](https://deep-paper.org/en/paper/2505.24067/images/cover.png)
经典算法与深度学习的交汇是计算机科学中最令人着迷的前沿领域之一。一方面,我们拥有经典算法——严谨、可解释且保证有效,但往往僵化,无法处理原始、混乱的现实世界数据。另一方面,我们拥有神经网络——灵活、适应性强且能够处理复杂的输入,但往往不透明,且容易“产生幻觉”臆造不正确的答案。
神经算法推理 (Neural Algorithmic Reasoning, NAR) 试图融合这两个世界。其目标是训练神经网络像算法一样“推理”。通过教导网络模仿经典算法 (如广度优先搜索或 Bellman-Ford 算法) 的步骤,我们希望构建出比标准深度学习模型具有更好泛化能力的系统。
然而,该领域存在一个显著的天花板。NAR 的大多数成功案例都集中在“简单”问题上——具体来说,是像排序或寻找最短路径这样的多项式时间问题。但现实世界充满了难题——即 NP 难 (NP-hard) 问题——对于大型数据集,要在有效时间内找到精确解是不可能的。
在这篇文章中,我们将深入探讨一篇直面这一天花板的论文: 《原始-对偶神经算法推理》(Primal-Dual Neural Algorithmic Reasoning) 。 这项研究引入了一个名为 PDNAR 的框架,该框架将图神经网络 (GNN) 与组合优化中强大的原始-对偶方法结合了起来。
这种方法的独特之处在于什么?它不仅是模仿算法;它学会了超越用于训练它的近似算法,并且可以扩展到它从未见过的海量图数据上。
挑战: 为何 NP 难问题对 AI 来说很难
要理解这篇论文的贡献,我们需要了解当前研究中的差距。
之前的 NAR 模型有效地学会了执行像用于最小生成树的 Prim 算法。这些是精确算法。如果模型学会了完美的执行步骤,它就能得到最优解。
但对于 NP 难问题——如顶点覆盖 (Vertex Cover) 或集合覆盖 (Set Cover)——我们没有高效的精确算法。我们依赖于近似算法 , 这些算法保证解在最优解的一定倍数范围内 (例如,“成本不超过最佳可能成本的 2 倍”) 。
如果我们仅仅训练一个神经网络来模仿近似算法,我们最好的期望也就是一个与该近似算法一样好的模型。这并没有特别大的用处。PDNAR 背后的研究人员提出了一个不同的问题: 我们能否利用近似算法的结构来构建神经网络,但训练它去寻找更好的解?
