](https://deep-paper.org/en/paper/2504.16925/images/cover.png)
引言
在机器人领域,数据就是财富。过去几年里,主要得益于模仿学习 (Imitation Learning, IL) 的推动,机器人策略的能力有了巨大的飞跃。其公式看似简单: 收集大量人类专家执行任务 (如折叠毛巾或开门) 的数据集,然后训练神经网络来复制这些动作。
然而,这其中有个陷阱。这种“专家数据”极其昂贵。它需要人类操作员花费数小时遥操作机器人, meticulously 地为每个状态标记精确的动作。与此同时,存在着大量我们大多忽略的“廉价”数据: 机器人尝试任务并失败的视频 (次优数据) ,或者人类或机器人执行任务但没有记录具体电机指令的视频 (无动作数据) 。
标准方法,如最先进的 扩散策略 (Diffusion Policy) , 很难利用这些廉价数据。因为它们将视觉观察直接映射到动作,所以要求动作标签必须存在且是最优的。如果动作缺失或错误,模型就学不到任何东西——或者更糟,学到了错误的东西。
潜在扩散规划 (Latent Diffusion Planning, LDP) 应运而生。这种由斯坦福大学和加州大学伯克利分校的研究人员提出的新方法,通过将 “做什么” 与 “怎么做” 分离开来,从根本上改变了机器人的学习方式。通过将学习过程拆分为规划未来状态和弄清楚如何到达那里的动作,LDP 能够利用其他模型弃之不用的那些廉价、杂乱的数据。
在这篇文章中,我们将拆解 LDP 的架构,解释它如何以新颖的方式利用扩散模型,并分析它如何通过从失败和观察中学习,从而超越最先进的基准模型。
背景: 模仿学习中的数据问题
要理解为什么潜在扩散规划是必要的,我们需要先看看当前模仿学习 (IL) 方法的局限性。
行为克隆与扩散策略
标准的 IL 框架是 行为克隆 (Behavior Cloning, BC) 。 你拥有一组数据对: 世界的图像 (\(x_t\)) 和专家采取的动作 (\(a_t\)) 。目标是学习一个策略 \(\pi\),使得 \(\pi(x_t) \approx a_t\)。
最近, 扩散策略 (Diffusion Policy) 已成为这方面的黄金标准。它将机器人的动作序列视为一个“去噪”问题。从随机噪声开始,它迭代地精炼噪声,直到其变成平滑的、类似专家的动作轨迹。
虽然功能强大,但这些方法有一个严格的要求: \((x_t, a_t)\) 数据对必须是最优的。
