](https://deep-paper.org/en/paper/2506.05584/images/cover.png)
引言
如果你上过机器学习的入门课程,你可能知道表格数据的一条黄金法则: 梯度提升决策树 (GBDT) 为王。 虽然深度学习彻底改变了图像 (CNN、ViT) 和文本 (LLM) 领域,但表格数据——构成商业和医疗数据库绝大多数的行和列——仍然是 XGBoost、LightGBM 和 CatBoost 的坚固堡垒。
然而,最近的研究试图使用 Transformer 来挑战这一统治地位。最引人注目的尝试是 TABPFN (Tabular Prior-Data Fitted Network) ,这是一种类似于“表格大语言模型”的模型。你不需要在数据集上训练模型,只需将训练数据输入到提示 (Prompt) 中 (即上下文学习) ,它就能立即预测测试标签。这是革命性的,但它有一个巨大的缺陷: 可扩展性。 由于依赖标准的注意力机制,其计算成本随着样本数量的增加呈二次方爆炸式增长。对于 1,000 行数据来说它很棒,但对于 100,000 行数据则完全没用。
TABFLEX 应运而生。
在这篇文章中,我们将深入探讨一篇提出表格扩展问题解决方案的新论文。通过用 线性注意力机制 (Linear Attention) 替换标准的 Softmax 注意力机制,TABFLEX 将计算复杂度从二次降低到线性。结果如何?一个能在 5 秒内对一百万行数据进行分类的模型,在效率上超越了 XGBoost,同时保持了最先进的准确率。
问题所在: 上下文的代价
要理解为什么 TABFLEX 是必要的,我们需要先了解它所基于的架构: TABPFN。
TABPFN 将表格分类视为一个 上下文学习 (In-Context Learning, ICL) 问题。就像你在要求 GPT-4 翻译新句子之前,可能会用几个英语到法语的翻译示例作为提示一样,TABPFN 将你的整个训练数据集 (特征和标签) 以及测试集 (仅特征) 作为一个单一序列输入到 Transformer 中。
 图 1: TABPFN 的架构。整个训练集作为一个序列输入到模型中。模型在单次前向传递中利用注意力机制学习训练样本和测试样本之间的关系。
图 1: TABPFN 的架构。整个训练集作为一个序列输入到模型中。模型在单次前向传递中利用注意力机制学习训练样本和测试样本之间的关系。
如图 1 所示,模型嵌入特征 (\(x\)) 和标签 (\(y\)) ,并通过 Transformer 编码器对其进行处理。这里的关键优势是 推理过程中不发生梯度更新。 你不需要在数据上“训练”模型;模型通过注意力机制即时“学习”模式。
二次复杂度的高墙
这种方法的阿喀琉斯之踵是标准的自注意力机制 (通常称为 Softmax 注意力) 。对于长度为 \(N\) 的序列,标准注意力需要计算一个大小为 \(N \times N\) 的注意力矩阵。
如果你有 1,000 个样本,复杂度与 \(1,000^2\) (\(1,000,000\)) 成正比。如果扩展到 10,000 个样本,复杂度就变成了 \(10,000^2\) (\(100,000,000\)) 。这种二次方扩展 (\(O(N^2)\)) 使得将大型数据集输入提示在计算上变得不可能。TABPFN 实际上被限制在几千个样本以内,使其无法用于“现实世界”的大数据任务。
寻找可扩展的架构
TABFLEX 的作者们着手寻找一种线性扩展——\(O(N)\)——的注意力机制,使他们能够处理数百万个样本。他们研究了两种主要的可扩展架构候选者: 状态空间模型 (SSM/Mamba) 和 线性注意力机制 。
调查 1: 状态空间模型 (Mamba) vs. Transformer
状态空间模型 (SSM) ,特别是 Mamba,最近因在语言任务上以线性扩展匹配 Transformer 的性能而声名鹊起。这看起来似乎是一个完美的契合,对吧?
