](https://deep-paper.org/en/paper/2505.22939/images/cover.png)
引言
在传统的民主进程中,选项菜单通常是固定的。你把票投给候选人 A 或候选人 B;你在政策 X 或政策 Y 之间做出选择。但是,如果目标不仅仅是从预定义的列表中进行选择,而是要将成千上万人的复杂、非结构化的观点综合成一组连贯且具有代表性的陈述,那该怎么办?
这就是生成式社会选择 (Generative Social Choice) 所面临的挑战。
想象一下有一场 10,000 名居民参加的市政厅会议。让每个人都发言是不可能的,让人类主持人手动总结每一个不同的观点而不带偏见同样困难。最近,研究人员转向大语言模型 (LLM) 来解决这个问题。像 Polis 这样的系统已经在台湾以及联合国被用于对观点进行聚类。然而,从“聚类”迈向数学上严谨的代表性陈述选择是一个难题。
现有的生成式社会选择框架已经显示出了希望,但它们依赖于两个危险的假设:
- 一致性: 它们假设所有陈述都是平等的 (长度相同,复杂性相同) 。
- 完美性: 它们假设 AI 能完美地理解人类的偏好。
在现实世界中,注意力是一种稀缺资源 (一种“预算”) ,而且 LLM 会产生幻觉或误判偏好 (它们是“近似的”) 。
在这篇文章中,我们将深入探讨 Boehmer、Fish 和 Procaccia 的论文 “Generative Social Choice: The Next Generation” 。 我们将探索他们如何升级 AI 辅助民主的理论框架,以处理成本限制和 AI 误差,并最终推出一个名为 PROSE 的新引擎,该引擎可以消化原始用户评论并输出一组可证明具有代表性的观点列表。
背景: 从选举到生成
要理解这篇论文的贡献,我们必须首先立足于计算社会选择 (Computational Social Choice) 。
委员会选举与参与式预算
经典地,如果我们想选出一个由 \(k\) 名代表组成的委员会,我们会寻找一个最能代表选民的候选人子集。如果我们加入“成本”因素——即不同的候选人花费不同数量的资金——我们就进入了参与式预算 (Participatory Budgeting, PB) 的领域。在 PB 中,一个城市可能会让选民决定如何花费 100 万美元。一个公园花费 50 万美元;一条自行车道花费 10 万美元。目标是选择一束既尊重预算又能最大化选民满意度的项目。
生成式的转变
在生成式社会选择中,“候选人”不是人或预定义的项目。候选人是语言中所有可能的陈述。
因为这个“陈述全集”是无限的,我们不能简单地将它们列在选票上。我们需要一种机制来:
- 生成可能吸引选民群体的候选陈述。
- 评估 (判别) 特定选民对特定陈述的喜爱程度。
Fish 等人 (2024) 提出了一个两步框架,利用 LLM 来执行这些查询任务。然而,他们的模型是僵化的。它要求固定数量的陈述 (例如,“生成正好 5 个陈述”) ,忽略了这样一个事实: 一个长而微妙的陈述可能抵得上两个短而有力的陈述。此外,如果 LLM 在预测用户幸福感方面不是 100% 准确,他们的数学推导就会崩溃。
这项新工作弥合了抽象理论与 AI 部署的混乱现实之间的鸿沟。
