](https://deep-paper.org/en/paper/2503.01776/images/cover.png)
在检索增强生成 (RAG) 和海量向量数据库的时代, 嵌入 (Embeddings) ——即数据的数值向量表示——的质量和效率至关重要。我们希望嵌入既能包含丰富的语义含义,又足够轻量,以便能在毫秒级时间内搜索数百万条记录。
长期以来,行业标准一直是稠密表示 (Dense representations) 。最近, 套娃表示学习 (Matryoshka Representation Learning, MRL) 因其能够创建可截断为不同长度的“嵌套”嵌入而受到欢迎 (甚至被 OpenAI 采用) 。然而,MRL 代价高昂: 它需要昂贵的全模型重新训练,并且当向量变短时,往往会遭受显著的精度下降。
一篇新论文 《Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation》 (超越套娃: 重访自适应表示的稀疏编码) 提出了一个引人注目的替代方案。研究人员推出了对比稀疏表示 (Contrastive Sparse Representation, CSR) , 这是一种放弃缩短向量,转而使其稀疏化的方法。通过将数据投影到一个高维空间,其中只有少数“神经元”处于激活状态,CSR 实现了比 MRL 更高的准确率和更快的检索速度,而且所有这些都不需要重新训练骨干模型。
在这篇文章中,我们将解构 CSR 的工作原理、背后的数学机制,以及为什么稀疏编码可能是自适应表示的未来。
问题: 保真度与速度之间的权衡
深度学习模型将输入 (图像、文本) 转换为固定长度的稠密向量 (例如 2048 维) 。
- 高维度 捕获更多的语义细节 (高保真度) ,但搜索速度慢 (高延迟) 。
- 低维度 搜索速度快,但会丢失关键信息 (低保真度) 。
套娃方法 (MRL)
MRL 试图通过训练模型对向量内的信息进行排序来解决这个问题。最重要的特征被推到前面。这允许你“切掉”向量的末端 (例如,只保留前 64 个维度) ,这仍然能得到一个还不错的表示。
然而,如图 1 所示,MRL (中间的表示) 有其局限性。为了使前几个维度强大,模型损害了整体质量。此外,你不能简单地将 MRL 应用于像 CLIP 或 BERT 这样的现有模型;你必须从头开始重新训练整个网络。
