](https://deep-paper.org/en/paper/2504.08823/images/cover.png)
想象一下,你教一个智能助手识别不同的鸟类。它首先学会了识别知更鸟。然后,你教它认识麻雀。但当你再次让它识别知更鸟时,它却完全忘记了知更鸟长什么样。
这种令人沮丧的现象被称为 灾难性遗忘 (catastrophic forgetting) , 是创建真正智能且自适应的 AI 系统时最大的障碍之一。
在一个不断变化的世界里,我们需要 AI 能够持续学习——在不覆盖旧知识的情况下获取新技能和新知识。这就是持续学习 (Continual Learning, CL) 的精髓。虽然人类可以毫不费力地做到这一点,但深度学习模型仍然举步维艰,通常需要从头开始完全重新训练,这既缓慢、昂贵又不切实际。
最近的一篇研究论文 “FM-LoRA: Factorized Low-Rank Meta-Prompting for Continual Learning” 提出了一个紧凑而强大的框架来解决这一问题。作者设计了一种方法,使大型预训练模型——尤其是视觉 Transformer (ViT)——能够高效地学习一系列任务,无需存储旧数据,也不会发生灾难性遗忘。
让我们来看看它是如何做到的。
AI 的两难境地: 稳定性 vs. 可塑性
持续学习的核心在于一个称为稳定性–可塑性困境 (stability–plasticity dilemma) 的根本权衡:
- 稳定性: 模型必须保留先前学到的知识。
- 可塑性: 模型必须保持足够的灵活性以学习新任务。
可塑性过强会导致遗忘;稳定性过强则会导致停滞。
研究人员尝试了几种方法来寻求平衡:
- 回放方法: 在训练新任务时重用一小部分过去的数据。有效但占用大量内存且具有隐私风险。
- 正则化方法: 对先前任务中重要参数的过大更新进行惩罚。稳定但限制性强。
- 架构方法: 为每个任务附加新的模块或适配器。理论上可扩展,但会迅速使模型变得臃肿。
最近,一种新思路出现了: 参数高效微调 (PEFT, Parameter-Efficient Fine-Tuning) 。 与其重新训练庞大的预训练模型的所有参数,PEFT 只更新一小部分——例如 LoRA (低秩自适应, Low-Rank Adaptation) 模块——从而大大提高了效率。
然而,像 LoRA 这样的 PEFT 方法并非为顺序、终身学习而设计,在跨多个任务时仍然会遇到困难。
这正是 FM-LoRA 发挥作用的地方。
FM-LoRA 的核心: 三重奏式的和谐机制