核心方法: 预算与近似查询
作者提出了一种新的民主程序,该程序考虑了预算 (例如,最终报告的总字数限制) 和误差 (LLM 可能会出错) 。
1. 模型
我们假设有一组代理人 \(N\) (选民) 和一个预算 \(B\)。陈述的全集 \(\mathcal{U}\) 是未知的。每个陈述 \(\alpha\) 都有一个成本 \(c(\alpha)\) (即其长度) 。
每个代理人 \(i\) 都有一个效用函数 \(u_i(\alpha)\),决定了他们对陈述的同意程度。然而,因为我们不能向每个用户询问英语语言中每一个可能的句子,我们依赖于查询 (Queries) 。
2. 查询 (及其误差)
这篇论文的核心在于形式化了我们如何与 LLM 交互。作者定义了两种特定类型的查询。至关重要的是,他们对这些查询可能产生的误差进行了建模。
判别式查询 (Discriminative Query)
此查询预测用户的效用。
- 理想情况: \(DISC(i, \alpha) = u_i(\alpha)\)
- 近似情况: LLM 是 \(\beta\)-准确的。它返回一个在真值 \(\pm \beta\) 范围内的值。
生成式查询 (Generative Query)
这是重头戏。我们给 LLM 一组代理人 \(S\)、一个目标效用水平 \(\ell\) 和一个成本限制 \(x\)。我们要问: “写一个成本不超过 \(x\) 的陈述,使得群体 \(S\) 中在水平 \(\ell\) 上批准该陈述的人数最多。”
因为 LLM 是概率性的,它们可能会在三个方面失败:
- 支持者数量 (\(\gamma\)): 它找到的陈述的支持者可能比最佳陈述少 (乘性误差) 。
- 成本 (\(\mu\)): 它可能会高估预算,实际上在一个更小的空间内搜索 (乘性误差) 。
- 效用 (\(\delta\)): 生成的陈述可能比要求的稍微不那么受欢迎 (加性误差) 。
在数学上,作者使用这些参数定义了一个近似生成式查询。
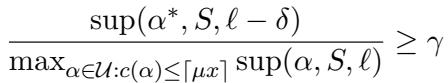
如上式所示,该查询保证返回的陈述相对于真正的最佳陈述是“足够好”的,并在我们的误差参数 \(\gamma\)、\(\delta\) 和 \(\mu\) 下打折。如果 \(\gamma=1, \mu=1, \delta=0\),我们就拥有了一个完美的查询。
3. 公理: 成本平衡的合理代表性 (cBJR)
我们如何知道最终的陈述列表是否“公平”?作者采用了社会选择理论中的一个概念,称为平衡的合理代表性 (Balanced Justified Representation, BJR) 。
直观地说, cBJR 指出:
如果一群选民足够大,能够利用他们的预算份额“负担”得起一份陈述,并且存在一份他们都同意的陈述,那么他们必须在最终列表中由他们喜欢的 (至少在一定程度上) 东西来代表。
如果一个群体占人口的 20%,他们本质上控制着 20% 的字数预算。如果他们意见一致 (他们都在某个话题上达成共识) ,算法就不能忽略他们。
4. 算法: DemocraticProcess
