](https://deep-paper.org/en/paper/2504.08201/images/cover.png)
理解大脑本质上是一个翻译问题。一方面,我们有生物学现实: 神经元以复杂、有节律的模式发放电脉冲。另一方面,我们有可观察到的输出: 运动、选择和行为。
几十年来,计算神经科学一直将这种翻译视为两个独立、截然不同的任务。如果你利用行为来预测神经活动,你就在进行神经编码 (Neural Encoding) 。 如果你利用神经活动来预测行为,你就在进行神经解码 (Neural Decoding) 。 历史上,模型通常被设计为只执行其中之一。我们要么构建编码器来理解大脑如何表征世界,要么构建解码器利用神经信号控制机械臂。
但大脑并不是在真空中运作的。神经活动与行为之间的关系是双向的,且紧密交织。要真正理解神经计算,我们需要一个统一的框架,能够流畅地运用这两种语言。
在这篇文章中,我们将深入探讨一篇题为 “Neural Encoding and Decoding at Scale” (大规模神经编码与解码,简称 NEDS) 的新论文。这项研究介绍了一种多模态基础模型,该模型通过一种新颖的“多任务掩码”策略,学会了在脉冲 (spikes) 和动作之间无缝转换,从而实现了最先进的性能。
神经科学的双行道
在了解解决方案之前,我们必须明确定义问题。神经元的作用与动物的行为之间的关系是由复杂的概率控制的。
- 编码 (\(P(\text{Neural} | \text{Behavior})\)): 这提出的问题是: “假设动物将手向左移动,神经元 X 发放脉冲的概率是多少?”这有助于我们理解神经元的*感受野 (receptive fields) *和调谐特性。
- 解码 (\(P(\text{Behavior} | \text{Neural})\)): 这提出的问题是: “假设神经元 X 和 Y 发放了脉冲,动物正在移动手的概率是多少?”这是脑机接口 (BCI) 的基础。
