](https://deep-paper.org/en/paper/2506.07785/images/cover.png)
引言
“一例胜千言。”这句话在人工智能领域尤为真切。当我们希望模型解决一个复杂问题——比如分析几何图形或解读历史图表——向它展示一个类似的、已解决的例子,往往比给它一长串指令效果更好。这种技术被称为上下文学习 (In-Context Learning, ICL) 。
然而,大型视觉语言模型 (LVLM)——那些能看也能说的 AI 系统——仍然面临着巨大的障碍。尽管它们能力超群,却容易产生幻觉 。 它们可能会自信地歪曲历史事件,或者因为缺乏特定的领域知识而完全无法回答用户的问题。
为了解决这个问题,研究人员通常使用检索增强生成 (Retrieval-Augmented Generation, RAG) 。 其原理很简单: 在 AI 回答之前,它会搜索数据库以获取相关信息 (如教科书或维基百科) ,并以此为依据进行回答。但问题在于: 标准的 RAG 通常只检索事实,而不检索背后的逻辑。它可能会找到一张相似的图片,但如果检索到的例子没有解释如何解决问题,AI 仍然只能靠猜。
在这篇文章中,我们将深入探讨一种名为 RCTS (推理上下文与树搜索) 的新框架。这种方法不仅仅是检索相似的图像;它构建了一个充满分步推理的“智能”知识库,并使用复杂的搜索算法来精确决定哪些例子最能帮助模型。
“普通” RAG 的问题
在了解解决方案之前,我们需要先了解当前方法的局限性。
现有的多模态 RAG 方法有点像学生参加开卷考试。当被问到一个问题时,学生翻阅书本,找到看起来相关的一页,然后尝试回答。如果书里只包含原始事实,学生可能仍然无法理解底层概念。
当前的局限性包括:
- 推理匮乏: 大多数数据集包含问答 (QA) 对。它们告诉你答案是“C”,但不告诉你为什么。没有“为什么”,AI 就很难学习到模式。
- 不稳定的检索: 检索系统通常基于视觉或语义相似性来挑选例子。但仅仅因为两张图片看起来很像,并不意味着它们需要相同的逻辑来解决。如果 AI 检索到一个“干扰项” (看起来相似但解法不同的例子) ,实际上反而会通过混淆模型。
RCTS 框架旨在将 LVLM 从仅仅“知道”事实转变为“理解”如何通过事实进行推理。
RCTS 框架: 概览
研究人员提出了一个三阶段的流程,旨在改变 LVLM 利用外部知识的方式。
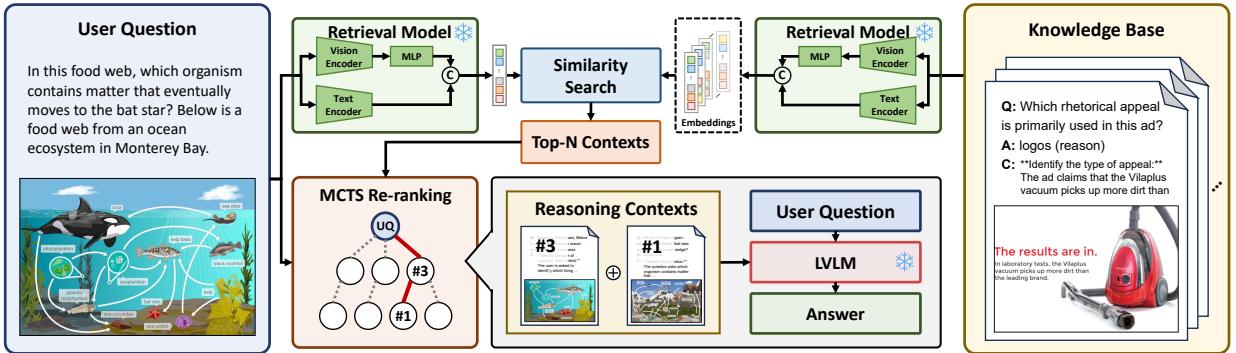
如图 2 所示,该流程如下:
- 知识库构建: 系统构建的不是一个静态的问答数据库,而是一个富含推理上下文 (分步解释) 的数据库。
- 混合检索: 当用户提问时,系统利用视觉和文本线索检索潜在的相关例子。
- MCTS 重排序: 这是核心创新点。系统不再盲目相信排名靠前的检索例子,而是使用蒙特卡洛树搜索 (MCTS) 来探索不同的例子组合并对它们进行“重排序”,以找到能最大化正确回答概率的那一组。
让我们详细分解这些组件。
1. 构建包含“推理上下文”的知识库
如果你想让 AI 进行逻辑思考,你就必须给它“投喂”逻辑。标准数据集通常是这样的:
- 图片: 一张长城的照片。
- 问题: 这个建筑的目的是什么?
