](https://deep-paper.org/en/paper/2503.01811/images/cover.png)
我们正生活在“AI 智能体 (AI Agent) ”的时代。我们已经超越了只会写诗的简单聊天机器人;现在,我们评估大语言模型 (LLM) 的能力主要看它们是否具备推理、规划以及与软件环境交互的能力。像 SWE-Bench 这样的基准测试旨在测试 AI 是否能修复 GitHub issue,而其他测试则考察它们能否浏览网页或解决夺旗赛 (CTF) 安全挑战。
但在研究界,一直萦绕着一个问题: 这些基准测试能反映现实吗?
通常,基准测试依赖于“代理 (proxies) ”——即真实任务的简化版本。一个 CTF 挑战通常被设计成可解的;它有清晰的设置和一个具体的“旗帜 (flag) ”等待发现。然而,现实世界的安全漏洞往往隐藏在混乱、缺乏文档且像面条一样纠缠不清的代码库中。
在一篇引人入胜的新论文 AutoAdvExBench 中,来自 Google DeepMind 和苏黎世联邦理工学院 (ETH Zurich) 的研究人员提出了一个去除这些“代理”的基准测试。他们要求 LLM 执行机器学习安全研究人员的一项实际工作: 自主攻破针对对抗样本的防御。
结果揭示了一个惊人的“现实差距”。虽然当今最顶尖的 LLM 可以轻松解决 75% 的“家庭作业式”安全问题,但在面对真实的学术研究代码时,它们却遭遇滑铁卢,成功率仅为 13-21% 左右。
背景: 安全博弈
要理解这个基准测试,我们首先需要了解它所针对的具体安全领域: 对抗样本 (Adversarial Examples) 。
在计算机视觉领域,对抗样本就像是机器的视错觉。这是一张经过修改的图像 (比如一张熊猫的照片) ,其中加入了精心设计但通常肉眼不可见的噪声。对人类来说,它看起来仍然像一只熊猫。但对神经网络来说,它看起来像是一只长臂猿、一台烤面包机或一架客机。
猫鼠游戏
在过去的十年里,关于这个主题的论文数以千计。
- 攻击者 创建算法 (如 FGSM 或 PGD) 来生成这些噪声图像。
- 防御者 提出新的模型架构或训练方法来抵御这些攻击。
- 研究人员 随后分析这些防御措施,证明它们实际上并不起作用。
第三步至关重要。当研究人员发布一种新的防御方法时,其他专家会试图攻破它以验证其鲁棒性。这正是 AutoAdvExBench 分配给 LLM 的任务。
这项任务是可验证且客观的。如果 LLM 声称它已经攻破了防御,我们不需要人类来给它的“论文”打分。我们只需将生成的对抗图像输入防御模型。如果准确率下降,LLM 就成功了。如果准确率保持高位,LLM 就失败了。
构建基准测试: 寻找真实代码
这篇论文最重要的贡献之一是数据集本身的构建。研究人员没有编写合成的挑战。相反,他们挖掘了 AI 研究的历史,寻找其他科学家提出的真实防御实现。
策划这个数据集的过程凸显了机器学习复现性的危机。

如图 1 所示,作者从超过 600,000 篇 arXiv 论文的庞大池子开始。
- 过滤: 他们使用分类器和 LLM 将范围缩小到 1,652 篇关于对抗性防御的论文。
- 代码可用性: 他们检查了哪些论文实际上附带了 GitHub 仓库链接。
- 可复现性: 这是瓶颈所在。他们尝试运行 211 个不同的防御实现。
结果呢?只有 46 篇论文 (涵盖 51 个实现) 能够成功复现。其余的都因为缺少文件、依赖关系损坏、古老的库 (如 TensorFlow 0.11) 或缺乏文档而失败。
