](https://deep-paper.org/en/paper/2503.17061/images/cover.png)
想象一下,一架智能无人机被部署去监控一个偏远的野生动物保护区。最初,它被训练来识别鹰和鹿。但有一天,一种新物种——狐狸——进入了该区域。为了让无人机保持实用价值,它必须在不遗忘鹰和鹿长相的情况下学习识别这种新动物。这种能够顺序学习而不丢失以往知识的能力被称为 持续学习 (Continual Learning, CL) 。
对于人工智能系统来说,这是一个出乎意料的难题。当标准神经网络学习新任务时,它往往会覆盖旧知识——这种现象被称为 灾难性遗忘 (catastrophic forgetting, CF) 。 如图 1 所示,随着模型在新任务上的准确率显著提升,它在旧任务上的表现却急剧下降。
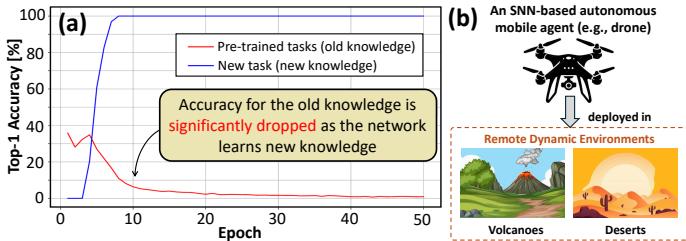
图 1. (a) 图展示了灾难性遗忘: 模型在学习新任务 (蓝线) 时,旧任务的准确率 (红线) 急剧下降。(b) 图展示了目标应用: 一架需要在偏远环境中进行高效持续学习的自主无人机。
用旧数据和新数据从零重新训练整个模型是一种“暴力”解决方案,但对于嵌入式或资源受限的系统来说不可行。它需要大量时间、能量,并要求访问完整的数据集,而这通常受限于存储或隐私问题。对于运行在边缘侧的小型电池供电设备,如无人机或机器人而言,这尤为棘手。
此时, 脉冲神经网络 (Spiking Neural Networks, SNNs) 登场。受人脑启发,SNN 通过离散且高能效的“脉冲”进行通信,非常适合低功耗系统。在 SNN 中实现持续学习的研究,构成了一个名为 神经形态持续学习 (Neuromorphic Continual Learning, NCL) 的新兴方向。
近期的研究《Replay4NCL: 一种用于嵌入式 AI 系统中神经形态持续学习的高效记忆回放方法》正面应对了这一挑战。作者提出了 Replay4NCL , 这是一种创新的技术,不仅能防止灾难性遗忘,而且效率卓越,为自适应边缘 AI 开启了新篇章。
AI “记忆”的难题
对抗灾难性遗忘的一个被证实有效的策略是 记忆回放 (memory replay) 。 核心思想是: 在 AI 学习新信息的同时,周期性地“回放”旧任务的压缩表示,从而巩固过去的知识,防止其被覆盖。
当前 SNN 领域的先进方法 SpikingLR 采用了这样的记忆回放机制。然而,它并不适用于嵌入式应用——速度慢且耗电量高。为了保持高准确率,SpikingLR 依赖于长时间处理周期称为“时间步 (timesteps)”,类似于慢动作视频的帧。更多的时间步意味着更多的计算,从而带来更高的延迟和能耗。
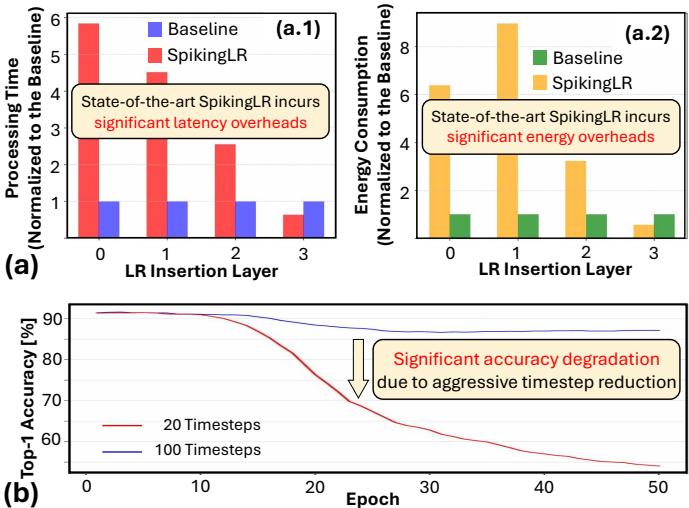
图 2. (a) 图显示,现有最优的 SpikingLR 方法带来了显著的延迟和能耗开销。(b) 图表明,仅将时间步从 100 减少到 20 就会造成严重的准确率下降。
如上所示,SpikingLR 引入了沉重的计算负担。简单地减少时间步将导致信息损失和性能下降。因此,Replay4NCL 针对一个关键问题展开研究: 如何在不牺牲准确率的前提下,让记忆回放足够高效以适应嵌入式 AI?
