](https://deep-paper.org/en/paper/2507.01204/images/cover.png)
引言
在数字媒体的世界里,我们一直在质量和文件大小之间进行着一场拉锯战。我们想要晶莹剔透的 4K 图像,但同时也希望它们能瞬间加载,并且不占用手机存储空间。几十年来,像 JPEG、HEVC 和 VTM 这样由人工设计的算法一直占据着主导地位。但最近,一位挑战者进入了竞技场: 神经图像压缩 (Neural Image Compression) 。
神经编解码器通常使用深度学习来寻找比任何人类设计的公式都能更好地压缩图像数据的方法。然而,它们也有一个缺点。它们通常计算量很大,需要庞大的神经网络,这会消耗电池寿命并拖慢处理器速度。
但是,如果我们不需要从头开始训练一个庞大的网络呢?如果完美的图像压缩器已经存在于一个混乱的、随机初始化的神经网络中,我们只需要找到它呢?
这就是 LotteryCodec 背后的前提,这是一种打破图像压缩现状的开创性新方法。利用“彩票假设 (Lottery Ticket Hypothesis) ”,研究人员创建了一种编解码器,它使用未经训练的随机网络实现了超越最先进经典编解码器 (VTM) 的压缩性能,同时解码过程非常轻量。
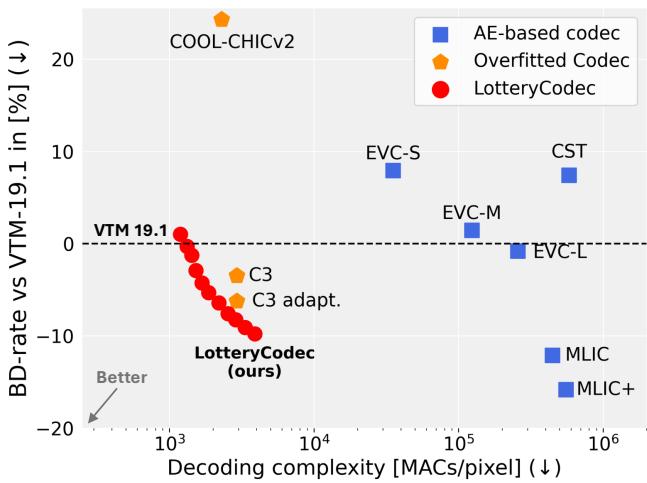
如图 1 所示,LotteryCodec (红色圆圈) 占据了一个“最佳平衡点”: 它提供了更好的压缩效率 (更低的 BD-rate) ,同时所需的运算量 (解码复杂度) 明显少于其他神经方法。
在这篇文章中,我们将揭秘这张“中奖彩票”是如何工作的,它是如何将图像编码进随机网络的结构中的,以及为什么这可能是我们设备上轻量级媒体的未来。
背景: 神经编解码器的演变
要理解 LotteryCodec 为何如此特别,我们需要看看神经压缩通常是如何工作的。
两种主要方法
目前,神经压缩主要有两种主导范式,如图 3 所示:
- 基于自编码器 (AE) 的编解码器 (图 3a) : 也就是所谓的“重型武器”。它们由在数百万张图像上训练的庞大编码器和解码器组成。它们是通才——知道如何压缩任何图像。然而,因为它们太大了,在移动设备上运行它们的计算成本非常高。
- 过拟合编解码器 (图 3b) : 这是一种较新的、令人着迷的方法。我们要做的不是训练一个通用网络,而是训练一个微小的、特定的神经网络来只记住这一张图片。然后我们传输这个微小网络的权重。这被称为隐式神经表示 (Implicit Neural Representation, INR) 。
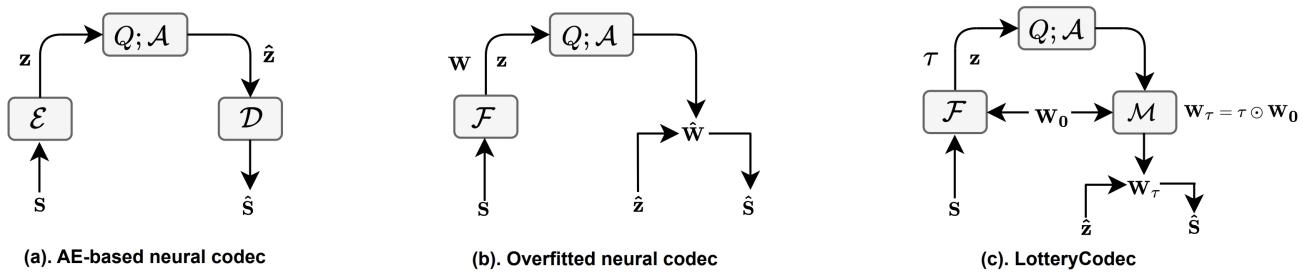
标准的过拟合编解码器 (如“COIN”或“COOL-CHIC”方法) 很有前景,因为解码器很小。然而,为了获得高质量的图像,你通常需要让网络变大或训练更长时间,这会增加文件大小,因为你必须传输所有那些浮点数权重 (参数 \(\mathbf{W}\)) 。
强彩票假设
LotteryCodec 走出了第三条路 (图 3c) ,其灵感来自机器学习中一个名为强彩票假设 (Strong Lottery Ticket Hypothesis, SLTH) 的概念。
最初的彩票假设指出,在密集的、训练过的神经网络内部,存在着稀疏的子网络 (“中奖彩票”) ,如果单独训练它们,可以达到类似的性能。 强版本的假设更进一步: 它认为如果一个随机初始化的网络足够大,它已经包含了一个无需任何权重训练就能表现良好的子网络。你只需要修剪掉“坏”的连接。
这就是 LotteryCodec 的核心洞察: 不要传输权重。传输架构。
彩票编解码器假设
作者提出了彩票编解码器假设 (Lottery Codec Hypothesis) 。 它指出,在一个足够大的随机神经网络中,存在一个子网络可以作为图像压缩的合成网络,其性能可与完全训练好的网络相媲美。
为什么这很重要?
- 效率: 我们不需要传输沉重的 32 位浮点权重。我们只需要传输一个二进制掩码 (0 和 1) ,告诉解码器保留哪些连接。
- 先验知识: 随机初始化的网络实际上能出奇好地捕捉自然图像的统计数据 (这一概念被称为深度图像先验,Deep Image Prior) 。
