](https://deep-paper.org/en/paper/2503.01103/images/cover.png)
引言
在当前的 AI 图像生成领域,我们见证了基于似然模型的统治地位。无论是扩散模型 (Diffusion Models,如 Stable Diffusion 或 EDM) 还是自回归模型 (Autoregressive Models,如 VAR) ,这些架构已成为稳定性和可扩展性的标准。它们是“AI 艺术”革命背后的引擎。
然而,这其中存在一个陷阱。这些模型通常使用最大似然估计 (MLE) 进行训练。虽然 MLE 在确保模型覆盖数据的整体分布方面表现出色,但它有一个众所周知的缺陷: 模式覆盖 (mode-covering) 。 简单来说,为了避免对任何真实数据点分配零概率,MLE 训练的模型往往会“两边下注”,将概率质量分摊得太薄。视觉上的结果就是: 生成的图像通常看起来模糊,或者缺乏让照片看起来真正“真实”的高频细节。
为了解决这个问题,研究人员和工程师通常依赖推理时的技巧,如无分类器引导 (Classifier-Free Guidance, CFG) ,以强制模型生成更清晰的结果,但这往往以牺牲多样性或推理速度为代价。
但是,如果我们能在不需要 GAN (生成对抗网络) 训练不稳定性的情况下,获得 GAN 的清晰度呢?如果我们根本不需要一个单独的判别器网络呢?
这就是 直接判别优化 (Direct Discriminative Optimization, DDO) 的前提。

如上图所示,DDO 将最先进的模型 (如 EDM2) 推向了新的高度——在不依赖重度引导的情况下实现了破纪录的 FID 分数。在这篇文章中,我们将解读 DDO 的工作原理,为什么你的生成模型“秘密地”是一个判别器,以及这种方法如何架起扩散模型与 GAN 之间的桥梁。
背景: 目标函数之争
要理解为什么 DDO 是必要的,我们首先需要审视当前训练范式的局限性。
最大似然的缺陷
基于似然的生成模型旨在最小化数据分布 (\(p_{data}\)) 与模型分布 (\(p_{\theta}\)) 之间的差异。在数学上,这等同于最小化前向 Kullback–Leibler (KL) 散度。
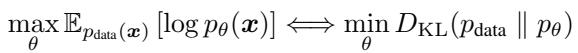
前向 KL 的问题在于,如果模型忽略了真实数据分布的任何部分,它会施加重罚。如果模型的容量有限 (所有模型都是如此) ,它就会通过分散其密度来覆盖所有内容以作为妥协。
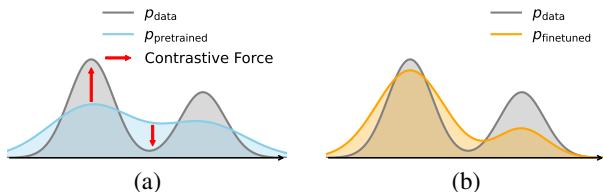
如上图 2(a) 所示,预训练模型 (蓝色曲线) 比真实数据 (灰色曲线) 更宽、更平坦。它覆盖了数据,但没有在数据达到峰值的地方达到峰值。这导致生成的是“平均化”或模糊的样本。
GAN 的替代方案
