](https://deep-paper.org/en/paper/2503.07067/images/cover.png)
追求更大、更强的大型语言模型 (LLMs) 的竞赛一直是头条新闻,但在效率领域,一场平行的革命正在发生。部署像 GPT-4 或 Llama-3-70B 这样的庞大模型不仅计算成本高昂,而且速度缓慢。这推动了知识蒸馏 (Knowledge Distillation, KD) 的需求——即把庞大的“教师”模型的智能压缩到一个更小、更快的“学生”模型中的过程。
虽然 KD 行之有效,但标准方法通常将所有训练数据一视同仁,无论这些数据是来自天才的教师还是正在学习的学生。这种缺乏细微差别的方式导致了压缩效果并不理想。
在这篇文章中,我们将深入探讨 DISTILLM-2 , 这是一篇引入“对比”蒸馏方法的新研究论文。通过在数学上将损失函数与正在处理的具体数据类型 (教师输出与学生输出) 相结合,研究人员在指令遵循、代码生成和数学任务上都取得了最先进的结果。
对称蒸馏的问题
为了理解为什么需要 DISTILLM-2,我们首先需要看看 LLM 蒸馏通常是如何工作的。其目标是最小化教师的概率分布 (\(p\)) 与学生的概率分布 (\(q_\theta\)) 之间的差异。
最常用的工具是 Kullback-Leibler (KL) 散度,通常在词元 (token) 级别进行计算:
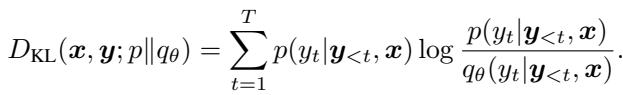
这里的损失衡量了学生偏离教师的程度。标准方法通常使用前向 KL (Forward KL) (匹配教师的高概率区域) 或反向 KL (Reverse KL) (迫使学生避开低概率区域) 。
然而,现有的方法存在一个盲点: 它们通常对教师生成的输出 (TGOs) 和学生生成的输出 (SGOs) 应用相同的损失函数。
- TGOs 是高质量的“基准真值”序列。
- SGOs 是学生生成的探索性序列,可能包含错误或幻觉。
对称地对待这两种截然不同的数据源忽略了它们内在的差异。DISTILLM-2 的作者认为,为了最大化性能,我们需要在损失公式和数据类型之间建立协同作用。
背景: 偏斜方法 (Skewed Approach)
DISTILLM-2 建立在一种名为 DistiLLM 的先前方法之上,该方法引入了偏斜 KL (Skew KL, SKL) 和偏斜反向 KL (Skew Reverse KL, SRKL) 的概念。
标准 KL 散度存在“模式平均” (产生通用的、安全的回复) 或“模式坍塌” (卡在某种特定回复上) 的问题。为了解决这个问题,偏斜 KL 使用混合系数 \(\alpha\) 混合了教师和学生的分布。
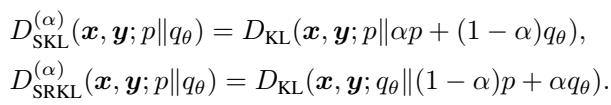
通过在分布之间进行插值 (例如,\(\alpha p + (1-\alpha)q_\theta\)) ,训练变得更加平滑,避免了标准 KL 的极端情况。DISTILLM-2 采用这些偏斜目标作为其数学支柱,但从根本上改变了应用的方式和时机。
核心方法: 对比蒸馏
DISTILLM-2 的核心是面向 LLM 蒸馏的对比方法 (Contrastive Approach for LLM Distillation, CALD) 。 其直觉类似于强化学习中使用的直接偏好优化 (DPO) : 我们希望增加“好”回复的可能性,并降低“坏”回复的可能性。
在蒸馏的背景下:
- 教师回复 (\(y_t\)) : 代表理想的行为。我们要 “拉升” 学生对这些内容的概率。
- 学生回复 (\(y_s\)) : 通常包含偏差或错误。我们要 “压低” 学生对这些内容的概率 (特别是当学生很自信但教师不自信时) 。
为什么不直接用 DPO?