背景: 原始-对偶范式
该框架的核心引擎是原始-对偶方法 (Primal-Dual method) 。 这是设计近似算法的一种标准技术。
每个线性规划 (LP) 问题都有一个“对偶”问题。如果“原始”问题是最小化成本,那么“对偶”问题就是最大化收益 (通俗地说) 。“弱对偶原理”指出,对偶问题的任何可行解都为原始问题提供了一个下界。
通过迭代更新原始问题和对偶问题中的变量,我们可以缩小两者之间的差距,最终得出一个解。
问题定义
该论文关注三个经典的 NP 难问题。让我们看看它们的数学表述,以此理解原始-对偶结构。
1. 最小顶点覆盖 (MVC)
想象一个图。你想选择最少数量的顶点,使得每条边都至少连接到一个被选中的顶点。
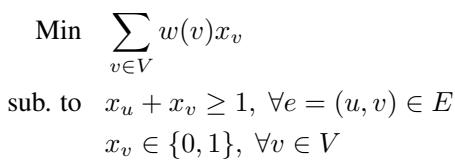
这个问题的对偶涉及“边打包 (edge packing)”——给边分配权重,使得没有顶点“过载”。
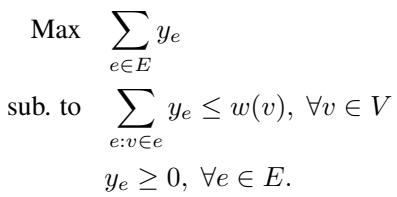
2. 最小集合覆盖 (MSC) 和碰集 (Hitting Set) 集合覆盖是顶点覆盖的推广,你试图使用一组集合族来覆盖元素。碰集问题在数学上是等价的,但通常更容易进行一般化表述。目标是选择最小权重的元素来“碰到”每一个集合。

在这些公式中:
- 原始变量 (\(x\)) : 通常是二元决策 (例如,“我是否包含这个顶点?”) 。
- 对偶变量 (\(y\)) : 与连接相关的约束或成本。
近似算法通常通过逐渐增加对偶变量来工作。当一个约束变得“紧 (tight)” (即对偶压力等于该项的权重) 时,算法就会选择该项进入解集。
PDNAR 框架
研究人员提出了 PDNAR (原始-对偶神经算法推理) 。 这种方法的天才之处在于它如何将原始变量和对偶变量之间的数学关系转化为神经架构。
1. 二部图表示
PDNAR 不将输入图视为标准图,而是将问题视为二部图 (bipartite graph) 。
- 左侧节点 (原始) : 代表我们可以选择的元素 (例如顶点覆盖中的顶点) 。
- 右侧节点 (对偶) : 代表我们需要满足的约束 (例如需要被覆盖的边) 。
如果某个元素涉及某个约束,则原始节点和对偶节点之间存在一条边。
2. 架构
