](https://deep-paper.org/en/paper/2506.05035/images/cover.png)
引言
在人工智能快速发展的版图中,时间序列数据是关键行业的命脉。从 ICU 患者的生命体征监测 (医疗健康) ,到预测电网波动 (能源) ,再到检测交通异常 (交通运输) ,深度学习模型正在做出关乎人类安全的决策。
然而,这些深度神经网络通常是“黑盒”。我们输入数据,它们输出预测。在高风险环境中,仅仅“能运行”是不够的;我们需要知道为什么它能运行。这就是可解释人工智能 (XAI) 的领域。
多年来,研究人员开发了多种方法将重要性归因于输入数据中的特定特征。但是,一篇最近的论文——TIMING: Temporality-Aware Integrated Gradients for Time Series Explanation,揭示了我们评估这些方法的方式存在重大缺陷。它指出,我们依赖的评估指标无意中惩罚了理解“方向” (正面与负面影响) 的方法,而偏袒了仅关注幅度的方法。
在这篇文章中,我们将深入探讨这项研究。我们将剖析为什么传统的评估指标在时间序列上会失效,介绍一套修补这一盲点的新指标,并详细拆解 TIMING——一种针对时间序列的时间复杂性改编了强大的积分梯度 (Integrated Gradients) 技术的新方法。
当前 XAI 评估存在的问题
要理解这篇论文的贡献,首先需要审视特征归因 (Feature Attribution) 的现状。
有符号与无符号归因
当模型做出预测时——比如预测一名患者有很高的死亡风险——不同的生命体征会有不同的贡献。
- 无符号归因 (Unsigned Attribution) : 这种方法问的是,“这个特征有多重要?”它给出一个幅度分数。高血压的得分可能是 0.8,心率可能是 0.2。它不告诉你该特征是推高还是拉低了风险,只告诉你它很重要。