生成对抗网络 (GAN) 采取了不同的方法。它们不仅最大化似然;它们在玩一个游戏。生成器试图创建图像,而一个单独的 判别器 (discriminator) 网络试图分辨它们是真实的还是伪造的。
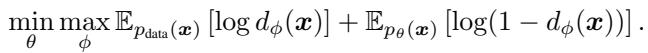
GAN 的目标 (通常与 Jensen-Shannon 散度或反向 KL 相关) 鼓励 模式寻找 (mode-seeking) 。 模型因生成完全位于数据流形上的样本而获得奖励,从而产生高保真度。然而,GAN 的训练以不稳定著称,因为你需要平衡两个相互对抗的独立网络。
核心方法: 直接判别优化
研究人员提出了一种方法,结合了似然模型的稳定性与 GAN 的清晰度。其核心洞察非常简单: 你不需要一个单独的判别器网络。
隐藏的判别器
让我们看看 GAN 判别器的最优解。如果我们有一个固定的生成器 (我们称之为参考模型,\(\theta_{ref}\)) 和真实数据,完美的判别器 \(d^*(x)\) 由真实数据密度与生成密度的比率定义:
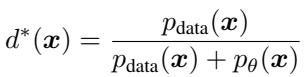
这个方程告诉我们,如果我们知道概率密度,我们就知道了最优判别器。基于似然的模型 (如扩散或自回归模型) 正是为了给出这些密度 (\(p_{\theta}\)) 而设计的。
因此,我们要做的不是训练一个单独的神经网络来分类“真与假”,而是利用模型本身来 隐式地 参数化判别器。我们将当前可训练的模型 (\(p_{\theta}\)) 与其前一个训练阶段的冻结版本 (\(p_{\theta_{ref}}\)) 进行比较。
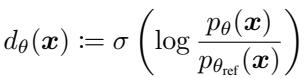
将此定义代入标准 GAN 损失函数,我们就得到了 DDO 目标函数 :
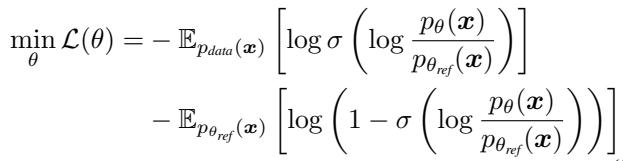
DDO 在实践中如何工作
DDO 框架在一个类似于“自博弈 (Self-Play) ”的循环中运行。
- 参考 (Reference) : 你从一个预训练模型 (例如标准的扩散模型) 开始。冻结它的一个副本作为“参考模型” (\(p_{\theta_{ref}}\)) 。
- 采样 (Sampling) : 你使用这个冻结的参考模型生成“伪造”样本。
- 优化 (Optimization) : 你训练目标模型 (\(p_{\theta}\)) 来区分真实数据和参考模型生成的样本。
由于判别器是由似然比定义的,最大化判别器的成功率在数学上等同于将模型分布 \(p_{\theta}\) 推向真实数据分布 \(p_{data}\)。
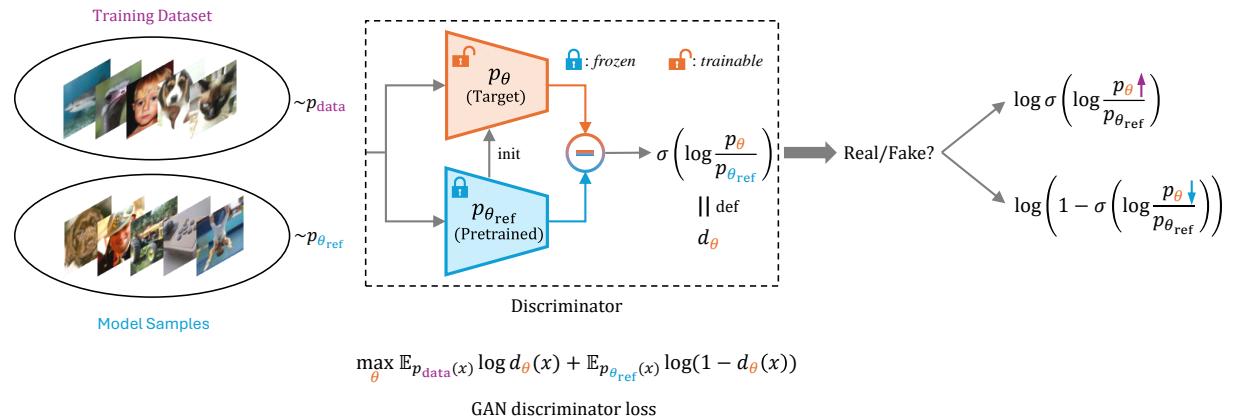
如上图所示:
- 对比力 (Contrastive Force) : 模型被训练以增加真实数据的似然 (正信号) 。
