](https://deep-paper.org/en/paper/2503.04094/images/cover.png)
人工智能已经征服了像国际象棋和围棋这样的完全信息博弈游戏。在这些领域,经过数百万次自我对弈训练的深度强化学习 (RL) 智能体占据了统治地位。然而,这些方法通常需要巨大的特定任务训练资源。
现在,大型语言模型 (LLM) 登场了。这些模型拥有海量的通用知识,但众所周知,它们在战略规划方面表现挣扎。如果你让一个标准的 LLM 去玩游戏,它经常会产生规则幻觉,或者无法进行前瞻性思考。
这引出了研究人员推出的一个新智能体——PokéChamp 。 它在无需对 LLM 进行额外训练的情况下,在宝可梦 (Pokémon) 对战中达到了专家级水平。PokéChamp 并没有将 LLM 视为一个独立的智能体,而是将其嵌入到一个经典的博弈论算法中: Minimax (极小化极大) 搜索。
通过将 GPT-4o 等模型的推理能力和通用知识与 Minimax 严谨的规划能力相结合,PokéChamp 在对抗最先进的机器人时取得了 76% 的胜率,并在竞争激烈的在线天梯中排名前 30%-10%。这篇文章将探讨研究人员如何构建该系统、其背后的架构,以及为何宝可梦对 AI 来说是一个如此困难的基准测试。
挑战: 为什么选择宝可梦?
要理解 PokéChamp 的重要性,我们首先需要了解竞技宝可梦的复杂性。与双方都能看到整个棋盘的国际象棋不同,宝可梦是一个部分可观测马尔可夫博弈 (POMG) 。
- 部分可观测性: 你知道自己的队伍,但在对手展示之前,你不知道他们的完整队伍、属性数据 (Stats) 、携带道具或招式配置。
- 随机性 (Stochasticity) : 招式有命中率检查 (可能会未命中) ,暴击或追加效果也是随机发生的。
- 状态空间: 可能的状态数量是天文数字。考虑到超过 1000 种宝可梦,结合道具、性格和努力值 (EVs) ,仅第一回合的估计状态空间就高达 \(10^{354}\)。
- 队伍构建 (Teambuilding) : 在战斗开始前,玩家必须组建一支由六只宝可梦组成的队伍,并为每个角色配置复杂的细节。
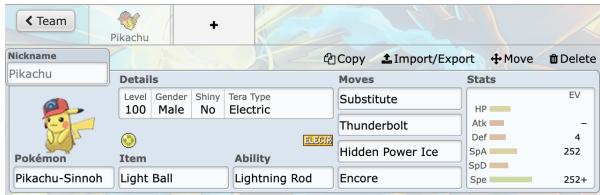