快速入门: 脉冲神经网络及其学习机制
脉冲神经网络 (SNNs)
与处理连续信号的传统神经网络不同,SNN 处理的是离散事件——脉冲 (spikes) , 类似于生物神经元。神经元的内部状态称为 膜电位 (\(V_{mem}\)),在接收脉冲时会上升。一旦超过阈值 (\(V_{thr}\)),神经元就会发出脉冲并重置。
这种行为可由 Leaky Integrate-and-Fire (LIF) 模型描述:
\[ \tau \frac{dV_{mem}(t)}{dt} = -(V_{mem}(t) - V_{rst}) + Z(t) \]其中,\(V_{rst}\) 是重置电位,\(Z(t)\) 表示输入,\(\tau\) 控制电位的衰减速率。
当 \(V_{mem} \ge V_{thr}\) 时,神经元发放脉冲并重置电位:
\[ V_{mem} \leftarrow V_{rst} \]这种事件驱动的计算方式实现了稀疏且高效的处理,非常适合嵌入式系统。
使用代理梯度训练 SNNs
训练 SNNs 并不容易,因为“脉冲”激活函数不可微,使得标准的反向传播无法直接进行。 代理梯度 (Surrogate Gradient, SG) 学习的出现带来了突破,它在训练时用平滑、可微的曲线替代不可微的阶跃函数,使梯度能正确传递。
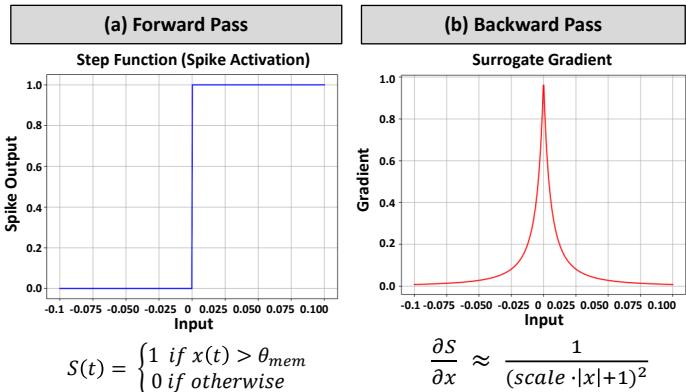
图 5. 前向传播 (a) 使用不可微的阶跃函数进行脉冲激活。在训练期间,平滑的“代理梯度” (b) 使基于梯度的优化成为可能。
通过这种方法,梯度可以跨越脉冲激活层传播,从而实现强大的监督式 SNN 训练。
Replay4NCL 方法论: 三步实现高效学习
Replay4NCL 方法引入了三项核心创新,如图 4 所示。它们协同作用,在保持学习质量的同时显著降低延迟和能耗。

图 4. Replay4NCL 流程包括三个协同步骤: 时间步优化、参数调整和数据注入策略设计。