研究人员发现答案是 否定的 。 根本问题在于 因果性 (Causality) 。
SSM 和 Mamba 本质上是因果的 (自回归的) 。它们按顺序处理数据,其中 Token \(t\) 只能看到 Token \(0\) 到 \(t-1\)。这对语言 (从左到右阅读) 或音频 (时间向前推移) 来说是有意义的。然而, 表格数据具有置换不变性 。 你将行输入模型的顺序应该没有影响。第 100 行包含的相关信息对于第 1 行来说,与第 2 行一样多。
 图 2: 因果掩码与非因果掩码的影响。随着样本量的增加,非因果模型 (蓝色) 持续改进。而模仿 Mamba 约束的因果模型 (粉色) 则停滞不前甚至性能下降。
图 2: 因果掩码与非因果掩码的影响。随着样本量的增加,非因果模型 (蓝色) 持续改进。而模仿 Mamba 约束的因果模型 (粉色) 则停滞不前甚至性能下降。
如图 2 所示,强制因果性会损害表格任务的性能。因果模型实际上忽略了序列中的“未来”行,浪费了宝贵的上下文。当作者将基于 Mamba 的架构与 Transformer 架构进行测试时,结果很明确:
 图 3: Mamba 与 Transformer 在表格任务上的对比。Transformer (非因果) 实现了显著更低的损失和更高的 AUC。
图 3: Mamba 与 Transformer 在表格任务上的对比。Transformer (非因果) 实现了显著更低的损失和更高的 AUC。
调查 2: 线性注意力机制
由于因果模型失败了,作者转向了 线性注意力机制 。 要理解这一点,我们需要看一下数学原理。
标准的 Softmax 注意力机制使用查询 (Query, \(Q\)) 、键 (Key, \(K\)) 和值 (Value, \(V\)) 向量来计算输出 \(\mathbf{a}_i\)。它使用 softmax 函数来归一化相似度分数:
\[ \text{Softmax Attention: } \mathbf{a}_{i} = \frac{\sum_{j=1}^{n} \exp\left(\mathbf{q}_{i}^{\top} \mathbf{k}_{j}\right) \cdot \mathbf{v}_{j}}{\sum_{j=1}^{n} \exp\left(\mathbf{q}_{i}^{\top} \mathbf{k}_{j}\right)} \]\(\exp(\mathbf{q}^\top \mathbf{k})\) 项将查询和键锁定在一个非线性函数内,迫使我们计算完整的 \(N \times N\) 矩阵。
线性注意力机制 移除了 softmax。取而代之的是,它分别对 \(Q\) 和 \(K\) 应用特征映射函数 \(\phi(\cdot)\) (如 elu(x) + 1) 。这允许我们利用矩阵乘法的结合律:
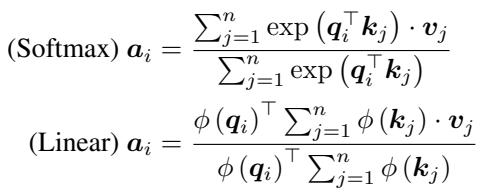
为什么这很重要? 在线性注意力中,我们可以先计算 \(\sum_{j=1}^{n} \phi(\mathbf{k}_{j}) \cdot \mathbf{v}_{j}\)。这个求和结果是一个大小为 \(D \times D\) 的矩阵 (其中 \(D\) 是嵌入维度,通常很小) ,完全独立于序列长度 \(N\)。
- Softmax 注意力: \(O(N^2 D)\)
- 线性注意力: \(O(N D^2)\)
由于 \(N\) (样本数) 通常远大于 \(D\) (嵌入大小) ,因此线性注意力对于大型数据集来说效率要高得多。
研究人员实现了这一点,并发现线性注意力在保持 Softmax 注意力准确性的同时,大幅缩减了运行时间。
 图 4: 用线性注意力替换 Softmax 保留了准确率 (y 轴) ,同时显著减少了运行时间 (x 轴) 。
图 4: 用线性注意力替换 Softmax 保留了准确率 (y 轴) ,同时显著减少了运行时间 (x 轴) 。
TABFLEX: 架构
决定使用非因果线性注意力后,作者开发了 TABFLEX 。
硬件效率
如果 GPU 实现很差,理论复杂度 (\(O(N)\)) 并不总是转化为现实世界的速度。作者分析了高带宽内存 (HBM) 的访问模式。他们证明,线性注意力的直接 PyTorch 实现实际上非常高效,其内存访问复杂度与像 FlashAttention 这样高度优化的内核相匹配,而无需复杂的自定义 CUDA 代码。
 图 5: 计算时间 (a) 和内存使用量 (b)。请注意,标准的 FlashAttention (黑色虚线) 在某些设置下仍然会出现内存或时间的峰值,而线性注意力 (粉色实线) 在不同序列长度上都能线性且高效地扩展。
图 5: 计算时间 (a) 和内存使用量 (b)。请注意,标准的 FlashAttention (黑色虚线) 在某些设置下仍然会出现内存或时间的峰值,而线性注意力 (粉色实线) 在不同序列长度上都能线性且高效地扩展。
条件模型选择
一种模型大小无法适应所有表格问题。一个数据集可能有 50 行和 20 个特征,或者 1,000,000 行和 1,000 个特征。TABFLEX 利用一套三个专门的模型,根据数据集的形状进行路由:
- TABFLEX-S100: 针对小型数据集优化 (\(<3k\) 样本,\(<100\) 特征) 。
