](https://deep-paper.org/en/paper/2502.14791/images/cover.png)
人类学习单词的速度惊人地快。只需给一个孩子几个包含陌生词 (如 “ski”) 的句子——“苏西去年冬天学会了滑雪 (ski) ”、“人们在积雪覆盖的高山上滑雪 (ski) ”、“我看到苏西飞快地从雪山上滑雪 (ski) 而下”——孩子通常就能推断出 “ski” 是一个与在雪上滑动有关的动词。这种单例式、灵活的泛化能力是人类语言习得的典型特征。
相比之下,大语言模型 (LLM) 通过海量语料库获取知识。它们在许多任务上表现出色,但在处理罕见或未见过的词汇时却出奇地脆弱: 缺乏足够示例时,它们往往无法像人类那样泛化。这种差距是否不可避免?或者,我们能否通过少量的上下文示例,让模型快速且系统地学习新词?
本文介绍了纽约大学与麻省理工学院研究人员的一项最新研究,该论文对这个问题给出了肯定的答案。这个方法被称为 Minnow (Meta-training for IN-context learNing Of Words,即“用于情境词学习的元训练”) 。Minnow 并不是为每个新词创建嵌入或在庞大语料上重新训练,而是通过元训练让模型更擅长于从用法中学习词汇的过程——这是一种针对情境学习的元学习方法。效果令人瞩目: 在类人规模的、面向儿童的语料上通过 Minnow 训练的模型获得了强大的少样本词汇学习能力,而使用 Minnow 微调还能进一步提升大型预训练 LLM 的情境学习表现。
下面我将解析 Minnow 的核心问题、逐步阐述其方法,并结合论文中的精选图表展示实验与关键发现。
为什么这很重要 (简版)
- 它证明了少样本词汇学习可以作为一种通用能力被习得,而非依赖海量记忆示例。
- Minnow 具有很高的数据效率: 在与儿童一年语言输入量相当的数据集上训练的模型能发展出稳健的少样本词汇学习能力。
- Minnow 可用于从零训练小模型,也可用于以高效的参数方式微调大型 LLM。
Minnow 要解决的问题: 罕见词障碍
自然语言服从齐夫分布 (Zipfian distribution) : 少数词频高,大量词频低。LLM 在训练中会多次甚至上百万次看到高频词,却仅有几个甚至没有罕见词的示例,而新词汇则持续被引入。传统方法通常通过上下文聚合或形态线索来为新词构建嵌入,这些方法虽然能工作,但每个新词都需要单独工程化处理。Minnow 从另一个角度提出问题: 能否让模型具备一种普遍的能力——从少量上下文中推断词义,并将这种技能泛化到任何新词?
一段话概括 Minnow 的理念
Minnow 是一种面向词汇习得的元情境学习训练。在元训练阶段,每个训练片段会随机选择一个低频词,将该词的所有出现替换为一个共享的占位符标记 (如 [new-token]) ,即对该词进行掩码。该片段包含若干含占位符的例句;模型的任务是在这些例句拼接成的序列上执行标准的下一标记预测,从上下文推断占位符的合理续写。重复这种过程,模型通过多个词汇的学习实践,学会如何学习新词的含义,而非记忆具体的词形。
Minnow 与普通语言建模的对比示意
![Minnow 训练过程 (上) 与标准语言建模 (下) 的对比。Minnow 使用占位符 <code>[new-token]</code> 来教模型学会从上下文中推断意义。](/en/paper/2502.14791/images/001.jpg#center)
图 1: Minnow 框定元学习片段 (上) : 一个词被共享占位符掩码,模型必须依据少量学习示例预测新用法。普通语言建模片段 (下) 保持交替进行以维持流畅度。核心在于跨多个片段进行元训练,使模型掌握一种普遍的情境词学习策略。
分步详解: Minnow 如何构建一个训练片段
- 从语料中选出一个低频词 \( w \) (例如 “ski” 或 “aardvark”) 。
- 收集该词的 \( K \) 个使用示例,作为“学习样本”。
- 将所有示例中的 \( w \) 替换为同一个占位符,如
[new-token]。同一占位符用于所有训练片段,防止模型对词形创建专属嵌入。 - 将这 \( K \) 个掩码句拼接成一条序列,以特殊分隔符 (如
<sep>) 分隔句子。 - 在该序列上执行下一标记预测任务。由于占位符在不同上下文中反复出现,模型必须从这些上下文中推断其语义功能才能生成连贯续写。
为什么要使用同一个占位符?