如图 3 所示,玩家必须配置每个队员的招式、特性、道具和属性数据。由于这种复杂性,穷举搜索算法 (如简单的国际象棋引擎所使用的) 在计算上是不可行的。你无法简单地计算每一个可能的未来结果。
核心方法: LLM 增强的 Minimax
研究人员的主要创新不是一种新的模型架构,而是一个新的框架 。 他们利用了 Minimax 树搜索——一种用于双人游戏的标准算法——但将其计算最昂贵和最困难的部分替换为了 LLM。
在传统的 Minimax 搜索中,智能体试图最大化其回报,同时假设对手试图最小化该回报。搜索会构建一棵包含未来可能回合的树。对于宝可梦来说,构建这棵树非常困难,因为分支因子 (每回合可能的动作数量) 巨大,而且我们不知道对手的隐藏信息。
PokéChamp 通过将 LLM 插入搜索过程的三个特定模块来解决这个问题:
- 玩家动作采样 (Player Action Sampling) : 通过仅建议“好”的动作来修剪树。
- 对手建模 (Opponent Modeling) : 预测敌人可能会做什么。
- 价值函数估计 (Value Function Estimation) : 在不将游戏进行到底的情况下评估谁处于优势。
让我们分解一下这个架构。
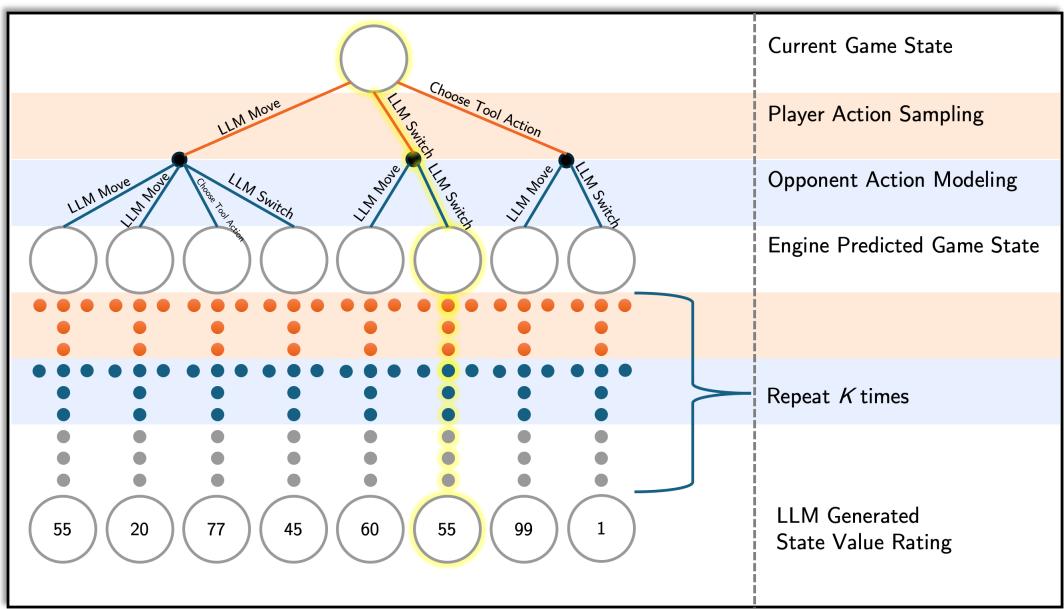
1. 玩家动作采样
在一个典型的回合中,玩家的每只在场宝可梦可能有 4 个招式和 5 个潜在的替换选择,也就是 9 个基本选项。然而,考虑到游戏的细微差别 (如太晶化 Terastallization) ,选项会成倍增加。
PokéChamp 没有模拟每一个选项,而是向 LLM 提供当前的战斗状态,并要求它采样一小部分可行的动作。这充当了一种启发式剪枝机制。LLM 利用其预训练的宝可梦策略知识来丢弃明显糟糕的动作 (比如对水属性使用火属性招式) ,并将树搜索集中在具有战略意义的候选动作上。
为了辅助 LLM,系统向其输入了一个 “近似状态转移启发式” 。 这是一个计算好的“单步前瞻 (one-step lookahead) ”,用于计算即时伤害和击倒潜力。
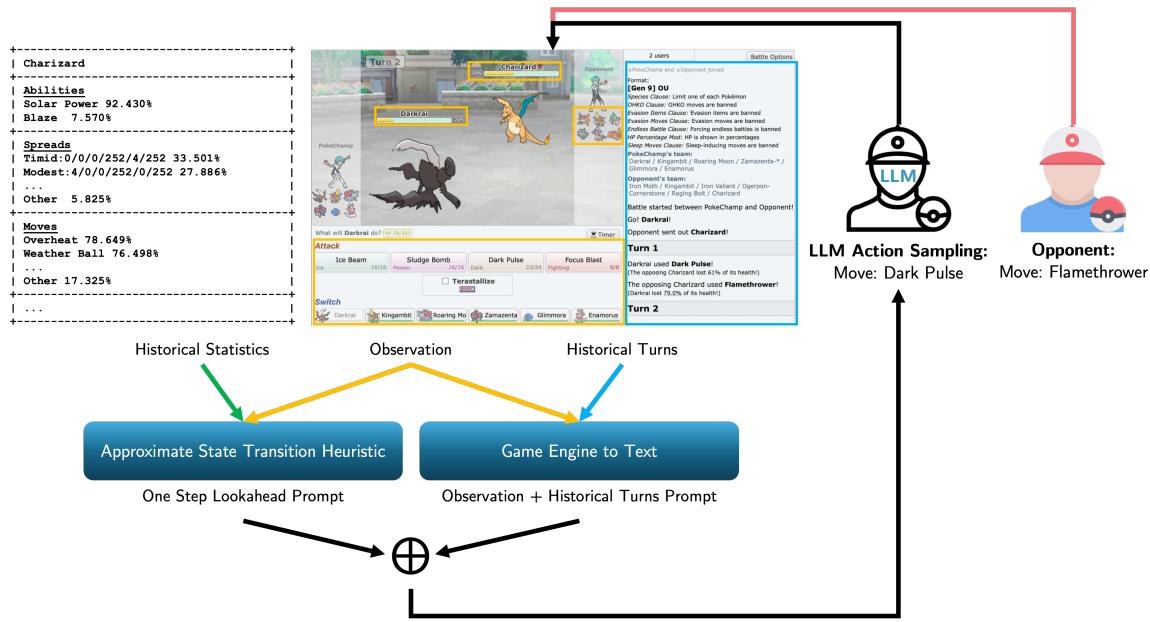
如图 2 所示,LLM 接收历史统计数据 (这只宝可梦通常使用什么招式) 和当前的观察结果。然后,它输出最合乎逻辑的动作来填充搜索树。