FM-LoRA 通过三个协同模块实现终身学习:
- 分解式低秩自适应 (F-LoRA)
- 动态秩选择器 (DRS)
- 动态元提示 (DMP)
它们共同使模型能够高效学习、快速适应并持久记忆。
让我们分别来看。
1. F-LoRA: 在共享、稳定的子空间中学习
标准的 LoRA 会为每个新任务引入小矩阵 \(A_t\) 和 \(B_t\),来计算权重矩阵的增量变化:
\[ \Delta W_t = A_t B_t^{\top} \]这帮助模型高效学习,但在任务之间容易产生冗余和干扰。
F-LoRA 对这一思路进行了改进。与为每个任务单独学习适配器不同,FM-LoRA 将低秩更新分解为共享和任务特定组件:
\[ \Delta W_t = A_{\text{shared}} M_t N_t^{\top} B_{\text{shared}}^{\top} \]- \(A_{\text{shared}}\) 和 \(B_{\text{shared}}\) 是全局低秩基,只在第一个任务时学习一次并随后冻结,表示所有任务通用的稳定适应方向。
- \(M_t\) 和 \(N_t\) 是小型任务特定矩阵,用以为每个任务调整这些共享基。
通过固定共享基,所有更新都保持在一个受控且一致的低维子空间内。
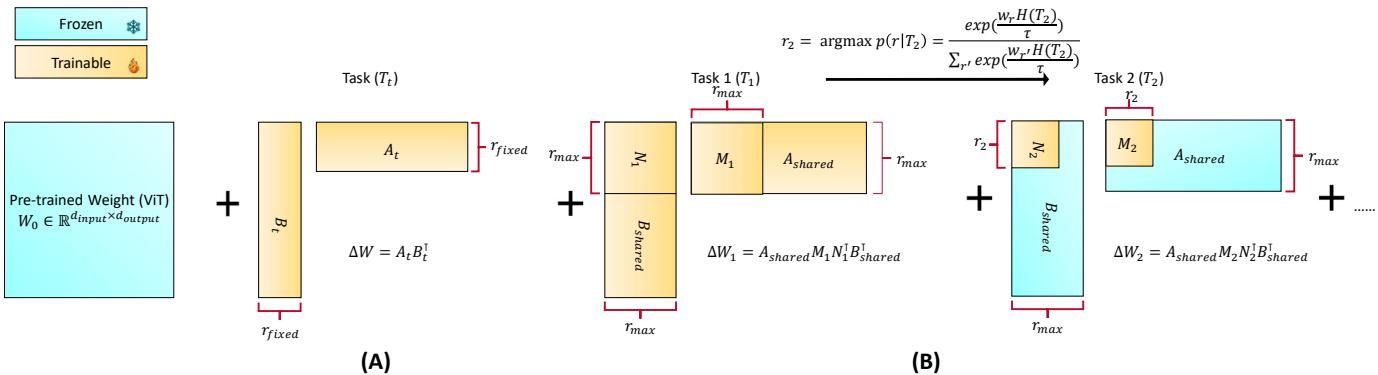
图 1: FM-LoRA 在第一个任务上学习共享基 \(A_{\text{shared}}\) 和 \(B_{\text{shared}}\)。后续任务仅学习小矩阵 \(M_t\) 和 \(N_t\),使所有更新都保持在一个稳定、共享的子空间内。
F-LoRA 的优势:
- 极致高效: 每个任务只增加很少的参数——仅 \(2r^2\),相比传统方法的几十万参数要轻得多。
- 减少干扰: 任务更新被限制在共享基内,最大限度地减少了新旧知识之间的冲突。
可以把 F-LoRA 看成一个安全的适应区——确保新知识的学习与已有经验和谐共存。
2. 动态秩选择器 (DRS): 适应任务的复杂性
接下来的问题是: 这个子空间需要多大? 秩 (r) 决定了适配器的灵活性——更高的秩允许更多的表现力,但也需要更多参数。
为所有任务使用固定秩无法反映任务复杂性的多样性。 这时便需要 动态秩选择器 (DRS) 。
DRS 通过评估任务复杂性自动调整每个任务的秩 \(r_t\)。作者用一次短暂预训练中的验证损失来衡量复杂性: 较难的任务会产生更高的损失。模型通过 Gumbel-Softmax 机制以概率方式选择秩:
\[ p(r|\mathcal{T}_t) = \frac{\exp\left(\frac{w_r H(\mathcal{T}_t)}{\tau}\right)}{\sum_{r'} \exp\left(\frac{w_{r'} H(\mathcal{T}_t)}{\tau}\right)} \]其中,\(H(\mathcal{T}_t)\) 表示任务复杂性,\(w_r\) 是不同候选秩的可学习权重,\(\tau\) 控制平滑度。 模型最终选择概率最高的秩 \(r_t\)。
这种自适应策略使模型具备任务相似性感知能力 :
- 当新任务与旧任务相似时,DRS 选择较小的秩,以节省容量并避免冗余。
- 当任务较独特或更复杂时,DRS 则选择更高的秩来捕获新的信息。
最终,使模型能够动态调整自己的容量,在保持稳定性的同时具备灵活性。
3. 动态元提示 (DMP): 构建隐式记忆
即使具备稳定的适应机制,没有回放的模型仍可能发生表示漂移——跨任务的表示逐渐失去对齐。 FM-LoRA 使用 动态元提示 (DMP) 来解决这一问题,它是一组共享的可学习 token,在输入序列进入 Transformer 前被添加到序列开头。
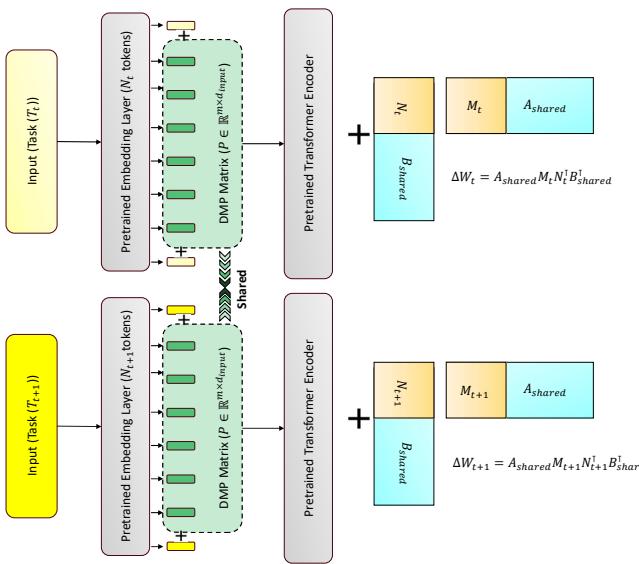
图 2: 动态元提示 (DMP) 在每个输入前添加可学习的 token。它们在所有任务中持续演化,充当共享上下文,锚定并稳定表示。
这些 token 就像共享记忆的锚点 , 在跨任务的表示中保持稳定。 它们会随每个新任务更新,逐渐形成一个贯穿所有经验的通用上下文。 随着时间推移,DMP 提供稳定的提示信号,减少漂移并帮助模型保留已学知识。
实验与结果: 实践检验
研究人员在多个持续学习基准上评估了 FM-LoRA,包括 ImageNet-R、CIFAR100、CUB200 和 DomainNet , 涵盖类增量和域增量两种场景。
主要的两个指标是:
- 准确率 (Acc): 序列化训练结束后在所有任务上的整体性能。
- 平均随时准确率 (AAA): 学习全过程中的平均性能,用于衡量遗忘程度。
压力下的表现: 更长任务序列
在 ImageNet-R 基准上,FM-LoRA 随任务数量增加仍保持卓越的稳定性。
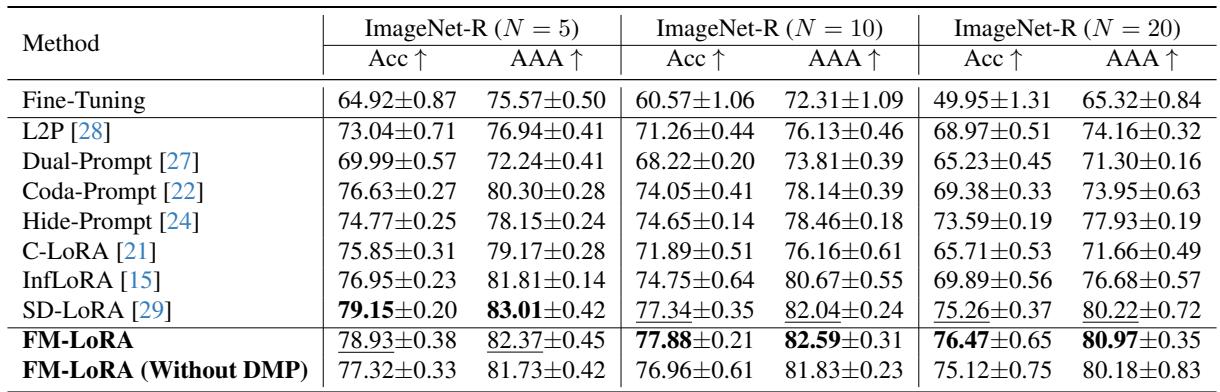
当大多数方法随着任务增多而性能急剧下降时,FM-LoRA 依然保持稳定——甚至随着任务序列变长,其优势更加明显。
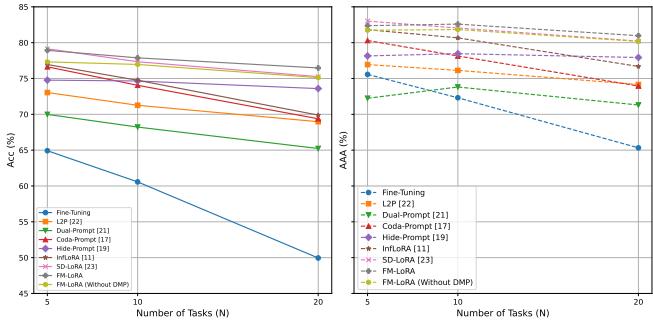