- 有符号归因 (Signed Attribution) : 这种方法问的是,“这个特征增加还是减少了预测分数?”高血压可能是 +0.8 (增加风险) ,而健康的血氧水平可能是 -0.5 (降低风险) 。
终端用户 (如医生) 通常更喜欢有符号归因。他们想知道是什么导致了警报,而不仅仅是什么特征在起作用。
“抵消”陷阱
评估 XAI 方法的标准方式是屏蔽 (移除) 最“重要”的特征,看模型的预测会发生多大变化。这逻辑很合理: 如果一个特征很重要,移除它应该会破坏预测。
然而,作者发现了一个严重的缺陷。现有的评估指标通常同时移除前 \(K\) 个特征。
设想一种情况: 特征 A 使预测分数增加了 +5,特征 B使其减少了 -5。两者都是极其关键的特征。但是,如果一个归因方法将两者都识别为重要特征,而我们将它们同时移除,对预测的净影响可能是零 (\(+5 - 5 = 0\)) 。
评估指标会看到这个零变化并得出结论: “移除这些特征没有任何作用;因此,该 XAI 方法未能找到重要部分。”
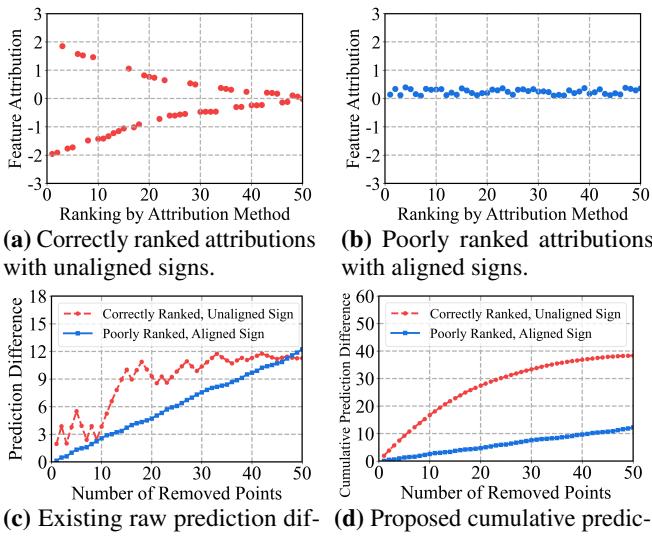
如上图 Figure 1 所示,这产生了一种偏差。
- 图 (a) & (c): 一个“完美”的方法 (红色) 正确识别了正面和负面特征。但因为它们在同时被移除时效果相互抵消,所以“原始预测差异” (图 c) 保持在低位。
- 图 (b) & (d): 一个“糟糕”的方法 (蓝色) 只是猜测具有相同符号 (方向一致) 的特征。当被移除时,它们的效果叠加,导致预测发生稳定的变化。
标准指标惩罚了正确的方法 (红色) ,奖励了有偏差的方法 (蓝色) 。这表明最近的许多文献可能都在为一个错误的目标进行优化——即对齐符号,而不是寻找真正的重要性。
新标准: CPD 和 CPP
为了解决抵消陷阱,研究人员提出了两个尊重模型决策复杂性的新指标。
累积预测差异 (CPD)
CPD 不会一次性移除所有顶级特征,而是按顺序 (逐个或分小组) 移除它们,并累加每一步预测变化的绝对值。
