](https://deep-paper.org/en/paper/2505.06892/images/cover.png)
引言
在机器学习领域,时间序列分类 (Time-Series Classification, TSC) 是一项普遍存在的挑战。从检测心电图信号中的心律失常,到识别智能手表的姿势,再到对机器人在不同表面上的运动进行分类,时间序列数据无处不在。
然而,从业者往往面临着一个艰难的权衡: 准确性 vs. 可解释性。
深度神经网络通常能提供最高的准确性,就像强大的“黑盒”一样,摄入数据并输出预测结果。但在医疗保健等关键领域,“黑盒”是不够的。医生需要知道模型为什么认为心跳是不规则的。这就是 Shapelets 发挥作用的地方。Shapelets 是特定的、具有判别力的子序列——数据中的微小“形状”——它们充当类别的签名。虽然解释性很强,但发现它们在计算上非常昂贵,而且传统方法为了节省时间,往往会丢弃大量潜在有用的上下文信息。
如果我们不必在丢弃数据的效率和保留数据的准确性之间做选择呢?
在这篇文章中,我们将探讨一篇新的研究论文 “Learning Soft Sparse Shapes for Efficient Time-Series Classification” (学习软稀疏形状以实现高效时间序列分类) , 该论文介绍了 SoftShape 。 该模型提出了一种新颖的“软”稀疏化机制。它不是无情地删除信息量较少的形状,而是智能地对其进行加权和融合,在保持效率的同时保留了至关重要的上下文。
让我们看一个研究人员提供的具体例子。
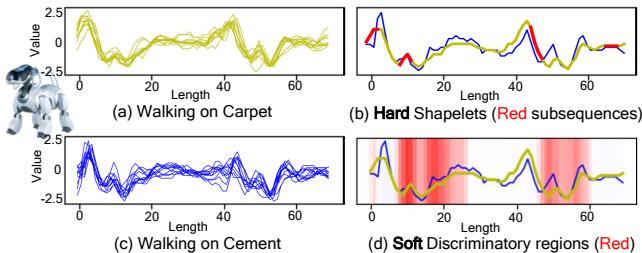
在上图中, (a) 和 (c) 显示了机器狗在地毯与水泥地上行走的原始传感器数据。传统的“硬” Shapelet 方法 (b) 将特定的红色子序列识别为重要部分,并忽略其余部分。然而,这错过了非红色区域中的细微模式。提出的 SoftShape 方法 (d) 用“软”的红色阴影突出了判别区域,捕捉到了关于“地毯”类别独特性的更丰富、更细致的视图。
问题: 微妙世界中的硬性决策
要理解 SoftShape,我们首先需要了解它所解决的局限性。
时间序列 \(\mathcal{X}\) 是按时间排序的数据点序列。 子序列是该序列的一个较小片段。如果特定的子序列 (如突然的尖峰或正弦波模式) 经常出现在 A 类中而不出现在 B 类中,它就是一个 Shapelet 。
传统上,识别 Shapelets 涉及暴力搜索或“硬性”选择过程:
- 提取所有可能的子序列。
- 根据它们区分出来的效果进行评分。
- 保留前 \(k\) 个 (最具判别力的) 。
- 丢弃其余部分。
这被称为 硬稀疏化 (Hard Sparsification) 。 理想情况下,这会给你留下一组小而高效的特征。实际上,它产生了两个问题:
- 信息丢失: “被拒绝”的子序列可能包含微弱但有用的信号,尤其是在上下文很重要的复杂分类中。
- 二元重要性: 一个子序列被视为要么“关键”要么“无用”,忽略了信号的某些部分是“稍微”重要的这一现实。
