](https://deep-paper.org/en/paper/2505.17928/images/cover.png)
代码审查是软件质量的守门员。在一个完美的世界里,每一行代码在合并之前,都会有一位高级工程师仔细检查,捕捉细微的逻辑错误、安全漏洞和潜在的性能瓶颈。
但在现实世界中,代码审查往往是一个瓶颈。审查人员工作繁忙,上下文难以获取,有时候“LGTM” (看起来不错,Looks Good To Me) 敲得稍微快了点。
这种情况推动了自动化代码审查研究的激增。如果 AI 能写代码,那它肯定也能审查代码吧?然而,大多数现有工具都陷入了一个陷阱: 它们将代码审查视为简单的翻译任务。它们查阅一小段代码,然后试图生成一句“听起来”像审查意见的话。结果呢?充满了关于变量命名或格式的“细枝末节 (nitpicks) ”,而关键的 Bug (如空指针解引用或逻辑错误) 却被漏掉了。
今天,我们将深入探讨一篇题为 “Towards Practical Defect-Focused Automated Code Review” (面向实用的缺陷聚焦型自动化代码审查) 的论文。这项研究超越了简单的文本生成。它详细介绍了一个部署在一家拥有 4 亿日活跃用户的大型科技公司的系统,该系统的设计目的只有一个: 发现真正的缺陷。
我们将探讨作者如何从“代码片段级”的猜测转向“仓库级”的推理,利用代码切片、多角色 LLM 智能体和严格的过滤流水线等先进技术。
核心问题: 为什么当前的 AI 审查工具会失败
要理解这篇论文的重要性,我们需要先了解现状的局限性。
大多数学术研究将自动化代码审查视为一个 代码到文本 (Code-to-Text) 的问题。你给模型输入一个“Diff” (旧代码和新代码之间的差异) ,模型预测一段文本序列 (评论) 。这些模型通常使用 BLEU 分数 来评估——这是机器翻译中借用的指标,用于衡量生成文本与“参考”文本的重叠程度。
这种方法有三个致命缺陷:
- 上下文短视 (Context Myopia) : 标准的“Diff”只显示变化的内容。它不会显示变量是在三个文件之外定义的,或者函数在其他地方是如何被使用的。没有这些上下文,发现深层逻辑错误是不可能的。
- 过度吹毛求疵 (Nitpick Overload) : 由于模型是在所有历史数据上训练的,它们学会了复制最常见的评论: 风格建议。它们会产生幻觉,或者抱怨无关紧要的事情 (误报) 。
- 错误的评估指标 (Wrong Metrics) : 像“请修复这个逻辑”这样的通用评论可能会得到很高的 BLEU 分数,因为它与参考词匹配,即使它没有提供具体的帮助。相反,一个精彩的、新颖的 Bug 发现可能会因为不在参考集中而得零分。
该论文的作者认为,目标不应该是“文本相似性”。目标应该是 缺陷检测 (Defect Detection) 。
现实世界的流水线
研究人员将他们的系统集成到了工业级的 DevOps 平台中。这不仅仅是一个理论模型;它直接位于开发人员提交合并请求 (MR) 和代码被合并之间的工作流中。
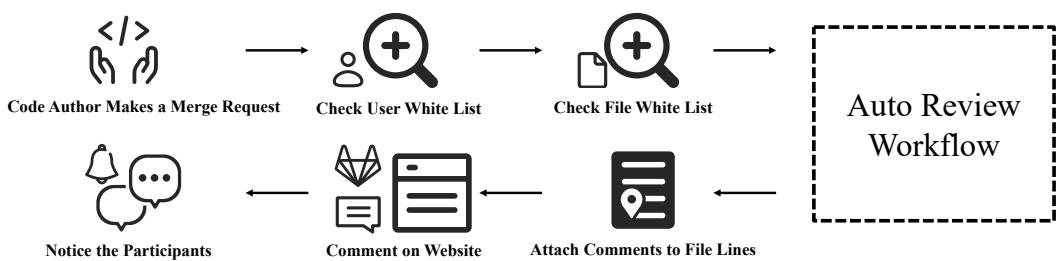
如 图 1 所示,该流水线由合并请求触发。它检查权限,运行自动审查工作流,将评论附加到特定的代码行,并通知参与者。
但是,那个标有“自动审查工作流 (Auto Review Workflow) ”的虚线框内发生了什么?这才是创新所在。作者确定了四个主要挑战,并为每个挑战提出了解决方案:
- 上下文: 如何在不超出 Token 限制的情况下为 LLM 提供正确的代码?( 解决方案: 代码切片 )
