](https://deep-paper.org/en/paper/2505.07450/images/cover.png)
想象一下,你教一个智能系统识别不同类型的鸟。它掌握了知更鸟、麻雀和老鹰。然后,你教它关于鱼的知识——金枪鱼、鲑鱼和小丑鱼。但当你再次让它识别知更鸟时,它却茫然无措。它已经忘记了。这种现象被称为灾难性遗忘 (Catastrophic Forgetting, CF) , 是构建真正自适应人工智能的最大障碍之一。一个在新任务上训练的模型,往往会覆盖掉它从先前任务中学到的知识,实际上患上了一种“数字失忆症”。
要让AI在自动驾驶或个性化医疗等动态的真实世界环境中发挥作用,它必须能够在学习新任务的同时不丢弃旧知识。致力于解决这一问题的领域被称为持续学习 (Continual Learning, CL) 。
最近的一篇研究论文《用于持续学习的原型增强超网络》提出了一个名为PAH的创新框架,直面这一挑战。作者没有存储大量过去的数据或冻结部分网络,而是引入了一个系统,其中单个“主”网络可以按需生成任务特定的分类器头 。 诀窍是什么?它使用紧凑、可学习的原型 , 这些原型充当每个任务的记忆密钥。让我们来探究一下它是如何工作的。
挑战: 为什么神经网络会遗忘
为了理解PAH的贡献,我们首先需要了解是什么导致了神经网络的遗忘。
神经网络通过微调其内部参数——即权重——来最大化在特定任务上的性能。当在任务A上训练时,它调整权重以识别与任务A数据相关的模式。接下来,当学习任务B时,相同的权重会再次更新。新的调整覆盖旧的调整,从而抹去任务A的表示。这就是灾难性遗忘 。
研究人员提出了几种方法来缓解这一问题:
- 正则化方法: 增加惩罚项,阻止改变先前任务中至关重要的权重。
- 重放方法: 存储并重放部分旧数据 (“重放缓冲区”) ,提醒网络过去的知识——但这需要额外的内存。
- 基于架构的方法: 为新任务分配新的网络单元,防止覆盖,但会导致模型规模无限增长。
研究表明,灾难性遗忘通常发生在分类层 , 而不是特征提取器中。学习通用特征的深层网络往往保持稳定,而分类器中的任务特定层则容易退化。PAH正是在解决这种不稳定性方面表现突出。
PAH架构: 超网络与原型的结合
PAH整合了两个强大的概念: 超网络 (Hypernetworks) 和原型 (Prototypes) 。
- 超网络是一个神经网络,用于生成另一个网络 (称为主网络) 的权重。与其存储多个分类器头,超网络可以动态生成它们。
- 原型是类别的紧凑、可学习表示——在特征空间中捕捉“猫性”或“狗性”等本质的理想化特征。
在PAH中,超网络接收一组任务特定原型 , 并输出相应的分类器权重。单一生成器可以重建任何先前学习过的分类器头,无需为每个任务单独存储。
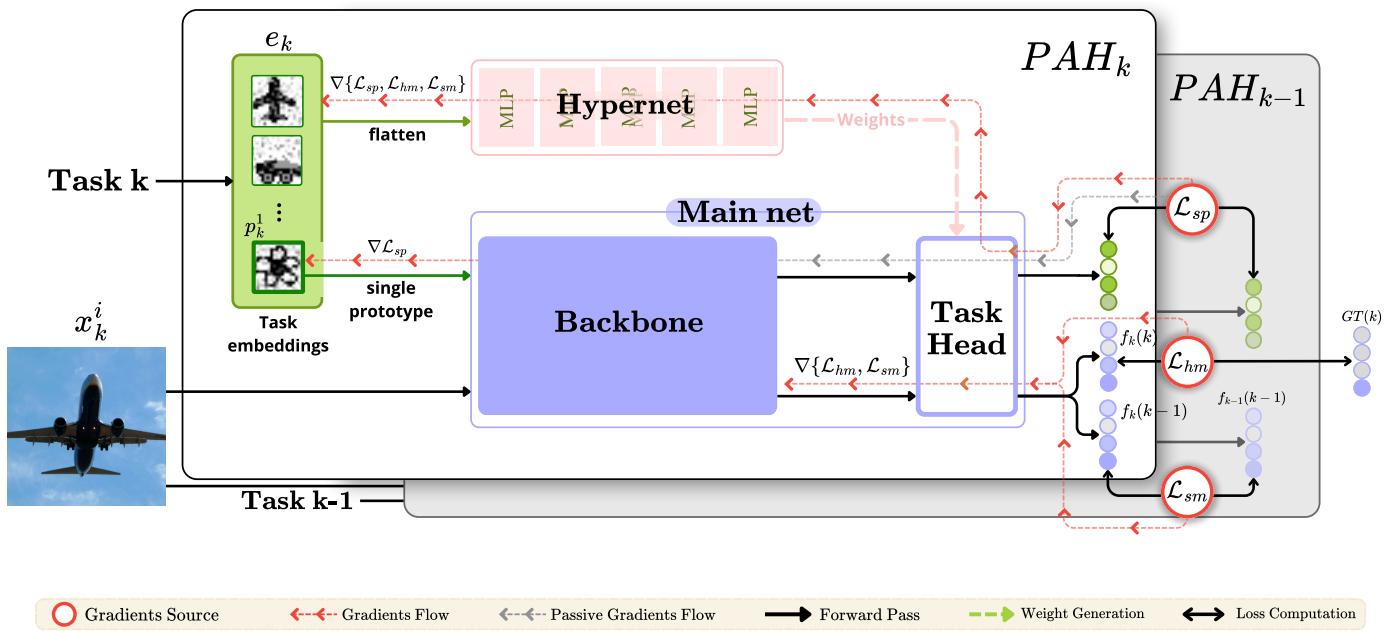
图 1. PAH架构概览。超网络以可学习的任务原型为条件,动态生成分类器权重。知识蒸馏有助于保留先前任务的信息。
1. 主网络: 学习特征
主网络包含两部分:
- 骨干网络 (\(\beta_{\theta}\)) : 特征提取器,如ResNet,将输入图像转换为特征向量。