你可能会问,为什么不直接将教师视为“赢家”,将学生视为“输家”来应用 DPO 呢?研究人员发现,盲目地将 DPO 应用于蒸馏 (他们称这种方法为 DPKD) 会导致奖励破解 (reward hacking) 。
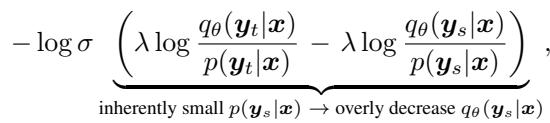
如上所示,由于教师对学生错误回复的概率 (\(p(y_s|x)\)) 本来就很小,损失函数会产生巨大的梯度,过度惩罚学生。这不仅没有优化模型,反而破坏了学生的语言能力。
CALD 解决方案
DISTILLM-2 通过为特定数据类型分配特定的损失函数来解决这个问题。它使用 SKL 处理教师输出 (学习“正确”的分布) ,使用 SRKL 处理学生输出 (纠正“不正确”的分布) 。
最终的损失函数是这两个目标的平衡总和:
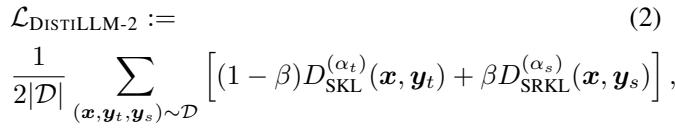
在这里,\(\beta\) 控制了向教师学习 (SKL) 和自我纠正 (SRKL) 之间的平衡。
动态可视化
为了理解为什么这种分离至关重要,请看下图中 KL 和反向 KL (RKL) 的行为。
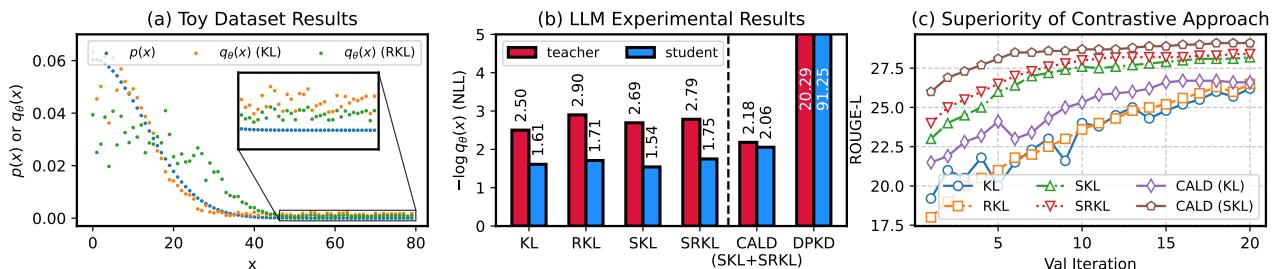
- 图 (a): 注意 KL (橙色) 在分布峰值处的“拉升”效应——它鼓励学生匹配教师的高置信度。相反,RKL (绿色) 在尾部有“压低”效应——它惩罚学生对教师认为不太可能发生的事情分配概率。
- 图 (b): 此条形图显示了负对数似然 (NLL) 。提出的 CALD 方法 (绿色/橙色分离) 实现了健康的平衡。对比最右侧的 DPKD,学生的 NLL 激增至 91.25,表明模型已被目标函数破坏。
- 图 (c): SKL 和 SRKL 的结合 (CALD-SKL) 比单独使用标准 KL 或 SKL 收敛得更快,并达到了更高的 ROUGE-L 分数。
优化数据与课程
拥有一个新的损失函数固然很好,但 DISTILLM-2 更进一步,优化了进入该函数的数据内容以及训练随时间的演变方式。
1. 数据筛选: 谁生成什么?
研究人员提出了一个关键问题: 我们是否应该用更好的回复 (例如来自 GPT-4) 替换教师的输出,或者使用“投机解码 (speculative decoding) ”来混合分布?
令人惊讶的是,答案是否定的。
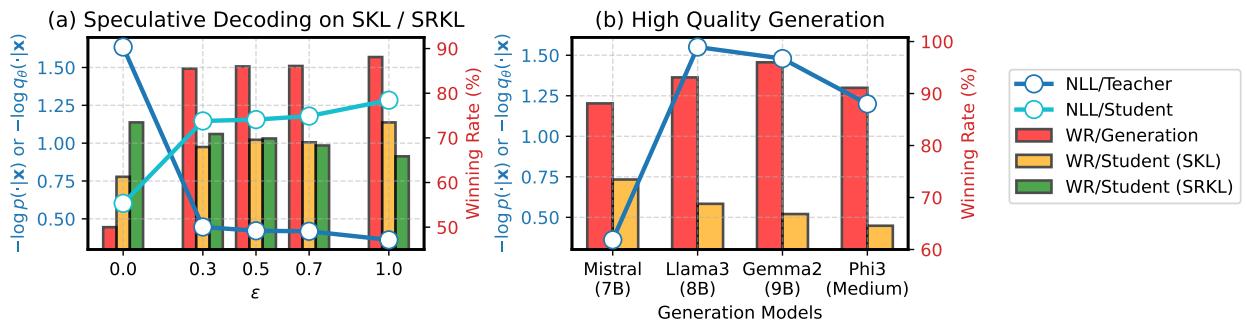
- 图 2(a): 与在 SKL 项中使用纯教师输出相比 (橙色条) ,使用投机解码 (混合学生和教师的 token) 实际上损害了性能。
