](https://deep-paper.org/en/paper/2502.20330/images/cover.png)
大型语言模型 (LLM) 处理海量信息的能力呈爆炸式增长。我们已经从只有几千个 token 的上下文窗口,发展到能够在单个提示中摄入数百万字——包括整本书、代码库或法律档案——的模型。然而,这场“长上下文”革命伴随着高昂的代价: 延迟。
处理 128K token 的文档计算成本高昂。随着上下文的增加,键值 (KV) 缓存操作受限于内存带宽,导致生成速度像爬行一样缓慢。为了缓解这一问题,开发者通常面临两个极端的选择: 要么严格使用 检索增强生成 (RAG) , 速度虽快但可能忽略“全局”信息;要么使用 长上下文 (LC) 推理,虽然全面但慢得令人痛苦。
在本文中,我们将探讨一篇新的研究论文 RAPID , 它提出了第三种路径。通过结合 RAG 和投机解码 (Speculative Decoding) ,研究人员创造了一种方法,将长上下文推理加速超过 \(2\times\),同时还提高了生成质量。
1. 困境: 上下文 vs. 速度
在深入探讨解决方案之前,我们需要了解瓶颈所在。当你基于一个巨大的文档向 LLM 提问时,模型必须关注该文档中的每一个 token 才能生成答案。
在标准的 投机解码 (Speculative Decoding, SD) ——一种流行的加速推理技术——中,一个较小的“草稿”模型会快速猜测接下来的几个 token,而较大的“目标”模型则并行验证它们。如果草稿是正确的,你就免费获得了 token 并提升了速度。
然而,SD 依赖于这样一个假设: 草稿模型比目标模型快得多。在长上下文场景中,这一假设不再成立。为什么?因为草稿模型也必须处理这巨大的 128K 上下文来进行猜测。仅仅是为草稿模型加载 KV 缓存所需的巨大内存带宽,就抵消了它的速度优势。
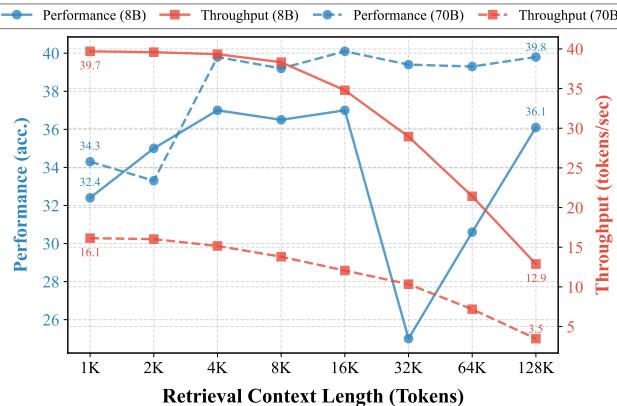
如 图 1 所示,随着上下文长度的增加,吞吐量 (红线) 崩溃式下降。注意 8B 模型的红色虚线: 它从 1K 上下文时的约 40 tokens/sec 降至 128K 上下文时的约 12 tokens/sec。当上下文变得过长时,标准加速技术的有效性荡然无存。
2. RAPID 登场: 检索增强投机解码
研究人员推出了 RAPID (Retrieval-Augmented SPeculatIve Decoding) 。其核心洞见非常优雅: 草稿模型不需要读完整本书来做出好的猜测;它只需要相关的页面。
RAPID 在两个根本方面修改了标准的投机解码工作流程:
- RAG 草稿器 (RAG Drafter) : 草稿模型在压缩的、检索到的上下文上运行,而不是在完整文档上运行。
- 检索增强目标分布: 目标模型 (阅读完整文档) 通过推理时知识迁移 (inference-time knowledge transfer) 进行调整,使其更能接受草稿模型的见解。
2.1 RAG 草稿器