使用统一的占位符可以防止模型在权重中记忆具体词汇。模型必须基于当前片段中的上下文即时形成解释。这直接练习了情境学习: 形成临时、依赖上下文的意义,而非新增永久嵌入。
留存词分类: 一种判别测试
该任务测量模型能否利用学习样本,将一个被掩码的查询句正确归属到相应词汇的上下文。具体流程如下:
- 对于 \( C \) 个候选词,每个收集 \( K-1 \) 个学习示例;
- 为其中一个候选词采样一个被掩码的查询句;
- 将每个候选词的学习示例与查询句拼接,计算模型在该上下文下的条件似然;
- 模型选出使似然最高的候选词。
该测试评估模型是否能根据少量上下文匹配正确词义。
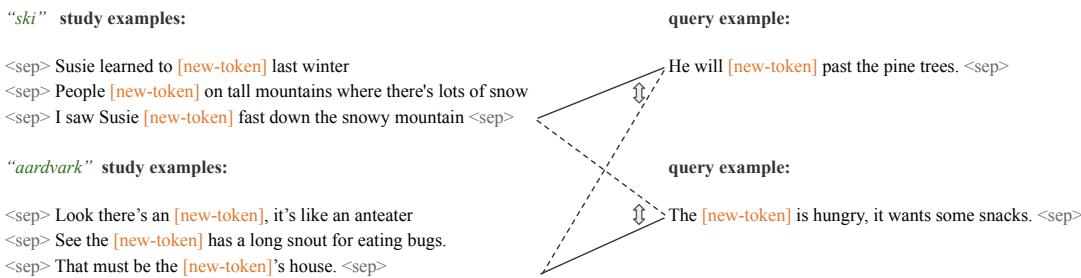
图 2: 左侧为每个候选词的学习上下文,右侧为查询句。模型评估哪个上下文使查询句更可能出现。
训练数据: 面向儿童、儿童规模的语料
为测试数据效率,作者使用两套近似儿童语言输入的语料:
- CHILDES : 儿童与照护者的互动转录文本 (筛选为照护者语言) ,规模虽小但口语化且儿童导向。
- BabyLM-10M : 含约 1000 万词的 BabyLM 赛道语料,混合了儿童导向及其他儿童合适的数据源。
每个语料分为元学习部分 (掩码词训练片段) 与语言建模部分 (其余句子) 。从零训练时两部分交替,以保持流畅;微调预训练 LLM 时仅使用 Minnow 片段。
从零训练小模型: Minnow 能像儿童一样学习吗?
研究者在 CHILDES 和 BabyLM-10M 数据集上使用 Minnow 从零训练了约 1 亿参数的自回归 Transformer 模型。模型采用词级分词,将低频词形从词表中移除以防内部权重学习。
关键结果 (从零训练)
- 使用 \( K=5 \) 个示例的模型,在四选一分类任务中达到了约 72% (CHILDES) 和 77% (BabyLM-10M) 的准确率;
- 这与预训练于海量数据的 Llama-3 8B 模型 (71–78%) 仅相差数个百分点。
令人惊讶的是,尽管数据量很小,Minnow 小模型的表现几乎追平大型模型,表明只要训练目标恰当,少量数据即可学得少样本词汇能力。
微调大型 LLM: Minnow 能让强者更强
另一组实验研究 Minnow 微调是否能提升已预训练的强大模型。作者使用 BabyLM-10M 的 Minnow 片段微调 Llama-3 8B (并部分比较 Llama-2 7B) 。微调过程高度参数高效: 冻结所有权重,仅更新占位符与分隔符两个特殊标记的输入和输出嵌入,这两者初始为现有嵌入均值。
留存词分类: Llama-3 8B + Minnow
- 在 BabyLM-10M 上,准确率从 78% → 87%,提升约 9 个百分点;
- 在 CHILDES 上,从 71% → 79%。
结果显示 Minnow 微调显著增强了模型在少量示例下推断正确含义的能力。
超越判别: 模型究竟学到了什么?