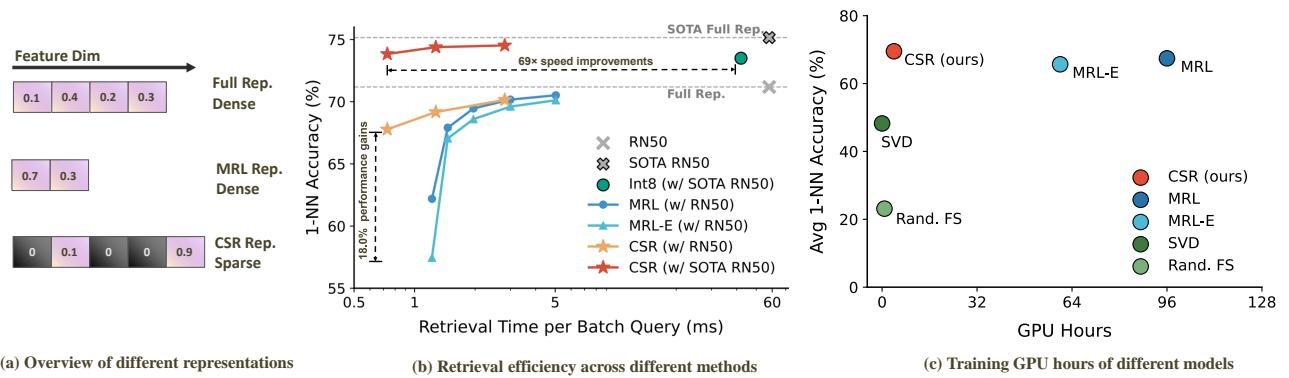
图 1(a) 展示了根本的区别。MRL 依赖于短的稠密向量。而本方法 CSR 使用长向量,但强制它们是稀疏的——这意味着大多数值为零。如图 1(b) 所示,与 MRL (蓝色圆圈) 相比,CSR (红色星星) 以更快的检索速度实现了更高的准确率,有效地打破了通常的权衡曲线。
解决方案: 对比稀疏表示 (CSR)
CSR 的核心洞察是: 稀疏性是一种比截断更好的压缩机制。 CSR 不是将信息挤压到一个微小的稠密向量中,而是将信息投影到一个更大的空间 (例如 8192 维) ,但确保对于任何给定的输入,这些维度中只有极小的一部分 (例如 32 个) 是非零的。
因为向量是稀疏的,我们不需要执行稠密矩阵乘法。我们可以使用优化的稀疏运算,其复杂度随非零元素的数量 (\(K\)) 而不是总维度 (\(d\)) 而变化。
架构
CSR 框架是一个轻量级的“适配器”,位于冻结的、预训练的骨干网络 (如 ResNet 或 Transformer) 之上。这意味着你可以拿一个现成的基础模型,在不破坏其原始权重的情况下使其具有自适应性。
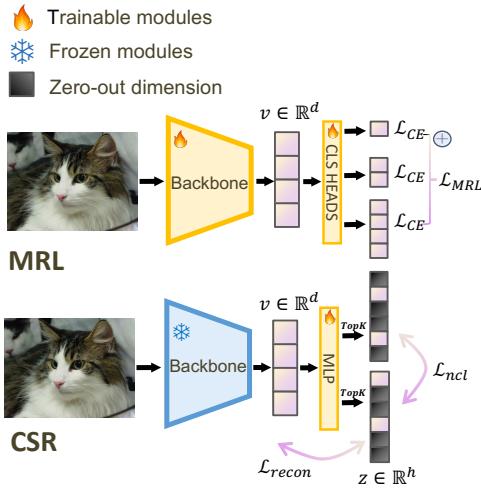
如图 2 所示,该过程如下:
- 骨干网络 (Backbone) : 图像/文本通过冻结的骨干网络以获得标准的稠密嵌入 \(v\)。
- 投影 (MIP) : 该向量被投影到一个更高维的隐藏空间。
- Top-K 激活: 系统强制执行“赢家通吃”的动态,只保留前 \(K\) 个值;其余变为零。
- 训练目标: 该模块使用重构损失 (自编码) 和判别损失 (对比) 的混合进行训练。
让我们分解一下使其工作的数学组件。
1. 稀疏自编码器 (SAE)
CSR 的首要目标是确保稀疏表示保留原始稠密嵌入的信息。为此,作者采用了稀疏自编码器。
他们使用一个线性编码器,后跟一个特定的非线性操作 TopK。
编码和解码过程:
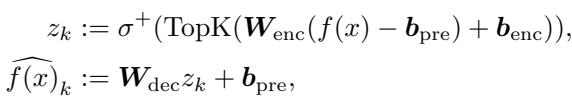
这里,\(f(x)\) 是原始的稠密嵌入。
- 编码器将其投影到隐藏表示 \(z\)。
- \(\text{TopK}\) 仅保留 \(k\) 个最大值。
- \(\sigma^+\) 是 ReLU 激活函数 (确保存非负性) 。