- 任务特定头 (\(\tau\)) : 分类器,根据提取的特征预测类别标签。
PAH不为每个任务保留单独的分类器头,而是按需生成它们的权重:
\[ f_k(x_k \mid k) = \tau\left(\beta_{\theta}(x_k) \mid \theta_k^{\tau}\right) \]这使得内存使用保持低水平并保持灵活性。
2. 超网络: 按需生成权重
超网络 (\(\Upsilon\)) 充当“权重生成器”。对于每个任务 \(T_k\),它以任务嵌入 \(e_k\) 作为输入,并输出分类器权重:
\[ \theta_k^{\tau} = \Upsilon(e_k) \]如果超网络接收正确的任务描述符,它就能准确地重新生成任何任务头——无需存储它们。
3. 任务嵌入: 可学习的原型
任务嵌入 \(e_k\) 捕捉任务 \(T_k\) 的身份。PAH通过拼接一组可学习的类别原型来构建这个嵌入:
\[ e_k = \text{Flatten}\left(p_k^{1}, p_k^{2}, \ldots, p_k^{C}\right) \]每个原型 \(p_k^c\) 表示任务中的一个类别,通常是一个 \(10 \times 10\) 的特征网格。这些原型在训练过程中持续调整,编码了任务的关键信息。
原型的初始值不是随机噪声,而是通过对应类别的真实样本进行语义初始化——例如调整大小并归一化的样本图像。这种初始化简化了学习并提高了嵌入质量。
训练PAH: 三部分损失策略
为了在学习新任务的同时保留旧知识,PAH采用包含三个组件的综合损失: 一个用于分类,两个用于蒸馏。
1. 硬边界损失 (\(L_{hm}\))
标准交叉熵损失用于优化当前任务分类性能:
\[ L_{hm} = -\sum_{c=1}^{C} y_c \log \hat{y}_c \]它推动准确率的提升,并允许梯度更新骨干网络、超网络和当前原型。
2. 主网络软损失 (\(L_{sm}\))
一种知识蒸馏损失,用于保留旧任务行为。对于任务 \(T_k\) 中的每个样本 \(x_k\),PAH将前一个模型 (\(f_{k-1}\)) 与当前模型 (\(f_k\)) 的预测对齐:
\[ L_{sm} = \frac{1}{k-1} \sum_{j=1}^{k-1} \text{KL}(f_{k-1}(x_k \mid j) \parallel f_k(x_k \mid j)) \]这帮助新模型维持决策边界并稳定特征表示。
3. 原型软损失 (\(L_{sp}\))
这是微妙但至关重要的原型对齐损失。在 \(L_{hm}\) 更新骨干网络后,旧原型可能不再与新的特征空间匹配。\(L_{sp}\) 用于调整它们:
\[ L_{sp} = \frac{1}{k-1} \sum_{j=1}^{k-1} \sum_{c=1}^{C} \operatorname{KL}(f_{k-1}(p_j^c \mid j) \parallel f_k(p_j^c \mid j)) \]这一步中, 仅原型被更新,骨干网络和超网络被冻结。这样原型得以随网络演化而不引入不稳定。
总体训练目标为:
