](https://deep-paper.org/en/paper/2505.01267/images/cover.png)
引言
在人工智能不断发展的格局中,计算机视觉模型在从医疗诊断到自动驾驶等任务中取得了超越人类的表现。然而,这些模型拥有一个令人震惊的弱点: 对抗性样本 (Adversarial Examples) 。
想象一下,拍一张熊猫的照片,加上一层人类肉眼无法察觉的静态噪声,然后将其输入到最先进的 AI 中。突然之间,AI 100% 确信这只熊猫是一只长臂猿。这并非假设的场景;这是对抗性攻击的基本前提。这些扰动旨在利用神经网络特定的数学敏感性,导致分类任务的灾难性失败。
为了应对这一问题,研究人员开发了对抗性净化 (Adversarial Purification) 。 这个想法简单而优雅: 在图像输入分类器之前,先经过一个“净化器”模型,旨在洗去对抗性噪声,将图像恢复到干净的状态。最近,扩散模型 (Diffusion Models) ——即 DALL-E 和 Stable Diffusion 等图像生成器背后的技术——已成为这项任务的黄金标准。它们向图像添加噪声,直到对抗性模式被淹没,然后从头开始重建图像。
然而,这其中存在一个陷阱。目前的基于扩散的净化方法往往会“连洗澡水带孩子一起倒掉”。在擦除对抗性噪声的过程中,它们经常破坏图像的语义内容 (即真正的“熊猫特征”) 。
在这篇深度文章中,我们将探讨一篇名为 “Diffusion-based Adversarial Purification from the Perspective of the Frequency Domain” (从频域视角看基于扩散的对抗性净化) 的突破性论文。研究人员提出了一种名为 FreqPure 的新方法,从根本上改变了我们进行图像净化的方式。通过将图像不仅仅视为像素,而是视为频域中的波,他们找到了一种在去除攻击的同时保留图像灵魂的方法。
背景: 鲁棒性之战
在剖析解决方案之前,我们必须了解战场。
像素的问题
标准的计算机视觉模型将图像视为像素网格 (空间域) 。对抗性攻击会对这些像素值进行微小的操纵。像对抗性训练 (Adversarial Training) 这样的防御措施涉及在训练期间向模型展示数百万张受攻击的图像,以便模型学会忽略它们。虽然有效,但这在计算上非常昂贵,且难以泛化到新型攻击。
对抗性净化则不同。它是一个预处理步骤。它不需要重新训练分类器。它只是接收一个输入 \(\mathbf{x}_{adv}\) 并试图将其转换回原始的 \(\mathbf{x}_{0}\)。
作为净化器的扩散模型
扩散模型分两步工作:
- 前向过程 (Forward Process) : 逐渐向图像添加高斯噪声,直到它变成纯随机的静态噪声。
- 反向过程 (Reverse Process) : 学习逐步减去噪声以恢复干净的图像。
对于净化,我们获取一张受攻击的图像,添加少量噪声 (部分扩散) ,然后运行反向过程。其理论依据是,对抗性扰动——通常是脆弱且特定的——会被添加的噪声破坏,而图像的鲁棒特征得以保留,从而允许反向过程重建出干净的版本。
缺陷: 本文的研究人员认为现有的方法过于激进。它们将整个图像视为一个需要去噪的整体,未能区分图像中实际受到攻击的部分和安全的部分。
频域视角
为了解决这个问题,研究人员转向了 频域 (Frequency Domain) 。 利用离散傅里叶变换 (DFT) ,任何图像都可以分解为不同频率的正弦波和余弦波。这种变换将图像分解为两个部分:
- 幅度谱 (Amplitude Spectrum) : 代表不同频率的强度或力度。它通常决定图像的“风格”和对比度。
- 相位谱 (Phase Spectrum) : 代表波的位移。它携带了关键的结构信息——边缘、形状和物体轮廓。
分析破坏
研究人员提出了一个关键问题: 对抗性攻击如何影响图像的频率分量?