- 准确性: 如何发现关键 Bug?( 解决方案: 多角色系统 )
- 噪音: 当 AI 变得烦人时,如何让它闭嘴?( 解决方案: 过滤机制 )
- 可用性: 开发人员如何知道 Bug 在哪里?( 解决方案: 行定位 )
让我们分解一下架构。
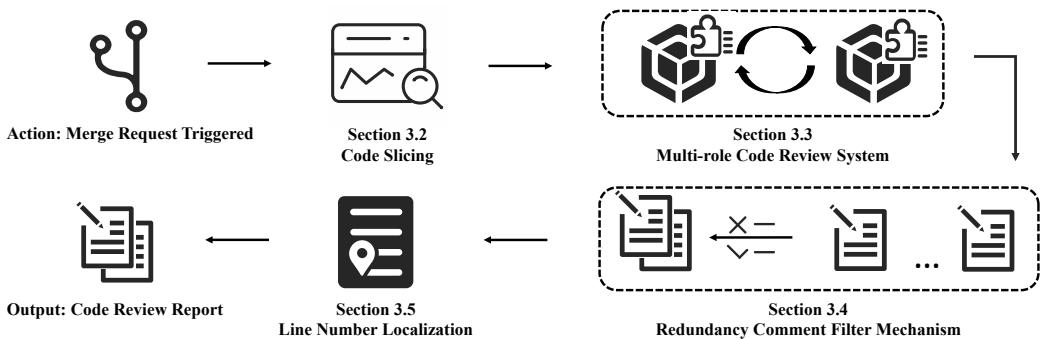
图 2 提供了高层路线图。系统接收合并请求,对代码进行切片,将其传递给一组 LLM 智能体,过滤结果,最后将评论固定到确切的行号上。
第一步: 代码切片 (解决上下文问题)
如果你把整个代码仓库都喂给 LLM,你会耗尽上下文窗口 (和预算) 。如果你只喂给它变更的行,它就缺乏发现 Bug 的信息。折衷方案是 代码切片 (Code Slicing) 。
作者提出了四种不同的切片算法来收集上下文。可以把这些看作 AI 观察代码的不同“透镜”:
- 原始 Diff (Original Diff) : 基准。只是原始的变更。对语法错误有效,对逻辑错误效果不佳。
- 父函数 (Parent Function) : 包含发生变更的整个函数。这有助于 AI 理解直接的局部逻辑。
- 左值流 (Left Flow) : 这里开始变得有趣了。该算法执行静态分析以跟踪“左值” (被赋值的变量) 。它向 后 查找这些变量的来源以及它们是如何定义的。
- 全流 (Full Flow) : 最全面的方法。它向后跟踪 (变量从哪里来) 并向 前 跟踪 (变量稍后如何被使用,包括函数调用) 。
为什么这很重要? 想象一下你修改了 x = y + 1。
- 原始 Diff 只看到这一行。
- 全流 看到
y是一个指针,可能为空 (定义在 50 行上面) ,而x稍后用于除法 (潜在的除以零风险) 。这种上下文就是吹毛求疵和捕捉 Bug 之间的区别。
第二步: 多角色代码审查系统
对于复杂的推理,仅靠一个提示 (Prompt) 往往是不够的。受“智能体 (Agent) ”工作流的启发,作者设计了一个 多角色系统 。 他们没有要求一个 AI “审查这段代码”,而是将特定角色分配给模型的不同实例。

如 图 3 所示,工作流涉及协作:
- 审查员 (The Reviewer) : 该智能体查看切片代码并使用 思维链 (Chain-of-Thought, CoT) 推理。它被要求:
- 理解 变更。
- 分析 缺陷。
- 重新评估 以检查是否在吹毛求疵。
- 输出评论草稿。
- *注意: * 系统可以生成多个审查员以获得不同的视角。
元审查员 (The Meta-Reviewer) : 如果你有多个审查员,他们的工作可能会重复。元审查员充当经理的角色。它汇总评论,合并重复项,并按严重程度排序。
验证员 (The Validator) : 这是质量控制关卡。它获取合并后的评论和代码,并提出一个关键问题: “这条评论真的正确吗?” 它对问题重新评分,以过滤掉幻觉 (虚假 Bug) 。
翻译员 (The Translator) : 最后,对于跨国团队,此角色确保评论使用正确的语言,并格式化为 JSON 以供系统读取。
第三步: 过滤机制 (消除噪音)
关于 AI 工具的一个主要抱怨是 误报率 (False Alarm Rate, FAR) 。 如果一个 AI 警告你 10 件事,其中 9 件是错的,即使第 10 件是严重的安全漏洞,你也会忽略它。
为了解决这个问题,审查员和验证员智能体会给每条潜在评论打三个分 (1-7 分) :
- Q1: 吹毛求疵得分 (Nitpick Score) : 这只是风格建议吗? (高分 = 是) 。