让我们分别解析这三步。
步骤 1: 时间步优化
降低延迟和能耗的最直接手段是减少时间步。然而,如图 2 所示,过度削减会严重损害准确率。目标是找到一个既快速又精确的平衡。
研究人员通过实验探索时间步、准确率和处理时间之间的权衡。
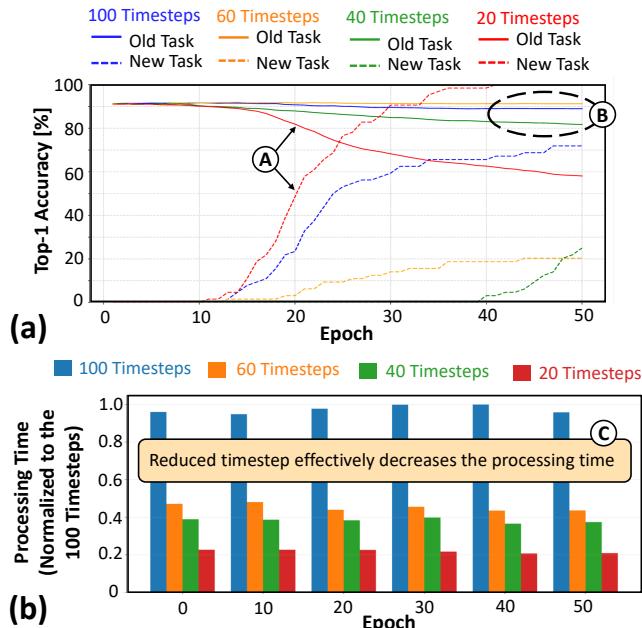
图 8. (a) 将时间步从 100 减少到 20 会明显降低准确率,而 40 个时间步则达到了良好折衷。(b) 时间步越少,处理时间越短。
结果表明, 40 个时间步既能保持高准确率,又能大幅降低处理时间——是嵌入式系统的理想选择。
更少的时间步意味着更小的 潜在回放 数据 (旧任务神经元状态快照) 。为了进一步提高存储效率,Replay4NCL 使用了简单的压缩–解压机制。
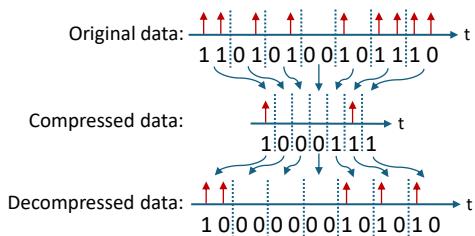
图 7. 无损压缩与解压机制可高效地存储和检索潜在回放数据。
时间步优化和压缩机制共同显著降低了延迟与内存占用。
步骤 2: 参数调整
随着时间步减少,神经元发放的脉冲也会减少,导致信息流受限,从而影响学习。Replay4NCL 通过调整两个关键参数来应对:
- 神经元阈值电位 (\(V_{thr}\)) ——略微降低,使神经元在输入减少时仍易于发放脉冲。
- 学习率 (\(\eta\)) ——适度减小,使在信息稀疏的情况下权重更新更平稳。
这种调整确保脉冲活动与预训练模型保持一致,从而顺利适应低时间步学习模式。
步骤 3: 数据注入策略设计
最后一步是确定在何处以及如何注入潜在回放 (Latent Replay, LR) 数据。SNN 架构如图 6 所示,其层被划分为 冻结层 (保持不变) 和 学习层 (更新) 。LR 数据被注入在这两类层的交界处。
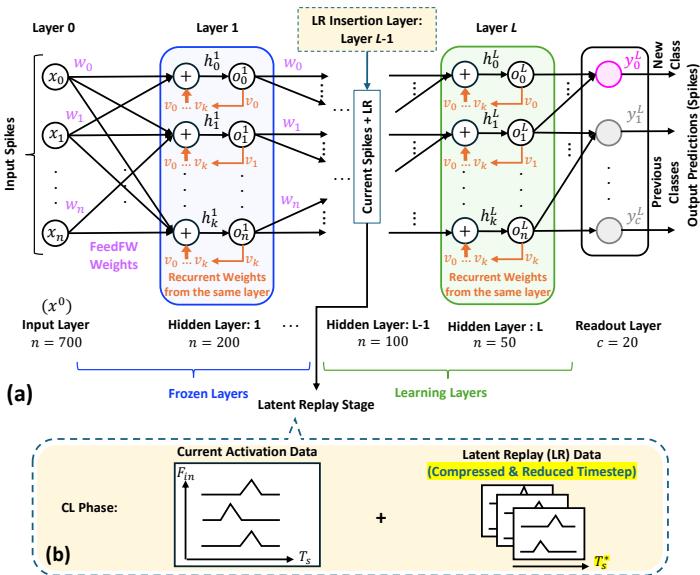
图 6. SNN 被划分为冻结层与学习层。潜在回放数据在关键层注入,以巩固旧任务。