LotteryCodec 如何工作
LotteryCodec 系统是一个过拟合编解码器 。 这意味着对于你想压缩的每张图像,系统都会执行搜索以找到针对该特定图像的最佳配置。
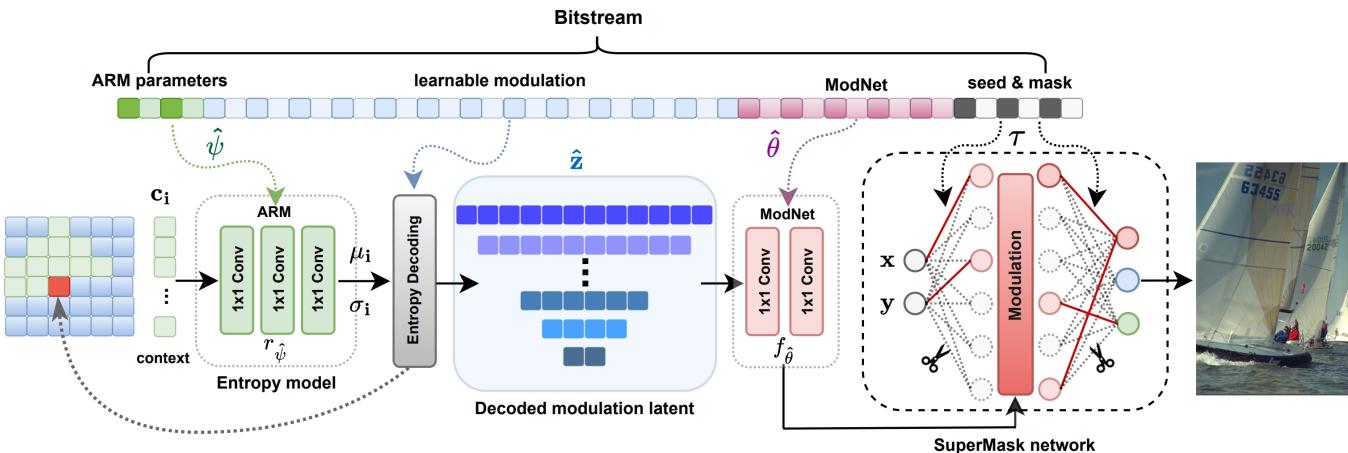
以下是高层工作流程,如图 2 所示:
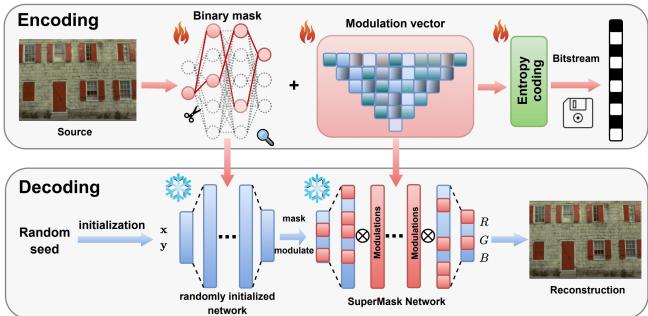
1. 共享随机网络
发送方 (编码器) 和接收方 (解码器) 商定一个随机种子 。 这个种子用于初始化一个巨大的、“过参数化”的神经网络。因为他们共享种子,所以生成的随机权重完全相同。 不需要传输任何权重。
2. 寻找“中奖彩票” (SuperMask)
编码器的工作是在这一团随机的网络中找到一个能够重现目标图像的子网络。它通过学习一个二进制掩码 (\(\tau\)) 来实现这一点。
如果网络中的某个连接有助于重建图像,掩码就被设为 1。如果没用,就是 0。这个过程有效地将随机网络“剪枝”成特定的形状。
这个“SuperMask 网络”中一层的数学运算如下所示:
\[ v _ { k } ^ { ( i ) } = \sigma \left( \sum _ { j = 1 } ^ { d _ { i - 1 } } \tau _ { k , j } ^ { ( i - 1 ) } w _ { k j } ^ { ( i - 1 ) } m ( v _ { j } ^ { ( i - 1 ) } ) \right) , \]这里,\(\tau\) 是学习到的掩码,\(w\) 是冻结的随机权重。由于 \(\tau\) 是二进制的,与完整权重相比,压缩和传输它的成本极低。
3. 潜在调制与 ModNet
仅仅修剪随机网络并不足以获得照片级的质量。网络需要引导。
LotteryCodec 输入坐标对 \((x, y)\) 来生成 RGB 像素。但作者引入了潜在调制 (Latent Modulations) , 而不是仅仅输入原始坐标。这些是微小的、可学习的向量 (\(\mathbf{z}\)) ,提供关于图像的高级信息 (如“这个区域是蓝天”或“这个区域是纹理”) 。