- 无动作数据 (Action-Free Data) : 如果你有一段机器人移动的视频,但没有记录电机扭矩 (动作) ,标准的 BC 智能体无法从中学习。它不知道该预测什么 \(a_t\)。
- 次优数据 (Suboptimal Data) : 如果你有一段机器人试图拿起杯子但没拿到的日志,训练于此的标准 BC 智能体会学会错过杯子。
模块化学习的希望
LDP背后的研究人员提出了一种模块化的解决方案。他们不再学习从图像到动作的直接映射,而是将问题拆分为两个不同的阶段:
- 规划器 (The Planner) : 观察当前世界并构想一部任务已解决的未来状态“电影”。关键在于,这只处理 状态,不处理动作。
- 逆动力学模型 (Inverse Dynamics Model, IDM) : 观察那部“电影”中两个连续的帧,并计算出从一帧移动到另一帧所需的动作。
这种分离是解锁廉价数据的关键。你可以用没有动作的视频 (无动作数据) 来训练规划器。你可以用杂乱的机器人日志 (次优数据) 来训练 IDM 以理解物理规律,即使整体计划是糟糕的。
核心方法: 潜在扩散规划
潜在扩散规划 (LDP) 由三个不同的训练阶段组成: 学习压缩的潜在空间、训练规划器以及训练逆动力学模型。
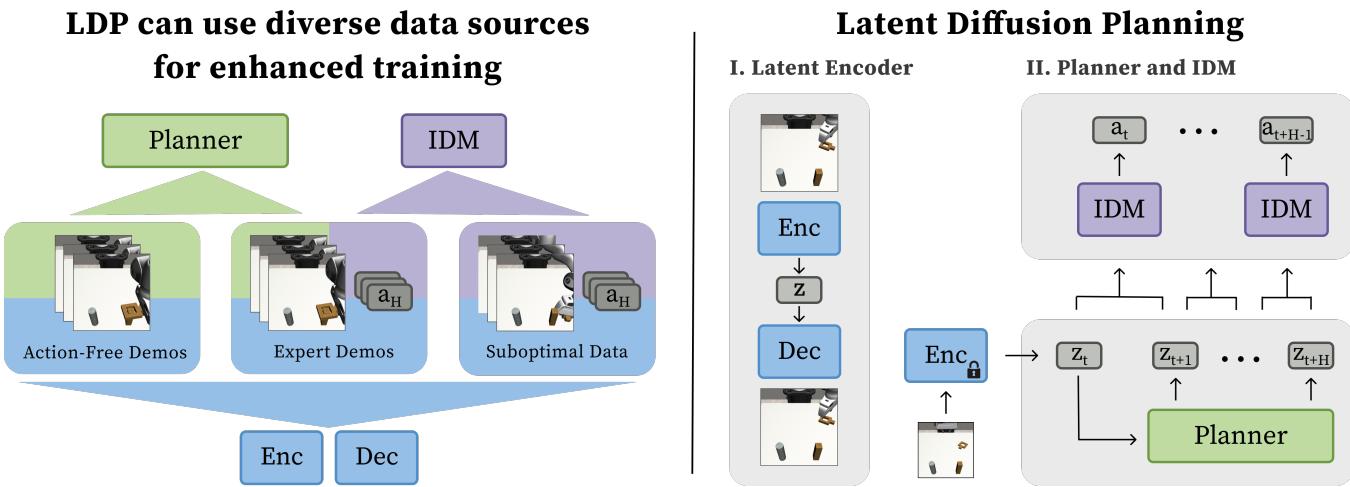
如 图 1 所示,该架构不再直接预测动作,而是预测潜在空间中密集的未来状态序列。让我们分解每个组件。
1. 学习紧凑的潜在空间 (\(\beta\)-VAE)
直接在“像素空间”中进行规划 (生成未来的高分辨率视频帧) 计算量大且困难。视频生成模型必须考虑光照、纹理和背景细节,而这些与机器人移动物体的任务无关。
为了解决这个问题,LDP 本质上将图像“压缩”成一种称为 潜在嵌入 (Latent Embedding, \(z\)) 的格式。它使用的是 \(\beta\)-变分自编码器 (\(\beta\)-Variational Autoencoder, VAE) 。
VAE 包含:
- 编码器 (Encoder, \(\mathcal{E}\)) : 接收图像 \(x\) 并将其压缩为低维向量 \(z\)。
- 解码器 (Decoder, \(\mathcal{D}\)) : 接收向量 \(z\) 并尝试重建原始图像 \(x\)。
训练目标是在重建质量与保持潜在空间平滑的正则化项 (KL 散度) 之间取得平衡:
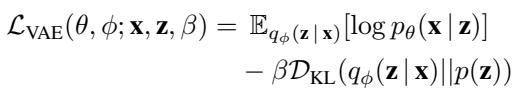
这里,\(\beta\) 控制潜在空间的结构化程度。通过在所有可用数据 (专家、次优和无动作数据) 上进行训练,机器人学习到了世界的紧凑表示,其中数学上相似的向量代表视觉上相似的状态。