\[ L_{\text{total}} = L_{hm} + \lambda_{sm} L_{sm} + \lambda_{sp} L_{sp} \]它有效吗?实验验证
PAH在两个标准基准上进行了测试:
- Split-CIFAR100 : 100个类别被划分为10个任务。
- TinyImageNet : 200个类别被划分为10或20个任务。
性能通过平均准确率 (Average Accuracy, AA) 和遗忘度量 (Forgetting Metric, FM) 进行衡量,这两个指标量化了模型在多次更新后的任务保留度。
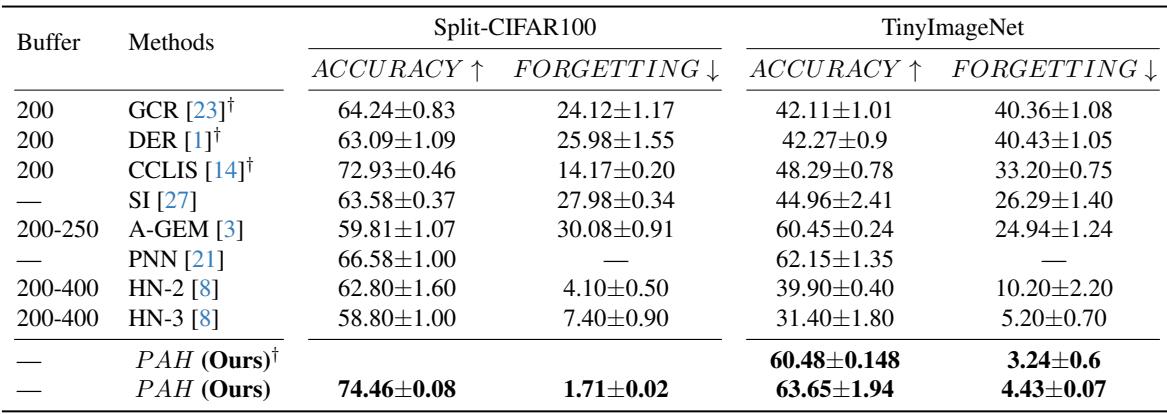
图 2. PAH与强基线模型在Split-CIFAR100和TinyImageNet上的对比。PAH在实现最高准确率的同时,遗忘极少。
基准测试结果
Split-CIFAR100: PAH达到了74.5%准确率和仅1.7%遗忘率——显著优于重放方法 (如DER: 63.1%准确率,26%遗忘率) 以及超网络替代方案 (如HN‑2: 62.8%准确率,4.1%遗忘率) 。
TinyImageNet: PAH实现了63.7%准确率和4.4%遗忘率 , 超过所有基线,包括那些存储大量样本的重放模型。即使不保留旧数据,PAH也能有效维持知识。
这些结果凸显了PAH在防止分类层遗忘方面的能力,而分类层通常是持续学习系统的瓶颈。
消融研究: PAH成功的关键是什么?
为了找出PAH成功的关键因素,作者进行了消融研究,分别调整原型形状、损失系数和初始化方法等。
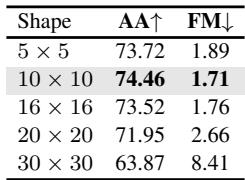
图 3. Split-CIFAR100上的消融研究结果。原型大小、稳定性系数和语义初始化显著影响性能。
主要发现:
- 原型形状很重要: \(10 \times 10\) 的网格在表达能力与计算效率之间取得了最佳平衡。较小原型缺乏细节,而较大原型则容易过拟合。
- 稳定性与可塑性平衡: 蒸馏损失的权重控制遗忘程度。系数为0.5时表现最佳。
- 自适应原型至关重要: 去掉 \(L_{sp}\) 会显著降低性能,证明原型自适应性至关重要。
- 语义初始化有帮助: 使用真实图像进行初始化比随机噪声更有效,提升了准确率 (74.46%对72.54%) 并降低遗忘率 (1.71%对2.32%) 。
总体来说,这些结果说明可学习、语义初始化的原型结合精准的超网络条件,是PAH高效表现的基石。
结论: 迈向AI的终身学习
灾难性遗忘仍是人工智能面临的最大挑战之一。原型增强超网络 (PAH) 提供了一个优雅、可扩展的解决方案。通过让超网络生成任务特定分类器头,结合可学习原型及双重蒸馏损失,PAH在无需扩大模型规模或依赖重放缓冲区的情况下实现了最先进的表现。
主要要点:
- 动态分类器生成: 无需存储任务头——权重可按需生成。
- 原型作为记忆密钥: 可学习的原型高效编码任务特定上下文。
- 双重蒸馏: 分别稳定骨干特征与任务原型,最大限度减少遗忘。
PAH证明了持续学习可以兼具实用性、内存效率和极低遗忘率。它是迈向具备自适应、终身学习能力的AI系统的重要一步——让系统能像人类一样记忆、进化与成长。