如果移除特征 A (+5),预测值下降 5。变化量 = 5。 接着移除特征 B (-5),预测值回升 5。变化量 = 5。 总 CPD = 10。
这个指标正确地奖励了识别出任何有影响力特征的方法,无论方向如何。
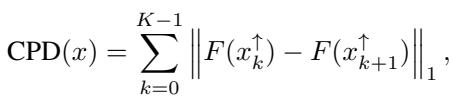
通过对连续步骤 (\(x_k\) 到 \(x_{k+1}\)) 之间的差异范数求和,CPD 确保了正面和负面贡献都被计入分数,而不是相互抵消。
累积预测保留 (CPP)
CPD 关注的是最重要的特征 (高归因) ,而 CPP 关注的是最不重要的特征。它按顺序移除具有最低归因分数的点。
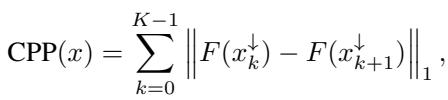
这里的逻辑是: “如果你说这些特征不重要,移除它们就不应该对预测产生太大改变。”CPP 分数越低越好,表明当移除“无用”特征时模型保持稳定。
有了这些忠实的指标,作者重新评估了现有的方法,发现 积分梯度 (IG)——一种经典的基于梯度的方法——实际上比最近提出的最先进 (SOTA) 方法表现好得多。然而,朴素的 IG 在处理时间序列数据时仍有重大问题,这就引出了论文的核心贡献: TIMING 。
TIMING: 感知时间性的积分梯度
积分梯度 (IG) 是一种理论上完善的方法,它通过累积从“基线” (通常是零向量) 到实际输入的路径上的梯度来计算归因。
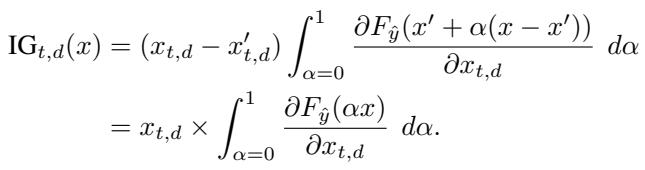
上面的公式本质上是说: 取输入与基线之间的差值,乘以两者之间直线路径上计算出的平均梯度。
为什么标准 IG 在时间序列上会失效
直接将 IG 应用于时间序列 (\(x' = 0\)) 有两个主要缺点:
- 破坏时间依赖性: 将时间序列从 0 线性缩放到 \(x\) (例如,\(0.1x, 0.2x, ...\)) 完美保留了序列的形状。时间步 \(t\) 和 \(t+1\) 之间的相对值从未改变。这意味着梯度永远看不到当时间关系被破坏时会发生什么,而这往往是时间序列“含义”的所在。