该模型遵循标准的 NAR “编码器-处理器-解码器 (Encoder-Processor-Decoder)” 蓝图,但处理器是专门设计用来模拟原始-对偶更新的。
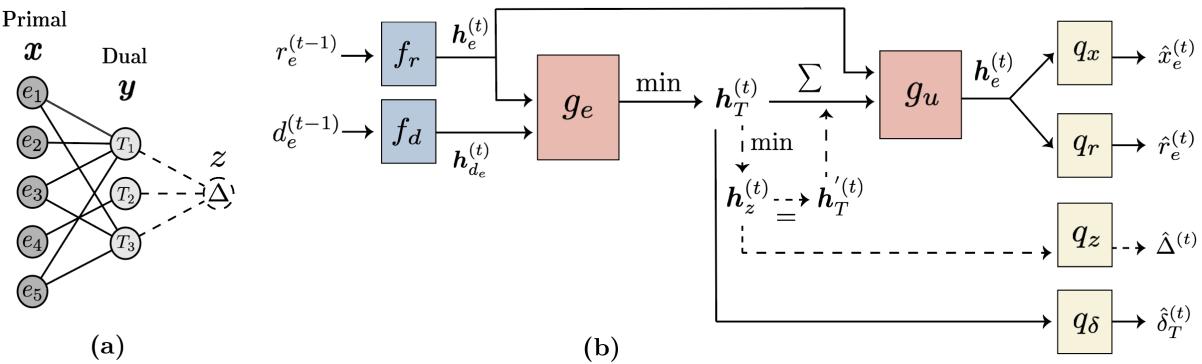
让我们分解上图所示的流程:
步骤 A: 编码 模型获取解的当前状态。这包括元素的“残余权重” (\(r_e\)) (即在我们被迫选择它之前还剩多少“成本”) 及其度数 (\(d_e\))。这些通过多层感知机 (MLP) 传递以创建潜在向量。
 注: 在实现中,通常使用对数变换来处理不同的尺度。
注: 在实现中,通常使用对数变换来处理不同的尺度。
步骤 B: 处理器 (算法对齐) 这是模型的核心。标准的 GNN 只是对邻居特征求和。PDNAR 将其消息传递与原始-对偶算法的特定数学运算对齐。
首先,对偶节点 (约束) 从原始节点收集信息。在经典算法中,这一步涉及寻找最小比率。因此,GNN 使用最小聚合 (min-aggregation) 函数:
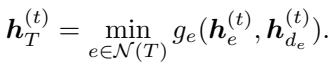
接下来,原始节点根据来自对偶节点的反馈更新其状态。在算法中,这对应于减少元素的残余权重。GNN 使用求和来模拟这一点:
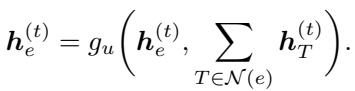
步骤 C: “均匀增加”规则 一些高级近似算法需要全局更新——同时增加所有对偶变量,直到某种平衡被打破。为了支持这一点,PDNAR 引入了一个虚拟节点 (\(z\)) (见架构图) 。
- 所有对偶节点向虚拟节点发送消息 (全局聚合) 。
- 虚拟节点向原始节点发送全局信号。
这使得网络能够学习局部消息传递所忽略的复杂的全局推理步骤。
步骤 D: 解码 最后,解码器将潜在向量转换回预测结果:
- \(\hat{x}_e\): 选择该元素的概率 (解) 。
- \(\hat{r}_e\): 预测的残余权重。
- \(\hat{\delta}_T\): 预测的对偶变量更新。
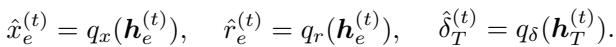
3. 理论对齐
该论文的重要贡献之一是理论证明。作者证明了该神经网络存在一组权重,可以精确复制经典原始-对偶算法的执行过程。
通过证明这种算法对齐,他们确保了模型具有至少与近似算法一样好的容量。