- 答案: 防御。
这对于复杂推理来说是不够的。RCTS 框架自动创建“推理上下文”。它利用 LVLM 本身为现有的数据生成详细的解释。

工作原理 (参考图 3) :
- 生成: 模型查看训练集中的问答对,并生成几个候选的“思维过程” (推理上下文) ,解释如何从问题得出答案。
- 自洽验证: 然后系统会测试这些候选过程。它将问题加上生成的上下文反馈给模型。如果模型利用该上下文预测出了正确的真实答案,则认为该上下文是有效的。
- 选择: 能够以最高置信度导出正确答案的推理上下文会被保存到知识库中。
现在,当系统后续检索一个例子时,它不仅仅是提取一个原始的 QA 对;它提取的是关于如何解决该特定类型问题的“迷你教程”。
2. 混合检索
准备好增强型知识库后,下一步是检索。由于我们处理的是视觉语言模型,仅依靠文本搜索是不够的。
作者采用了混合嵌入策略 。 他们使用:
- 文本编码器来理解问题的语义。
- 视觉编码器来理解图像的内容。
这两种表示被拼接 (连接在一起) 形成一个统一的查询。系统将用户的查询与知识库进行比对,以找到前 \(N\) 个最相似的例子。然而,相似度评分是不完美的。“最相似”的图片可能会产生误导。这就引出了论文中最复杂也是最具影响力的部分。
3. 通过蒙特卡洛树搜索 (MCTS) 进行重排序
在传统的 RAG 中,你可能会提取前 3 个检索到的例子并将其提供给模型。但如果第 4 个例子实际上比第 1 个好得多呢?如果第 1 个例子实际上是一个会让模型困惑的陷阱问题呢?
为了解决这个问题,作者将例子的选择视为一个决策博弈 , 并使用蒙特卡洛树搜索 (MCTS) 来解决它。MCTS 正是 AlphaGo 用来精通围棋的算法。
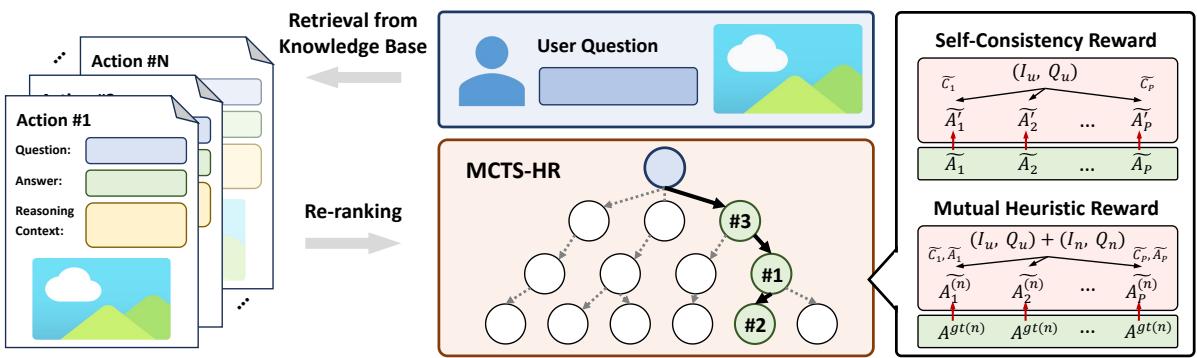
树结构
在这个“游戏”中,目标是构建完美的提示上下文。
- 根节点: 用户的原始查询。
- 动作: 选择一个特定的检索例子加入到上下文中。
- 节点: 一系列已选定的例子序列。
搜索过程
该算法迭代执行四个主要步骤:
- 选择: 它查看当前的可能性树,并选择一条能够平衡“探索” (新例子) 与“利用” (已知的好例子) 的路径。