- 分布外 (OOD) 样本: 直线路径上的中间点 (比如所有值都只有 10% 幅度的时间序列) 可能看起来完全不像真实数据。模型在这些无意义的输入上可能会表现异常,产生不可靠的梯度。
解决方案: 基于片段的随机掩码
TIMING (Time Series Integrated Gradients) 修改了积分路径。它不使用从 0 开始缩放整个序列,而是使用随机基线 。
它通过屏蔽真实输入的部分内容来创建中间点。但这里的关键创新在于: 它不只是丢弃随机的单个点 (这看起来像静态噪声) ,而是丢弃时间的片段 (Segments) 。
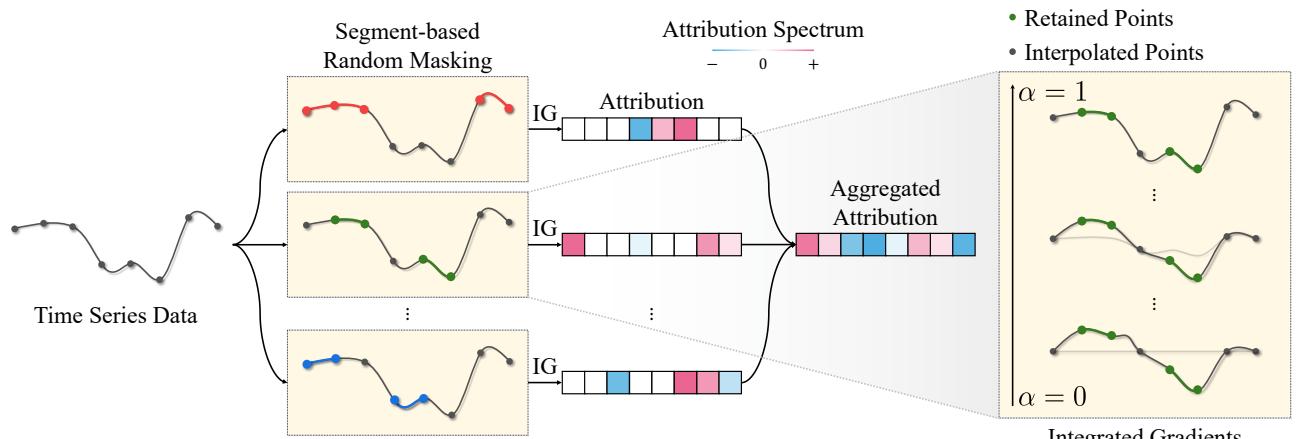
如 Figure 2 所示,该过程如下运作:
- 基于片段的随机掩码: 算法生成随机掩码,隐藏时间序列中连续的块 (片段) 。这模仿了数据缺失或时间模式中断的情况。
- 路径生成: TIMING 不使用从零开始的单一直线,而是考虑从这些被屏蔽的基线出发的路径。
- 聚合: 它使用不同的随机掩码多次运行此过程,并聚合归因结果。
随机掩码路径的数学公式如下所示:
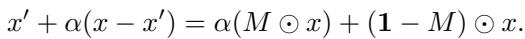
这里,\(M\) 是二进制掩码。路径在 \(x\) 的屏蔽版本和完整的 \(x\) 之间进行插值。这确保了中间点 (\(x'\)) 在结构上与原始数据相似,从而缓解了 OOD 问题。
最后,TIMING 计算这些屏蔽积分梯度在掩码分布 \(G\) 上的期望 (平均值) ,该分布生成长度为 \(s_{min}\) 到 \(s_{max}\) 的片段:
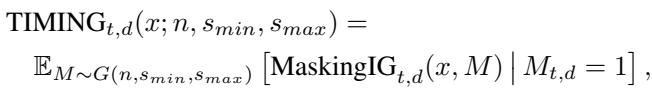
这种方法满足敏感性和不变性的理论公理,确保解释在数学上严谨的同时,也是为数据的序列性质通过量身定制的。
实验与结果