SoftShape 旨在用 软稀疏化 (Soft Sparsification) 取代这种硬性过滤。
SoftShape 架构
SoftShape 模型的设计旨在像人类专家阅读图表一样: 它专注于重要的尖峰 (判别形状) ,但仍然关注背景噪声 (融合的非判别形状) 以获取上下文。
这是高层架构图:
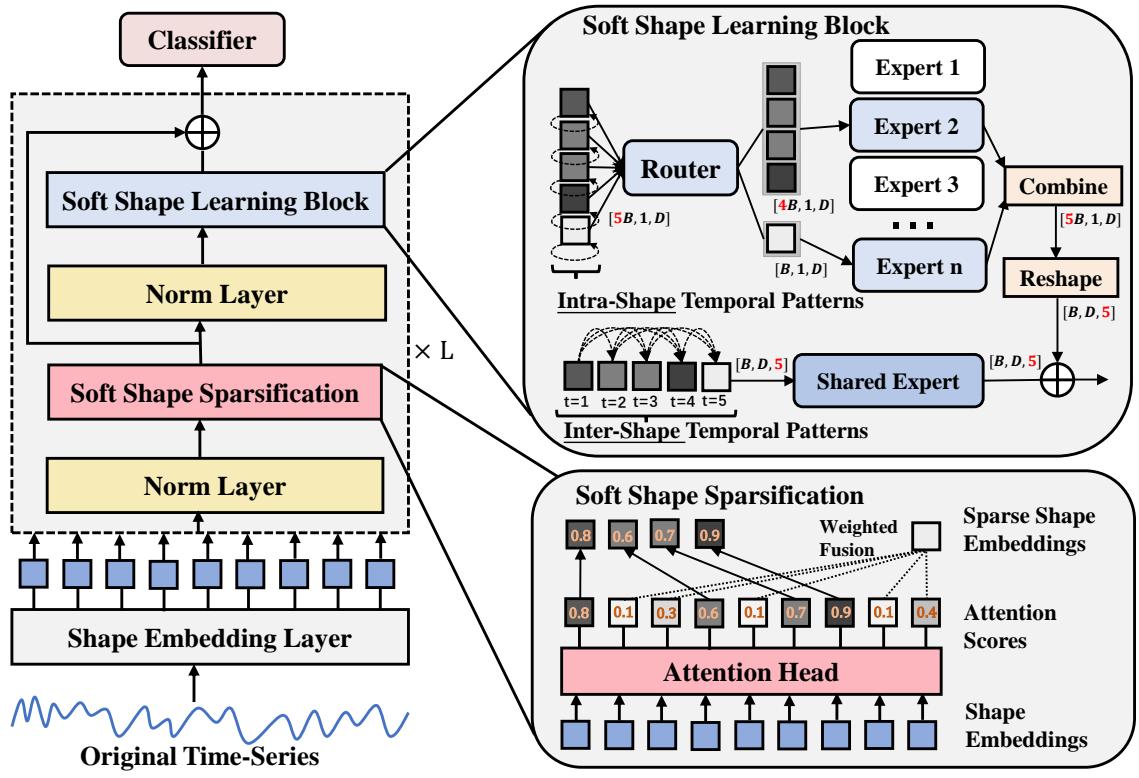
该模型由三个主要阶段组成:
- 形状嵌入 (Shape Embedding) : 将原始时间点转换为特征向量。
- 软形状稀疏化 (Soft Shape Sparsification) : 核心创新——对形状进行加权和融合。
- 软形状学习模块 (Soft Shape Learning Block) : 使用先进的神经组件来学习形状内部和形状之间的模式。
让我们逐步分解这些步骤。
1. 形状嵌入与注意力
首先,模型需要处理原始时间序列。它不查看单个时间点,而是查看重叠的窗口 (子序列) 。
所有可能子序列的集合 \(\mathcal{A}\) 在数学上定义为:
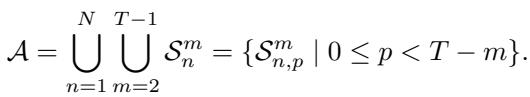
模型使用 一维卷积神经网络 (CNN) 将这些原始子序列转换为 形状嵌入 (Shape Embeddings) 。 时间序列的每个窗口都被转换为一个稠密向量 \(\hat{S}\)。
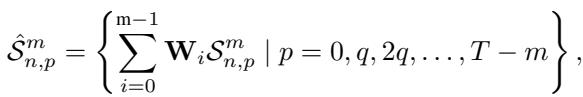
为形状评分
一旦我们有了这些形状嵌入,我们如何知道哪些是重要的?该模型采用了一个可学习的 注意力头 (Attention Head) 。 这是一个小型的神经网络层,它查看形状嵌入并输出一个介于 0 和 1 之间的分数 \(\alpha\)。接近 1 的分数意味着该形状具有高度判别力;接近 0 的分数意味着它可能是噪声或不相关的背景。
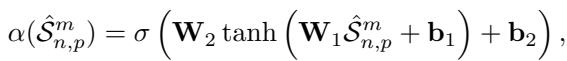
2. 软形状稀疏化: “加权融合”
这是 SoftShape 与传统方法分道扬镳的地方。SoftShape 不是设定阈值并删除其下的所有内容,而是执行 软分割 (Soft Split) 。
模型根据注意力分数对所有形状进行排名。然后定义一个比例 \(\eta\) (例如,前 50%) 。
对于前 \(\eta\) 个形状 (“明星”) : 这些形状保持独立。但是,它们会根据其注意力分数进行缩放。这强调了最有信心的预测。
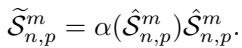
对于后 \((1-\eta)\) 个形状 (“背景”) : 在硬性方法中,这些会被删除。在 SoftShape 中,它们被 融合 。 模型计算所有这些低分形状的加权和,以创建一个单一的 融合形状 (Fused Shape) 。
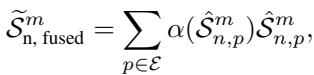
