](https://deep-paper.org/en/paper/2502.17543/images/cover.png)
引言
我们通常认为大型语言模型 (LLM) 是巨大的静态知识宝库——会说话的百科全书。当你提出一个问题,它们会根据训练过的海量数据集预测下一个可能的 token。但当我们从构建聊天机器人转向构建智能体 (agents) ——即能够独立实现目标的系统时,这种被动特性就成了瓶颈。
一个真正的智能体不仅仅是回答问题;它会进行调查。它与世界互动。如果你要求智能体“诊断服务器宕机的原因”,它不应该仅仅根据训练数据进行猜测;它需要登录系统,检查指标,读取错误日志,并战略性地收集信息,直到找到根本原因。这需要探索 。
问题在于,现有的 LLM 在这种特定类型的战略性信息收集方面通常表现不佳。它们倾向于产生幻觉性的答案,而不是提出澄清性问题,或者它们的探索效率低下,在无关的操作上浪费步骤。此外,在现实世界中训练它们这样做既危险又昂贵——你肯定不希望一个 AI 仅仅为了“看看会发生什么”就随机删除服务器上的文件。
在这篇文章中,我们将深入探讨 PAPRIKA , 这是一篇提出训练通用好奇智能体新方法的研究论文。研究人员介绍了一种教 LLM 执行“上下文内强化学习 (In-context Reinforcement Learning) ”的方法。通过在各种不同的合成决策任务上微调模型,他们创建了不仅能解决训练过的任务,还能将其探索策略泛化到完全未见过的游戏和场景中的智能体。
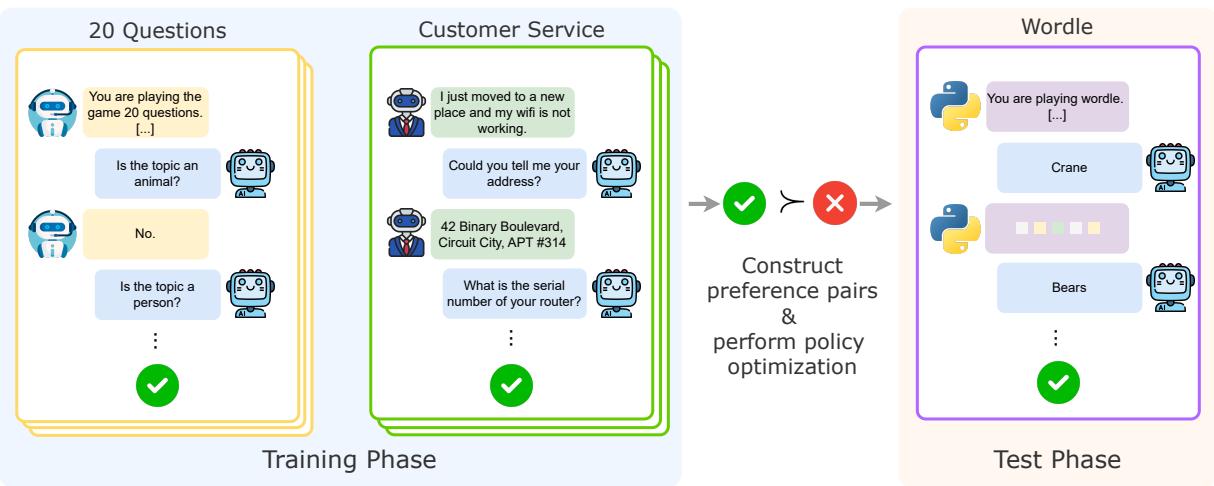
如图 1 所示,PAPRIKA 将重点从训练模型解决特定问题转移到了训练模型掌握解决问题的通用过程上。
上下文内探索的挑战