2. 对手建模
这是 POMG 中最具挑战性的方面。为了有效地进行规划,你必须预测对手会做什么,即使你不知道确切的属性数据或招式。
PokéChamp 通过结合历史数据和 LLM 直觉来解决这个问题。
- 属性估算: 系统使用包含 300 万场真实玩家对局的庞大数据集来估算对手宝可梦的可能属性 (攻击、防御、速度) 。
- 动作预测: LLM 被提示扮演对手的角色。给定对手视角的博弈状态,LLM 预测他们可能的反击或换人。
这使得 Minimax 树能够基于可能的对手行为进行分支,而不是基于随机猜测或数学上可能但战略上不太可能的最坏情况。
3. 价值函数估计
由于宝可梦对战可能持续数十个回合,在时间限制内 (通常每位玩家总共 150 秒) 搜索整棵树直到结束 (游戏结束) 是不可能的。
搜索必须在特定深度 (\(K\)) 停止。在这个叶节点,智能体需要知道: 这个状态对我有利吗?
传统上,这需要一个手工制作的评估函数 (例如,计算剩余 HP) 。PokéChamp 用 LLM 取代了这一点。模型被要求基于以下因素评估棋盘状态:
- 剩余的属性克制关系。
- 速度优势。
- 获胜概率。
- 负面因素 (异常状态、关键宝可梦的损失) 。
LLM 输出一个分数,有效地作为修改后的 Minimax 方程中的启发式价值函数 \(V(x_{h+k})\):
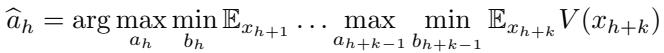
世界模型: 近似现实
为了让任何搜索算法发挥作用,智能体需要知道游戏规则——即世界的物理规律。如果我使用“十万伏特 (Thunderbolt) ”,会造成多少伤害?
PokéChamp 利用一个世界模型 (World Model) 来近似游戏状态转移。由于对手的确切状态是隐藏的,系统使用标准伤害公式结合从历史数据推导出的估计属性来计算期望伤害。
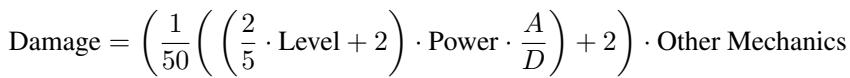
通过将估计变量 (如攻击 \(A\) 和防御 \(D\)) 代入方程 2,系统模拟回合的结果。为了处理随机元素 (如命中率为 85% 的招式) ,系统计算期望值,而不是模拟每一个概率分支,从而使计算成本保持在可控范围内。
实验结果