- 负信号 (Negative Signal) : 独特的是,模型也被训练以 降低 参考模型生成样本的似然 (负信号) 。
这种利用来自自身生成数据的“负信号”的做法,正是 DDO 区别于标准微调的地方。它积极地将模型推离基础模型倾向于生成的低质量区域。
理解梯度
在这个过程中,模型的权重实际上发生了什么变化?如果我们分析损失函数的梯度,就能精确地看到 DDO 如何改进模型:
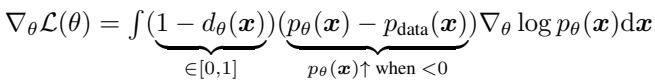
梯度包含三个部分:
- 似然梯度: \(\nabla \log p_{\theta}(x)\) — 增加概率的标准方向。
- 差值项: \((p_{\theta}(x) - p_{data}(x))\) — 如果概率低于数据分布,模型会提高概率;如果高于数据分布,则降低概率。
- 判别器权重: \((1 - d_{\theta}(x))\) — 更新的幅度根据样本看起来有多“假”进行加权。
这证实了 DDO 正在执行一种特定的密度校正,将概率质量从过度表示的区域 (模糊模式) 转移到代表性不足的区域 (清晰模式) 。
迭代优化 (自博弈)
一轮 DDO 能提供显著提升,但由于参考模型是固定的,改进最终会停滞。为了解决这个问题,作者采用了迭代策略。
第一轮结束后,优化后的模型成为第二轮的新参考模型。这使得模型能够不断攀升至更好的质量,有效地“自举 (bootstrapping) ”其改进。
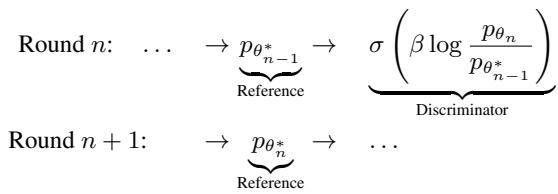
这种方法计算效率很高,因为每一轮都非常短——通常只需要不到原始预训练 epoch 的 1%。
与直接偏好优化 (DPO) 的联系
如果你关注大语言模型 (LLM) 的研究,这听起来可能很熟悉。DDO 的灵感来自于 直接偏好优化 (DPO) , 这是一种用于使 LLM (如 Llama 或 GPT) 与人类偏好对齐的技术,且无需复杂的强化学习设置。
然而,有一个关键区别。DPO 依赖于 成对 的偏好数据 (结果 A vs. 结果 B,其中人类更喜欢 A) 。DDO 作用于 不成对 的分布 (真实数据 vs. 生成数据) 。
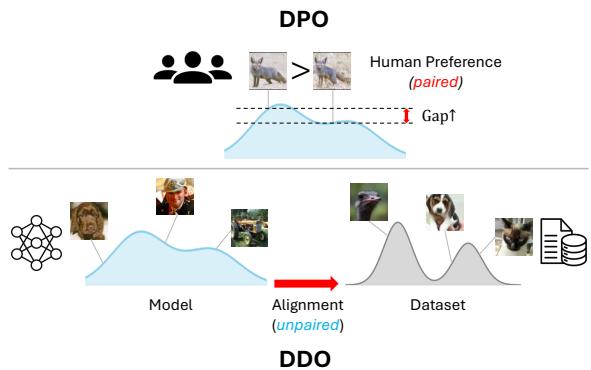
DDO 将 DPO 的数学优雅性调整到了视觉生成领域,将“人类偏好”替换为“基准真实数据分布”。
实验与结果
作者在两类主要的生成模型上测试了 DDO: 扩散模型 (Diffusion Models,如 EDM, EDM2) 和自回归模型 (Autoregressive Models,如 VAR) 。
扩散模型 (CIFAR-10 & ImageNet)
标准基准测试的结果令人印象深刻。在 CIFAR-10 上,DDO 显著降低了最先进的 EDM 模型的 FID (Fréchet Inception Distance,越低越好) 。