要理解为什么这很难,我们需要看看 LLM 通常是如何训练的。预训练和标准的监督微调 (SFT) 教模型模仿人类的反应。然而,决策是一个序列过程。智能体必须采取行动,观察环境反馈,更新其内部状态,并规划下一步行动。这是一个部分可观测马尔可夫决策过程 (POMDP) 。
作者指出了两个主要障碍:
- 数据稀缺: 大多数自然产生的文本数据 (如维基百科或 Reddit) 缺乏交互式试错的结构。它包含的是决策的结果,而不是迭代的过程本身。
- 安全与成本: 通过将未经训练的模型部署到现实世界中来收集交互数据会导致错误,这既昂贵又有风险。
PAPRIKA (这个名字虽然是一个朗朗上口的缩写,但主要灵感来自于侦探电影《红辣椒》 (Paprika) ) 方法通过生成合成交互数据来规避这些问题。如果我们还不能在现实世界中信任模型,我们就为它建立一个数字游乐场。
方法论: 构建好奇的智能体
该论文的核心方法由三大支柱组成: 任务设计、数据构建和优化。
1. 游乐场: 任务设计
要教智能体如何探索,首先需要需要探索的环境。研究人员设计了 10 个不同的任务组。这些不仅仅是简单的问答数据集;它们是交互式环境,智能体必需通过多轮交互才能成功。
至关重要的是,这些任务是部分可观测的 。 智能体在开始时不知道答案。它必须执行操作 (提问、猜测、检查网格) 以揭示隐藏信息。
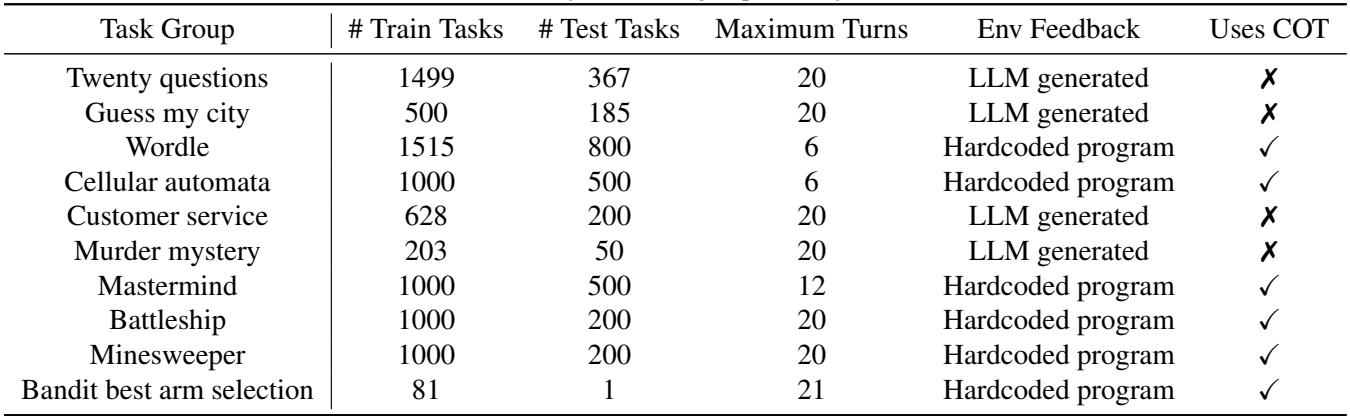
如表 1 所示,任务范围从语言游戏到逻辑谜题:
- 二十个问题 (Twenty Questions) & 猜猜我的城市 (Guess My City): 纯粹的信息收集。智能体必须有效地缩小巨大的搜索空间。
- Wordle & 珠玑妙算 (Mastermind): 演绎推理,反馈允许智能体排除可能性。