这一幸存的子集构成了 AutoAdvExBench 的“现实世界”数据集。它代表了研究人员写给研究人员看的代码——混乱、多样,且并未为了易用性而优化。
为了进行对比,作者还包含了一个“CTF 子集”。这是取自“评估对抗鲁棒性自学课程”中的 24 个防御。这些实现代表了现实世界中相同的数学防御原理,但代码是由专家重写的,专门为了整洁、可读和具有教学价值 (家庭作业式) 。
智能体: LLM 如何攻击 AI
你不能简单地把一篇研究论文粘贴到 ChatGPT 中然后说: “攻破它。”上下文窗口太小了,而且这项任务需要复杂的规划。研究人员设计了一个专门的智能体框架,以给予 LLM 最大的成功机会。
该智能体在一个循环中运行: 编写 Python 代码、执行代码、读取错误或输出,然后改进其方法。攻击过程被分解为四个不同的里程碑:
- 前向传播 (Forward Pass) : 智能体必须首先弄清楚如何加载防御模型,并运行单张图像以获得预测。这证明了智能体理解代码库的 API。
- 可微前向传播 (Differentiable Forward Pass) : 大多数攻击需要梯度 (数学导数,告诉你要改变哪些像素以降低模型的置信度) 。智能体必须确保防御代码支持反向传播。这通常是最难的一步,因为许多防御包括破坏标准梯度流的不可微预处理步骤 (如 JPEG 压缩) 。
- FGSM (快速梯度符号法) : 智能体尝试一种简单的单步攻击。这是一个“健全性检查”,以确保梯度实际上指向危害模型的方向。
- PGD (投影梯度下降) : 最后,智能体实施一种强大的迭代攻击。如果这一步成功,则该防御被视为“已攻破”。
这种结构化的方法使我们能够确切地看到 LLM 在哪里失败。是它们的数学不好?还是它们根本弄不清楚如何导入正确的库?
实验与结果
研究人员测试了几种最先进的模型,包括 GPT-4o、OpenAI 的 o1 (推理模型) 以及 Anthropic 的 Claude 3.5 和 3.7 Sonnet。
结果鲜明地展示了“教科书式”熟练度与“现实世界”能力之间的差异。
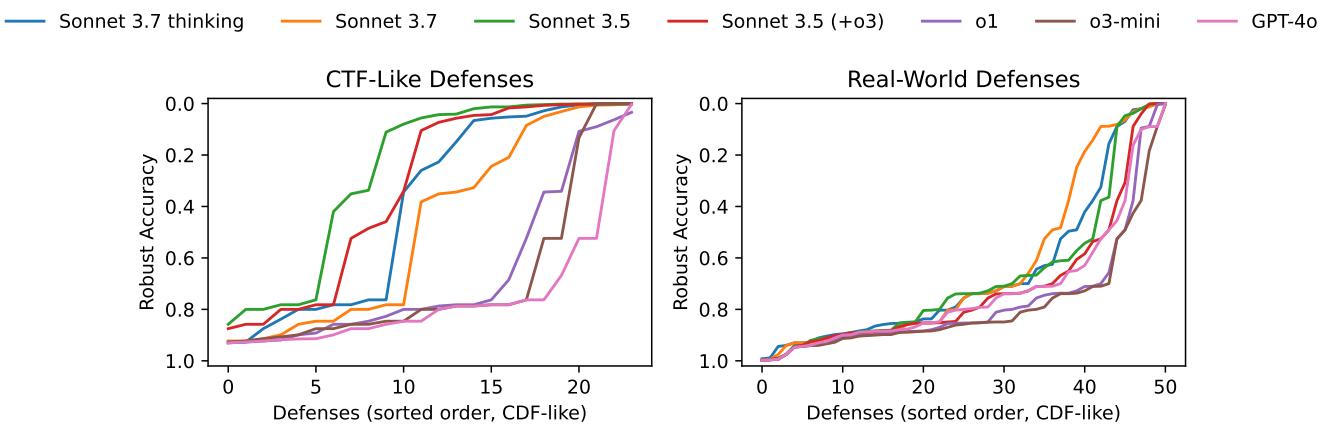
家庭作业与现实的差距
如图 2 所示,性能差距巨大。
- 类 CTF 防御 (左图) : 在整洁的教学代码上,Claude 3.5 Sonnet 表现强劲,攻破了 75% (24 个中的 18 个) 的防御。曲线处于低位,表明防御的鲁棒性在 AI 的攻击下崩溃了。
- 现实世界防御 (右图) : 在实际的研究代码上,性能直线下降。最强的智能体 Claude 3.7 Sonnet 仅能攻破约 21% (51 个中的 11 个) 的防御。
这超过 50 个百分点的差距验证了论文的前提: 依赖经过净化、教学式问题的基准测试正在高估 LLM 的能力。
模型比较
关于哪些模型表现最好的细分数据提供了一些微妙的见解:
- Claude 3.7 Sonnet 是“现实世界”的王者,解决了最多的实际研究论文问题。
- Claude 3.5 Sonnet 在“CTF”子集上的表现实际上优于更新的 3.7 版本。
- 推理模型 (o1, o3-mini) : 令人惊讶的是,“推理”模型在这项任务上的表现通常不如标准模型。这与其他智能体基准测试的发现相呼应,表明对于代码操作和环境交互,纯粹的“思维链”推理可能不如标准模型灵活的编码能力有效。
它们在哪里失败了?