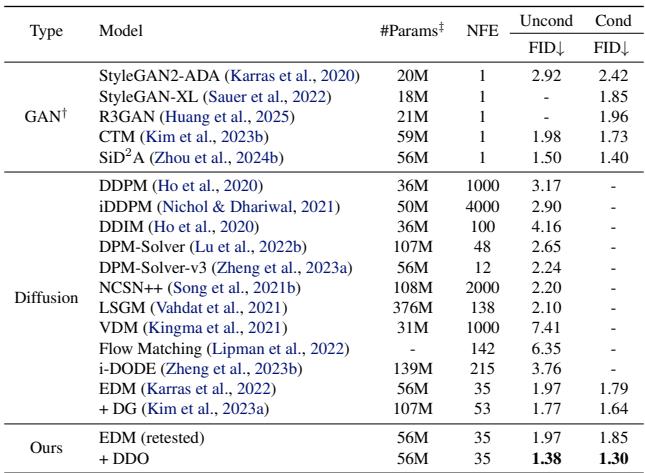
最值得注意的是,DDO 在无引导的情况下 实现了这些结果。通常,为了获得极低的 FID 分数,扩散模型依赖于无分类器引导 (CFG) ,这会使推理成本加倍 (因为每步需要运行模型两次) 。DDO 有效地将这种质量“内化”到了权重中。
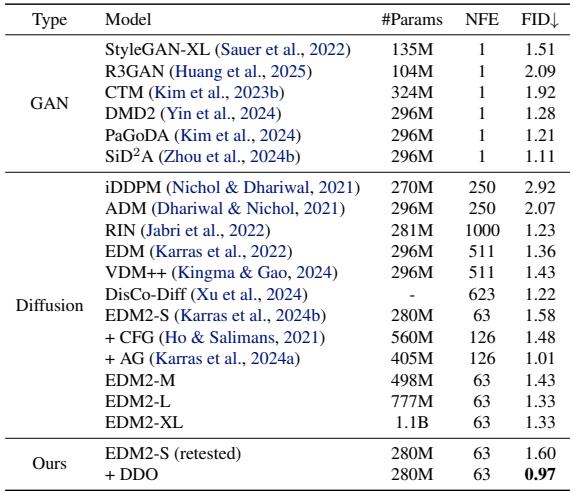
在 ImageNet-64 和 ImageNet-512 上,这种趋势仍在继续。该方法创造了无引导生成的最新 SOTA 记录。
多轮优化过程中样本的视觉演变清晰地展示了模型随时间推移解决细节和修复伪影的过程。

自回归模型 (VAR)
自回归模型通常需要重度 CFG 才能生成连贯的图像。作者将 DDO 应用于 VAR (视觉自回归) 模型。
下表展示了 FID (质量) 和 IS (Inception Score/多样性) 之间的权衡。DDO 微调后的模型 (绿线) 始终优于基础模型,在每个引导水平上都实现了更好的质量。
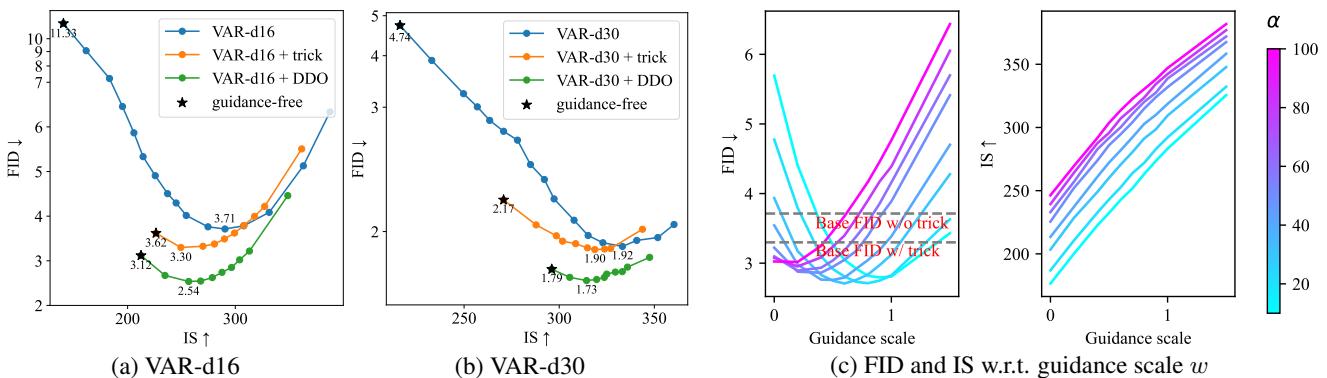
至关重要的是,DDO 使得 VAR 模型能够在没有任何“采样技巧” (如 top-k 或 top-p 采样) 的情况下生成高质量图像,而这些技巧通常会通过降低多样性来掩盖模型缺陷。
以下是 VAR 模型在 DDO 前后的视觉对比。注意 DDO 样本中伪影的减少和结构连贯性的提升。
DDO 前 (基础 VAR-d30, FID 4.74):

DDO 后 (VAR-d30 + DDO, FID 1.79):

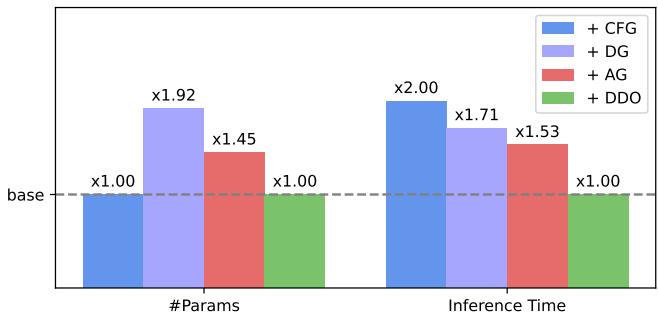
效率
DDO 的一个主要优势是它不改变模型架构。它纯粹是一个微调目标。这意味着:
- 无额外参数: 你不需要交付一个判别器网络。
- 无推理开销: 模型的运行速度与基础模型完全相同。
如图 5 所示,虽然其他方法如无分类器引导 (+CFG) 或判别器引导 (+DG) 显著增加了推理时间,但 DDO (绿色条) 保持了与基础模型相同的成本。
结论
直接判别优化 (DDO) 代表了一个统一的框架,架起了生成式 AI 两大主导范式之间的桥梁: 基于似然的建模和对抗训练。
通过认识到生成模型实际上包含其自身的判别器 (通过与参考模型的似然比) ,作者提供了一种微调模型以发挥其全部潜力的方法。该方法消除了 MLE 训练的“模糊性”,忽略了 GAN 判别器的不稳定性,并移除了引导技术的推理成本。
对于学生和研究人员来说,DDO 提供了一个强有力的教训: 有时改进模型所需的信息已经隐藏在模型内部——你只需要正确的目标函数来解锁它。
随着生成模型规模的不断扩大,像 DDO 这样能够从预训练权重中榨取最大性能的高效微调方法,很可能会成为深度学习工具箱中的标准工具。