研究人员介绍了一种名为 DemocraticProcess 的算法。这是一种贪婪的迭代方法,旨在即使在查询不完美的情况下也能满足 cBJR。
它是如何工作的:
- 初始化: 从完整的代理人集合 \(S\) 和一个空列表开始。
- 迭代效用: 开始请求具有尽可能高支持率的陈述 (例如,“强烈同意”) 。逐渐降低标准到“同意”,然后是“中立”。
- 迭代成本: 对于每个支持水平,检查不同的陈述长度 (成本) 。
- 贪婪选择:
- 调用生成式查询以找到剩余代理人 \(S\) 的一个子集所喜欢的陈述 \(\alpha^*\)。
- 检查群体 \(S_{\alpha^*}\) (支持者) 是否足够大,能够利用他们的预算份额“支付”该陈述 (\(|S_{\alpha^*}| \ge \lceil c(\alpha^*) \cdot n / B \rceil\)) 。
- 如果是,将该陈述添加到列表中。
- 从集合 \(S\) 中移除支持者 (他们现在已被代表) 。
- 重复直到预算已满或所有人即被代表。
理论保证
作者证明了该算法提供了一个特定的保证: \((\dots)\)-cBJR 。 保证中的具体数值取决于 LLM 的误差。
如果 LLM 产生误差 (\(\beta, \gamma, \delta, \mu\)) ,结果的公平性会优雅地降级。论文证明,虽然没有算法能完美克服这些误差,但 DemocraticProcess 非常接近理论极限。
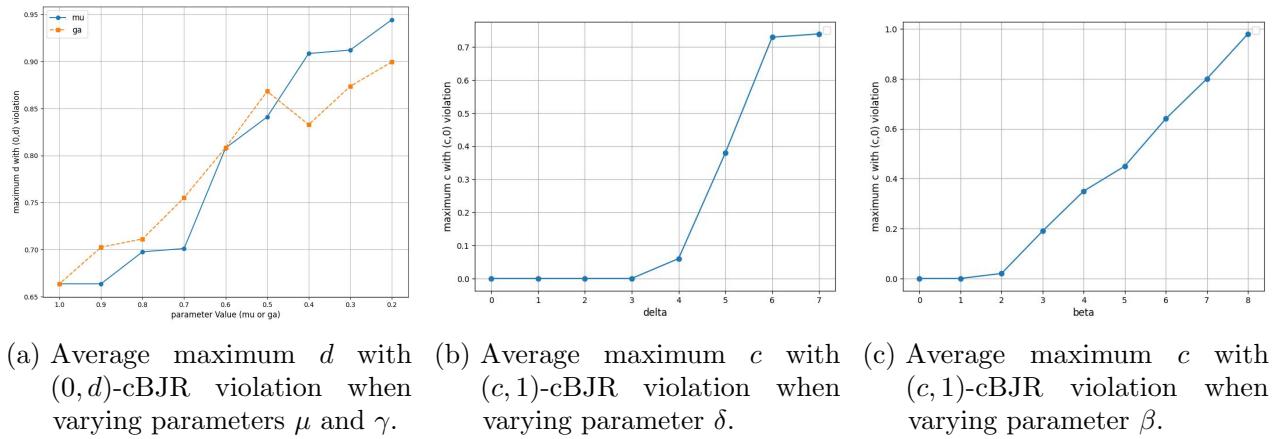
上图展示了这种降级。随着误差参数 (如判别准确度的 \(\beta\) 或成本准确度的 \(\mu\)) 增加,比例性的“违规”也随之增加。然而,他们算法的复杂版本 (搜索完整的成本空间) 即使在简单的基线失效后,仍能保持稳健。
实现: 介绍 PROSE
理论很有用,但它能在实际文本上工作吗?作者构建了 PROSE (Proportional Slate Engine,比例列表引擎) ,这是他们算法的一个使用 GPT-4o 的实用实现。
处理非结构化数据
与以前要求用户对特定调查进行投票的系统不同,PROSE 接受非结构化文本 (例如论坛上的评论、评论) 和一个总字数预算。
实现查询
- 判别式: 他们提示 GPT-4o 充当用户的代理。他们将用户过去的评论和新陈述输入模型,要求其在 1-6 的范围内对一致性进行评分。他们甚至校准了“具体性”,以防止模型偏爱模糊的星座运势式废话 (适用于所有人但言之无物的陈述) 。
- 生成式: 这更难。他们使用两步流程:
- 聚类/嵌入: 使用向量嵌入找到在观点空间中彼此接近的“意见一致”的用户群体。
- 起草: 将该特定聚类的评论输入 GPT-4o,并要求其在特定字数限制内撰写共识陈述。
实验与结果
作者在两个截然不同的领域测试了 PROSE:
- 药物评论: 用户评论避孕药和减肥药 (意见方差大,存在明显的亚群体) 。
- 公民参与: 来自肯塔基州鲍灵格林关于城市改善规划的“Polis”数据集。
他们将 PROSE 与几个基线进行了比较:
- 聚类 (Clustering): 标准的观点 K-means 聚类。
- 零样本 (Zero-Shot): 仅仅要求 GPT-4o,“写一个这些观点的总结。”