人工智能领域的最新进展为我们带来了在海量数据上训练的“大规模模型”。在神经科学中,像 POYO+ 或 NDT2 这样的模型已成功将 Transformer 架构应用于神经数据。然而,这些模型通常是专业化的。它们要么是出色的解码器,要么是出色的编码器,但很少两者兼备。这导致了我们工具的碎片化——我们实际上是在分别构建“英语到法语”和“法语到英语”的字典,却失去了通过理解整体语言而获得的细微语境。
NEDS 登场: 一个统一的基础模型
研究人员提出了 NEDS (Neural Encoding and Decoding at Scale) 来填补这一鸿沟。NEDS 是一个多模态 Transformer 。 在像 GPT-4 这样的大型语言模型 (LLM) 世界中,“多模态”通常指文本和图像。在这里,模态是指神经脉冲和行为变量 (如轮速、胡须运动或选择) 。
NEDS 的核心洞见在于,通过训练单个模型同时解决多个掩码任务,模型可以学习到一种稳健的大脑状态内部表示,从而同时惠及编码和解码任务。
翻译的架构
如何将脉冲和动作输入到同一个神经网络中?答案在于词元化 (Tokenization) 。 Transformer 对词元 (tokens) 序列进行操作。NEDS 将神经活动和行为视为两个需要对齐的平行序列。
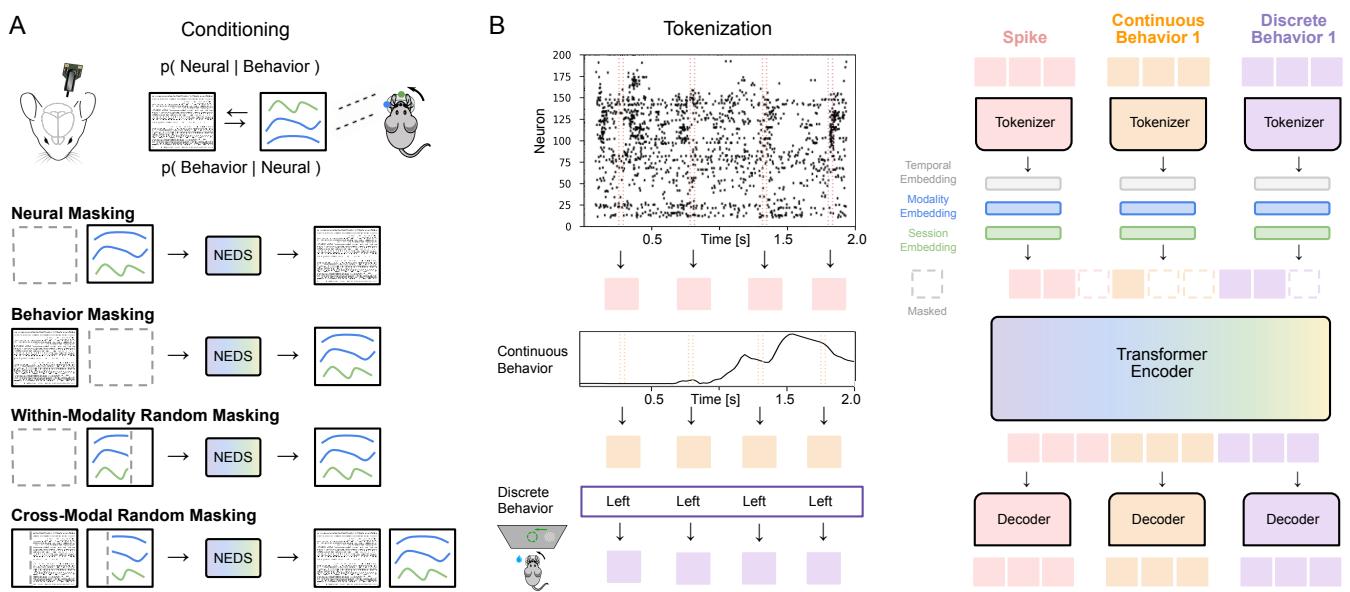
如图 1 所示,该架构旨在处理数据的不同性质:
- 神经数据: 脉冲被划分到 20ms 的时间窗 (bins) 中。“神经词元化器”将这些脉冲计数转换为向量嵌入 (embeddings) 。
- 连续行为: 像轮速这样的变量也被划分到 20ms 的时间窗中。特定的词元化器将这些连续值转换为嵌入。
- 离散行为: 像“左/右”选择这样的变量是分类的。这些变量在试验期间被重复,以与时间序列数据对齐。
一旦完成词元化,模型会添加时间 (时间位置) 、模态 (这是神经元还是行为?) 和会话 (这是哪只老鼠?) 的嵌入。然后将这些词元拼接起来,输入到一个标准的 Transformer 编码器中。
核心创新: 多任务掩码 (Multi-Task-Masking)
NEDS 的“秘诀”在于它的训练方式。作者利用了一种称为掩码建模 (Masked Modeling) 的技术,该技术在语言领域的 BERT 和计算机视觉领域的 MAE 中非常流行。其核心思想很简单: 隐藏部分数据,并强迫模型猜测缺失的部分。