2. 潜在规划器
一旦 VAE 训练完成,我们就将其冻结。我们不再关心像素;我们只关心潜在向量 \(z\)。 规划器 是一个负责“想象”未来的扩散模型。
给定当前的潜在状态 \(z_k\),规划器预测未来的潜在状态序列: \(\hat{z}_{k+1}, \dots, \hat{z}_{k+H}\)。
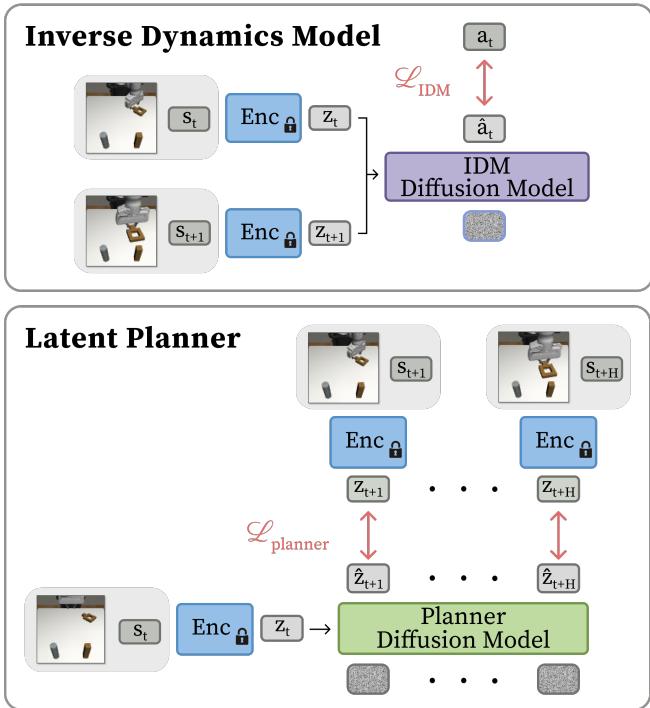
如 图 2 下半部分所示,规划器使用条件 U-Net 架构 (改编自扩散策略) 。它从高斯噪声开始,将其去噪为连贯的潜在嵌入轨迹。
规划器的损失函数为:
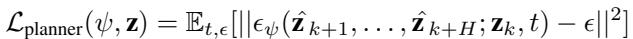
为什么这很强大? 这个目标仅依赖于状态 (\(\mathbf{z}\))。这意味着你可以给规划器输入没有记录动作数据的视频演示。规划器学会了“如果我正拿着杯子,下一个有效的状态是杯子稍微高一点”,而不需要知道举起它所需的电机电流。
3. 逆动力学模型 (IDM)
规划器给了我们一部成功的“心理电影”,但机器人需要电机指令。这就是 逆动力学模型 (IDM) 的工作。
IDM 是一个较小的扩散模型,它接收两个相邻的潜在状态 \(z_k\) 和 \(z_{k+1}\),并预测弥合差距所需的动作 \(a_k\)。
损失函数很简单:
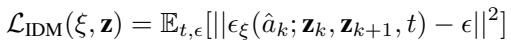
为什么这很强大? IDM 学习局部的物理规律。即使在机器人打翻杯子的“失败”轨迹 (次优数据) 中,从 [手靠近杯子] 到 [手撞到杯子] 的过渡也包含了关于手臂如何移动的有效物理信息。IDM 可以从这些杂乱的数据中学习,而标准的行为克隆会被失败所困扰。
推理循环
在部署 (运行时) 期间,LDP 执行一个闭环循环:
- 观察: 机器人看到当前图像 \(x_0\) 并将其编码为 \(z_0\)。
- 规划: 规划器扩散出未来的潜在序列 \(\hat{z}_1 \dots \hat{z}_H\)。
- 行动: IDM 观察状态对 \((z_0, \hat{z}_1), (\hat{z}_1, \hat{z}_2) \dots\) 并预测相应的动作。
- 执行: 机器人执行这一小段动作 (滚动时域控制) ,然后观察新状态并重新规划。
这种方法是 闭环 的。不像某些视频规划器那样生成一段长视频后就盲目跟随,LDP 在每一步 (或每几步) 都会重新规划,使其能够在机器人打滑或被推动时纠正错误。
实验与结果