- PROSE-UnitCost: 忽略陈述长度的引擎版本 (将每个陈述的成本视为 1) 。
定量上的成功
为了评估结果,他们使用了一个“思维链” (CoT) 评估器——一个更昂贵、更慢且更严格的 LLM 提示——来评判最终的列表。这确保了他们不会用生成作业的同一个提示来批改作业。
结果非常显著。

如上表所示, PROSE (第一行) 在用户的平均效用方面始终得分最高。也许更重要的是,看看 Q1 (第 25 百分位) 或“第 10 百分位”指标 (通常作为少数群体代表性的代理) 。PROSE 显著优于“零样本”和“聚类”基线。
这证实了理论假设: 简单地要求 LLM 进行“总结” (零样本) 往往会清洗掉少数人的观点以支持多数人。通过使用贪婪、迭代的 DemocraticProcess,PROSE 确保了一旦多数人被“满足”并从池中移除,算法就会寻找下一个最大的意见一致群体来满足,从而确保比例性。
仿真分析
作者还在一个合成环境中运行了模拟,在那里他们可以控制“LLM”的确切错误率。
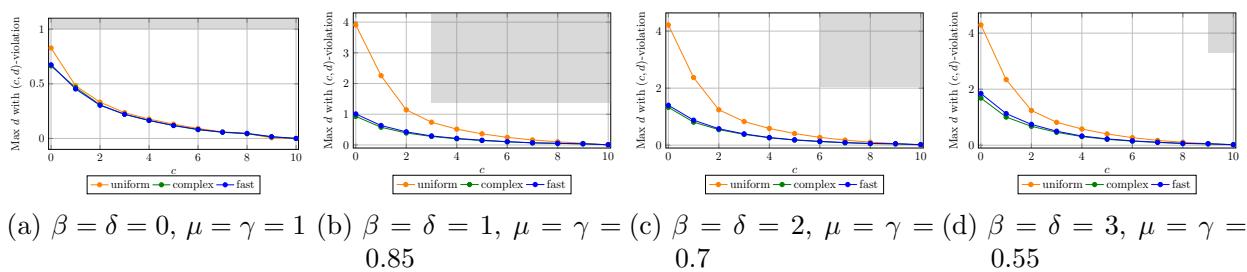
在上面的图 1 中,我们看到了模拟结果。 统一 (Uniform) 基线 (橙色线) 几乎立即未能实现比例性 (y 轴上的高违规) 。 复杂 (Complex) 算法 (绿线) ——即 PROSE 的完整实现——即使在问题复杂性 (\(c\),成本) 增加时也能保持低违规。阴影灰色区域代表论文推导出的理论保证;值得注意的是,实际性能往往优于最坏情况下的数学保证。
定性上的成功
生成的列表不仅在数学上更优越;它们在逻辑上也讲得通。
- 在 鲍灵格林 数据集中,PROSE 识别出了主张特定问题的不同群体: 交通改善、互联网基础设施和学区边界。
- 在 药物评论 数据集中,它捕捉到了那些发现药物有效但遭受特定副作用的用户的细微差别,而不是简单地将他们平均为“还可以”的情绪。
结论与启示
“Generative Social Choice: The Next Generation” 将该领域从一个巧妙的想法推进为一个可行的工程问题。通过承认 LLM 是不完美的,并且现实世界的报告有长度限制,作者创建了一个足以用于实际部署的框架。
关键要点
- 预算很重要: 你不能简单地要求“一个总结”。你必须定义注意力预算 (字数) ,算法必须按观点流行程度的比例来分配该预算。
- 贪婪即是好: 迭代移除满意的用户确保了少数群体在列表中获得一席之地,满足了 cBJR 公理。
- 对误差的鲁棒性: 即使 AI 犯错,只要这些错误在合理范围内,系统也能正常工作。
数字民主的未来
PROSE 的直接应用是总结大规模咨询——城市规划网站上的数千条评论或产品评论。但长远的愿景是参与式预算 。
想象一下,一个城市有成千上万的居民提交城市更新的想法。与其让一个人类委员会过滤它们,像 PROSE 这样的引擎可以生成一组项目列表,从数学上保证每组意见一致的公民都能得到公平的代表。虽然我们必须对 AI 偏见和透明度保持谨慎 (正如作者在影响声明中指出的那样) ,但这项工作为在民主进程中安全使用这些强大的工具提供了必要的数学护栏。