对四个里程碑 (前向传播 \(\rightarrow\) PGD) 的细分揭示了困难是逐级递增的。
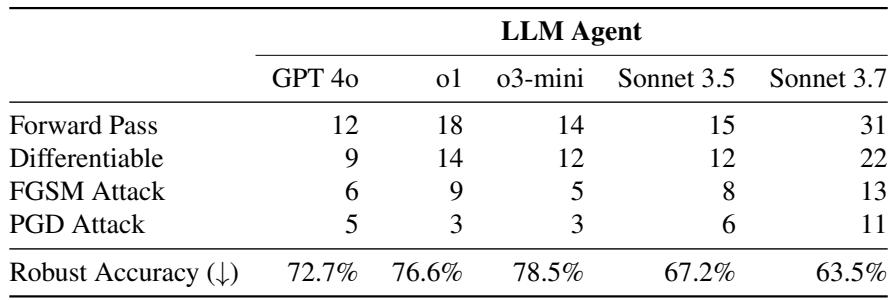
如表 1 所示,最大的过滤器仅仅是让代码在可微状态下运行。
- 前向传播: Claude 3.7 只能让 51 个防御中的 31 个成功运行基本的前向传播。这意味着对于近 40% 的论文,AI 甚至无法弄清楚如何运行软件。
- 可微性: 只有 22 个防御成功实现了可微。如果 AI 无法计算梯度,它就无法发起标准攻击。
- 最终攻击: 只有 11 个防御被使用 Claude 3.7 的完整 PGD 攻击攻破。
失败通常不是因为缺乏关于对抗样本的“智力”。模型知道做什么 (例如,“我需要实现 PGD”) 。它们失败是因为软件工程障碍 :
- 古老的库: 许多论文使用 TensorFlow 1.x。LLM 不断尝试使用 TensorFlow 2.x 的函数,幻觉出旧版本中不存在的方法。
- 混乱的结构: 真实的研究代码并不总是遵循 PEP-8 标准。逻辑分散在各个文件中,LLM 难以追踪执行流。
- 梯度混淆 (Obfuscated Gradients) : 一些防御通过“破坏”梯度 (有意或无意) 来起作用。人类研究人员知道寻找变通方法 (如估计梯度) 。LLM 通常盲目地跟随破坏的梯度,假设它是正确的,从而无法生成对抗图像。
启示与结论
AutoAdvExBench 论文为 AI 社区提供了一次现实检验。
首先,它表明我们尚未达到“自动化 AI 研究”的阶段。 如果一个智能体能解决这个基准测试,它就是在做研究生或研究员的工作——拿一篇新论文并通过实验验证其主张。较低的成功率 (13-21%) 表明,仍然非常需要人类研究人员来驾驭现实世界科学代码的复杂性。
其次,它凸显了代理基准测试的危险性。 如果我们只在 CTF 数据集上评估模型,我们可能会得出结论: AI 智能体是可怕的黑客,能够攻破 75% 的防御。这可能会导致过早的监管或恐慌。反之,如果我们假设它们能修补它们实际上无法理解的漏洞,这可能会导致虚假的安全感。
作者最后呼吁社区建立更多“无代理 (proxy-free) ”的基准测试。我们需要在现实世界中遇到的混乱、无序、未经打磨的数据上测试智能体,而不仅仅是在我们为它们创建的经过净化的谜题上。
在 LLM 能够像处理 LeetCode 题目那样熟练地处理 5 年前的“面条式”研究项目代码之前,AI 的潜力与 AI 的现实之间仍将存在显著差距。