- Q2: 伪问题得分 (Fake Problem Score) : 这是幻觉吗? (高分 = 是) 。
- Q3: 严重程度得分 (Severity Score) : 这是一个关键 Bug 吗? (高分 = 是) 。
系统通过审查员应用 粗略过滤器 (Coarse Filter) (丢弃具有高吹毛求疵/伪问题得分的评论) ,然后通过元审查员和验证员应用 精细过滤器 (Fine Filter) 。 这确保了只有系统确信严重的问题才会传达给开发人员。
第四步: 行号定位
听起来很简单,但告诉开发人员评论属于 哪里 却很难。代码变更导致的行号偏移会混淆 LLM。
作者使用了一种特定的“内联”格式化策略。他们不仅仅给出代码,还明确地对行进行编号,并用 +、- 或空格 (保留) 标记变更。
如 表 1 所示,这种格式帮助 LLM “看到”代码的确切位置,显著提高了 行定位成功率 (Line Localization Success Rate, LSR) 。
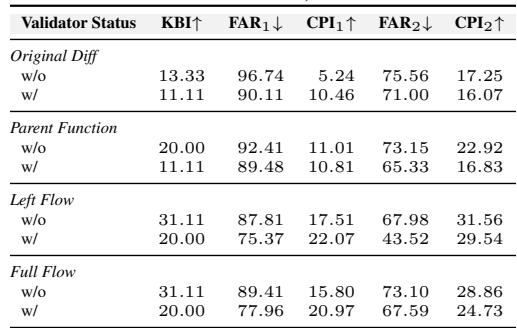
实验设置与指标
研究人员没有使用标准的开源数据集 (通常只是代码片段) 。他们挖掘了公司的 故障报告 (Fault Reports) 。 这些是导致生产事故 (金钱损失、崩溃) 的实际 Bug 的历史记录。他们将这些 Bug 追溯到原始的合并请求,看看 AI 是否能捕捉到它们。
评估指标
由于 BLEU 在这里毫无用处,他们定义了新的指标:
1. 关键 Bug 包含率 (Key Bug Inclusion, KBI) :
\[ { \mathrm { K B I } } = { \frac { \mathrm { N u m b e r ~ o f ~ r e c a l l e d ~ k e y ~ i s s u e s } } { \mathrm { T o t a l ~ n u m b e r ~ o f ~ k e y ~ i s s u e s } } } \times 1 0 0 \]简单来说: AI 发现那个导致崩溃的 Bug 了吗?
2. 误报率 (False Alarm Rate, FAR) :
\[ F A R _ { 1 } = \frac { 1 } { N } \sum _ { i = 1 } ^ { N } \left( \frac { \mathrm { N u m b e r ~ o f ~ f a l s e ~ a l a r m ~ c o m m e n t s ~ i n ~ M R } _ { i } } { \mathrm { T o t a l ~ n u m b e r ~ o f ~ c o m m e n t s ~ i n ~ M R } _ { i } } \times 1 0 0 \right) \]简单来说: AI 的评论中有百分之多少是无用的垃圾?
3. 综合性能指数 (Comprehensive Performance Index, CPI) :
\[ \mathrm { C P I } _ { 1 } = 2 \times \frac { \mathrm { K B I } \times ( 1 0 0 \mathrm { - F A R _ { 1 } } ) } { \mathrm { K B I } + ( 1 0 0 \mathrm { - F A R _ { 1 } } ) } \]这就像 F1 分数。它平衡了发现 Bug (KBI) 和保持安静 (FAR) 。
结果: 它有效吗?