- 扩展: 它向序列中添加一个新的例子 (动作) 。
- 模拟: 它使用选定的例子序列运行 LVLM,看看会发生什么。
- 反向传播: 它根据模型的表现更新该序列的“得分”。
秘诀: 启发式奖励
如果我们还不知道用户问题的答案,MCTS 怎么知道一系列例子是“好”的呢?这里作者引入了启发式奖励 。 由于我们无法直接检查答案,我们检查一致性 。
他们使用两种类型的奖励:
自洽性奖励 (\(Q_S\)): 系统使用选定的例子生成一个答案。然后,它利用预测的答案和推理上下文来生成更多的答案。如果模型持续生成相同的答案,则认为该上下文是高质量的。
互助启发式奖励 (\(Q_M\)): 这是一个绝妙的“合理性检查”。如果检索到的例子真的有帮助,它们应该也能帮助模型正确回答其他问题。 系统获取当前选定的例子,并尝试用它们来解决数据库中的其他问题 (已知答案的问题) 。如果当前例子能帮助解决那些参考问题,那么它们对于用户的问题来说可能也是稳健且有帮助的。
一组例子的最终得分是这两种奖励的加权组合。
实验与结果
增加所有这些复杂性——推理上下文和树搜索——真的值得吗?研究人员在几个具有挑战性的数据集上测试了 RCTS:
- ScienceQA: 具有多模态上下文的科学问题。
- MMMU: 涵盖大学水平学科 (艺术、商业、医学) 的大规模基准测试。
- MathV: 专门针对带视觉内容的数学推理数据集。
定量表现
结果显示 RCTS 明显优于标准方法。
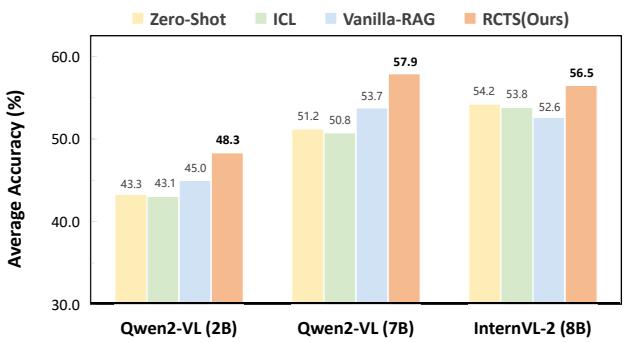
如图 1 所示,RCTS (橙色柱状图) 始终优于:
- Zero-Shot (零样本) : 不给例子直接问模型 (黄色) 。
- ICL: 标准的上下文学习 (绿色) 。
- Vanilla-RAG (普通 RAG) : 没有树搜索或推理上下文的标准检索 (蓝色) 。
在 MathV (数学视觉推理) 上的提升尤为显著。对于 Qwen2-VL (7B) 模型,RCTS 从大约 53.7% (普通 RAG) 跃升至 57.9% 。 在竞争激烈的 AI 基准测试领域,复杂推理任务上 4% 的增益是巨大的。