这产生了一个新的形状序列: 原始的高分形状 (经过缩放) ,加上 一个 代表其余所有聚合信息的单一形状。这显著降低了计算负载 (我们要处理的形状更少了) ,而又不会让模型完全忽视背景上下文。
3. 软形状学习模块
现在我们有了一组稀疏但信息丰富的形状,模型需要从中学习。研究人员引入了一个双路径学习模块,捕捉两种类型的模式: 形状内 (Intra-Shape) (单个形状内部的模式) 和 形状间 (Inter-Shape) (不同形状之间随时间变化的关系) 。
形状内学习: 混合专家模型 (MoE)
不同的形状代表不同的物理事件 (例如,“迈步”与“跌倒”) 。单个神经网络可能难以擅长分析所有这些事件。
SoftShape 使用了 混合专家模型 (Mixture of Experts, MoE) 。 这是一组小型、专业的网络 (“专家”) 。一个 路由器 (Router) 查看每个形状并决定哪个专家最适合处理它。
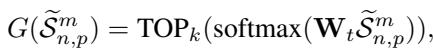
为了确保效率,路由器对于任何给定的形状只激活 Top-\(k\) 个专家 (通常只有 1 或 2 个) 。
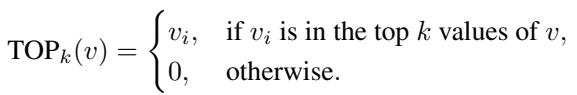
输出由选定的专家处理。这使得模型能够专业化——专家 A 可能非常擅长识别“上升斜坡”,而专家 B 专门研究“平坦高地”。
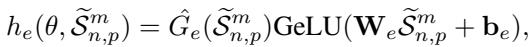
为了防止路由器变得“懒惰”并总是选择同一个专家 (这将导致其他专家未被训练) ,研究人员在训练期间包括了负载均衡损失函数:


形状间学习: 共享专家
虽然 MoE 孤立地查看形状,但时间序列数据是连续的。顺序很重要。为了捕捉这一点,模型将稀疏化后的形状重新组装成一个序列。
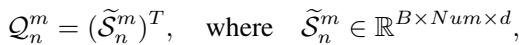
一个 共享专家 (Shared Expert) (实现为基于 Inception 的 CNN) 扫描这个序列。它基于形状随时间的演变来学习判别特征——捕捉单个 Shapelet 错过的全局时间模式。
4. 分类
最后,来自形状内和形状间路径的输出被组合在一起。模型通过聚合已处理形状的加权投票来计算最终的类别概率。
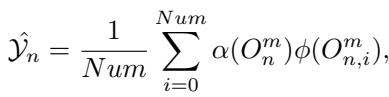
该模型使用总损失函数进行端到端训练,该函数结合了标准交叉熵损失 (用于准确性) 和辅助损失 (用于专家负载均衡) 。
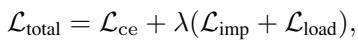
实验结果
这种“软”方法真的比“硬”选择或标准深度学习效果更好吗?研究人员在庞大的 UCR 时间序列归档 (128 个数据集) 上测试了 SoftShape。
准确性比较
结果令人信服。SoftShape 表现出优于各种基线的性能,包括 CNN、Transformer 和基础模型。
下面的临界差异图可视化了方法的统计排名。由水平线连接的方法在统计上没有差异,而越靠右的方法在统计上越优越。