- 海战棋 (Battleship) & 扫雷 (Minesweeper): 2D 网格探索,需要在覆盖新区域 (探索) 和针对特定区域 (利用) 之间取得平衡。
- 客户服务 (Customer Service) & 谋杀之谜 (Murder Mystery): 角色扮演场景,其中的“环境”是另一个扮演客户或游戏管理员的 LLM。
这里的多样性是关键。如果你只在“二十个问题”上训练智能体,它学会的是问“它是动物吗?”它学不到二分查找的抽象概念。通过在许多不同的任务上进行训练,目标是强迫模型学习探索的底层逻辑。
2. 数据构建: 自我博弈 (Self-Play)
我们如何获得这些任务的训练数据?我们并没有让名为人类专家的玩家玩数百万局海战棋。相反,作者使用 LLM 本身来生成数据,这种技术通常被称为“自举 (bootstrapping) ”。
他们采用一个基础模型 (如 Llama-3.1-8B-Instruct) 并让它玩这些游戏。为了确保模型尝试不同的策略,他们使用了高温度的 Min-p 采样 。 这种随机性鼓励模型探索不同的轨迹。
对于每个任务,他们生成多次尝试。有些会失败,有些会成功。然后他们创建偏好对 \((h^w, h^l)\):
- 赢家 (\(h^w\)): 以最少回合数解决任务的轨迹。
- 输家 (\(h^l\)): 失败或花费更长时间的轨迹。
这创建了一个数据集,本质上是在说: “在这种情况下,这个行动序列比那个更好。”
3. 优化: SFT 和 DPO
数据收集完毕后,训练分两个阶段进行。
监督微调 (SFT)
首先,在获胜轨迹上对模型进行微调。这类似于行为克隆——教模型模仿它在数据生成阶段发现的成功策略。
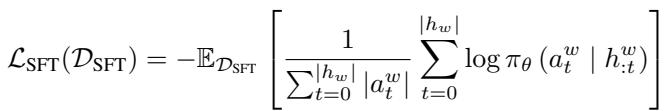
目标函数 (方程 1) 最大化获胜轨迹 \(h^w\) 中所采取行动的可能性。
直接偏好优化 (DPO)