定性分析: 为什么 RCTS 会赢
数字虽好,但让我们看一个实际的例子来对比行为上的差异。
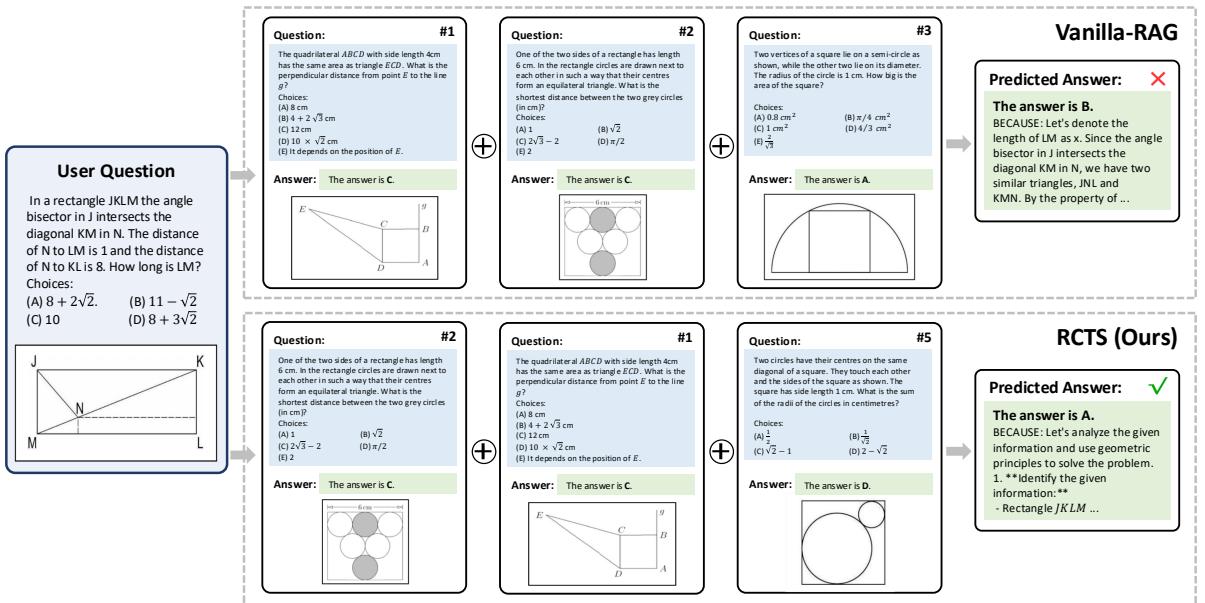
在图 6 中,我们看到一个几何问题,要求求出矩形中某条线段的长度。
- 普通 RAG (右上) : 它检索到的例子在几何上有些相关,但没有引导正确的逻辑。模型产生了一个错误的解释 (“让我们设…”) 并选择了错误的答案 (B)。
- RCTS (右下) : MCTS 过程过滤掉了令人困惑的例子,优先选择了那些能促进清晰、分步几何推理的例子。因此,模型正确分析了距离并推导出了正确答案 (A)。
我们真的需要这两个部分吗? (消融实验)
你可能会想: 提升是来自推理上下文还是树搜索?
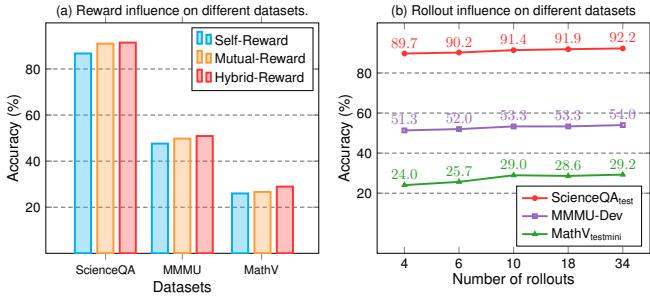
作者进行了消融实验 (拆解模型以测试组件) 。 图 5(a) 显示,使用混合奖励 (红色柱状图) ——结合自洽性和互助奖励——比单独使用其中任何一种效果都要好。
此外,表 4 (参考论文) 证实了:
- 仅使用 MCTS 能提高结果。
- 仅使用推理上下文能提高结果。
- 两者结合使用能产生最高的性能。
这证实了高质量的数据 (推理上下文) 和高质量的选择 (MCTS) 是相辅相成的。
结论与启示
“树搜索重排序推理上下文” (RCTS) 框架代表了多模态 AI 向前迈出的成熟一步。它承认仅仅获取信息 (检索) 是不够的;AI 需要被展示如何思考这些信息。
通过自动化创建推理链并使用博弈论方法 (MCTS) 来选择最佳的“教学范例”,RCTS 将 LVLM 从简单的模式匹配器转变为更稳健的推理者。
关键要点:
- 上下文至关重要: 提供“思维过程”和答案比仅提供答案更有价值。
- 选择是关键: “最相似”的例子并不总是最有帮助的。我们需要智能搜索算法来确定哪些例子实际上有助于推理。
- 自我修正: 使用一致性检查允许模型在提交答案之前对自己潜在的输入进行评分。
随着 LVLM 在规模和能力上的不断增长,像 RCTS 这样的框架对于弥合原始知识与真正理解之间的鸿沟将至关重要,从而确保 AI 能够处理我们所处的复杂、微妙的视觉世界。