在传统 SD 中,如果目标模型处理上下文 \(\mathcal{C}\),草稿模型也要处理 \(\mathcal{C}\)。而在 RAPID 中,草稿模型处理的是 \(\mathcal{C}^S\)——这是一个缩短版本的上下文,仅包含与当前查询最相关的前 \(k\) 个检索块。
让我们看看数学公式。目标模型分布 \(p(x_i)\) 以完整上下文为条件:
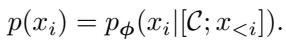
然而,草稿分布 \(q(x_i)\) 以压缩上下文 \(\mathcal{C}^S\) 为条件:
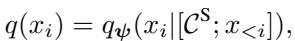
这种解耦至关重要。即使目标模型正在艰难地处理 100,000 个 token,草稿模型可能只关注 4,000 个 token。这恢复了草稿器的速度优势。
这种效率允许了一种称为 向上投机 (Upward-Speculation) 的范式转变。因为草稿器在如此小的上下文上运行,我们实际上可以使用更大的模型作为更小目标模型的草稿器,只要草稿器的上下文足够短。例如,使用一个 70B 参数的模型 (阅读 4K token) 为 8B 参数的模型 (阅读 128K token) 起草。
2.2 验证的挑战
标准的投机解码使用严格的接受标准。草稿 token \(x'\) 的接受与否取决于目标概率与草稿概率的比率:
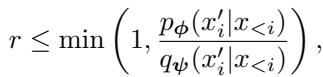
如果目标模型认为草稿 token 不太可能出现 (\(p(x')\) 很低) ,该 token 就会被拒绝。
问题就在这里: 如果是草稿器对了,而目标模型错了怎么办? 长上下文模型经常遭受“迷失在中间” (lost-in-the-middle) 现象的困扰,即它们会遗忘埋藏在长提示中间的信息。明确检索相关块的 RAG 草稿器实际上可能会生成更好的 token。但在标准 SD 规则下,目标模型会因为这个优质 token 偏离了它自己 (有缺陷) 的分布而拒绝它。
2.3 检索增强目标分布
为了解决这个问题,RAPID 不仅仅使用原始的目标分布。它采用了 推理时知识迁移 。 其想法是将 RAG 草稿器视为“老师”,将“学生” (目标模型) 推向检索到的信息。
研究人员定义了一个新的、增强的目标分布 \(\hat{p}(x_i)\)。该分布将目标模型的 logits \(z(x_i)\) 与草稿概率和目标概率之间的差值混合:
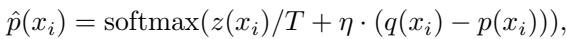
这里,\(\eta\) (eta) 是控制知识迁移强度的超参数,\(T\) 是温度。
这为什么有效?
这个方程源自知识蒸馏损失的梯度。如果我们把 RAG 草稿器的输出 \(q(x)\) 视为我们想要逼近的基准真相 (ground truth) ,那么关于 logits 的损失梯度为:
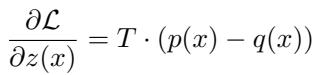
通过利用这个梯度更新目标 logits,我们将目标分布向 RAG 草稿器的分布移动。调整后的 logit \(\hat{z}\) 变为:
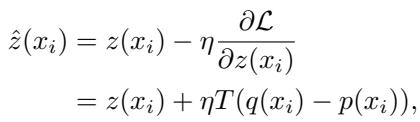
这产生了一个“检索增强目标分布”,它既保留了长上下文模型的深度推理能力,又对草稿器提供的精确、检索到的事实持开放态度。
新的接受标准
有了这个调整后的分布 \(\hat{p}\),投机解码循环中的验证步骤也随之改变。我们现在对照增强后的目标来检查草稿 token:
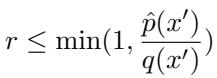
这种修改提高了 RAG 草稿器生成的高质量 token 的接受率,防止目标模型顽固地拒绝它在海量上下文中可能忽略的有效信息。
如果 token 仍然被拒绝,RAPID 会从残差分布中重新采样,确保最终输出在数学上与增强后的目标分布保持一致:
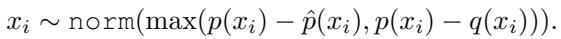
3. 实验结果
研究人员在 \(\infty\)Bench (InfiniteBench) 和 LongBench v2 等主要基准上评估了 RAPID,使用了 LLaMA-3.1 (8B 和 70B) 和 Qwen2.5 模型。结果突显了速度和质量的双重提升。
3.1 性能和加速比
表 1 展示了综合比较结果。重点关注 准确率 (Accuracy AVG) 和 加速比 (Speedup) 。
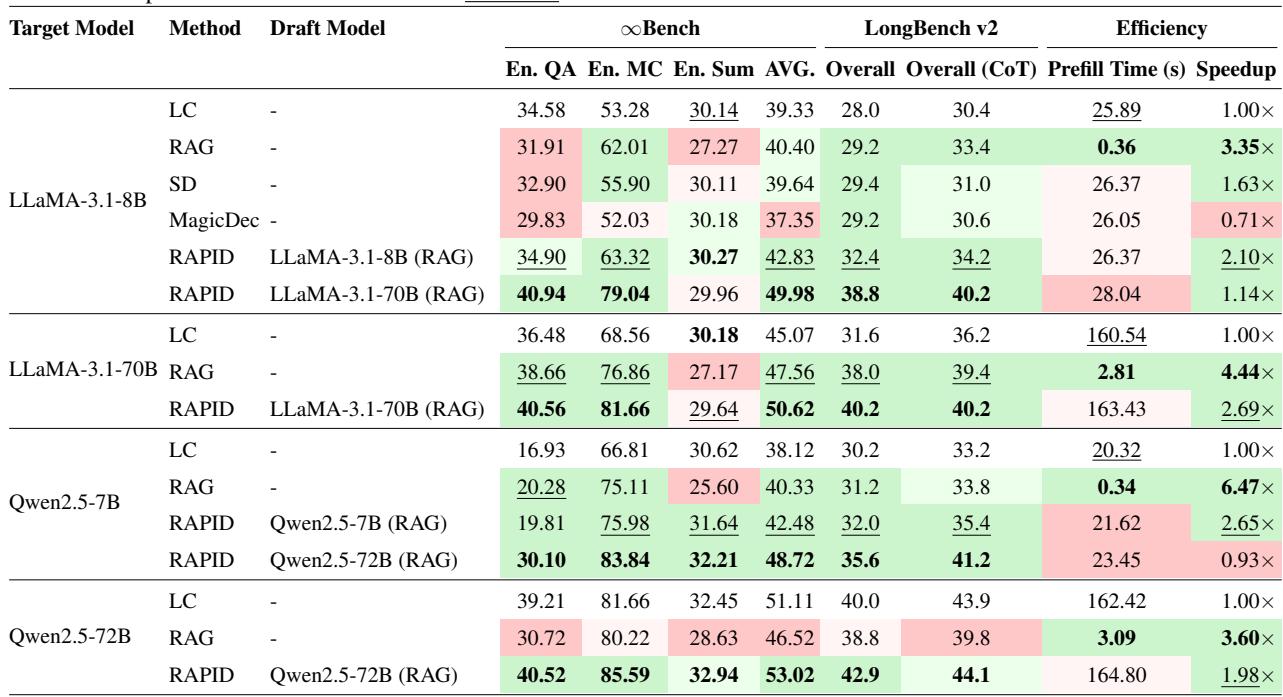
表 1 的主要结论:
- 自投机 (相同大小草稿器) : 对于 LLaMA-3.1-8B,RAPID 将准确率从 39.33 (LC 基线) 提高到 42.83 , 同时实现了 2.10x 的加速。它在速度和质量上都击败了标准 SD 和 “MagicDec”。
- 向上投机 (更大草稿器) : 看 LLaMA-3.1-8B 作为目标,但 LLaMA-3.1-70B 作为草稿器的那一行。得分跃升至 49.98 。 这实际上允许一个主要 8B 模型通过利用更大模型对检索块的推理能力,表现得像一个 70B 模型。
- 效率: RAPID 始终提供超过 LC 基线 2 倍以上的加速,接近纯 RAG 的吞吐量,但正确率显著更高。
3.2 收益来自哪里?
RAPID 只是简单地平均两个模型吗?不完全是。这种交互产生了一种协同效应,使得系统的表现优于任何单独一个模型。
图 2 分解了相对成功率和失败率。
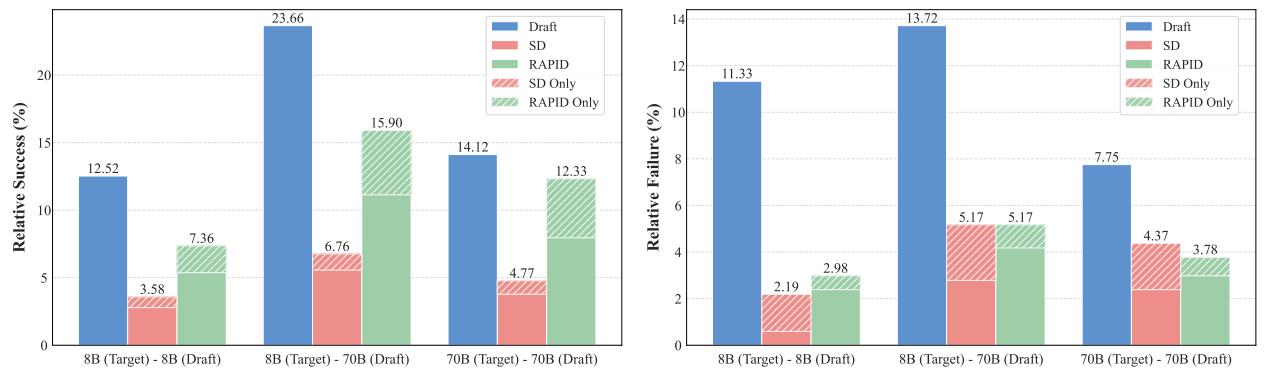
关注标有 RAPID 的绿色部分。在 “8B (Target) - 70B (Draft)” 列中:
- 仅 RAPID (RAPID Only,绿色横条纹) : 这代表了目标 8B 模型和草稿 70B 模型单独都未答对,但 RAPID 答对了的情况。这种“涌现”能力表明,将全上下文理解与敏锐的检索焦点相结合,能产生更卓越的推理。
- 相对成功 (Relative Success) : RAPID 捕获了草稿模型 (蓝色) 的优势,同时减少了失败。
3.3 鲁棒性和上下文长度
关于 RAG 一个常见的问题是: “如果检索很差怎么办?”或者“这是否只对海量上下文有效?”