作者使用合成数据集和真实世界数据集,将 TIMING 与 13 种基线方法进行了对比验证。真实世界数据集包括 MIMIC-III (死亡率预测) 、PAM (活动监测) 等。
定量性能
使用新的、更忠实的 CPD 指标,TIMING 展示了卓越的性能。
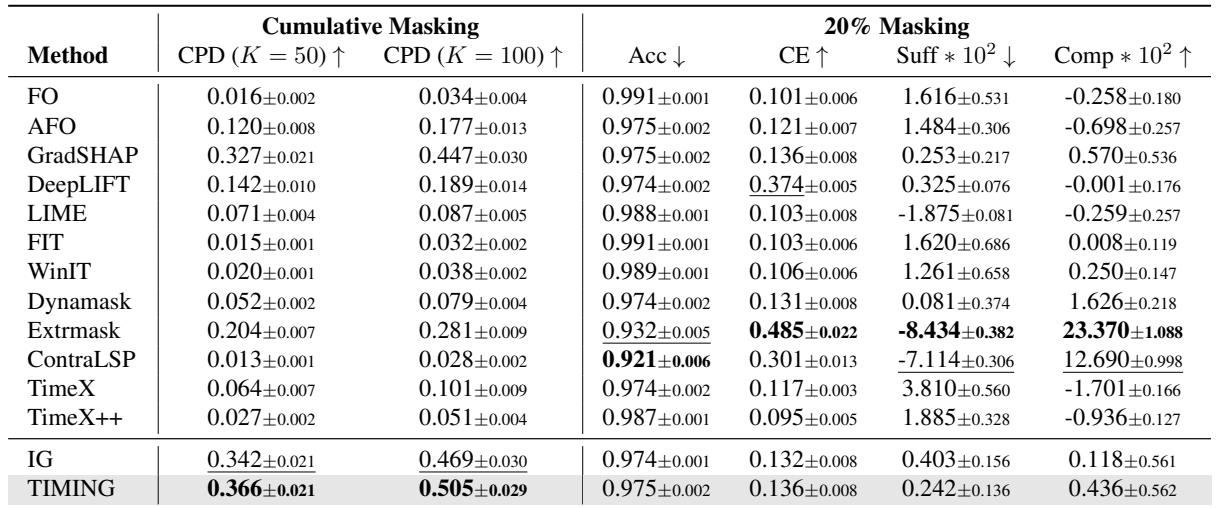
在 Table 2 中,查看 CPD (K=50) 列 (越高越好) ,TIMING 达到了 0.366 , 优于标准 IG (0.342),并显著击败了像 ContraLSP (0.013) 和 TimeX++ (0.027) 这样的近期方法。
等等,为什么像 ContraLSP 这样的“最先进”方法在 CPD 上得分这么低?这又要回到抵消问题。这些方法本质上是为了优化旧的指标 (如准确率下降) ,通过对齐符号来实现,但当逐步累加正面和负面特征时,它们未能捕捉到真正的影响幅度。
“不重要”的特征
我们还可以看看 CPP 指标 (累积预测保留) 。记住,这里我们移除的是方法认为最不重要的特征。我们希望预测保持稳定 (低曲线) 。
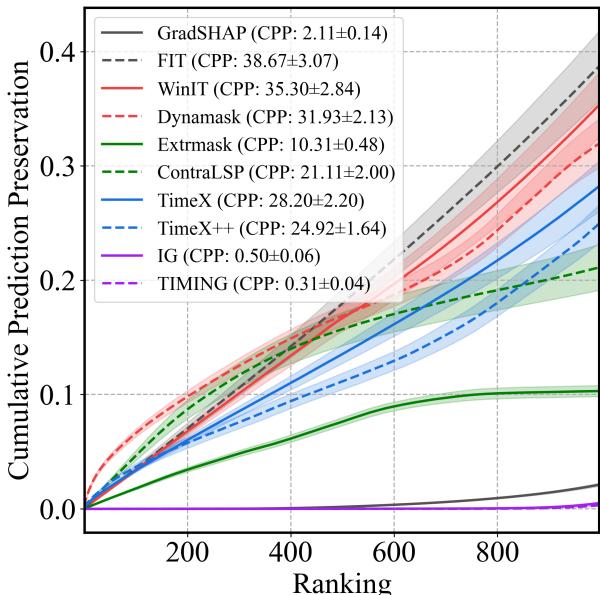
在 Figure 3 中,图表显示了当我们移除“不重要”点时预测的累积变化。
- TIMING 线 (紫色,图例中标注) 和 IG 线非常低且平坦。这意味着当 TIMING 说一个特征不重要时,移除它确实几乎没有影响。
- 相比之下,像 Extrmask 或 TimeX 这样的方法显示出急剧上升。这意味着它们将重要特征误分类为不重要;当你移除它们时,预测会发生剧烈变化。
跨数据集的一致性
成功并不局限于一个数据集。 Table 3 显示 TIMING 在各个领域都胜出,从锅炉故障检测到晶圆制造。

计算效率
对于像 TIMING 这种“集成”或“采样”方法,一个常见的担忧是速度。如果你必须用不同的掩码多次运行 IG,会不会很慢?