- 图 2(b): 即使是用更强的模型替换教师的输出 (例如用 Llama-3 教 Mistral 学生) ,也不能保证更好的蒸馏效果。
结论: SKL 项的有效性依赖于教师模型本身分配的高概率。目标是匹配教师的分布,而不一定是生成世界上“最好”的文本。因此,DISTILLM-2 使用教师输出进行 SKL , 使用学生输出进行 SRKL 。
2. 课程学习
偏斜 KL 中的混合系数 \(\alpha\) 很难调整。如果 \(\alpha\) 太高,学生学得太慢。如果太低,训练就会变得不稳定。
DISTILLM-2 引入了自适应课程 。 它根据样本的“难度” (教师和学生概率之间的差距) 为每个样本计算动态的 \(\alpha\)。
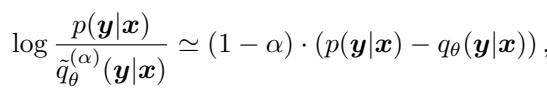
利用一阶泰勒展开 (墨卡托级数) ,作者推导出了 \(\alpha\) 的闭式更新公式。这允许模型自动调整损失函数的“偏斜度”。当学生和教师相距甚远 (困难样本) 时,\(\alpha\) 增加以稳定训练。当它们接近时 (简单样本) ,\(\alpha\) 减小以加速学习。
此外,参数 \(\beta\) (用于加权学生生成的惩罚项) 在训练期间线性增加。这意味着模型在早期专注于模仿,在后期专注于自我纠正。
实验结果
这种对比理论能转化为现实世界的性能吗?结果表明是非常肯定的。
指令遵循
作者使用“以 LLM 为裁判” (GPT-4) 在 AlpacaEval 和 UltraFeedback 等基准上评估了 DISTILLM-2。
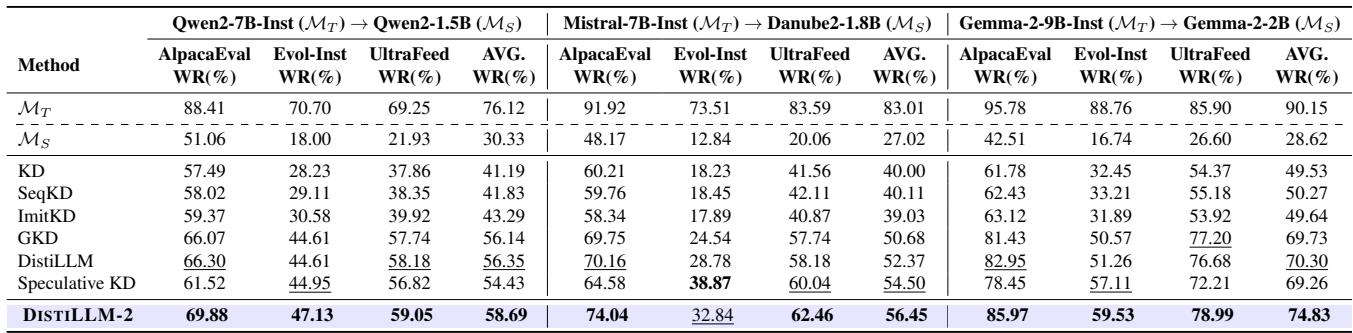
DISTILLM-2 始终优于其他蒸馏方法 (如 GKD、ImitKD 和标准 DistiLLM) 。例如,在 Gemma-2 模型上,它在 AlpacaEval 上实现了 85.97% 的胜率,显著高于之前的最先进水平。
数学和代码生成
对于小型模型来说,特定领域的任务通常很难。
- 数学 (GSM8K & MATH): DISTILLM-2 帮助 1.5B 参数的学生模型在 MATH 基准测试中超越了其自身的 7B 教师模型 (平均 62.07% vs 67.07%,但在特定指标上击败了教师) 。
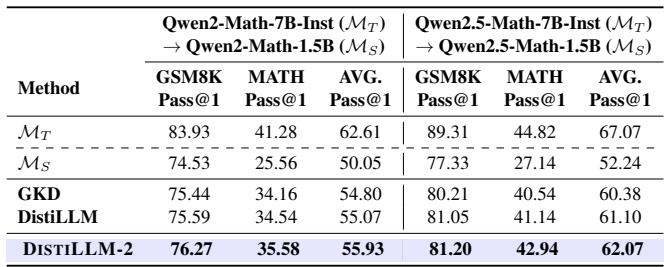
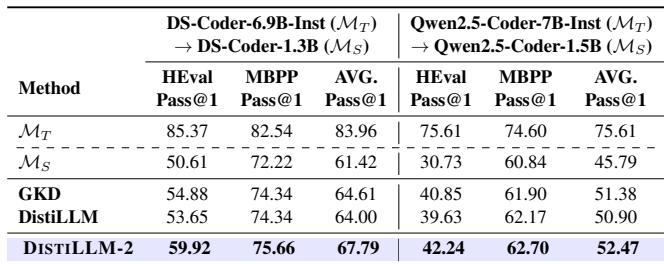
- 代码 (HumanEval & MBPP): 在编码任务中,该方法显示出明显优于 GKD 和原始 DistiLLM 的优势。