SFT 很好,但它并没有明确教模型不该做什么。强化学习通常更擅长这一点,但传统的 RL (如 PPO) 计算成本高且不稳定。
作者使用了直接偏好优化 (DPO) 的序列变体。DPO 允许模型与偏好 (赢 > 输) 对齐,而无需单独的奖励模型。
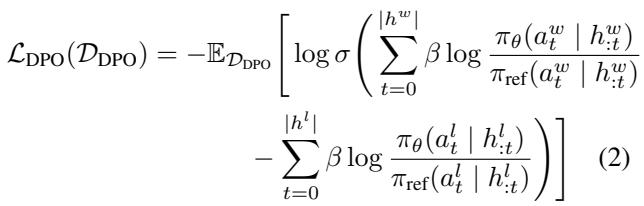
方程 2 展示了多轮 DPO 损失。相对于参考模型,它增加了获胜行动的概率,同时降低了失败行动的概率。
为了稳定训练,他们实际上将这两种方法结合为鲁棒偏好优化 (RPO) :
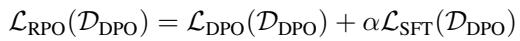
通过将 SFT 损失加回 DPO 目标 (方程 3) ,他们防止模型偏离太远或“遗忘”交互的基本语法,这是一个被称为非预期去对齐 (unintentional unalignment) 的常见问题。
通过课程学习实现可扩展性
这篇论文最有趣的贡献之一是他们如何处理训练成本。在标准的 LLM 训练中,瓶颈是梯度更新 (反向传播) 。在 PAPRIKA 中,瓶颈是采样 。 运行数千集“谋杀之谜”来生成训练数据需要大量的推理时间。
此外,并非所有任务在任何时候都同样有用。如果一个任务太难,模型永远赢不了,你就得不到正向信号。如果太简单,模型学不到新东西。
为了解决这个问题,作者提出了一种基于任务“学习潜力”的课程学习策略。他们定义了一个称为变异系数 (coefficient of variation, \(\nu\)) 的指标:
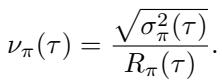
这里的直觉很优雅:
- \(R_{\pi}(\tau)\) 是平均奖励 (表现) 。
- \(\sigma_{\pi}^2(\tau)\) 是该表现的方差。
