](https://deep-paper.org/en/paper/2506.03863/images/cover.png)
打破码本坍缩: STAR 如何通过几何旋转教会机器人多样化技能
想象一下教机器人做饭。你不会告诉机器人打鸡蛋时肌肉运动所需的每一毫秒的细节。相反,你会以“技能”为单位来思考: 抓取鸡蛋、敲击平底锅边缘、掰开蛋壳。
这种分层方法——将复杂的长程任务分解为离散的、可复用的技能——是机器人操作领域的圣杯。然而,将连续的机器人动作转化为这些离散的“单词”或“Token”绝非易事。目前的方法经常遭受码本坍缩 (Codebook Collapse) 的困扰,即机器人忽略了它本可以学习的大部分技能,只依赖于极少数重复的动作。此外,即使机器人学会了这些技能,如何将它们流畅地串联起来 (组合) 也是另一个令人头疼的问题。
在这篇文章中,我们将深入探讨 STAR (Skill Training with Augmented Rotation,基于增强旋转的技能训练) , 这是在 ICML 2025 上提出的一个新框架。STAR 引入了一个巧妙的几何技巧来解决码本坍缩问题,并利用因果 Transformer 将这些技能串联起来,以执行诸如打开抽屉或整理物品等复杂任务。
问题所在: 为何机器人技能会“坍缩”
要理解 STAR,我们首先需要了解现代机器人是如何学习“技能”的。一种流行的方法是矢量量化 (Vector Quantization, VQ) 。
VQ 背后的直觉
把 VQ 想象成一个翻译器。机器人看到的是连续且杂乱的动作数据流 (关节角度、速度) 。VQ 试图将这些连续运动映射到固定字典 (称为码本 )中最近的“原型”运动上。
如果码本有 100 个条目,理想情况下,机器人应该学会 100 种不同的技能 (例如,向左推、向上提、扭动旋钮) 。
现实: 码本坍缩
实际上,神经网络是很懒惰的。在训练 VQ-VAE (矢量量化变分自编码器) 时,模型经常发现仅使用这 100 个代码中的 3 或 4 个就“足够”在训练早期最小化误差了。于是它停止了对字典其余部分的探索。
这就是码本坍缩 。 结果呢?机器人缺乏多样性。它可能知道一般意义上的“向前推”,但它缺乏区分“轻轻推”与“用力推”的细微差别,因为所有这些变体都坍缩成了一个单一、粗糙的技能代码。
罪魁祸首通常是梯度的计算方式。由于“吸附”操作 (四舍五入到最近的代码) 是不可微的,研究人员使用了一种称为直通估计器 (Straight-Through Estimator, STE) 的技巧。STE 本质上是假装梯度未被改变地传递过去。但这忽略了嵌入空间的几何形状,导致更新效果不佳,最终导致码本多样性的丧失。
STAR 登场: 两阶段解决方案
STAR 框架分两个阶段解决这些问题:
- RaRSQ (Rotation-augmented Residual Skill Quantization,旋转增强残差技能量化) : 一种在不发生坍缩的情况下学习技能字典的更好方法。