然而,标准的随机掩码不足以迫使模型学习大脑与行为之间的关系。NEDS 引入了一种多任务掩码策略 , 在四个特定目标之间交替进行 (如图 1A 所示) :
- 神经掩码 (编码) : 模型隐藏神经词元,只看行为。它必须预测神经活动。这明确地训练了条件期望 \(\mathbb{E}[X | Y]\)。
- 行为掩码 (解码) : 模型隐藏行为词元,只看神经活动。它必须预测行为。这训练了 \(\mathbb{E}[Y | X]\)。
- 模态内随机掩码: 随机隐藏神经数据块,并根据其他神经数据进行预测 (行为数据同理) 。这迫使模型学习单一模态的内部动态 (例如,“如果神经元 A 发放脉冲,神经元 B 通常会在 10ms 后发放”) 。
- 跨模态随机掩码: 随机隐藏跨越两种模态的数据块。模型必须利用一切可用线索——无论是神经的还是行为的——来重构缺失的数据。这鼓励模型学习联合概率分布。
通过在训练过程中不断切换这些任务,NEDS 不仅仅是死记硬背模式;它学习了连接大脑与动作的因果和相关结构。
数学框架
为了将其形式化,作者定义了一个生成过程。目标是在给定模型参数的情况下最大化数据的似然性。

让我们分解上面的方程:
- 词元化 (\(Z_X, Z_Y\)): 原始输入被投影到潜在空间。
- 掩码 (\(M \odot ...\)): 基于上述四种策略之一应用掩码 \(M\)。
- 位置嵌入 (\(Z_{pos}\)): 模型添加上下文: 模态 (大脑 vs. 行为) 、时间 (时间 \(t\)) 和会话 (老鼠 ID) 。
- Transformer: 处理序列的核心机制。
- 输出头 (\(X \sim, Y \sim\)):
- 对于神经活动 , 模型预测发放率 \(\lambda\)。由于脉冲计数是离散且非负的,损失函数基于泊松 (Poisson) 分布。
- 对于连续行为 (如速度) ,它最小化均方误差 (MSE) 。
- 对于离散行为 (如选择) ,它使用交叉熵 (Cross-Entropy) 损失。
这种统一的目标函数允许模型使用梯度下降同时针对所有任务进行优化。
实验结果: 验证基础