- TABFLEX-L100: 针对长序列优化 (\(>3k\) 样本,\(<100\) 特征) 。
- TABFLEX-H1K: 针对高维数据优化 (\(1,000\) 特征) 。
这确保了模型不会在小数据上浪费算力,也不会在海量数据面前力不从心。
实验结果
TABFLEX 的结果令人震惊,特别是与它的前身 TABPFN 和传统的梯度提升方法相比时。
1. 速度和可扩展性
在标准验证数据集上,TABFLEX 在速度上始终优于 TABPFN,同时保持或略微超过 AUC (曲线下面积) 性能。
 图 6: 与 TABPFN (左侧柱状图) 相比,TABFLEX (右侧柱状图) 实现了更高的平均 AUC 和显著更低的运行时间。
图 6: 与 TABPFN (左侧柱状图) 相比,TABFLEX (右侧柱状图) 实现了更高的平均 AUC 和显著更低的运行时间。
2. “困难”基准测试
真正的考验在于“困难 (Hard) ”数据集——那些大型、高维或复杂的数据集。许多 Transformer 方法在这里都会因为内存溢出 (OOM) 错误而失败。
 图 7: 运行时间与中位数 AUC 的散点图。理想位置是右下角 (快速且准确) 。TABFLEX (蓝星) 处于一个最佳平衡点——比 XGBoost 和 TABPFN 更快,且具有竞争力的准确率。
图 7: 运行时间与中位数 AUC 的散点图。理想位置是右下角 (快速且准确) 。TABFLEX (蓝星) 处于一个最佳平衡点——比 XGBoost 和 TABPFN 更快,且具有竞争力的准确率。
最令人印象深刻的结果来自 Poker Hand 数据集 , 其中包含超过 1,000,000 个样本 。
- TABPFN: 耗时 15.36 秒 (使用数据子集,因为它无法处理完整数据集) 。
- 其他基线: 有些耗时超过 500 秒。
- TABFLEX: 处理完整的 100 多万个样本仅需 4.88 秒 。
 表 1: 在 Poker-hand 数据集 (最后一行) 上,TABFLEX 在 <5 秒内达到了 0.84 的 AUC,而 TABPFN 滞后于 0.72 AUC 且耗时是其 3 倍。
表 1: 在 Poker-hand 数据集 (最后一行) 上,TABFLEX 在 <5 秒内达到了 0.84 的 AUC,而 TABPFN 滞后于 0.72 AUC 且耗时是其 3 倍。
3. 与 XGBoost 的比较
TABFLEX 能击败冠军 XGBoost 吗? 作者进行了细致的权衡分析。对于特征少于 800 个的数据集,TABFLEX 提供了更好的准确率与推理时间权衡。它本质上通过 ICL 即时“学习”数据集,而 XGBoost 需要迭代构建树。
 图 8: TABFLEX (蓝色) 与 XGBoost (粉色) 。TABFLEX 达到高准确率的速度比 XGBoost 快得多,尤其是在低维设置 (100-600 个特征) 中。
图 8: TABFLEX (蓝色) 与 XGBoost (粉色) 。TABFLEX 达到高准确率的速度比 XGBoost 快得多,尤其是在低维设置 (100-600 个特征) 中。
4. 小数据集统治力
即使在 TABPFN 擅长的小型数据集上,TABFLEX 也能在匹配性能的同时将运行时间缩短一半。
 表 2: TABFLEX 在平均 AUC (0.89) 上排名第二,与 TABPFN (0.90) 和 CatBoost (0.89) 基本持平,但平均运行时间仅为 0.48 秒,而 TABPFN 为 1.04 秒,CatBoost 为 19.51 秒。
表 2: TABFLEX 在平均 AUC (0.89) 上排名第二,与 TABPFN (0.90) 和 CatBoost (0.89) 基本持平,但平均运行时间仅为 0.48 秒,而 TABPFN 为 1.04 秒,CatBoost 为 19.51 秒。
扩展到图像和回归
虽然 TABFLEX 专为表格分类设计,但其灵活性允许进行有趣的扩展。
图像分类即表格学习: 通过将图像 (例如 MNIST 数字) 展平为像素向量,我们可以将它们视为表格中的行。TABFLEX 实现了惊人的高准确率 (MNIST 上 94.8%) ,且延迟极低,在这些特定规模下的训练/推理速度效率方面优于简单的 MLP 和 ResNet。
回归: 作者还将 TABFLEX 调整用于回归任务,方法是将连续目标离散化为分箱 (将回归转化为分类) 。即使采用这种简单的方法,它在与 XGBoost 的对抗中也表现相当不错,显示了学习到的表示的鲁棒性。
结论
TABFLEX 代表了表格深度学习的一个重要里程碑。多年来,Transformer 的内存瓶颈阻碍了它们成为大规模表格任务的有力竞争者。通过确定 非因果线性注意力 是该领域的最佳架构,研究人员创建了一个快速、可扩展且准确的表格“基础模型”。
关键要点:
- 因果性很重要: 标准的语言建模架构 (如 Mamba) 不适用于表格,因为行顺序无关紧要。
- 线性注意力是关键: 它解耦了序列长度与内存复杂度,允许 \(O(N)\) 扩展。
- 速度: TABFLEX 可以在几秒钟内处理数百万行数据,为使用上下文学习的实时、大规模表格应用打开了大门。
随着我们的前进,像 TABFLEX 这样的技术表明,表格学习领域的“守旧派” (梯度提升) 和“新浪潮” (Transformer) 之间的差距正在迅速缩小。