- CST (Causal Skill Transformer,因果技能 Transformer) : 一种将这些技能串联起来执行任务的更好方法。
让我们看看高层架构:
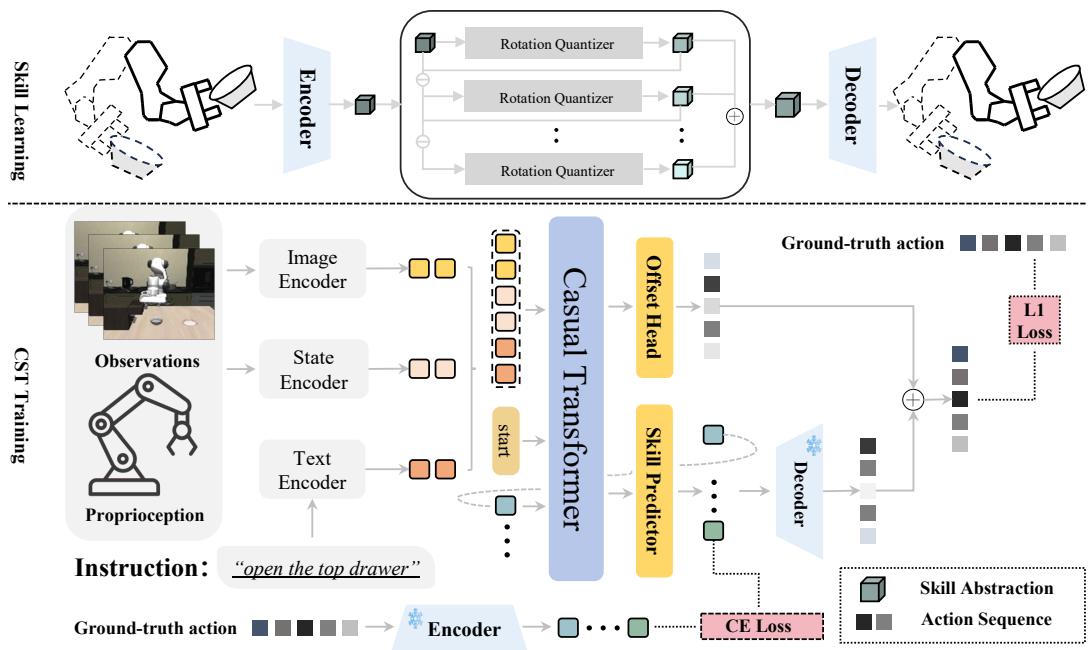
如 图 2 所示,上半部分专注于学习技能 (RaRSQ) ,而下半部分专注于使用技能 (CST) 。
第一部分: RaRSQ (学习多样化技能)
STAR 的核心创新在于它处理量化过程的方式。作者提出了 旋转增强残差技能量化 (RaRSQ) 。
“残差”方面
RaRSQ 不会将动作仅映射到一个代码,而是使用层次结构。这就像描述一个位置:
- 第 1 层 (粗略) : “纽约市”
- 第 2 层 (精细) : “时代广场”
在数学上,系统计算残差。它找到动作的最接近代码,从动作中减去该代码,然后尝试使用第二个码本对剩余部分 (残差) 进行量化。
“旋转”技巧
这是论文的数学核心。标准的 VQ 方法简单地将梯度从解码器复制到编码器 (STE) 。这忽略了编码器输出与码本向量之间的角度关系。
STAR 将其替换为基于旋转的梯度流 。 它不再只是将向量吸附到代码上,而是计算一个旋转矩阵 \(\mathbf{R}\),使输入残差 \(\mathbf{r}\) 与码本向量 \(\mathbf{e}\) 对齐。
更新规则如下所示:
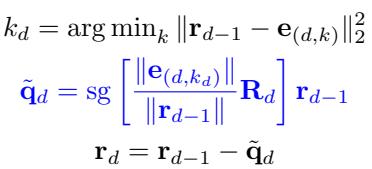
在这里,sg 代表停止梯度 (stop-gradient) 。系统旋转残差以匹配码本向量的方向。
为什么这很重要?
请看下面的 图 1 。 它比较了朴素 VQ (使用 STE) 和 RaRSQ。
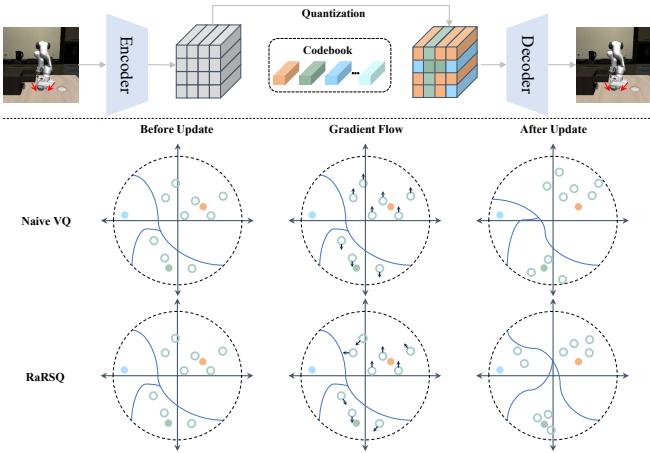
在 朴素 VQ (中间一行) 中,分配给特定代码的所有点的梯度 (箭头) 是完全相同的。它们都被推向完全相同的方向。这导致嵌入被极度地聚集在一起,使得其他代码未被使用。
在 RaRSQ (底部一行) 中,梯度源自旋转。这保留了相对角度。点是根据它们与代码的几何关系被推开或拉近的。这种梯度的“扇形散开”防止了嵌入坍缩成单个点,从而维持了一个丰富、多样化的空间,许多技能可以在其中共存。
旋转矩阵
对于那些对数学感兴趣的人来说,旋转矩阵 \(\mathbf{R}_d\) 的构建是为了将残差 \(\mathbf{r}_{d-1}\) 与选定的码本向量对齐。该公式确保几何结构被编码进梯度流中:
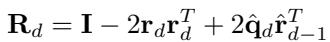
这种机制确保了当网络在反向传播期间更新其权重时,它尊重潜在空间的几何形状,迫使模型区分略有不同的动作,而不是将它们混为一谈。
第二部分: CST (组合技能)