- 解码器尝试从这个稀疏的 \(z_k\) 重构原始输入。
主要的损失函数是重构损失 , 它简单地最小化原始嵌入与重构版本之间的距离:
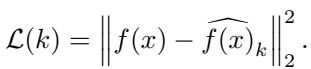
2. 解决“死潜变量”问题
稀疏自编码器的一个常见失效模式是“死潜变量” (dead latents) 。当隐藏空间中的某些维度在训练期间对于任何输入从未被激活时,就会发生这种情况。如果一个神经元从不激发,那就是浪费的容量。
为了解决这个问题,作者引入了一个巧妙的辅助损失。他们计算主要重构的误差 (残差) ,并尝试使用“死”神经元来重构该误差。这迫使模型利用整个特征空间。
改进后的重构目标变为:
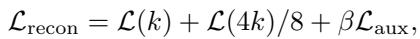
这个公式结合了:
- 稀疏度为 \(k\) 时的标准重构。
- 稀疏度为 \(4k\) 时的重构 (以鼓励更广泛的特征集) 。
- 专门针对死潜变量的辅助损失 \(\mathcal{L}_{aux}\)。
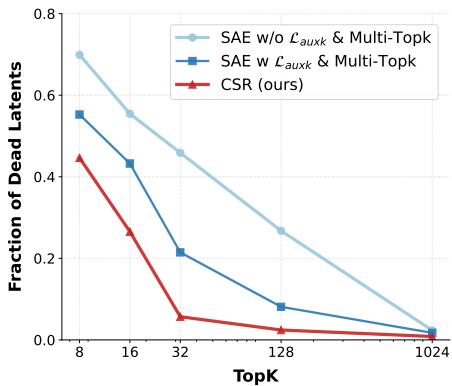
图 6 展示了这项工程的影响。红线 (CSR) 保持了接近零的死潜变量比例,而标准 SAE (蓝线) 随着稀疏度约束的增加而遭受严重影响。
3. 稀疏对比学习
仅有重构是不够的。对于分类或检索等任务,嵌入需要具有判别性——猫的嵌入应该靠近其他猫,而远离狗。
MRL 通过在每个截断层级应用交叉熵损失来处理这个问题:
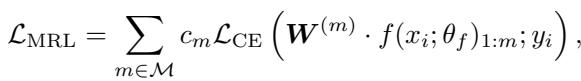
CSR 采用了不同的方法,集成了非负对比损失 (NCL) 。 这确保了稀疏特征 \(z\) 不仅有利于重构,而且是独特且可识别的。
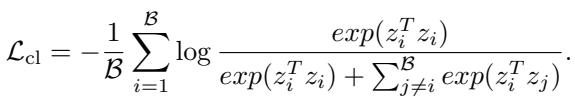
该损失函数将正样本对 (例如,同一图像的两个视图) 的稀疏表示推得更近,同时将负样本对推开。理论保证表明,NCL 有助于解纠缠特征,使稀疏向量中的每个维度代表一个独特的语义概念。
最终目标
CSR 的总训练目标结合了自编码器的重构能力和对比学习的判别能力:
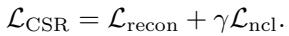
通过平衡这两者 (默认情况下 \(\gamma=1\)) ,模型创建了一个既忠实于源数据又对下游任务有用的表示。