- 如果相对于均值而言方差很高,说明模型表现不稳定。它能解决任务,但经常失败。这就是“恰到好处”的区域,模型在这里能学到最多东西。
他们将任务选择视为一个多臂老虎机 (Multi-Armed Bandit) 问题。他们使用置信上界 (UCB) 算法来动态选择从哪些任务中采样数据,优先考虑那些估计学习潜力 (\(\nu\)) 最高的任务。
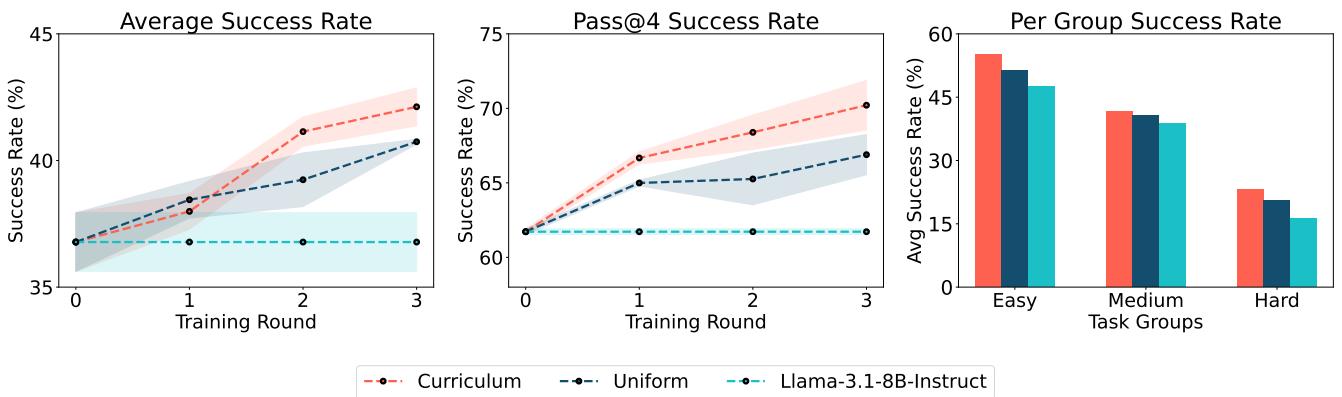
图 4 展示了这种方法的有效性。课程策略 (红线) 始终优于均匀采样 (蓝线) ,更快地实现了更高的成功率。这证明了智能的数据选择与训练算法本身同样重要。
实验与结果
那么,在扫雷和 Wordle 上训练智能体真的能让它变聪明吗?
1. 训练任务上的提升
首先是基础表现。研究人员使用 PAPRIKA 微调了 Llama-3.1-8B-Instruct 和 Gemma-3-12B-IT。
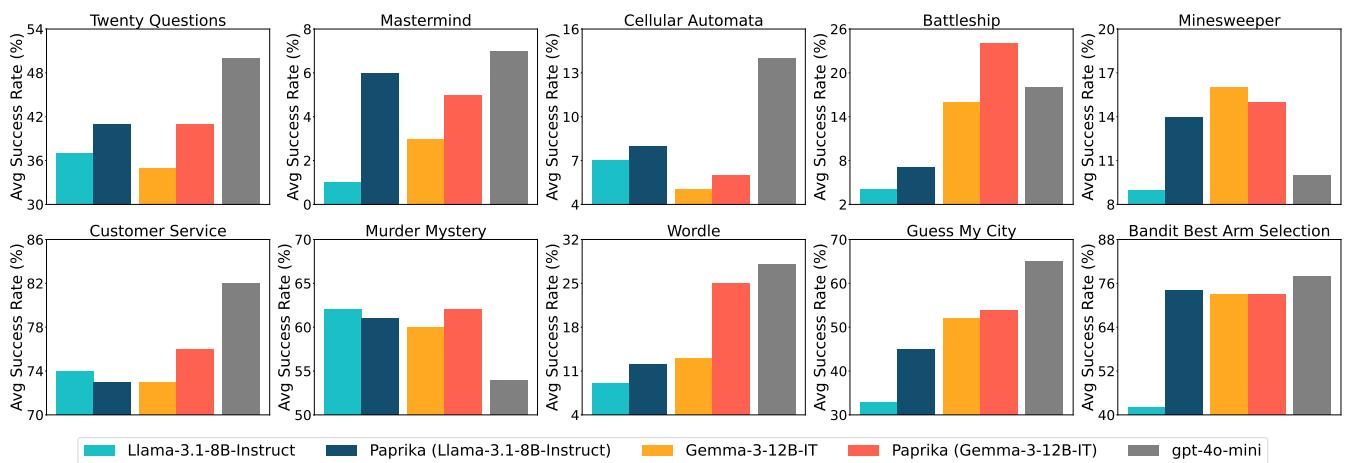
图 2 显示了所有 10 个任务组的结果。深蓝色柱状图 (PAPRIKA) 始终优于基础 Llama 模型 (青色) ,并且经常能与更大的 GPT-4o-mini (灰色) 相媲美。在“猜猜我的城市”和“Wordle”中,提升是巨大的。
他们还发现智能体变得更高效了。
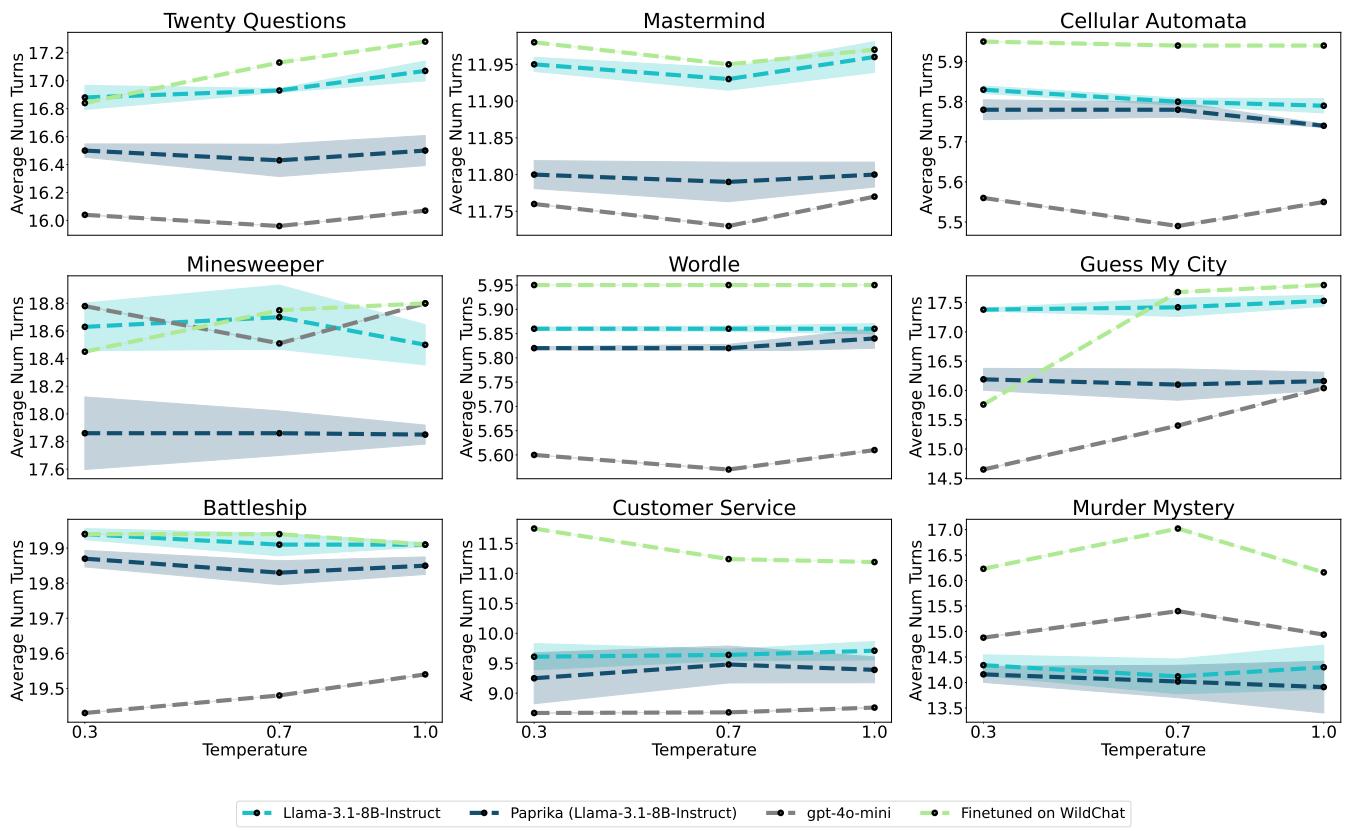
图 7 显示,与基础模型相比,PAPRIKA (深蓝色) 解决任务所需的回合数更少。这表明模型不仅仅是靠运气;它正在提出更好的、更具战略性的问题来快速修剪搜索空间。
2. 圣杯: 零样本泛化
这项研究最关键的问题是: 这种能力可以迁移吗? 如果我们在“二十个问题”上训练智能体,它在“海战棋”上会变得更好吗?