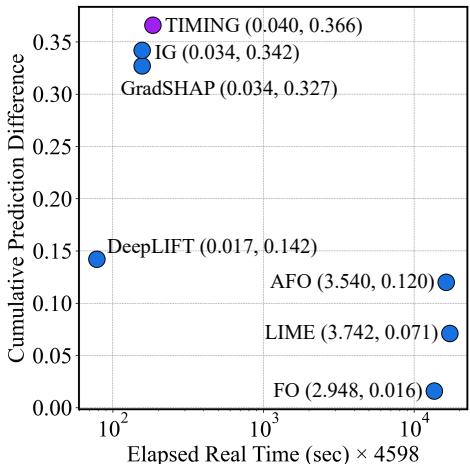
Figure 4 绘制了效率 (x 轴,对数时间) 与性能 (y 轴,CPD) 的关系。
- TIMING (左上角集群) 占据了“最佳平衡点”。它拥有最高的 CPD 分数。
- 它的运行时间与 GradSHAP 和 IG 相当,比像 LIME 或 AFO (位于最右侧) 这种基于扰动的方法快几个数量级。通过在积分路径中使用高效的采样策略,TIMING 相比标准 IG 只增加了极小的开销。
定性分析: 它合理吗?
最后,这些解释是否符合人类的领域知识?作者分析了 MIMIC-III 数据 (ICU 死亡率) 。
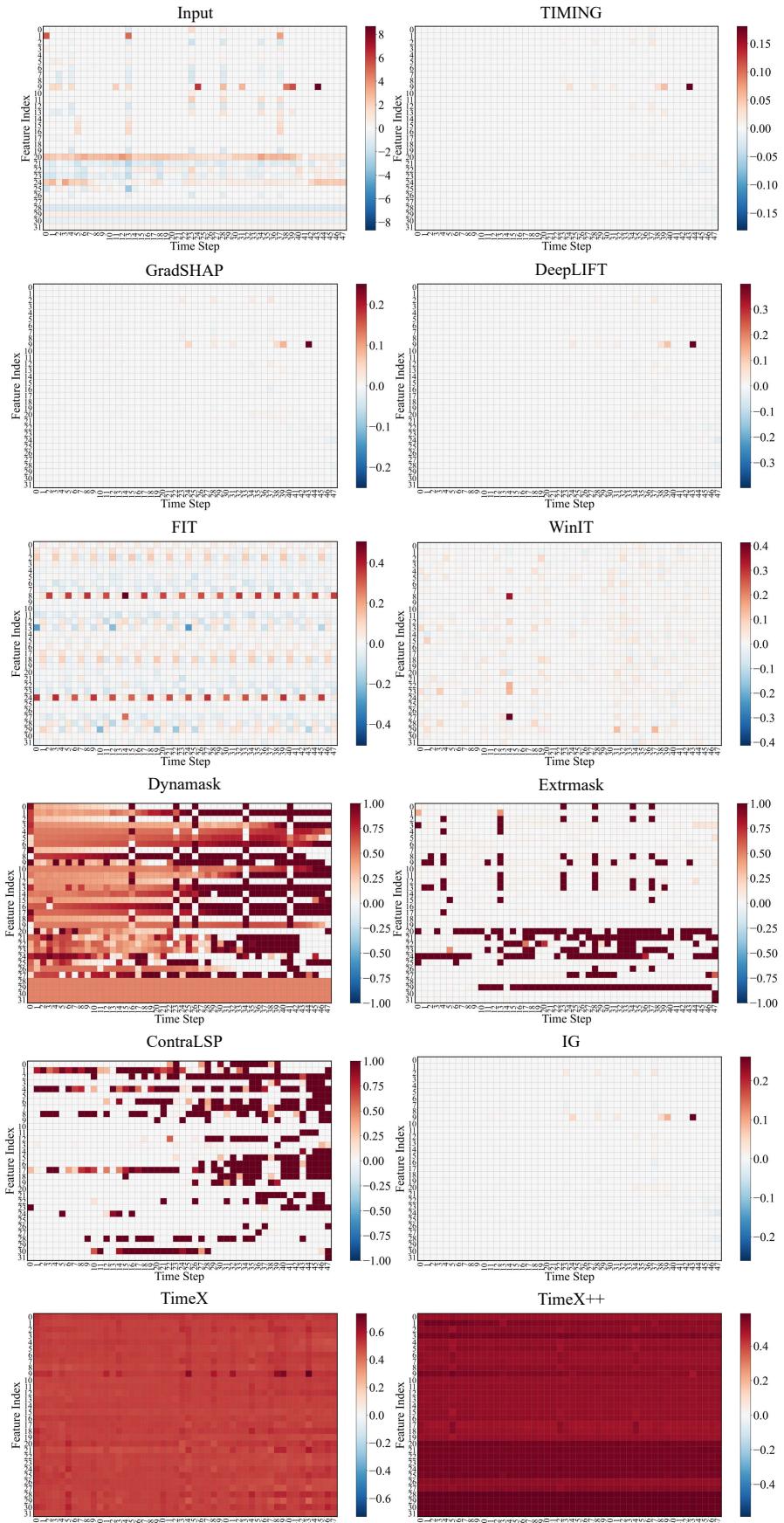
在 Figure 10 中,我们看到了归因的热力图。 TIMING 一行显示了稀疏、明显的红色 (正面) 和蓝色 (负面) 信号。具体来说,它高亮了 特征索引 9 (乳酸水平) 。临床文献证实,乳酸升高是死亡率的强预测因子 (乳酸酸中毒) 。
无符号方法 (如 TimeX++) 倾向于将重要性涂抹在整个时间序列上,使得临床医生很难精确定位究竟是何时以及什么出了问题。TIMING 提供了一个清晰、具有临床相关性的信号。
结论
论文 “TIMING” 为时间序列 XAI 领域做出了两大贡献:
- 指标的修正: 它揭露了当前的评估标准是如何意外惩罚那些正确识别对立特征贡献的方法的。通过引入 CPD 和 CPP , 作者提供了一种更公平的方式来基准测试忠实度。
- 更好的方法: 通过将 基于片段的随机掩码 适配到积分梯度中,TIMING 在不牺牲理论严谨性的前提下,捕捉到了时间序列数据的时间依赖性。
对于学生和从业者来说,结论很明确: 在处理时间序列时,“重要性”不是一个标量值。方向至关重要。并且在评估你的模型时,确保你的指标没有抵消掉你试图寻找的见解。TIMING 代表了在安全攸关领域迈向透明、可靠 AI 的重要一步。