这些潜在变量由一个名为 ModNet (调制网络) 的小型辅助网络处理。ModNet 接收压缩的潜在代码并生成调制参数,用于调整主随机网络的激活。
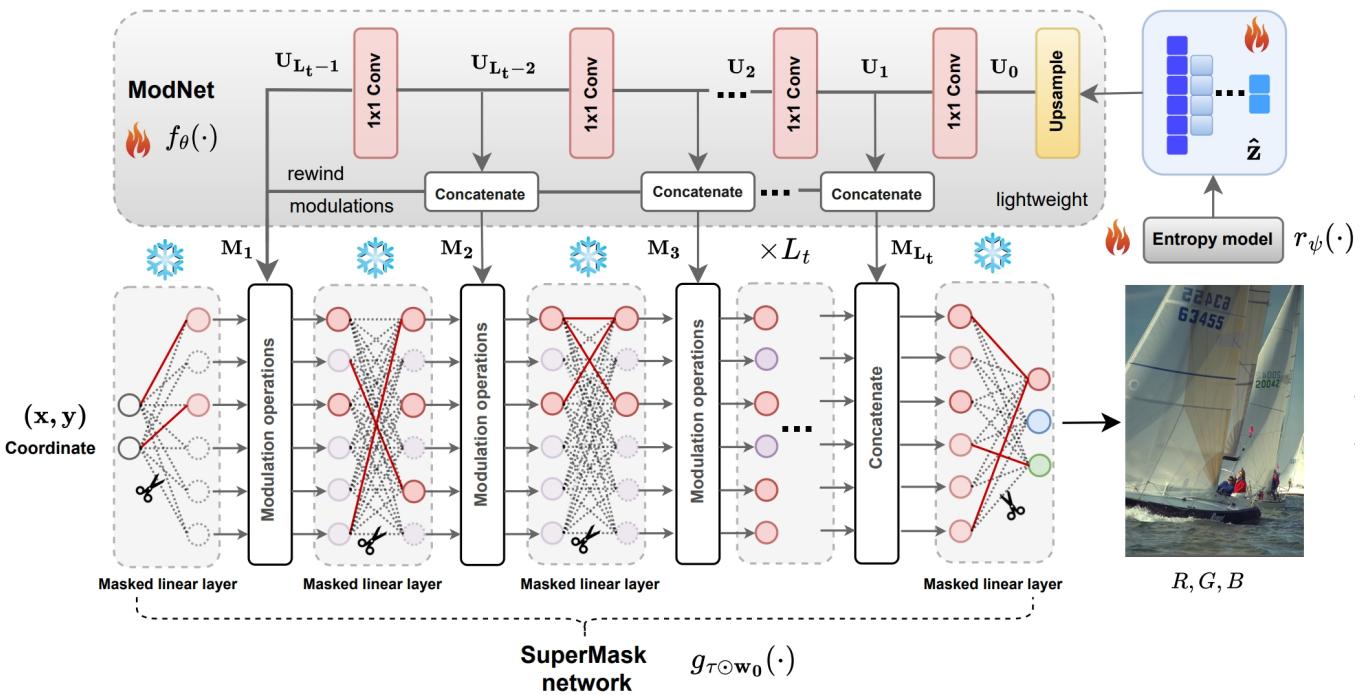
如图 5 所示,SuperMask 网络 (右) 具有冻结的权重。“中奖彩票”由红色实线 (掩码) 定义。ModNet (左) 将信号注入该结构,以引导随机权重生成正确的颜色和形状。
4. “倒带”调制机制
这篇论文最聪明的贡献之一是倒带调制 (Rewind Modulation) 。
在标准的深度学习中,信息是向前流动的。然而,在随机图中搜索子网络是很困难的。为了简化这一过程,作者以相反的顺序将 ModNet 的特征馈送到合成网络中。
ModNet 的深层 (包含粗略的高级信息) 调制合成网络的浅层。ModNet 的浅层 (细节信息) 调制合成网络的深层。这种“倒带”策略丰富了随机网络的结构信息,使得找到高性能的子网络变得容易得多。
解码过程
LotteryCodec 的美妙之处在于解码。它非常轻量级。
- 初始化: 解码器使用共享种子生成随机网络。
- 配置: 应用接收到的二进制掩码 \(\tau\),有效地删除无用的连接。
- 调制: 解码小的潜在向量 \(\hat{z}\) 并将其通过 ModNet。
- 合成: 被掩码处理后的随机网络处理坐标和调制信息,生成最终图像。
因为掩码使网络变得稀疏 (移除了 50-80% 的连接) ,解码器可以跳过大部分数学运算。这就是性能图表中显示的低“MACs/pixel” (每像素乘累加运算) 的原因。
实验与结果
研究人员在标准数据集 (Kodak 和 CLIC2020) 上测试了 LotteryCodec,并将其与图像压缩领域的重量级选手进行了比较。
假设验证
首先,他们必须证明假设是真实的。随机网络中真的包含一个好的压缩器吗?