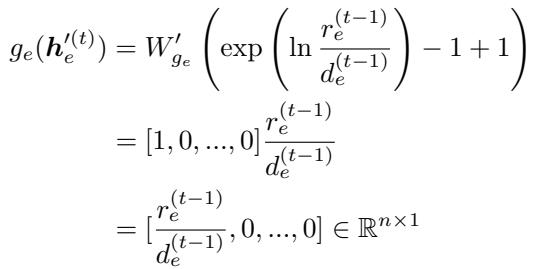
上面的方程是证明的一部分,表明 GNN 中的特定权重配置可以产生经典算法中发现的精确数学运算 (\(r_e / d_e\))。
秘诀: 最优监督
如果模型只学会模仿近似算法,它就只是标准脚本的一个更慢的版本。
作者引入了一种混合训练策略:
- 算法轨迹: 他们训练模型预测近似算法的逐步变化 (模仿老师) 。
- 最优监督: 对于小图 (例如 16 个节点) ,他们运行精确求解器 (如 Gurobi) 以获得完美解。他们添加了一个损失项,要求模型的最终输出与这个完美解相匹配。
这为什么重要? 近似算法是“贪婪”的——它们做出的局部最优选择在全局上可能是次优的。通过添加最优监督信号,神经网络学会利用其参数来“修正”算法的贪婪错误。它学习的是算法的结构,但却是最优求解器的决策方式。
因为它学习了结构,所以它可以泛化到巨大的图。因为它学习了最优决策,所以它的表现优于原始算法。
实验结果
作者在顶点覆盖 (MVC)、集合覆盖 (MSC) 和碰集 (MHS) 上测试了 PDNAR。
1. 击败老师
他们在小图 (16 个节点) 上训练模型,并在大得多的图 (最多 1024 个节点) 上进行测试。下面的指标是模型与算法的比率 (Model-to-Algorithm Ratio) 。
- 比率 = 1.0: 模型表现与近似算法完全相同。
- 比率 < 1.0: 模型找到了比它模仿的算法更好的解。
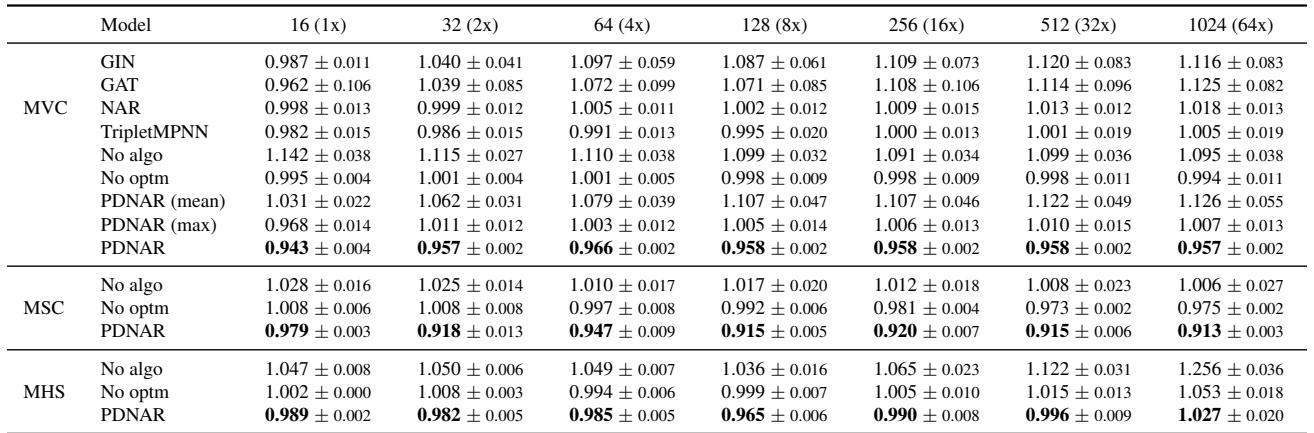
请看 PDNAR 行。比率始终低于 1.0 (例如,集合覆盖为 0.915) 。这证实了假设: 模型学会了改进近似逻辑。请注意,标准 GNN (GIN, GAT) 通常无法泛化到更大的图 (比率 > 1.0) ,而随着图大小呈指数增长,PDNAR 保持稳定。
2. 对新图类型的泛化
AI 的一个常见故障模式是“分布外” (OOD) 故障。在随机图上训练的模型可能会在“星形”图或“平面”图上失败。
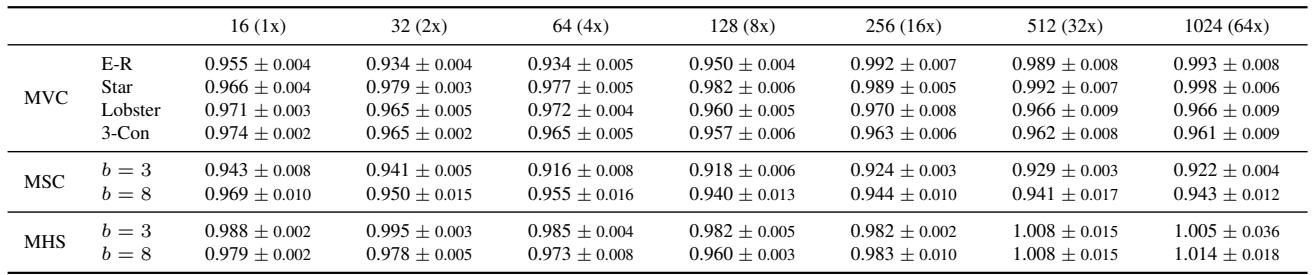
上面的结果表明 PDNAR 具有极好的泛化能力。即使在 Barabási-Albert 图上进行训练,它也能有效地处理星形图和龙虾图 (比率仍然 < 1.0 或非常接近) 。这表明模型学会了底层的算法,而不仅仅是数据集的统计特征。