研究人员在 Pokémon Showdown 上流行的第九世代 OU (OverUsed) 分级中评估了 PokéChamp。这是熟练人类玩家的标准竞技格式。
对抗机器人
PokéChamp 与以下对象进行了对战:
- PokéLLMon: 之前最先进的基于 LLM 的智能体。
- Abyssal: 一个高水平的启发式 (基于规则) 机器人。
- 基准: 随机 (Random) 和最大威力 (Max-Power) 机器人。
结果是决定性的。当由 GPT-4o 驱动时,PokéChamp 对抗启发式机器人 Abyssal 取得了 84% 的胜率 , 对抗 PokéLLMon 取得了 76% 的胜率 。
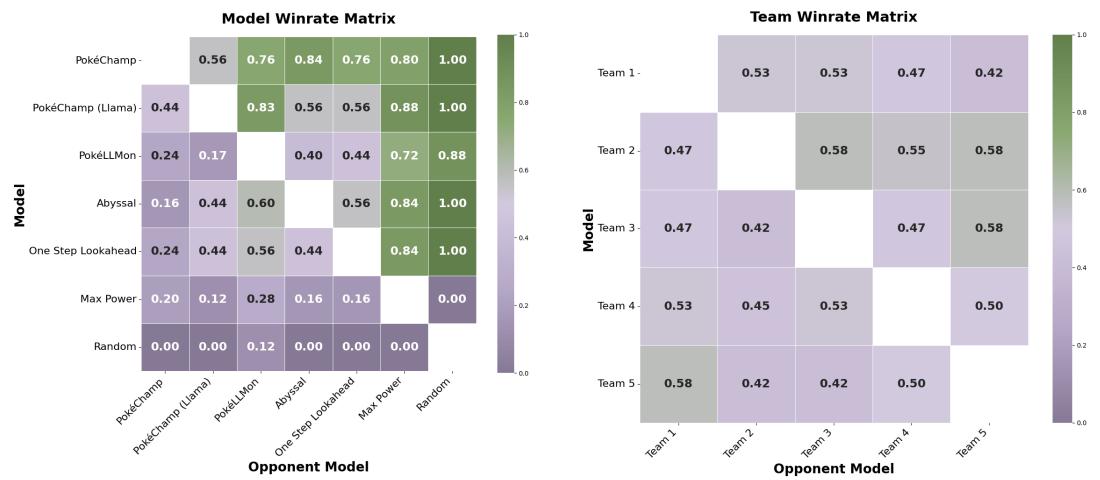
图 7 (左) 展示了成对胜率。在对抗“PokéLLMon”一栏中 0.76 的得分表明了明显的优势。也许更令人印象深刻的是,使用较小的开源 Llama 3.1 (8B) 模型的 PokéChamp 对抗 (使用 GPT-4o 的) PokéLLMon 也取得了 64% 的胜率,这证明了 Minimax 框架对性能的贡献显著,独立于模型规模。
对抗人类
游戏 AI 的终极测试是在线天梯。研究人员在 Pokémon Showdown 天梯上匿名部署了 PokéChamp。
该智能体实现了 1300-1500 的预计 Elo 等级分。虽然 Elo 数值因游戏而异,但在该特定天梯上,此评级将智能体置于人类玩家的前 30% 到 10% 之间。
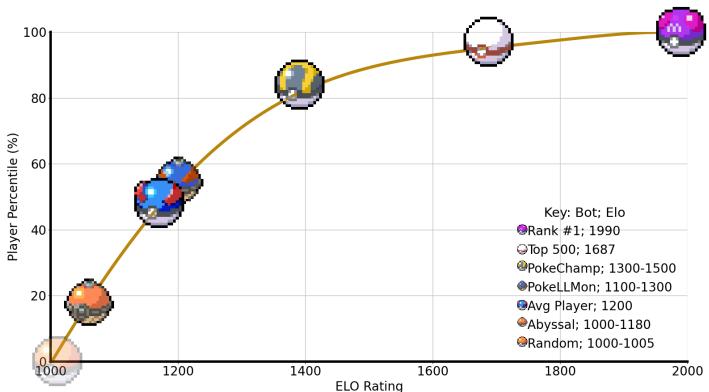
如图 1 所示,金色精灵球代表 PokéChamp。它在曲线上的位置明显高于普通玩家和之前的 LLM 方法 (蓝色球) ,接近精英人类玩家的领域。
处理复杂机制
对以前的语言智能体的一个批评是,它们无法利用特定世代的机制,如太晶化 (Terastallization) (战斗中改变宝可梦的属性) 或极巨化 (Dynamax) 。
基准测试表明,PokéChamp 能正确识别何时使用这些机制将劣势对局转变为优势对局。
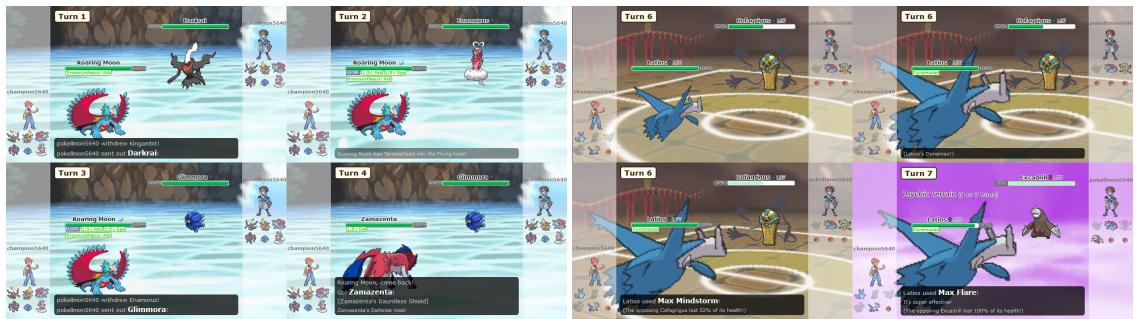
在图 6 (左) 中,PokéChamp 识别出其宝可梦 (轰鸣月 Roaring Moon) 对对手处于弱势。它触发太晶化改变其防御属性,从而抗下了攻击。这种战术意识凸显了 Minimax 框架提供的前瞻搜索的好处。