图 3: 随着任务数量增加,FM-LoRA 保持高准确率。普通微调 (灰线) 则彻底崩溃,出现严重遗忘。FM-LoRA 的曲线稳健,证明其出色的稳定性。
在 20 个任务情况下,FM-LoRA 在准确率上比领先的对比方法 SD-LoRA 高出约 1% , 在 AAA 上高出 0.7% , 证明了其在长期学习场景中的鲁棒性。
跨数据集的通用性
更令人瞩目的是 FM-LoRA 在不同基准上的一致表现 。 作者在 CIFAR100 (通用物体类别) 、CUB200 (细粒度鸟类数据集) 以及 DomainNet (包含六个风格域) 上进行了测试。
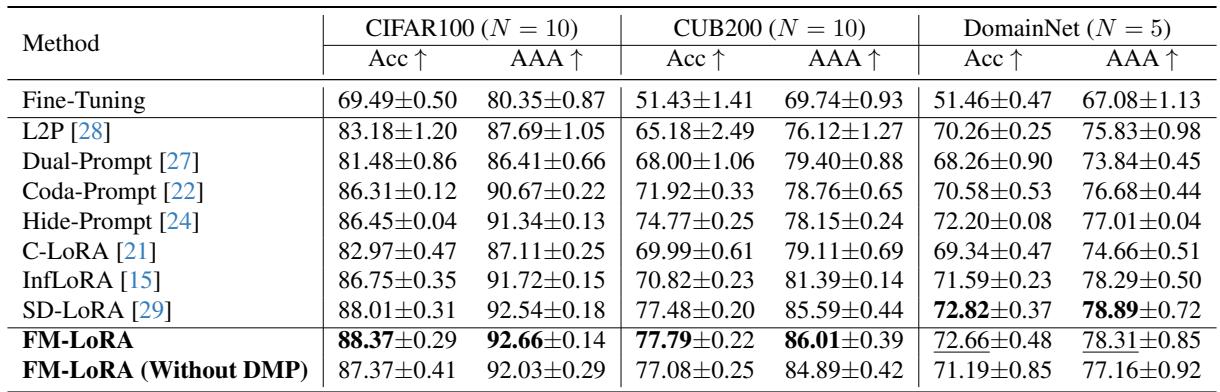
无论是处理新类别标签还是全新域迁移,FM-LoRA 在所有场景中都取得了领先或接近领先的结果。 该框架展现了强大的泛化能力,证明其在终身学习中的普适性和可扩展性。
各组件的重要性验证: 消融实验
任何强大的框架都要经过严格验证。研究人员进行了多项消融实验 , 评估各组件的贡献。
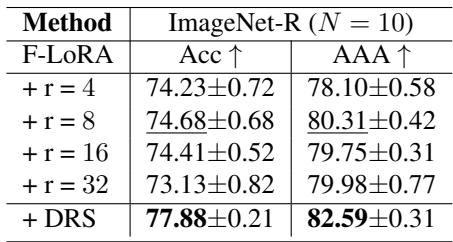
- DRS 的影响: 将使用固定秩的 F-LoRA 与 F-LoRA + DRS 对比,结果显示 DRS 始终优于所有固定秩的版本,能够精准地根据任务复杂性动态分配容量。
- DMP 的影响: 评估不同提示 token 数量的效果,结果表明 DMP 确实带来提升。适中的 token 数量能在效率与性能之间取得最佳平衡。
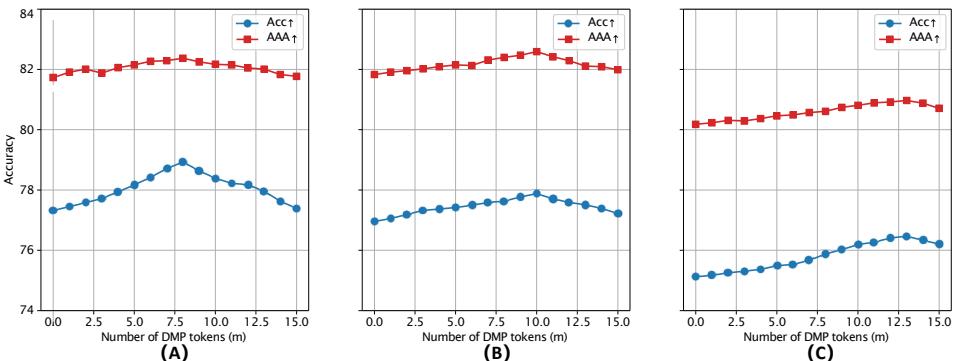
图 4: 改变提示 token 数量 \(m\) 会影响性能。较多的 token 有助于更长任务序列,而较少的 token 足以应对较短序列。
这些实验确认 FM-LoRA 的三大组件——F-LoRA、DRS 和 DMP——均对整体性能有重要贡献。它们共同构成了一个紧密且自适应的系统。
结论: 迈向真正的终身学习
FM-LoRA 是 AI 迈向终身学习的重要一步。 通过结合:
- F-LoRA : 将学习限制在稳定的低秩子空间,
- DRS : 智能地为每个任务调整模型容量,
- DMP : 通过共享提示锚定表征,
该框架在稳定性与可塑性之间实现了精妙的平衡——这是真正持续学习的核心。
FM-LoRA 不仅能学新东西,还能在学习过程中记忆、适应和改进——无需旧数据,也不依赖庞大模型。 这种统一的理念让我们距离构建像人类一样,随经验增长而愈加智慧、不再遗忘的 AI 系统又近了一步。