他们在 CIFAR-10 和 ImageNet 等数据集上,针对各种攻击 (如 PGD 和 AutoAttack) 分析并可视化了干净图像与受攻击图像在频谱上的差异。
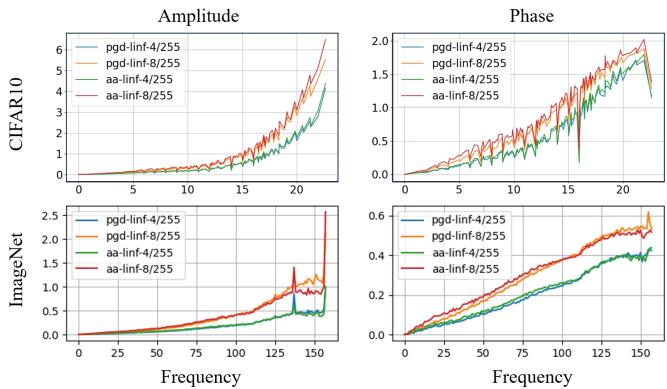
图 1 展示了他们的发现。X 轴代表频率 (从低到高) ,Y 轴代表干净图像与对抗性图像之间的差异。
关键洞察: 对于幅度 (左) 和相位 (右) ,对抗性扰动造成的破坏随频率单调递增 。
- 低频 (图表左侧) : 差异接近于零。这意味着对抗性图像的总体结构、颜色和光照与原始图像几乎相同。
- 高频 (图表右侧) : 差异激增。这证实了对抗性噪声主要隐藏在高频细节 (像素值的快速变化) 中。
过度破坏的理论证明
虽然经验数据表明低频在对抗性图像中保持相对干净,但作者在理论上证明了标准的扩散净化会破坏所有内容。
他们推导了扩散过程中干净图像与噪声图像之间幅度差 (\(\Delta A_t\)) 和相位差 (\(\Delta \theta_t\)) 的方差。
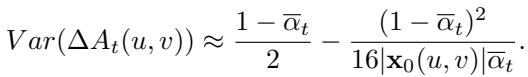
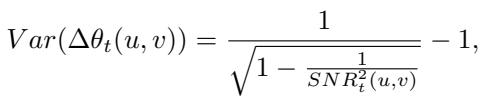
随着扩散时间步 \(t\) 的增加 (意味着我们添加更多噪声来净化图像) ,这两个方程中的方差都会增加。
这意味着什么? 这意味着基于标准扩散的净化不分青红皂白地破坏了低频信息——而图 1 显示这些信息实际上是安全的!通过盲目地扩散图像,传统方法破坏了图像的有效内容和结构,使得重建工作更加困难且不太准确。
核心方法: FreqPure
基于这些见解,研究人员提出了 FreqPure 。 其哲学很简单: 没坏就别修。
既然对抗性图像的低频分量基本上未受损伤,净化过程就应该明确地保留它们。FreqPure 干预反向扩散过程的每一步,利用输入的低频信息来“校正”估计的图像。
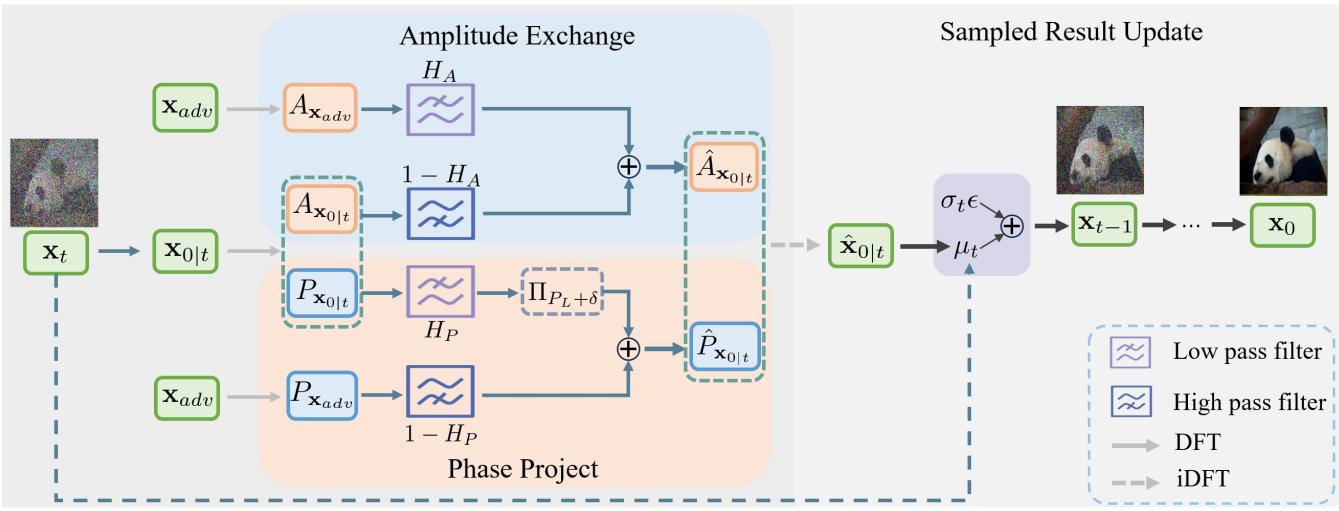
如图 2 所示,该流程是迭代进行的。在反向扩散的每个时间步:
- 模型从当前的噪声状态预测一个“干净”图像 \(\mathbf{x}_{0|t}\)。
- 该估计值通过 DFT 转换到频域。
- 发生两个并行操作: 幅度谱交换 (Amplitude Spectrum Exchange) 和 相位谱投影 (Phase Spectrum Projection) 。
- 校正后的频率分量通过逆 DFT (iDFT) 转换回空间域,以指导下一步采样。
让我们分解这两个核心机制。
1. 幅度谱交换 (ASE)
自然图像的幅度谱通常遵循幂律——低频包含大部分能量。实验表明,这些低频幅度对攻击具有很强的鲁棒性。
因此,作者构建了一个低通滤波掩码 \(H_A\)。该掩码在低频 (频谱中心) 为 1,在高频为 0。
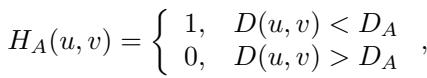