为了测试这一点,他们进行了留一法 (LOO) 实验。他们在 9 个任务组上训练模型,并在第 10 个未见过的组上进行测试。
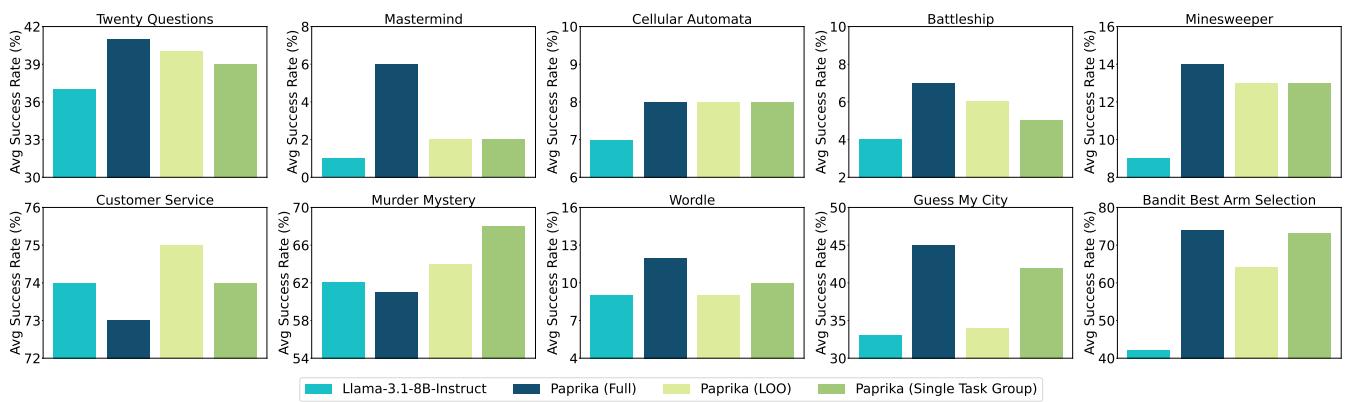
图 3 展示了这些泛化结果。
- PAPRIKA (LOO) (浅绿色) 指的是在训练期间从未见过测试任务的模型。
- 值得注意的是,LOO 模型在几乎每个任务上都显著优于基础 Llama 模型。
- 在某些情况下 (如“二十个问题”) ,在其他任务上训练的模型的表现几乎与在该特定任务上训练的模型一样好。
这表明 PAPRIKA 正在教模型一种可泛化的技能——战略性探究——而不仅仅是记住特定游戏的规则。
3. 这会破坏模型吗?
对特定数据 (如游戏) 进行微调的一个普遍担忧是“灾难性遗忘”,即模型失去其通用能力 (如编写代码或回答历史问题) 。

表 2 显示了在 MT-Bench 和 MMLU 等标准基准上的评估。PAPRIKA 模型没有表现出明显的退化。事实上,它在 GPQA 和 Math 等重推理的基准测试上略有提升,这表明学习探索也可能有助于通用推理。
定性分析: 观察行为
统计数据很好,但一个“好奇”的智能体实际上听起来是什么样的?
让我们看一个“二十个问题”任务中的例子,其中要猜的概念是“素数 (Prime Numbers) ”。
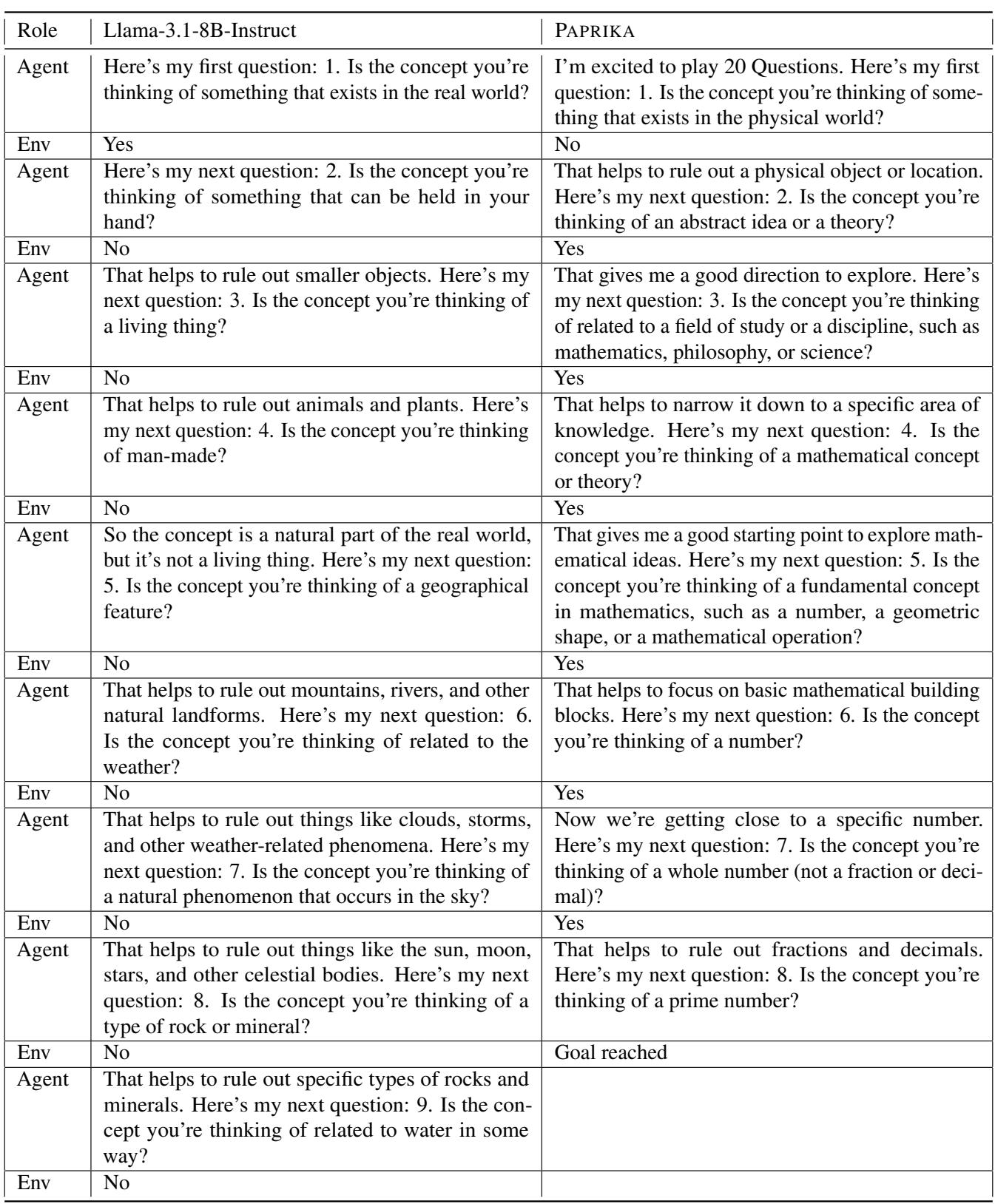