为什么稀疏更快 (且更好)
有人可能会问: 如果 CSR 向量是 8192 维,它怎么会比 2048 维的稠密向量更快呢?
答案在于稀疏矩阵乘法 。 当计算查询项和数据库项之间的相似度时:
- 稠密: 你将每个数字与每个数字相乘。复杂度 \(\approx O(d_{dense})\)。
- 稀疏: 你只对非零元素进行乘法运算。如果你强制 Top-32 稀疏度,你只需要执行 32 次乘法,无论总维度 \(h\) 有多大。复杂度 \(\approx O(K)\)。
图 3 在实践中验证了这一理论。
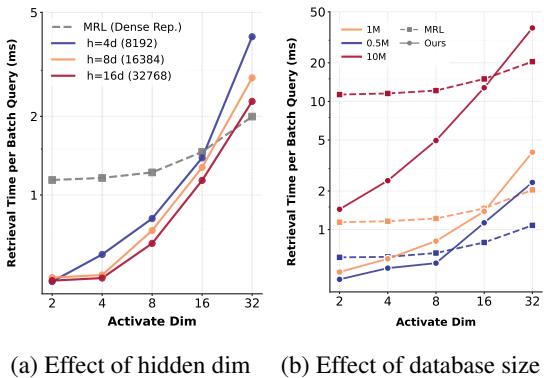
在图 3(a) 中,我们看到检索时间严格来说是激活维度 (K) 的函数。一个 \(K=16\) 的 CSR 向量的检索速度与长度为 16 的 MRL 向量一样快,即使 CSR 向量技术上存在于一个大得多的空间中。关键是, 图 3(b) 显示随着数据库规模增长到数百万,CSR 具有极好的扩展性。
此外,投影到更高维度 (\(h\)) 有助于“展开”数据流形,使其更容易线性分离类别。 图 5 显示了一个有趣的“倒 U 型”行为:
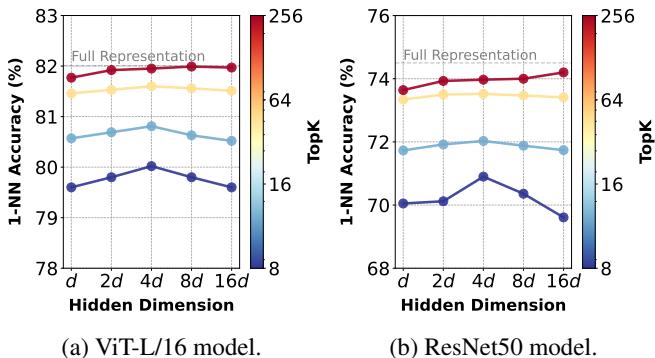
当隐藏维度大约是输入维度的 4 倍 (\(h=4d\)) 时,性能达到峰值。这表明在稀疏性约束变得过于激进之前,存在一个扩展的“最佳平衡点”。
实验结果
该论文在三种主要模态上评估了 CSR: 视觉、文本和多模态 (图像+文本) 。
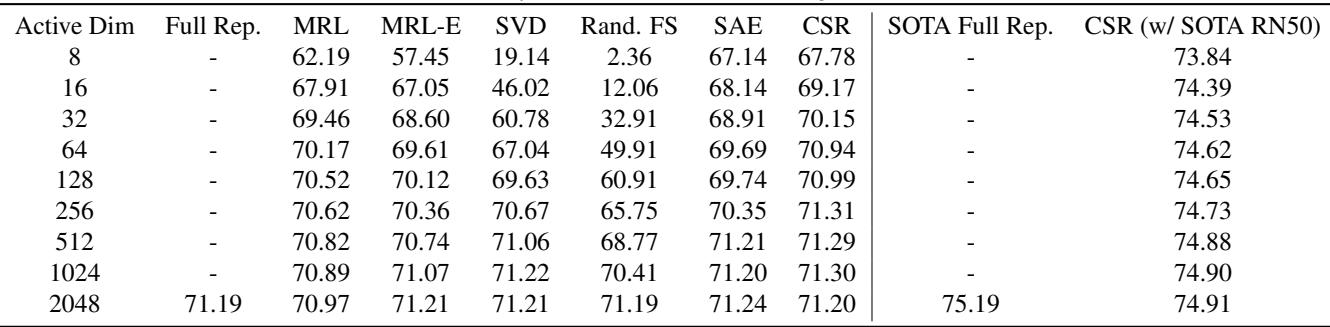
1. 视觉: ImageNet 分类
使用 ResNet-50 作为骨干网络,研究人员将 CSR 与 MRL 和其他压缩技术 (如 PCA/SVD) 进行了比较。
图 7(b) 展示了 1-最近邻 (1-NN) 准确率,这是检索性能的一个代理指标。
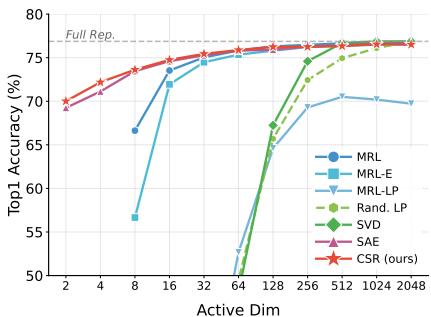
红线 (CSR) 明显优于蓝线 (MRL),尤其是在低维度端 (x 轴左侧) 。
- 在激活维度 = 16 时,CSR 创建了一个具有高准确率的可用嵌入。
- MRL 在这些低长度下挣扎明显,因为它被迫进行了有损压缩。
- CSR 以极少的激活参数匹配了“完整表示” (虚线) 的性能。