3. 现实世界应用: 机场交通
作者将 PDNAR 应用于现实世界的机场数据集,以预测机场活动水平 (一个节点分类任务) 。他们使用 PDNAR 生成基于顶点覆盖结构的嵌入,并将其与标准 GNN 嵌入连接起来。
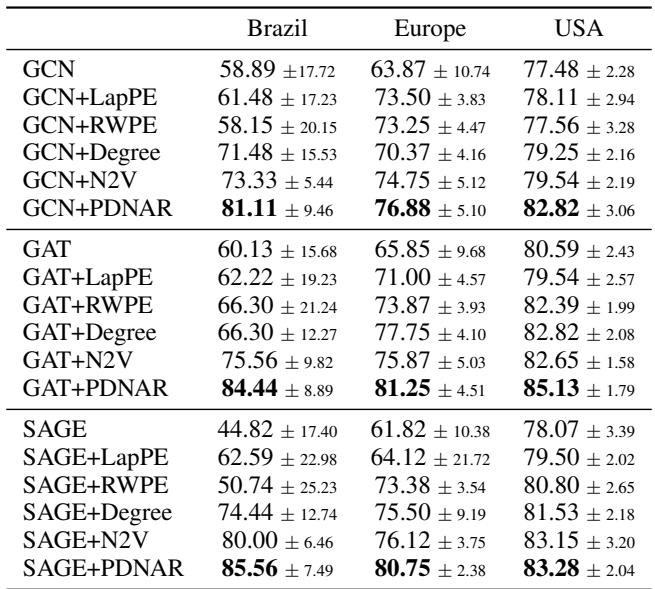
添加 PDNAR 特征 (GAT+PDNAR) 始终比基线提高准确率。这证明了“算法特征” (了解一个节点在顶点覆盖意义上的重要性) 对于一般学习任务是有价值的。
4. 实际工程: 热启动求解器
这也许是最直接的实际应用。像 Gurobi 这样的商业求解器被用于物流和金融领域以解决整数规划问题。它们很快,但随着问题变得巨大,它们会变慢。
你可以通过给 Gurobi 一个“热启动”——一个好的初始猜测——来加速它。作者使用 PDNAR 生成猜测并将其输入 Gurobi。
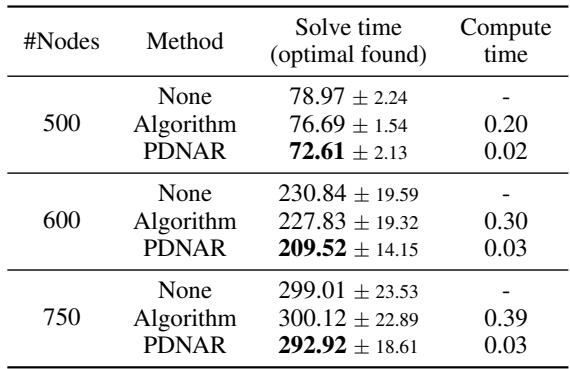
如表所示:
- 求解时间 (Solve Time): 使用 PDNAR 热启动 Gurobi (每部分的底行) 导致了最快的求解时间。
- 计算时间 (Compute Time): 神经网络生成猜测仅需几分之一秒 (0.03s),而运行经典近似算法则需要长得多的时间 (750 个节点需 0.39s) 。
神经网络本质上充当了一个闪电般快速的启发式生成器,使精确求解器更加高效。
结论
《原始-对偶神经算法推理》一文标志着我们利用神经网络解决困难组合问题能力的重大进步。
通过将神经架构与二部原始-对偶结构严格对齐,模型获得了经典算法的鲁棒性。通过在小实例上进行最优监督训练,它获得了精确求解器的直觉。
主要收获:
- 结构至关重要: 你不能仅仅把一个标准的 Transformer 或 GNN 扔给一个 NP 难问题就期望它能推理。架构必须反映问题的数学结构。
- 小数据,大泛化: 你可以在小型、求解成本低的图上进行训练,并部署在大型、求解成本高的图上。
- 青出于蓝: 神经网络可以学会模仿算法,然后通过梯度下降和最优标签,学会修正算法的贪婪错误。
该框架为混合系统打开了大门,在这种系统中,神经网络不会取代经典求解器,而是增强它们——即时提供高质量的近似解并加速对精确解的搜索。