研究人员在几个具有挑战性的模拟任务 (Robomimic 的举重、罐头、方形任务和 ALOHA 传递方块任务) 以及现实世界的 Franka Emika Panda 机械臂任务上评估了 LDP。主要目标是看 LDP 是否真的能利用“垃圾”数据来提高性能。
利用无动作数据
首先,他们测试了一种“低数据”场景,只提供少量专家演示。然后他们加入了 无动作数据 (没有动作标签的任务视频) 。
基准模型包括:
- DP (Diffusion Policy): 标准的 SOTA 方法,无法使用无动作数据。
- DP-VPT: 一种尝试使用单独模型为无动作数据打标签,然后在上面训练 DP 的方法。
- UniPi: 一种基于视频的规划器,生成像素而不是潜在变量。
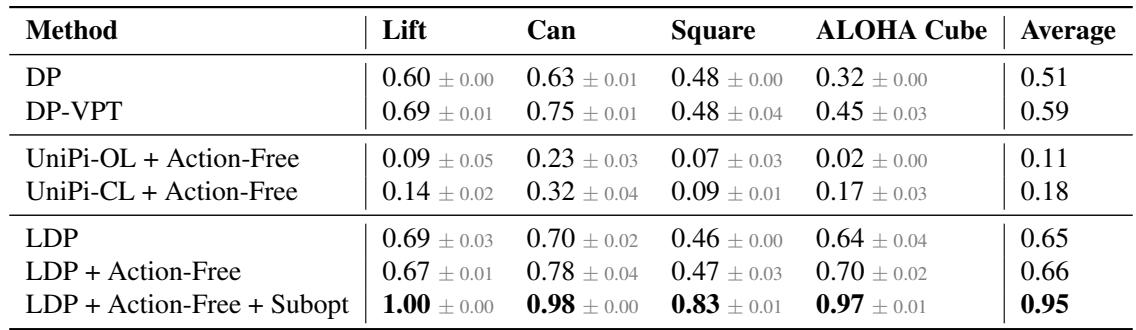
表 1 分析:
- LDP 优于 UniPi: 基于像素的规划器 (UniPi-OL 和 UniPi-CL) 表现非常挣扎,在像方形和方块这样的困难任务上成功率低于 20%。在像素空间进行规划实在是太难且容易出错了。
- LDP vs. 伪标签 (DP-VPT): 虽然使用模型对数据进行伪标签 (DP-VPT) 有帮助,但 LDP 表现更好 (平均 0.65 对比 0.59) 。这表明让规划器简单地学习状态转换比试图猜测训练集的精确动作更稳健。
- “协同”效应: 最后一行显示 LDP 同时 使用无动作数据和次优数据,平均成功率大幅跃升至 0.95 。 这证实了模块化组件相互促进: 从视频中获得更好的规划 + 从次优日志中获得更好的物理理解。
利用次优数据
接下来,他们研究了 次优数据——失败的轨迹。标准的模仿学习假设演示者是专家。如果你克隆一个失败,你就会失败。
LDP 使用这些数据来训练 IDM (学习动作如何影响状态) 和 VAE (学习表示世界) ,即使该轨迹未能达到目标。
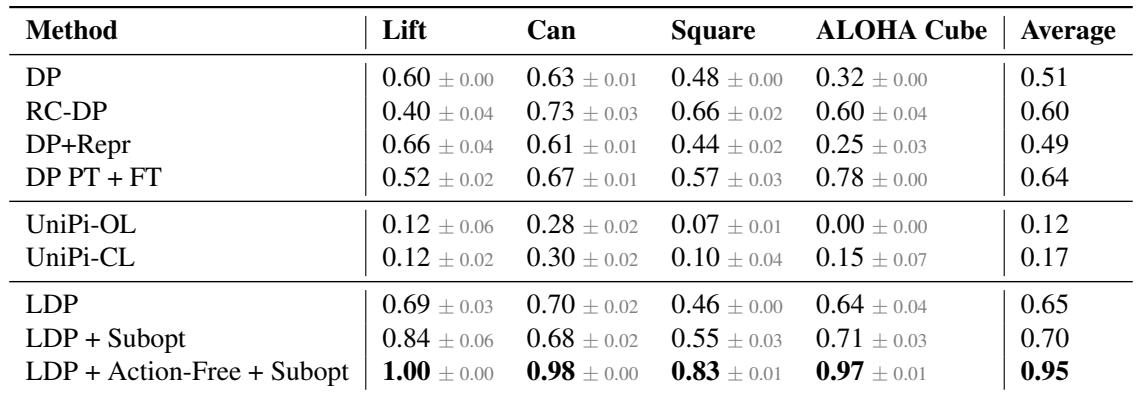
表 2 分析:
- LDP 占据主导地位: 比较标准 DP (0.51) 和 LDP + Subopt (0.70) 显示出明显的优势。模块化设计允许 LDP 从失败中提取价值。
- 与奖励条件 DP (RC-DP) 的比较: RC-DP 是一种告诉策略“这是一条糟糕的轨迹”或“这是一条好的轨迹”的技术。虽然 RC-DP 比基线 (0.60) 有所改进,但 LDP 仍然优于它,特别是在复杂的“ALOHA Cube”任务上。