下表 (表 4) 详细列出了具体数字。请注意,在激活维度 8 时,CSR 实现了 67.78% 的准确率,而 MRL 仅为 62.19% 。
2. 文本: MTEB 基准测试
对于文本嵌入,作者在海量文本嵌入基准测试 (MTEB) 上进行了测试,涵盖分类、聚类和检索。
表 1 中的结果令人震惊。
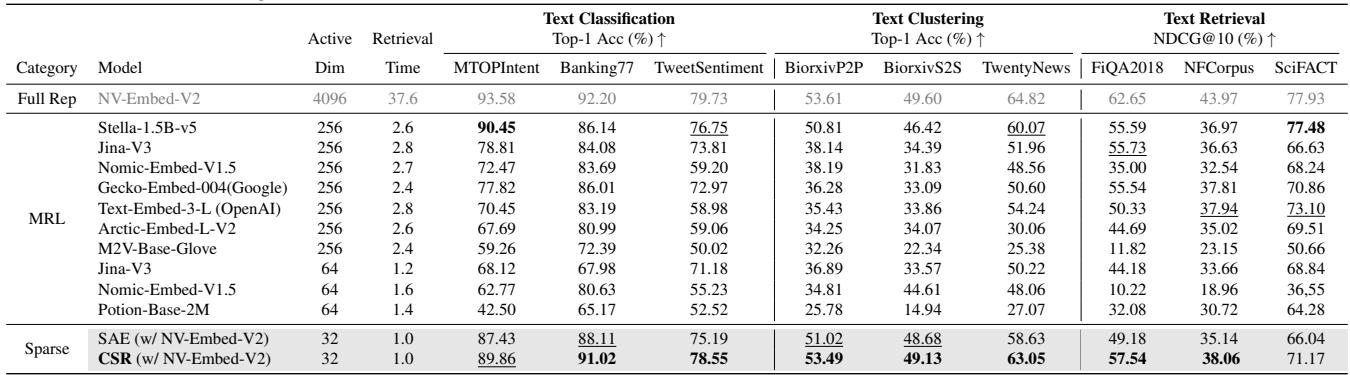
当匹配性能 (寻求相似的准确率) 时,CSR 提供了相对于稠密基线的 61 倍检索速度提升 。 当匹配检索效率 (相同速度) 时,CSR 相比 Nomic-Embed 等具有竞争力的基线提供了 15% 的性能提升 。
3. 多模态: 图像-文本检索
最后,他们将 CSR 应用于在 MS COCO 和 Flickr30k 数据集上使用文本查询检索图像 (反之亦然) 的任务。
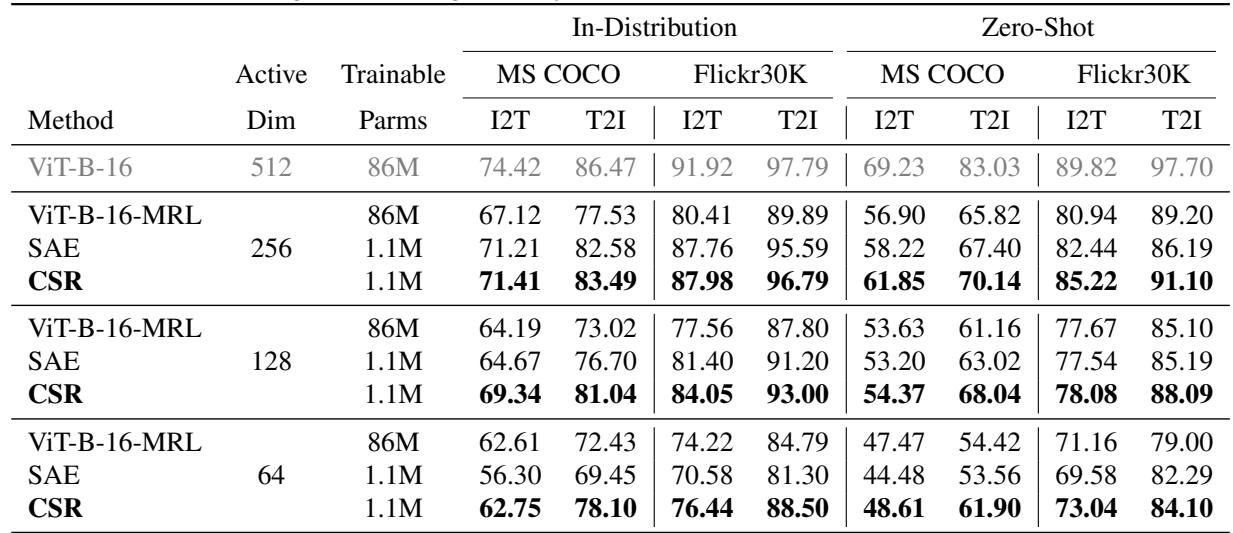
在表 2 中,我们看到 CSR (加粗部分) 始终优于微调后的 MRL 模型。这点尤其令人印象深刻,因为 CSR 是即插即用的——它仅在适配器上进行训练,而 MRL 基线涉及微调重量级的视觉 Transformer (ViT) 骨干网络。
结论: 稀疏性的理由
“超越套娃”这篇论文提出了一个强有力的论点,即我们一直从错误的角度处理自适应表示。与其截断稠密向量——这会丢弃信息并需要重新教模型如何打包数据——我们应该扩展并稀疏化它们。
主要收获:
- 无需重新训练: CSR 在冻结的、预训练的模型之上工作。这节省了大量的计算资源,并允许你轻松升级遗留系统。
- 更好的效率曲线: 稀疏矩阵运算使 CSR 与短稠密向量一样快,但准确率显著更高。
- 解决了“死神经元”问题: 通过巧妙的损失工程,CSR 确保了稀疏特征空间的高利用率。
随着向量数据库的持续增长以及对低延迟 AI 需求的增加,像对比稀疏表示这样的技术提供了一条鱼和熊掌兼得的路径: 既拥有大模型的丰富性,又拥有小模型的速度。
参考文献: Wen, T., Wang, Y., et al. (2025). Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation. Proceedings of the 42nd International Conference on Machine Learning.