随机对战中的鲁棒性
团队还在“随机对战 (Random Battles) ”中测试了该智能体,这是一种每场比赛队伍都随机生成的格式。这测试的是适应性而非预先规划。
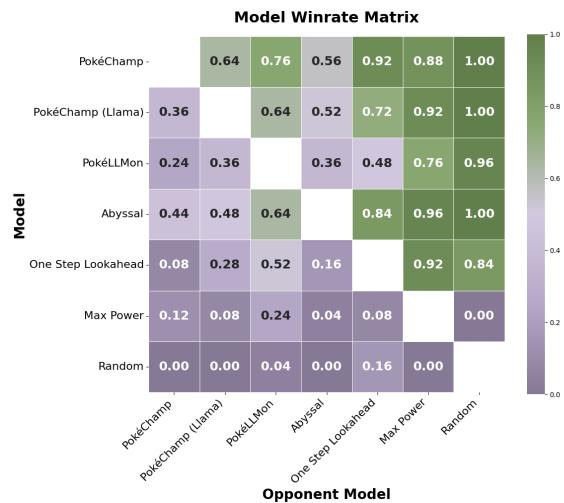
即使在这个混乱的环境中,PokéChamp (GPT-4o) 对抗启发式机器人仍保持了 70% 的胜率。图 9 中的对局矩阵可视化了智能体在面对不同对手时的一致性。
局限性: 它在哪里失败了?
尽管取得了成功,PokéChamp 并非不可战胜。研究人员确定了人类玩家用来利用 AI 弱点的两种特定策略:
- 受队策略 (Stall Strategies) : “受队”专注于极致的防御和被动伤害。由于 PokéChamp 的前瞻深度有限 (受时间限制) ,它经常无法预见慢性死亡的长期危险。它倾向于过度换人,试图找到并不存在的即时优势。
- 过度轮转 (Excessive Switching) : 专家级人类可以通过不断更换角色来操纵 AI。如果 AI 基于当前宝可梦预测了一个招式,但对手立即换上了联防宠,AI 的招式可能会失败。
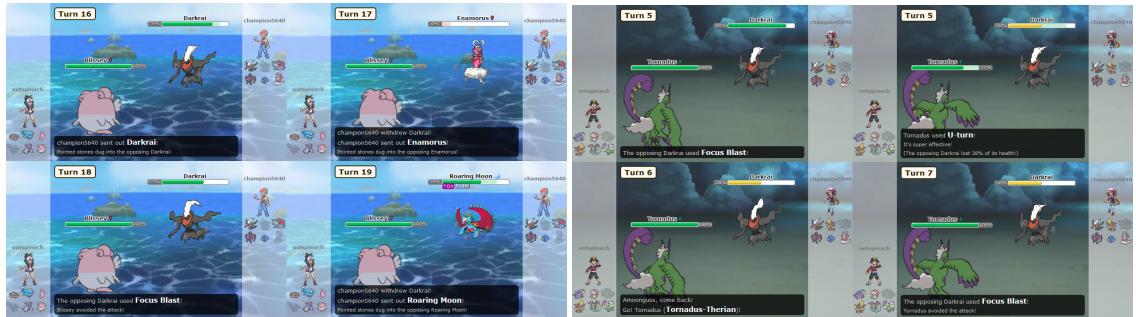
图 8 展示了这些失败案例。在左侧,PokéChamp 在循环中不断更换宝可梦,每次都受到钉子伤害,无法制定突破防御性“受队”高墙的策略。
结论与启示
PokéChamp 展示了我们将大型语言模型应用于复杂任务的方式发生了关键转变。研究人员没有训练模型去“成为”玩家,而是将 LLM 作为一个复杂的推理引擎使用在经典的规划算法内部。
关键要点是:
- 无需训练: 系统使用现成的模型 (GPT-4o, Llama 3) 。
- 即插即用的推理: LLM 取代了 Minimax 中难以编码的启发式部分 (评估和对手建模) 。
- 专家级表现: 它在部分可观测环境中与顶尖人类玩家竞争。
这种方法表明,游戏 AI——或许也是通用决策 AI——的未来可能不仅仅在于更大的模型或更多的强化学习,还在于将 LLM 更好地架构集成到经过验证的算法框架中。通过用树搜索的严格逻辑约束 LLM 的广博知识,PokéChamp 最小化了幻觉并最大化了战略深度。