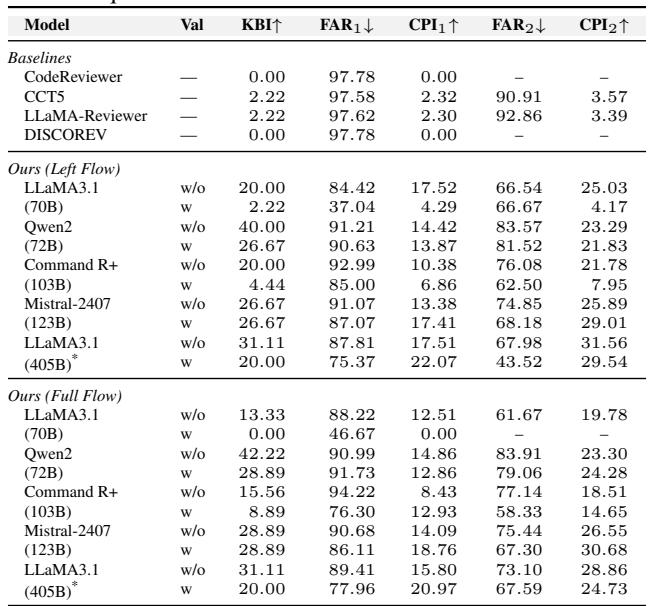
简短的回答是: 有效。该系统的表现显著优于现有的基线模型 (如 CodeReviewer 和 LLaMA-Reviewer) 。
下方的 表 2 展示了对比结果。请看 CPI1 列 (综合性能) 。基线模型的得分在 0.00 到 2.32 之间。而当使用 LLaMA3.1 (70B/405B) 时,本文提出的框架 (Ours) 得分高达 22.07 。
结果亮点 1: 切片至关重要
团队比较了四种切片算法。 表 3 揭示了明显的赢家。

左值流 (Left Flow) 和 全流 (Full Flow) 算法 (跟踪变量定义的算法) 实现的 KBI 和 CPI 显著高于简单的“原始 Diff”或“父函数”方法。这证明了 上下文为王 。 如果你不知道数据从哪里来,你就无法有效地审查代码。
有趣的是,观察发现的 Bug 的重叠情况 (图 4) ,不同的切片方法捕捉到了不同的 Bug。
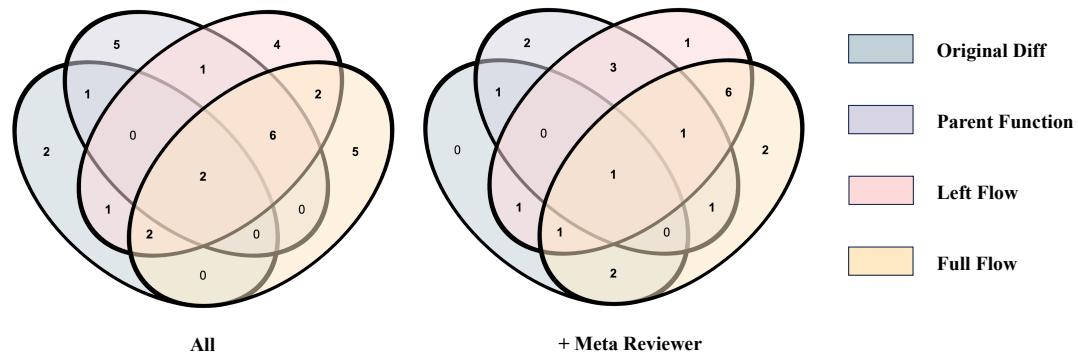
虽然基于流的方法 (Left/Full) 捕捉得最多,但也有些独特的 Bug 只有 父函数或原始 Diff 方法捕捉到了。这表明混合方法可能是最终的解决方案。
结果亮点 2: 角色的权衡
增加更多的审查员有助于发现更多的 Bug,但也会增加噪音。这就是 验证员 角色大放异彩的地方。
在 表 5 中,比较有验证员和无验证员的行 (w/ vs w/o) 。
- 无验证员: 高 KBI (发现很多 Bug) ,但高 FAR (大量噪音) 。
- 有验证员: FAR 显著下降。KBI 略有下降 (一些真正的 Bug 被过滤掉了) ,但整体 实用性 (CPI) 通常保持在较高水平或稳定性有所提高。验证员充当了必要的过滤器,防止开发人员因沮丧而关闭工具。
结论: 自动化审查的未来
这篇论文代表了我们对软件工程中 AI 思考方式的转变。我们正在从将代码视为待翻译的“自然语言”,转向将其视为需要上下文和推理的结构化逻辑系统。
对学生和从业者的主要启示是:
- 上下文不可或缺: 简单的 Diff 是不够的。需要静态分析 (代码切片) 来为 LLM 提供它们所需的信息。
- 专业分工致胜: 将任务分解为不同角色 (审查员、验证员) 比单一的巨大提示效果更好。
- 优化精确度: 在现实世界中,低误报率比高召回率更重要。如果 AI 惹恼了开发人员,它就会被忽略。
通过将传统的静态分析 (切片) 与现代 LLM 的推理能力相结合,该框架为 AI 铺平了道路——它不再仅仅是对你的变量命名吹毛求疵,而是真正阻止下一次生产事故的发生。