然后,他们通过将估计图像的幅度 (\(\hat{A}_{\mathbf{x}_{0|t}}\)) 与对抗性输入的幅度 (\(A_{\mathbf{x}_0}\)——注意在净化语境下,\(\mathbf{x}_0\) 指的是输入图像,即对抗性图像) 混合来更新幅度谱。
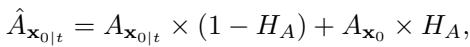
通俗地说: “取输入图像的低频幅度 (因为我们信任它) ,并将其与扩散模型估计的高频幅度 (因为输入的高频被破坏了) 相结合。”
2. 相位谱投影 (PSP)
相位谱比较棘手。它决定了结构 (物体在哪) 。虽然低频相位受攻击的影响比高频相位小,但它并非完全未受触动。直接复制对抗性图像的相位可能会泄漏一些对抗性模式或产生伪影,因为相位非常敏感。
作者没有直接交换,而是使用了投影 。 他们在对抗性输入的低频相位周围定义了一个“安全区域”。如果扩散模型估计的相位落在这个区域之外,它会被投影回该区域内。
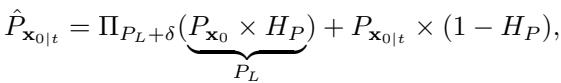
这里,\(\Pi\) 代表投影操作,\(\delta\) 定义了允许的变化范围。
通俗地说: “我们知道真实的结构与对抗性图像的低频结构比较接近。让扩散模型生成结构,但如果它偏离输入的低频相位太远,就把它推回来一点。”
这使得该方法能够从输入中提取粗粒度的结构信息,同时仍允许扩散模型修复细节。
实验与结果
研究人员在 CIFAR-10 和 ImageNet 基准数据集上,针对最先进的防御方法 (如 DiffPure, GDP, 和 AT) 评估了 FreqPure。他们使用了 PGD 和 AutoAttack 等强力攻击手段。
定量上的成功
结果非常有希望。该方法在标准准确率 (干净图像上的表现) 和鲁棒准确率 (受攻击图像上的表现) 方面均优于现有的净化技术。
CIFAR-10 结果
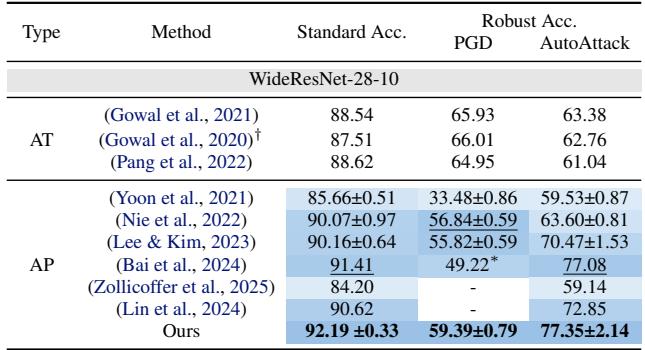
查看 表 1 (使用 WideResNet-28-10) :
- 标准准确率: FreqPure 达到 92.19% , 显着高于 DiffPure (90.07%),且与最佳对抗性训练方法相当。这证明保留低频确实保持了图像内容的完整性。
- 鲁棒准确率 (AutoAttack): 它达到了 77.35% , 优于标准的对抗性训练和其他净化方法。
ImageNet 结果
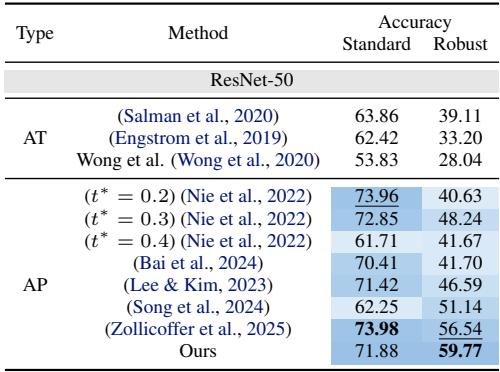
在更难的 ImageNet 数据集上( 表 6 ),差距进一步拉大。FreqPure 达到了 59.77% 的鲁棒准确率,而 DiffPure 根据噪声水平不同,仅在 40-48% 左右。这是一个巨大的提升,凸显了基于频率的方法的可扩展性。
定性分析: 眼见为实
数字固然重要,但在计算机视觉中,我们希望看到结果。净化后的图像实际上看起来像原图吗?