研究人员在一个来自国际大脑实验室 (IBL) 的海量数据集上评估了 NEDS。该数据集包含 83 只老鼠执行完全相同的决策任务的记录,并针对相同的大脑区域。这种标准化使其非常适合测试大规模模型。
扩大规模: 多会话训练的力量
现代人工智能的一个关键假设是“数据越多越好”。在 73 只不同的老鼠上进行训练,是否有助于模型预测第 74 只未见过的老鼠的活动?
作者比较了单会话 NEDS (仅在测试的特定老鼠上训练) 和多会话 NEDS (在 73 只动物上预训练,然后在目标动物上微调) 。
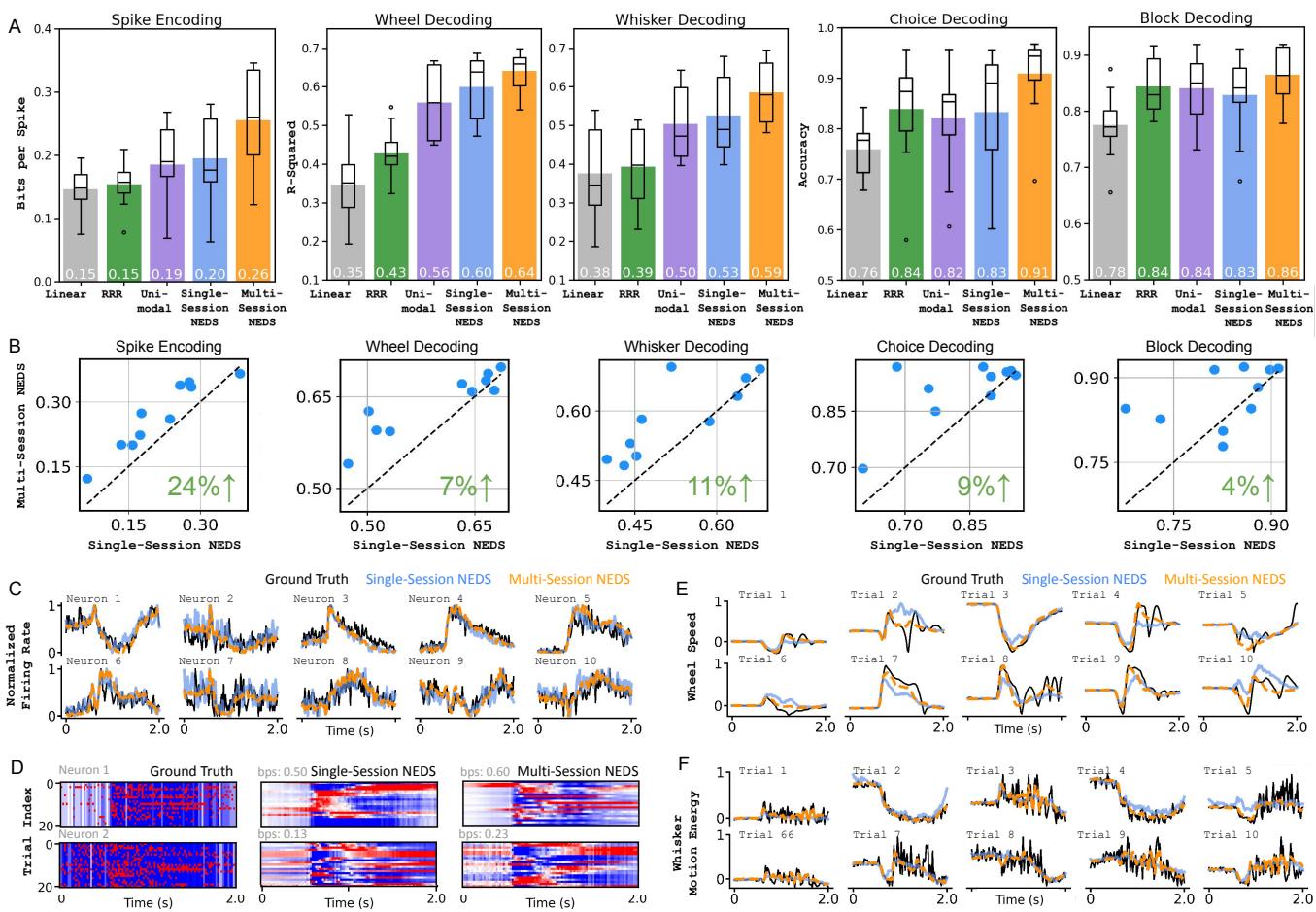
图 2 中的结果令人信服:
- 图 A: 多会话 NEDS (橙色框) 在所有指标上均取得最高分。在神经编码方面,它达到了近 0.27 bits/spike (bps),显著高于线性基线或单会话模型。
- 图 B: 散点图展示了直接对比。每个点代表一个会话。由于几乎所有的点都在对角线之上,我们证实了在其他动物上进行预训练显著提高了在目标动物上的性能。
- 脉冲编码实现了巨大的 24% 的提升 。
- 轮子解码提高了 7% 。
- 定性轨迹 (C-F): 观察图 C 中的橙色线条。多会话预测比蓝色单会话线条更紧密地跟踪真实值 (黑色) 。这表明模型利用其对老鼠大脑动态的“通用知识”填补了单会话模型认为是噪声的空白。
与最先进技术的比较
NEDS 与该领域的其他重量级模型相比如何,特别是 POYO+ (一种专用的解码模型) 和 NDT2 (一种掩码建模方法) ?
作者在相同的 74 个会话上预训练了所有模型,并在留出的动物上对它们进行了微调。
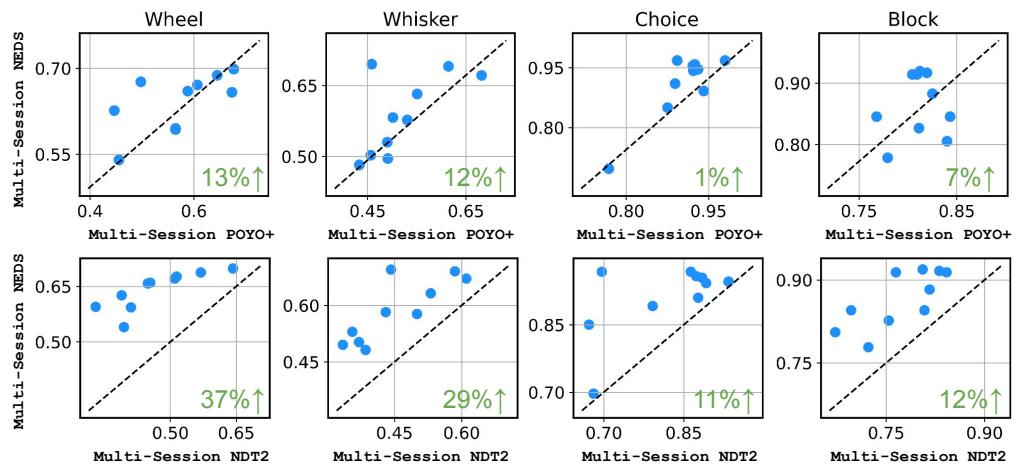
图 3 展示了 NEDS 的优势:
- 对比 POYO+ (上排) : POYO+ 是一个强有力的竞争者,专用于解码。NEDS 与其势均力敌或略胜一筹 (例如,在轮子解码上 +13%) ,同时保持了执行编码的能力 (这是 POYO+ 无法做到的) 。
- 对比 NDT2 (下排) : NEDS 显著优于 NDT2,在轮子解码上有 37% 的提升 , 在胡须解码上有 29% 的提升 。