一旦 RaRSQ 学会了一个多样化的技能库 (表示为离散代码) ,我们需要一个大脑来选择它们。这就是 因果技能 Transformer (CST) 。
自回归预测
机器人任务是序列化的。你必须先抓取才能举起。CST 显式地建模了这种依赖关系。它使用 Transformer 根据观察历史 (图像、机器人状态) 和先前的技能来预测下一个技能代码。
技能序列的概率建模为:
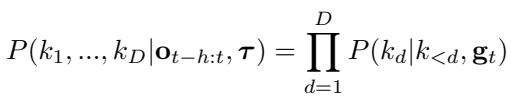
因为 RaRSQ 使用残差层次结构 (粗略 \(\to\) 精细) ,CST 首先预测第 1 层代码,然后以此为条件预测第 2 层代码。这反映了人类的规划方式: 先决定大体动作,再细化细节。
动作细化 (偏移量)
离散代码非常适合推理,但现实世界是连续的。离散代码可能会说“将手移动到坐标 (10, 10)”,但物体实际上在 (10.1, 9.9)。如果机器人仅依赖离散代码,它会显得笨拙。
为了解决这个问题,CST 包含一个 连续偏移头 (continuous offset head) 。 它预测一个小的连续调整量 \(\zeta_{\text{ref}}\) 以添加到解码后的动作中。
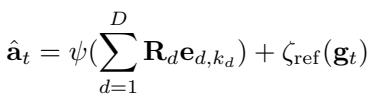
这种混合方法为机器人提供了两全其美的方案: 离散技能的结构化推理和连续回归的高精度控制。
训练目标
CST 使用双重目标进行训练: 它必须准确分类正确的技能代码 (使用交叉熵损失) ,并准确预测连续动作轨迹 (使用均方误差) 。
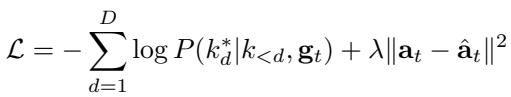
实验与结果
研究人员在两个主要基准上测试了 STAR: LIBERO (包含 130 个语言条件任务的套件) 和 MetaWorld MT50 。
它击败了最先进的方法 (SOTA) 吗?
是的,而且优势明显。
在包含 50 个不同操作任务的 MetaWorld MT50 基准测试中,STAR 达到了 92.7% 的成功率 , 始终优于 Diffusion Policy 和 VQ-BeT 等强基准。
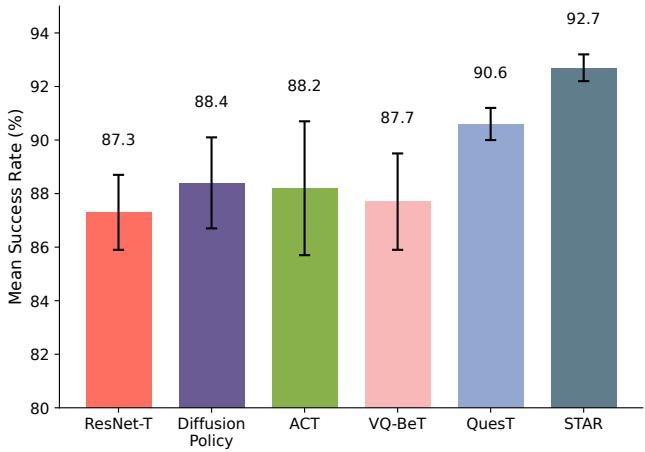
在 LIBERO 上的结果甚至更具说明性。LIBERO 包含“长程 (Long-Horizon) ”任务,这类任务因误差会随时间累积而极难处理。
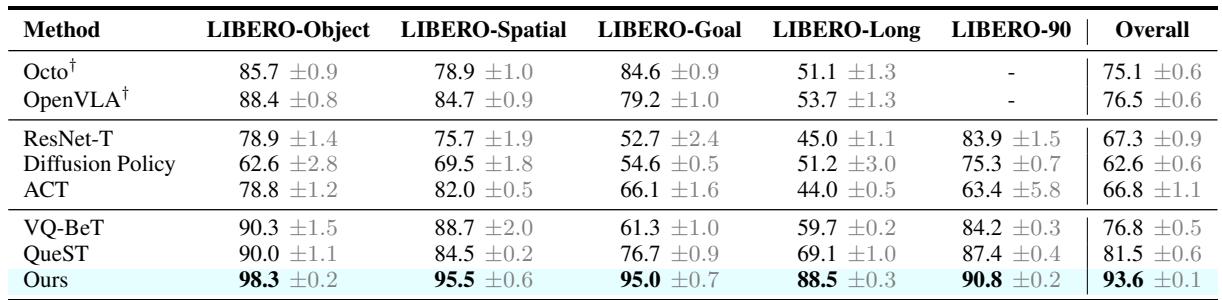
观察上面的 表 1 , 注意 LIBERO-Long 这一列。
- ACT: 44.0%
- VQ-BeT: 59.7%
- QueST: 69.1%
- STAR (Ours): 88.5%
相比之前的 SOTA (QueST),性能有了巨大的提升 (约 19%) 。这表明 STAR 保持多样化技能并对其进行细化的能力,使其能够处理长序列而不会丢失轨迹或精度。
它解决了码本坍缩问题吗?