留存词分类可能仅反映主题匹配而非真正词义理解。为深入探究,作者设计了句法与生成式评估来剥离这种干扰。
句法类别分类
任务要求模型从若干示例推断新词的语法类别 (名词、动词、形容词、副词) ,并泛化到语义不同的新句子,排除主题连贯性捷径。
关键结果 (句法类别)
- Llama-3 8B 基线: 约 66%;
- Llama-3 8B + Minnow: 约 83%;
- 从零训练的 Minnow 模型: 约 77%。
说明 Minnow 帮助模型从极少上下文中推断词的语法分布特征,并推广至新用法。
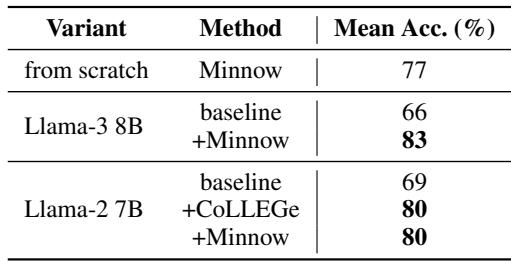
图 3: 跨类别判别 (如名词 vs. 动词) 的准确率。Minnow 微调增强了模型从少量用法推断词类并泛化的能力。
生成评估: 模型能使用新词吗?
前述测试说明模型能识别语境归属,但最直观的验证是: 它能否自己使用学到的新词?还能否从少量用法生成合理的词典式定义?
新用法生成
- 流程 : 给模型 \( K-1 \) 个被掩码的示例,提示生成一个新句 (以分隔符结束) 。
- 评估 : 由 GPT-4o 和人工评估分别判断 Minnow 微调模型与基线模型的生成哪一个更好。
总结结果
- 在 BabyLM-10M 测试集和 Chimera 数据集上,Minnow 模型生成的句子在自动与人工评判中均更受偏爱。
- 它常能生成语法正确、语义合理的新用法,与学习示例中推断出的意义一致。
例如,在涉及土耳其古代文明的学习示例中,Minnow 生成了:
- “the [new-token] were a people who lived in the area of turkey.” ([new-token] 是曾居住在土耳其地区的民族。)
显示了模型的语义泛化与句法正确性。

图 4: Minnow 模型生成了语义合理的例句 (展示为贪心解码) 。生成内容可能复制部分示例细节,或在采样时产出似是而非的信息;这与生成式语言模型的普遍特点一致。
定义生成
- 任务 : 根据一个或若干用法示例,生成一个简短的定义;
- 数据 : CoLLEGe-DefGen (GPT-4 生成样本) 与 Oxford 测试集 (词典定义) ;
- 指标 : BERTScore F1、ROUGE-L,以及 GPT-4 的对比评判。
结果 (单样本定义)
- Minnow 微调在两数据集上提升了 BERTScore 和 ROUGE-L;
- 在 GPT-4 与人工评估中,多数情况下 Minnow 版本的定义更受偏好。
例句: “尽管他很贪婪,但这位商人感到受一种 [new-token] 的约束,必须保持道德准则。” Minnow 生成定义:
- “a promise or agreement to do something.” (一个做某事的承诺或协议。)
该结果精准捕捉了“绝对命令”的核心语义,显示出强泛化能力。
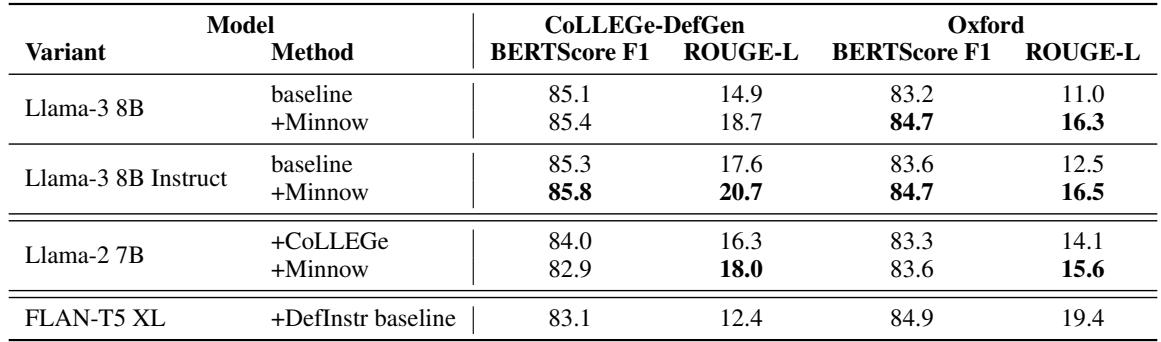
图 5: Minnow 微调提升了单样本定义生成性能。提升虽不大但一致,模型更擅长从稀疏上下文抽取定义性信息。
快速成绩概览
- Minnow 小模型 (从零训练) : 少样本分类与句法推断表现强劲,结果接近大型预训练模型。
- Llama-3 8B + Minnow 微调 : 留存分类提升约 8–10 个百分点,句法类别任务提升约 17 个百分点,生成质量更佳。
- 与其他方法比较 (如 CoLLEGe) : Minnow 在灵活的上下文驱动泛化上具有优势。
