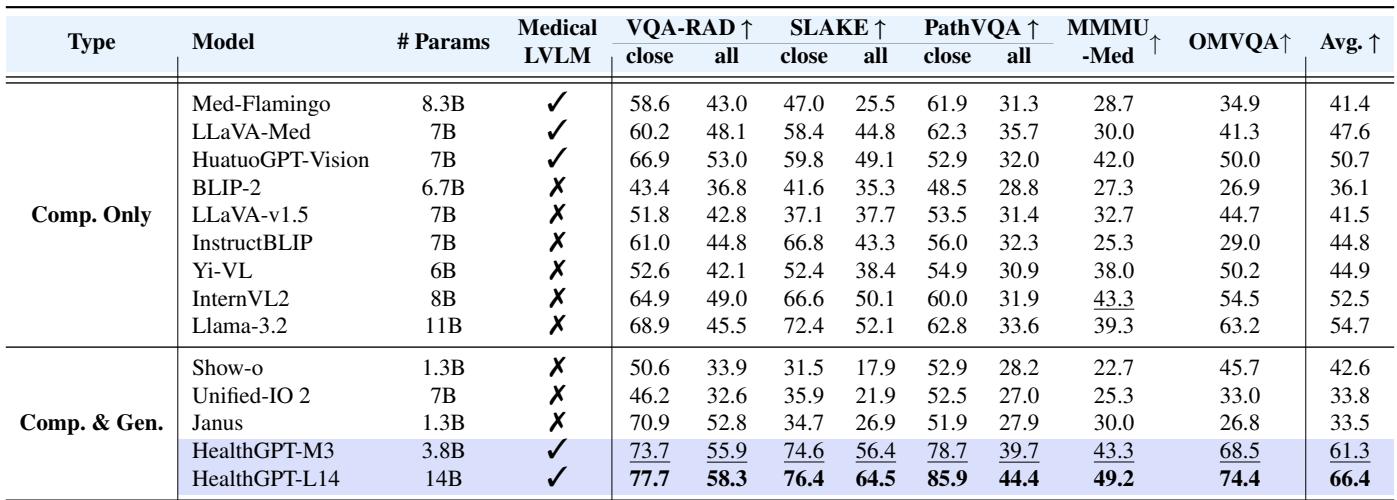
表 1 突显了 HealthGPT 的优势。
- HealthGPT-M3 (38亿参数) 优于像 Unified-IO 2 (70亿参数) 这样的庞大通用模型以及像 LLaVA-Med 这样的特定医疗模型。
- HealthGPT-L14 (140亿参数) 在几乎所有指标上 (包括 VQA-RAD 和 SLAKE) 都树立了新的最先进水平 (SOTA) 。
这证明了增加生成能力并没有损害模型理解图像的能力——事实上,由于 H-LoRA 的解耦作用,它表现得非常出色。
生成性能: 模态转换
HealthGPT 最令人印象深刻的能力之一是 模态转换 。 这指的是获取 CT 扫描 (使用 X 射线) 并生成同一解剖结构的精确 MRI 扫描 (使用磁场) 的能力。这非常困难,因为 CT 和 MRI 突出显示的组织不同。
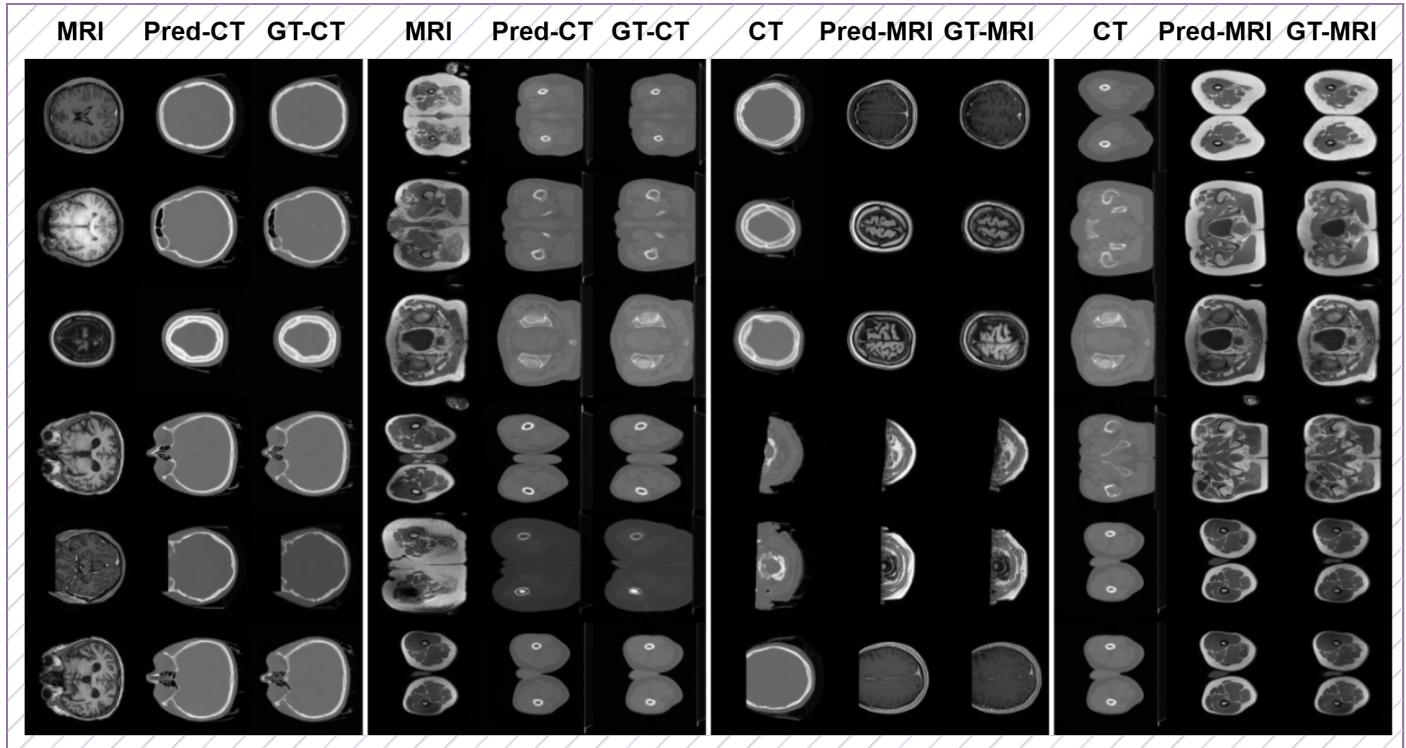