- 视频规划的挣扎: 同样,UniPi (无论是开环还是闭环) 在这里都未能取得进展,突显了 潜在 空间规划相对于 像素 空间规划的效率。
真实世界性能
模拟很有用,但真正的考验是物理硬件。团队设置了一个涉及举起方块的 Franka 机械臂任务。
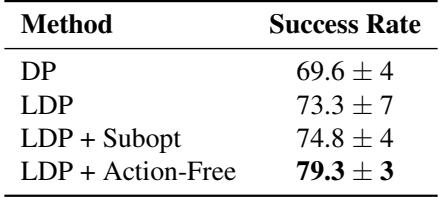
表 3 分析: 真实世界的结果与模拟相呼应。使用额外的次优和无动作数据训练的 LDP 达到了接近 80% 的成功率 , 比标准扩散策略高出约 10 个百分点。这在机器人技术中是一个关键的差距,因为可靠性就是一切。
可视化机器人的“思维”
LDP 最酷的一个方面是我们可以实际看到机器人在想什么。通过获取预测的潜在向量 \(\hat{z}\) 并将其传回 VAE 解码器,我们可以看到“想象”的未来状态。

在 图 3 中,你可以看到模型生成的密集计划。
- 第 1 行 (Lift): 模型想象夹持器向下移动,抓住红色方块并举起。
- 第 3 行 (Square): 你可以看到螺母被操纵到钉子上的过程。
这证实了扩散规划器不仅仅是在凭空捏造数字;它已经学到了关于任务如何随时间推进的结构化、物理的理解。
消融实验: 密集规划 vs. 分层规划
最后,作者检查了“密集”预测 (预测每一步) 是否必要。我们可以只预测相隔较远的“路径点” (子目标) 吗?
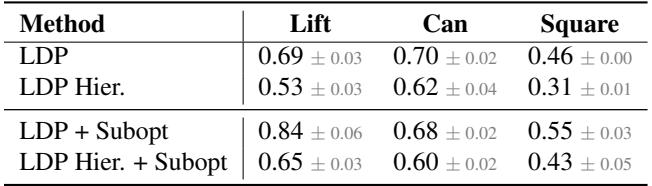
表 4 显示 密集预测 (LDP) 显著优于分层 (基于路径点) 规划。
- 为什么? 在复杂的操纵中,过渡 很重要。如果你只预测最终状态,机器人可能会试图让手臂穿过障碍物传送过去,或者因为没有规划接近角度而错过抓取。预测密集的序列就像是为整个运动提供了护栏。
结论与启示
潜在扩散规划为机器人学习提供了一个引人注目的新配方。通过将 规划 与 动作执行 解耦,它打破了对昂贵的、专家标记数据的严格依赖。
主要收获:
- 不要扔掉“垃圾”数据: LDP 将失败的运行记录和无动作视频变成了有价值的训练信号。
- 在潜在空间规划,而非像素空间: 通过 VAE 压缩图像使得扩散规划过程比视频生成方法更快、更准确。
- 模块化即稳健: 分离规划器和 IDM 允许每个组件各司其职,从而产生反应灵敏且可靠的闭环策略。
对于进入该领域的学生和研究人员来说,LDP 凸显了一个更广泛的趋势: 机器人技术的未来可能不仅仅在于针对专家数据的更好算法,而在于能够摄取世界上已经存在的杂乱、非结构化和海量数据的架构。当我们展望扩大机器人基础模型规模时,像 LDP 这样能够从“整个互联网”的视频数据中学习的技术将至关重要。