作者声称 RaRSQ 防止了坍缩。他们通过分析训练期间码本中每个代码的使用频率证明了这一点。
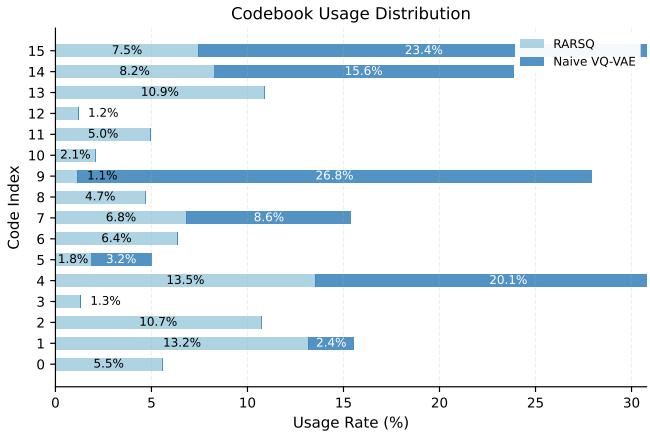
图 4 是“确凿的证据”。
- 朴素 VQ-VAE (深蓝色) : 它过度使用代码 0 和代码 4,而忽略了几乎一半的字典 (代码 8-13 几乎未被触及) 。这是典型的坍缩。
- RaRSQ (浅蓝色) : 使用情况分布在所有 16 个代码上。机器人有效地学会了 16 个不同的技能基元,而不仅仅是 7 个,从而为其提供了更丰富的动作词汇库。
真实世界表现
模拟很好,但在真正的机器人上能行吗?作者在 ALOHA 机械臂上测试了 STAR,执行诸如“把方块捡到盘子里,再把玩具捡到盒子里”的序列任务。

在这些测试中,STAR 表现出了卓越的稳定性。例如,在打开/关闭抽屉的任务中,基准方法通常在第一步 (打开) 后失败,无法过渡到放置物体。STAR 在整个序列中保持了连贯性。
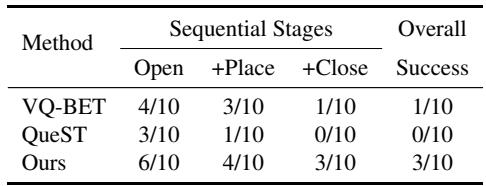
如 表 3 所示,虽然其他方法 (VQ-BeT, QueST) 难以完成完整的序列 (成功率为 0/10 和 1/10) ,但 STAR 有 30% 的时间成功完成了完整的“打开 \(\to\) 放置 \(\to\) 关闭”链条,并且在各个阶段的成功率都很高。
为什么这很重要
STAR 框架在 分层模仿学习 方面迈出了重要一步。
- 几何结构很重要: 它强调了我们不能简单地将矢量量化视为“黑盒”。通过尊重潜在空间的几何结构 (通过旋转) ,我们获得了更好的梯度和更丰富的表示。
- 多样性是关键: 一个技能词汇量匮乏的机器人是一个笨拙的机器人。防止码本坍缩对于处理现实世界的多变性至关重要。
- 组合 + 细化: 仅仅选择一项技能是不够的;你需要细化它。因果 Transformer 与连续偏移头的结合确保了高层规划与底层运动控制的结合。
通过解决离散表示的“坍缩”问题,STAR 允许机器人学习真正的多样化技能库,使我们更接近通用的机器人助手——它们可以做饭、打扫和整理,而不需要为每一个动作都编写硬编码脚本。