图 11 展示了结果。HealthGPT 生成的“Pred-MRI” (预测 MRI) 列与“GT-MRI” (真实值) 列惊人地相似。该模型准确地预测了大脑和腹部的软组织对比度,将 CT 的亨氏单位转换为 MRI 的信号强度。
生成性能: 超分辨率
另一项关键任务是将低质量、模糊的 MRI 重建成高分辨率图像。
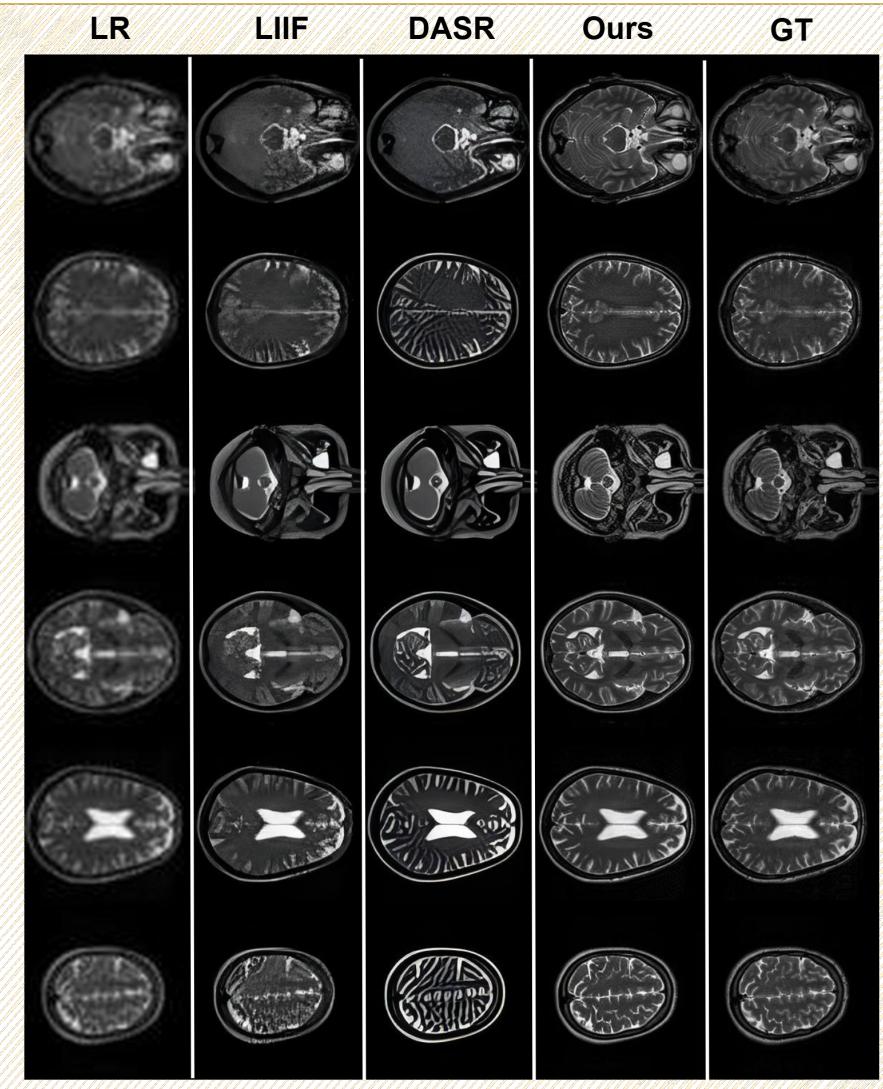
在图 12 中,对比“LR” (低分辨率) 列和“Ours” (HealthGPT) 列。区别是显而易见的。HealthGPT 恢复了大脑皮层的精细折叠模式,这些在低分辨率输入中完全丢失了。
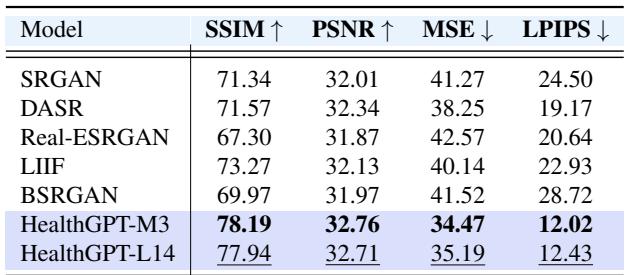
该任务的定量结果 (如下表 3 所示) 证实,HealthGPT 实现了比 SRGAN 或 SwinIR 等专用超分辨率模型更高的结构相似性 (SSIM) 和峰值信噪比 (PSNR)。
结论与启示
HealthGPT 代表了医疗 AI 向前迈出的重要一步。通过承认视觉抽象 (理解) 和视觉细节 (生成) 之间的内在冲突,作者设计了一种兼顾两者的架构。
主要要点包括:
- 统一能力: 构建一个既能充当放射科医生 (解读图像) 又能充当医学画家 (重建图像) 的单一模型是可能的。
- 架构创新: H-LoRA 和分层视觉感知是管理大型语言模型中异构知识的有效技术。
- 可扩展性: 这些方法在较小的模型 (38亿参数) 上有效,并且可以很好地扩展到较大的模型 (140亿参数) 。
对于学生和研究人员来说,HealthGPT 是 参数高效微调 的绝佳范例。它表明我们并不总是需要从头开始重新训练庞大的模型;通过像 H-LoRA 这样巧妙的工程设计,我们可以调整现有的强大 LLM,使其在医疗保健等关键领域执行高度专业化、复杂的任务。
随着这些统一模型的成熟,我们要么很快就能看到不仅能撰写报告,还能积极帮助提高医学影像数据质量的 AI 助手,从而实现更快速、更准确的诊断。