图 3 展示了原始干净图像、对抗性图像以及各种净化方法 (DiffPure, REAP 和 Ours/FreqPure) 输出之间的比较。
- DiffPure: 经常使图像模糊或引入色偏 (观察狐猴的毛发或鸟的羽毛) 。这就是破坏低频带来的“过度清洗”效应。
- FreqPure (Ours): 图像清晰,颜色鲜艳且与原图准确对应。狐猴的纹理和鸟身上的图案都得到了完美的保留。
相似度指标
为了量化“相似度”,作者使用了 DINO 和 CLIP 分数等先进的感知指标,这些指标衡量两张图像在语义上的相似程度。
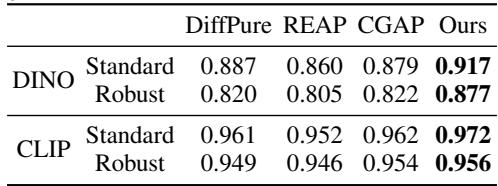
如 表 7 所示,FreqPure 在各项指标上都取得了最高的相似度分数。这在数学上证实了我们在图 3 中看到的: FreqPure 生成的图像最忠实于原始内容。
统计分布
最后,作者绘制了净化图像与原始图像的联合分布图。理想情况下,这些分布应该完全重叠。
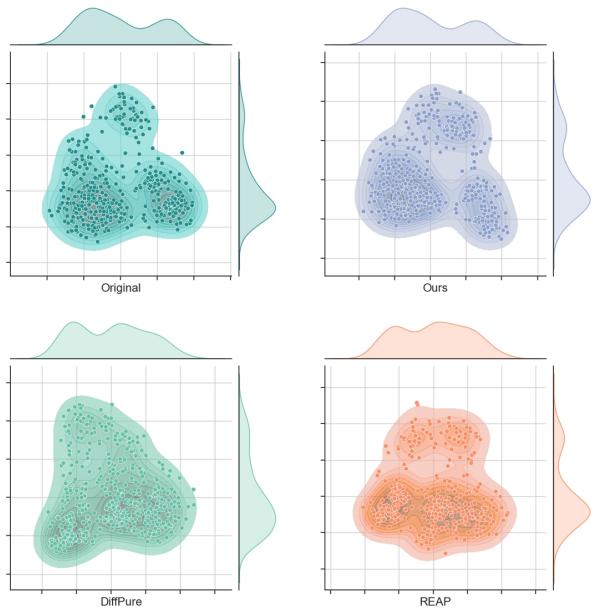
图 4 清楚地展示了这一点。“Ours” (右上) 的图显示分布紧凑,且结构上与“Original” (左上) 非常相似。相比之下,DiffPure (左下) 和 REAP (右下) 显示出更分散或偏移的分布,表明信息的丢失或伪影的引入。
结论与启示
论文 “Diffusion-based Adversarial Purification from the Perspective of the Frequency Domain” 为机器学习提供了一个令人信服的教训: 有时,从不同的角度 (字面意义上的频域) 观察数据,可以揭示复杂问题的简单解决方案。
通过认识到对抗性攻击不成比例地影响高频,作者指出了现有扩散防御的主要低效之处——它们正在破坏安全的低频数据。 FreqPure 方法通过在生成过程中充当频率选择性滤波器来解决这个问题。
关键要点:
- 对抗性噪声是高频的: 受攻击图像的内容和结构 (低频) 通常是值得信赖的。
- 标准扩散是不分青红皂白的: 它会随着时间推移侵蚀所有频率,降低准确性。
- 引导式净化行之有效: 通过交换幅度和在低频范围内投影相位,我们可以引导扩散模型恢复高频细节,而不会产生幻觉或模糊主体。
这项工作不仅为对抗性鲁棒性设立了新的基准,而且弥合了经典信号处理与现代生成式 AI 之间的鸿沟。它表明,鲁棒 AI 的未来可能在于结合神经网络的生成能力与频率分析的数学精度的混合方法。