表 7 突出了差异:
- Llama-3.1 (Base): 提出模糊、多余的问题。它问这是否是“现实世界”的物体,然后问是否是“人造的”,然后问是否是“地理特征”。它不知所措,未能识别出主题。
- PAPRIKA: 立即对领域进行分类 (“抽象概念”) 。它将其缩小到研究领域 (“数学”) ,然后是特定类型 (“数字”) ,然后是属性 (“素数”) 。
PAPRIKA 智能体用自然语言展示了二分查找行为 。 它明白要找到答案,必须通过每个问题对可能性空间进行二分。
结论
PAPRIKA 框架代表了构建自主智能体的重要一步。通过将探索视为一种可学习、可迁移的技能,作者表明我们不需要在智能体可能遇到的每一个场景上都对其进行训练。
相反,通过创建一个包含多样化合成推理任务的“健身房”并使用偏好优化,我们可以灌输一种通用的战略性信息收集能力。
关键要点:
- 合成数据有效: 只要你过滤出高质量的轨迹,就可以使用模型自身生成的数据来提升推理能力。
- 探索是可泛化的: 学习玩 Wordle 有助于你玩海战棋。假设检验和状态排除的底层逻辑可以跨领域迁移。
- 课程很重要: 使用简单的统计数据 (方差与均值) 来优先考虑训练任务可以极大地提高样本效率。
随着我们迈向能够预订航班、调试代码和进行科学研究的智能体时代,这种“提出正确问题”的能力将是聊天机器人与真正智能助手之间的区别。PAPRIKA 表明,到达那里的路径可能就是玩大量的游戏。