Replay4NCL 动态地探索不同的注入层,并引入 阈值自适应机制 。 在训练过程中,神经元阈值 (\(V_{thr}\)) 会根据脉冲时序平滑上升或下降以维持平衡。与降低的学习率结合,这种机制确保在新旧任务间实现稳健、稳定的学习。
实际训练过程分为三个阶段:
- 预训练: 学习初始任务并形成稳定权重。
- 准备阶段: 使用优化的时间步与自适应阈值生成压缩的回放数据。
- 持续学习: 使用新数据与回放数据训练新任务,并结合动态阈值与降低学习率实现稳定学习。
测试 Replay4NCL: SHD 基准
作者在 Spiking Heidelberg Digits (SHD) 数据集上评估了 Replay4NCL——这是一个神经形态音频信号的常用基准。实验设置 (图 9) 基于 Python 实现,并运行在 Nvidia RTX 4090 Ti GPU 上。
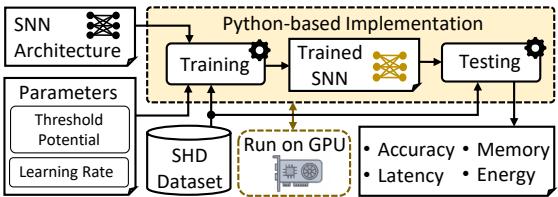
图 9. 基于 Python 的评估流程,使用 GPU 加速与 SHD 数据集进行准确率、内存、延迟和能耗测试。
测试场景模拟了增量学习: 先在 19 个声音类别上训练,再在不遗忘前 19 个类别的情况下学习第 20 个类别。
结果: 更快、更轻、更智能
准确率: 毫不妥协
Replay4NCL 的准确率与当前最优的 SpikingLR 相当,甚至略有超越。
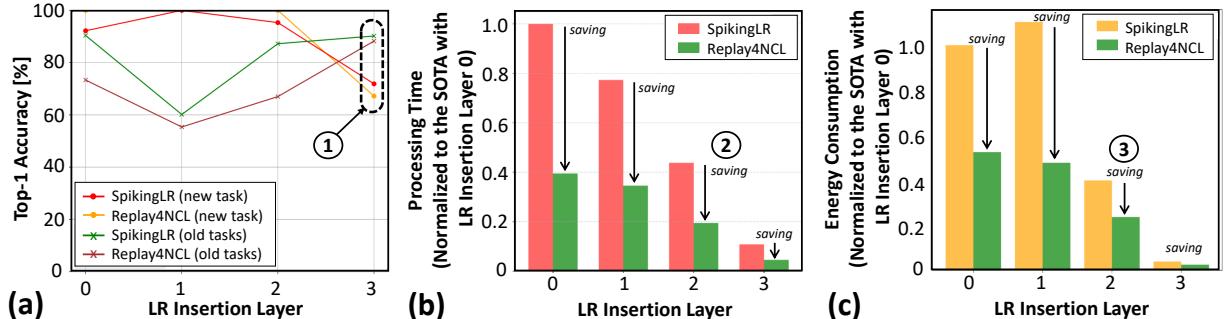
图 10. (a) Replay4NCL (绿色) 在准确率上持平或超越 SpikingLR (红色/橙色),同时 (b) 显著降低延迟并 (c) 大幅节省能耗。
在最佳配置 (LR 注入层为 3) 时,Replay4NCL 在旧任务上保持更高准确率,如下所示。
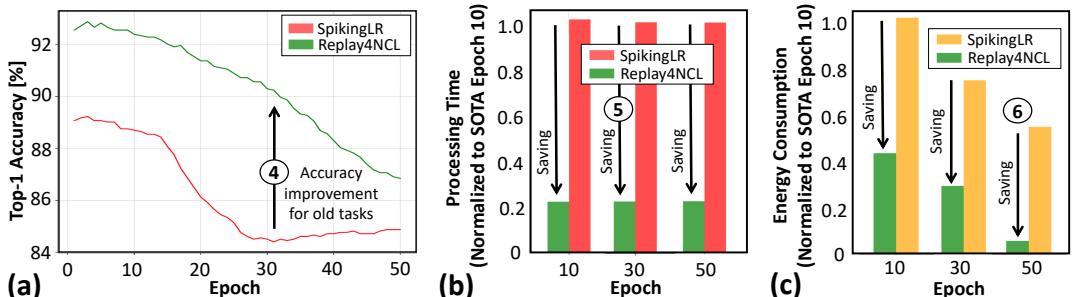