图 6 证实了这一点。图表显示,如果随机网络足够宽 (过参数化) ,“C3-Lottery” (该编解码器使用彩票方法的版本) 就能匹配甚至击败全训练网络 (C3 基线) 的性能。这证明了如果网络足够大且可供剪枝, 训练权重并不是绝对必要的 。
率失真性能
任何编解码器的终极测试都是率失真 (RD) 曲线。你希望曲线尽可能靠向左上角 (高质量,低比特率) 。
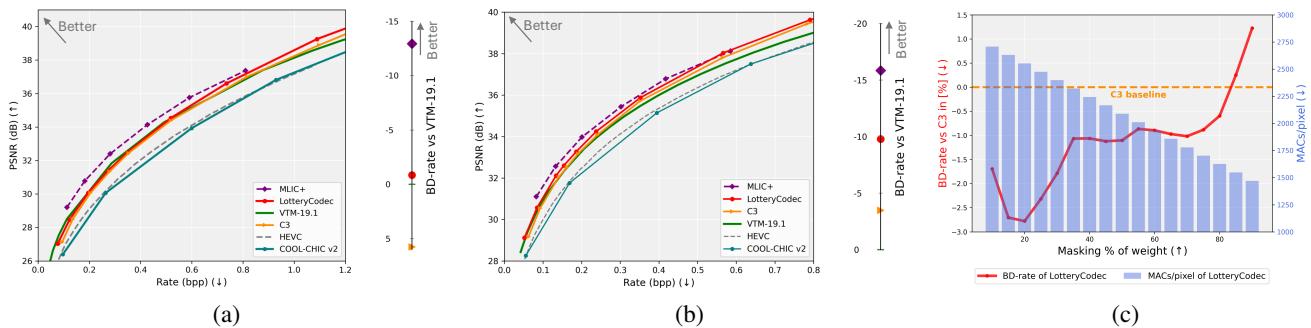
图 7 展示了结果:
- 击败 VTM: LotteryCodec 优于 VTM-19.1 (通用视频编码标准的参考软件) 。对于过拟合神经编解码器来说,这是一个巨大的成就。
- 击败神经竞争对手: 它明显优于其他过拟合编解码器,如 C3 和 COOL-CHIC。
- 低比特率: 它在低比特率下表现尤为出色,因为与浮点权重相比,二进制掩码的存储效率极高。
视觉质量
“调制”实际上做了什么?下面的可视化展示了不同的潜在向量 (\(\mathbf{z}\)) 如何对最终图像做出贡献。

在图 18 中,我们可以看到潜在代码 (\(\mathbf{z}_1\) 到 \(\mathbf{z}_7\)) 捕捉了不同的频率。有些捕捉整体形状 (灯塔) ,而另一些则填充精细纹理。系统学会了自动平衡这些信息。
自适应复杂度
最后一个优势是灵活性。通过改变掩码比例 (Mask Ratio) (即我们剪枝掉多少连接) ,我们可以用质量换取速度。
- 高掩码比例 (例如 90% 被剪枝) : 解码极快,质量略低。非常适合旧手机或省电模式。
- 低掩码比例 (例如 20% 被剪枝) : 质量最高,速度稍慢。
这使得 LotteryCodec 能够适应运行它的设备,这是大多数静态神经网络所缺乏的功能。
结论
LotteryCodec 代表了神经图像压缩的一次范式转变。它摒弃了神经网络的“智能”完全来自于训练权重的观念。相反,它表明智能可以在随机网络的结构中找到。
通过将图像编码为二进制掩码和一组调制,LotteryCodec 实现了:
- 最先进的性能: 击败了 VTM 和现有的过拟合编解码器。
- 低复杂度: 稀疏的、掩码处理后的网络运行速度快。
- 适应性: 同一个编解码器可以动态调整其计算成本。
这项工作验证了“彩票编解码器假设”,并为一类新的媒体格式打开了大门,这些格式高效、强大,并且建立在令人惊讶的随机性基础之上。当我们展望沉浸式视频和 AR/VR 的未来时,像这样的轻量级解码将是至关重要的。