局限与注意事项
- 仅限文本输入 : 与人类的多模态词汇学习不同,Minnow 基于纯文本,缺乏感知基础。
- 单一占位符 : 设计虽强化情境学习,但不反映人类词形差异,也不模拟词汇的持续累积。
- 微调评估可能泄漏 : 部分评估词可能已出现于预训练数据,使效果并非纯新词学习。
- 生成评估指标有限 : 如 ROUGE、BERTScore 以及 LLM 评判存在偏差,需要更多人工评估。
- 形态处理简化 : 不同词形被视为独立单词,未来可结合形态学结构改进。
为什么 Minnow 在概念上令人着迷
- Minnow 训练的是“学习能力”,而非“记忆能力”。通过最大化掩码片段的下一标记似然,模型习得基于上下文的推理策略。
- 单一占位符迫使模型依赖上下文推断,加深语义精度。
- 微调仅涉及特殊标记嵌入即可有效迁移,对实际应用非常高效。
对从业者与研究者的启示
- 想让模型擅长从少量文本例子中掌握新词?考虑引入明确练习该能力的元训练或元微调目标。
- 数据效率可实现: 人类规模数据结合匹配的训练目标即可产生强归纳能力。
- 在实际系统中,Minnow 式微调可作为低成本手段提升词汇适应性,而无需重新大规模训练。
结论
Minnow 将快速词汇学习重新定义为一种元学习问题: 反复练习从少量上下文中学习多种词汇,模型便会形成可迁移的通用策略。该方法既能让中型模型在儿童规模数据上取得成功,也能在大型预训练 LLM 上以极低成本实现增益。Minnow 在判别和生成评估中的改进表明,情境少样本词汇学习是一种可习得能力——只要训练目标教会模型如何学习 , 它就能在不依赖大语料的情况下实现。
未来方向包括:
- 扩展 Minnow 至多模态场景,让词汇与真实视觉或动作语义建立关联;
- 探索持续/元训练机制,使模型在累积长期词汇知识的同时保持即时学习的能力;
- 将 Minnow 型元训练与形态学先验结合,使模型在形式-意义对应中发挥优势。
研究者已公开代码与数据处理脚本,可复现多项实验结果 (见论文) 。Minnow 展示了模型的语言学习能力是可被明确教授的——这是迈向更灵活、更类人语言理解的重要一步。
主要参考文献 (精选)
- Min et al., MetaICL (2022): 跨任务的情境学习元训练。
- Teehan et al., CoLLEGe (2024): 针对新词嵌入生成的元学习。
- Lake & Baroni (2023): 面向系统化泛化的元学习。
- Minnow 论文: Wentao Wang, Guangyuan Jiang, Tal Linzen, Brenden M. Lake — “Rapid Word Learning Through Meta In-Context Learning.”
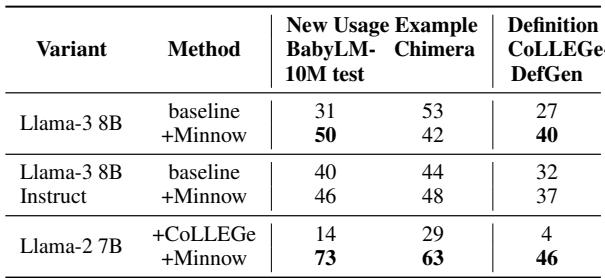
图 6: 新用法与定义生成的对比结果。Minnow 微调模型在 GPT-4 评判中胜出次数更多,人工评估结果亦一致。

图 7: 给定一个用法示例,Minnow 生成的定义捕捉核心意义,虽不完全符合词典表述 (“做某事的承诺或协议” vs. 哲学经典表达) ,但展现了强上下文推断力。
最后的思考
Minnow 显示,语言模型可以被教会成为更好的学习者。这种转变——从训练模型记忆事实到训练模型练习推理策略——对于构建能够快速适应语言变化与新概念的系统至关重要,而无需重新在庞大语料上训练。未来,将元学习目标 (如 Minnow) 与多模态基础、持续学习及以人为中心的评估结合,是迈向数据高效且灵活语言学习的关键途径。