图 11. 在 LR 注入层为 3 的情况下,Replay4NCL 在旧任务 (a) 上准确率更高,且在各训练周期中 (b) 更快、(c) 更节能。
延迟、内存和能耗: 显著改进
Replay4NCL 的时间步优化带来了卓越性能:
- 处理延迟提升 4.88×
- 回放数据存储内存节省约 20%
- 能耗降低 36.43%
这些改进使其成为实时和节能系统的理想选择。
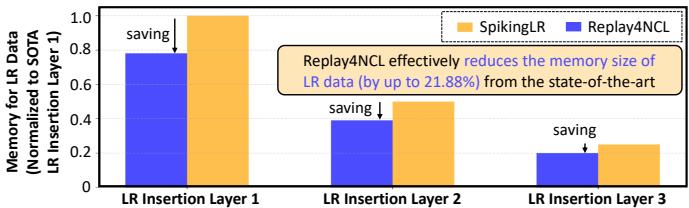
图 12. Replay4NCL 存储回放数据所需内存比 SpikingLR 更少,最高可节省 21.88%。
处理时间的缩短直接转化为更低的能耗——对移动或自主设备尤为关键。
学习稳定性: 长期一致性
Replay4NCL 在长期学习中同样表现稳定。训练延长至 150 个周期后,其收敛过程更平滑、更稳定,相较 SpikingLR 有显著改善。
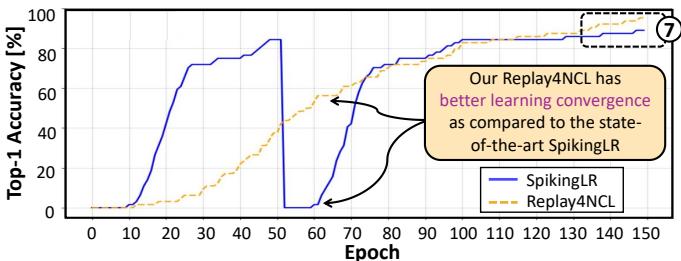
图 13. 在 150 个训练周期中,Replay4NCL (橙色虚线) 呈现比波动的 SpikingLR (蓝线) 更平滑稳定的收敛曲线。
这种稳定性意味着 Replay4NCL 不仅学习高效,而且学习 更可靠。
结论: 嵌入式 AI 的飞跃
灾难性遗忘长期以来阻碍了真正自适应 AI 的实现。尽管记忆回放可以缓解这一问题,但以往方法对于边缘设备而言代价过高。
Replay4NCL 提供了一个优雅而实用的解决方案。通过结合 时间步优化、参数校准 与 策略性数据回放 , 该方法实现了稳健且节能的持续学习。
Replay4NCL 以 90.43% 的 Top-1 准确率 保留旧知识,在 延迟方面提升 4.88× , 并将内存与能耗需求分别降低了 20% 和 36.43% 。
这一成果标志着朝着能够随时间学习与适应的智能系统迈出了重要一步——而不再以资源消耗为代价。借助 Replay4NCL,嵌入式 AI 终于能够不仅学习一次,而是实现终身学习。