组件分析
这种复杂性值得吗?一项消融研究证实,拼图的每一块都对最终得分做出了贡献。
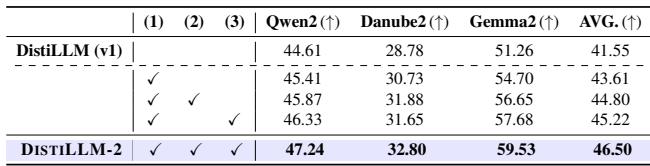
- 第 1 行: 基础 DistiLLM。
- 第 2 行: 加入对比损失带来了提升。
- 第 3 行: 加入动态 \(\beta\) 调度进一步提供了帮助。
- 第 4 行: 加入自适应 \(\alpha\) 课程产生了最终的 DISTILLM-2 性能。
更广泛的应用
该论文证明,DISTILLM-2 不仅仅适用于标准文本生成。它在 AI 的其他领域也有广泛的应用。
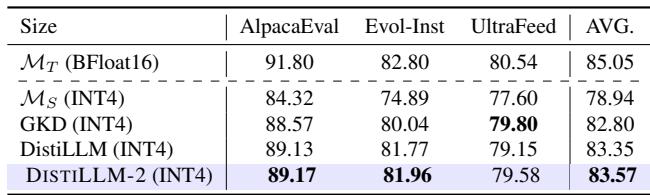
1. 偏好对齐: 在运行基于人类反馈的强化学习 (RLHF) 之前,模型通常会经过监督微调 (SFT) 。用 DISTILLM-2 替换 SFT 可以创建一个更好的起点 (参考模型) ,从而获得更好的最终对齐分数。
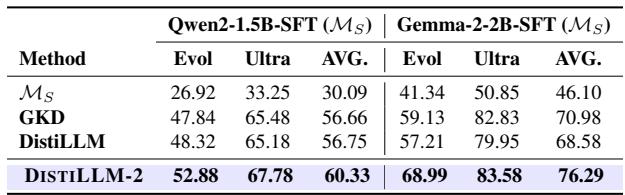
2. 视觉语言模型 (VLMs) : 该方法跨模态有效。当将大型 VLM (LLaVA-1.5-7B) 蒸馏为较小的 VLM 时,与其他方法相比,DISTILLM-2 在视觉问答基准测试中实现了更高的准确率。
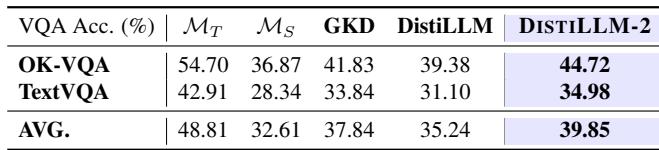
3. 拯救量化模型: 量化 (将模型精度降低到 4-bit) 可以节省内存但会损害性能。DISTILLM-2 有助于“治愈”这些量化模型,比标准微调更有效地恢复丢失的准确率。
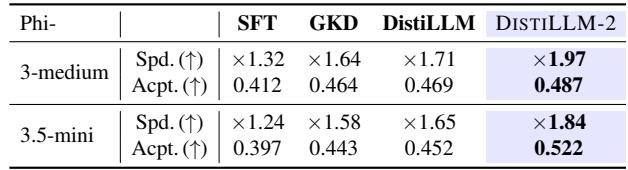
4. 更快的推理 (投机解码) : 投机解码使用微型“草稿”模型来猜测大型模型要验证的 token。更好的草稿模型意味着更多被接受的 token 和更高的速度。使用 DISTILLM-2 训练的草稿模型产生了最高的加速比 (高达 1.97 倍) 。
结论
DISTILLM-2 代表了知识蒸馏向前迈出的成熟一步。它不再将师生关系视为简单的模仿游戏,而是承认了学习过程的不对称性。
通过对教师数据应用偏斜 KL (拉升学生能力) 和对学生数据应用偏斜反向 KL (压低错误) ,并利用自适应课程管理这种相互作用,DISTILLM-2 使得小型模型的表现远超其参数规模的限制。
随着 AI 部署向移动设备和边缘计算转移,像 DISTILLM-2 这样的技术对于弥合前沿模型的巨大智慧与现实世界的实际限制之间的差距将至关重要。