图 3 说明了上下文长度 (X 轴) 和检索长度 (线条) 对准确率和速度的影响。
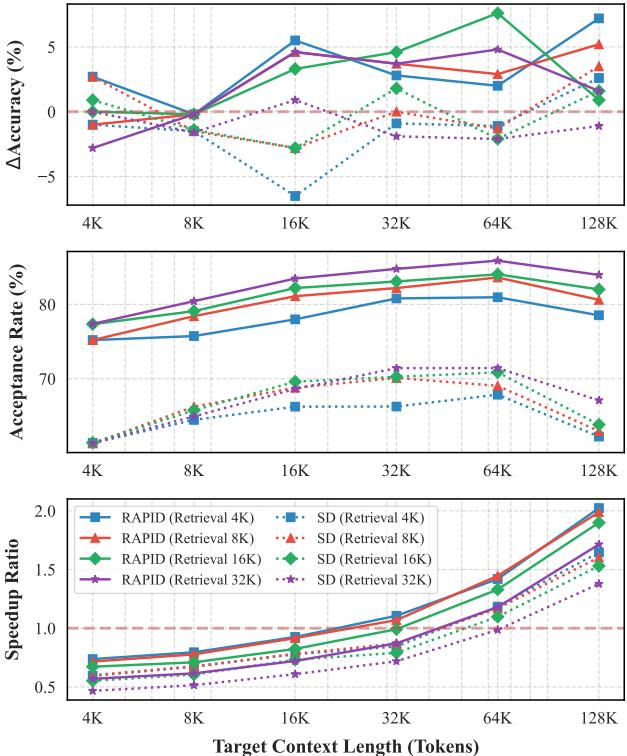
- 底部图表 (加速比) : 注意加速比随着目标上下文长度的增加而攀升。一旦上下文超过约 32K token,RAPID 就会变得高效 (加速比 > 1) 。在此之前,管理两个模型的开销可能不值得。
- 顶部图表 (准确率) : 与标准 SD (灰色线,通常在长上下文中性能下降) 相比,RAPID (彩色线) 始终保持较高的准确率提升 (\(\Delta\) Accuracy) 。
3.4 实际应用: 多轮对话
基准测试固然好,但在聊天应用中感觉如何呢?研究人员在具有扩展聊天历史 (约 122K token) 的多轮对话设置上测试了 RAPID。

如 表 2 所示,RAPID 获得了 4.21 的质量评分 (由 GPT-4 评分) ,显著高于单独的目标 LLM (2.82) 或标准 SD (2.94)。它还保持了近 77% 的健康接受率,确保用户界面响应迅速。
3.5 对糟糕检索的鲁棒性
最后,研究人员通过输入无关的检索上下文 (故意使用糟糕的 RAG) 对系统进行了压力测试。
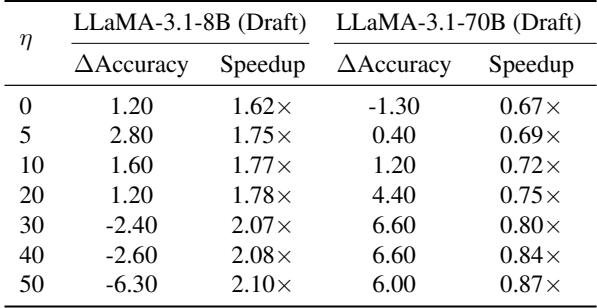
表 3 显示,即使检索内容无关,RAPID (当 \(\eta \le 20\) 时) 仍能保持正向的准确率收益和加速。目标模型的内部知识充当了护栏。然而,如果 \(\eta\) 设置得过高 (强迫目标过多地听取草稿器的意见) ,性能就会下降。这突显了知识迁移参数 \(\eta\) 的重要性: 它平衡了“阅读” (目标模型) 与“略读” (RAG) 。
4. 结论与启示
RAPID 代表了部署长上下文 LLM 的重要一步。通过承认 逐字阅读太慢 且 略读可能不准确 , 作者设计了一个兼顾两者的系统。
这对部署有着令人兴奋的启示:
- 降低成本: 我们可以使用较小的 GPU 来运行目标模型处理长上下文请求,同时依靠 RAG 来提速。
- 模型协同: “向上投机”的概念允许我们利用大模型来提升小模型的智能,而无需承担在全上下文上运行大模型的巨大延迟。
对于 NLP 领域的学生和研究人员来说,RAPID 是混合系统设计的大师级范例——它表明有时解决内存瓶颈的最佳方法不是更好的硬件,而是更聪明的算法。
本文基于论文 “RAPID: Long-Context Inference with Retrieval-Augmented Speculative Decoding” (2025)。