SoftShape (最右侧) 实现了最佳的平均排名 (数值越低越好) ,显著优于 InceptionTime、PatchTST 和 RDST 等流行模型。
效率
“稀疏化”的主要承诺之一是效率。通过融合非必要形状,模型在深层处理的数据更少。
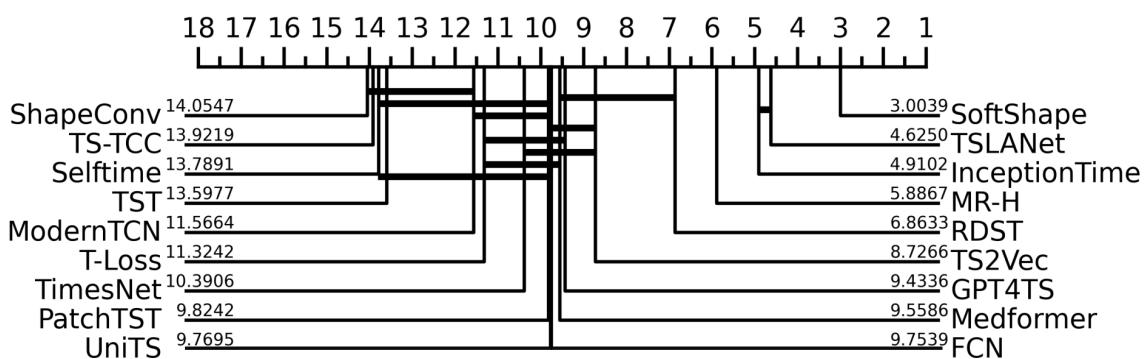
下图比较了 SoftShape 与其他深度学习模型在两个数据集 (ChlorineConcentration 和 HouseTwenty) 上的运行时间 (训练速度) 。
SoftShape (橙色条) 始终快于像 Medformer 这样沉重的 Transformer 模型,并且与 TSLANet 这样高效的 CNN 具有竞争力,特别是随着序列长度的增加 (图 3a 和 3b) 。
可解释性
我们能理解模型学到了什么吗?使用 多示例学习 (MIL) 可视化,研究人员绘制了 SoftShape 关注的时间序列部分。
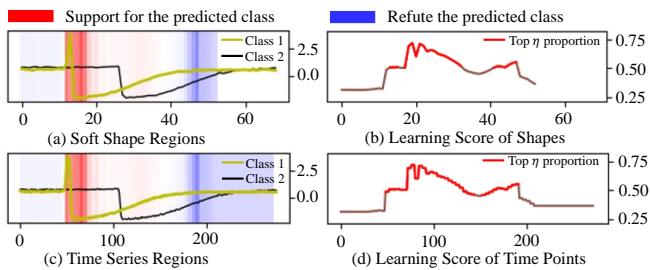
在 图 4(d) 中,红线代表“学习分数” (注意力) 。我们可以看到模型将高度注意力放在表征该类别的特定波峰和波谷上,而平坦的“噪声”区域得分较低。这证实了 SoftShape 成功识别了判别区域。
聚类能力 (t-SNE)
为了查看模型分离类别的效果,研究人员可视化了形状嵌入。
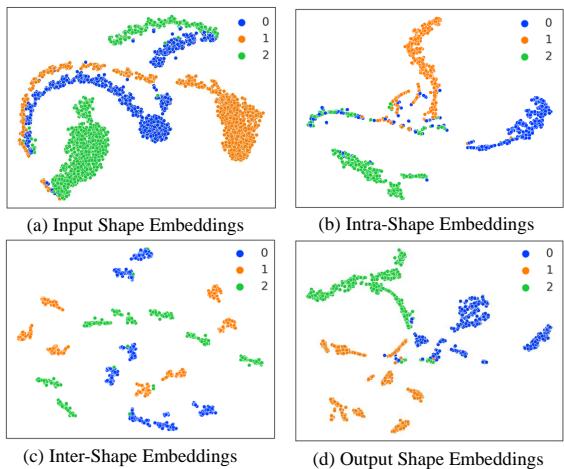
- (a) 输入: 原始形状嵌入杂乱且重叠。
- (b) 形状内: MoE 开始将相似的结构分组。
- (c) 形状间: 全局学习器分离出不同的时间模式。
- (d) 输出: 最终嵌入显示出与三个类别 (蓝色、橙色、绿色) 对应的清晰、分离良好的簇。这种清晰的分离使得线性分类器的最终分类任务变得容易得多。
每个部分都很重要吗? (消融实验)
研究人员对模型进行了精简,以查看哪些组件贡献最大。
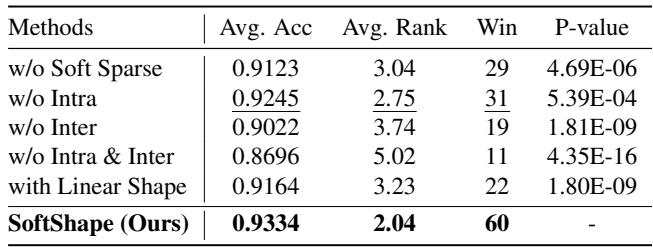
- w/o Soft Sparse: 移除软稀疏化 (改用硬选择) 导致准确率显著下降。
- w/o Intra / w/o Inter: 移除 MoE 或共享专家都会导致性能下降,证明局部形状专业化和全局序列建模都是必要的。
结论
SoftShape 模型代表了时间序列分类的一次智能演进。它解决了深度学习的“黑盒”问题,且没有牺牲现代应用所需的性能。
通过引入 软稀疏化 , 作者表明我们不需要为了效率而丢弃数据;我们只需要智能地压缩“无聊”的部分。此外,通过结合 形状内 MoE (专门的局部分析) 和 形状间学习 (全局序列分析) ,SoftShape 捕捉到了时间序列数据的全部复杂性。
对于学生和从业者来说,这篇论文强调了一个至关重要的教训: 我们如何表示数据 (嵌入和稀疏化) 往往与模型架构本身一样重要。
SoftShape 的代码已开源,为任何希望构建可解释、高效且准确的时间序列模型的人提供了新工具。