这验证了一个假设: NEDS 的多模态性质——在预训练期间既看到脉冲也看到行为——创造了比仅看神经数据 (NDT2) 或仅针对解码任务优化 (POYO+) 的模型更优越的潜在表示。
涌现特性: 大脑区域图谱
这就论文中最引人入胜的结果或许是模型的涌现特性 (emergent property) 。 模型从未被明确告知某个神经元属于哪个大脑区域。它只是被输入了脉冲序列和行为。
然而,每个神经元在模型内部都有一个学习到的“嵌入”——即向量表示。研究人员可视化了这些嵌入,看看模型是否学习到了任何关于神经解剖学的知识。
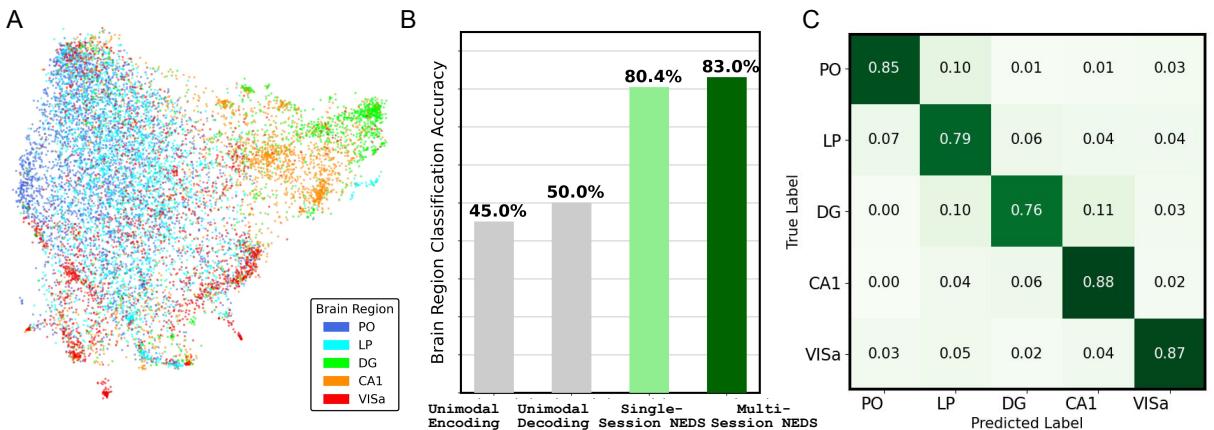
图 4A 展示了这些嵌入的 UMAP 投影。这些点自动组织成明显的聚类,对应于海马体 (CA1, DG) 、视觉皮层 (VISa) 和丘脑 (PO, LP) 等解剖区域。
- 图 B: 当在这些嵌入上训练一个分类器来预测大脑区域时,多会话 NEDS 达到了 83% 的准确率 。 这显著高于单模态模型 (约 45-50%) 。
- 解读: 这意味着神经元的功能角色 (它是如何发放脉冲以及如何与行为相关联) 是非常独特的,以至于一个足够强大的模型可以纯粹从功能数据中“重新发现”大脑的解剖结构。
- 图 C (混淆矩阵) : 错误也具有指导意义。模型有时会混淆 PO 和 LP (后丘脑) 。正如作者所指出的,这些区域在解剖上相邻且功能相似,这表明这种“错误”实际上反映了生物学现实。
结论
NEDS 代表了计算神经科学向前迈出的重要一步。通过将神经编码和解码不视为独立的问题,而是视为同一枚条件概率硬币的两面,研究人员构建了一个更稳健、泛化能力更强的模型。
关键要点如下:
- 统一性: 单一架构可以在预测脉冲和预测行为方面同时达到最先进的结果。
- 掩码至关重要: 多任务掩码策略对于学习不同模态的联合分布至关重要。
- 规模致胜: 在许多动物上进行预训练使模型能够学习可迁移到新个体的通用神经动态。
- 涌现性: 大规模训练在没有明确监督的情况下揭示了生物学结构 (如大脑区域) 。
随着数据集变得更大、更多样化,像 NEDS 这样的方法使我们更接近“大脑基础模型”——一种能够跨越受试者、区域和任务解释神经活动的通用翻译器,这可能会彻底改变从基础研究到临床脑机接口的一切。