](https://deep-paper.org/en/paper/2507.04635/images/cover.png)
引言
我们正目睹着多模态大语言模型 (MLLMs) 的黄金时代。从 GPT-4V 到 Gemini,这些模型预示着这样一个未来: 人工智能可以像人类一样感知世界——将文本、图像和音频整合成无缝的理解流。我们通常认为,既然模型能看见图像,它就完全理解了图像。
然而,如果你让这些模型稍微超越表面层次的描述,裂痕就会开始显现。让一个标准的多模态大语言模型解释电影场景中微妙的讽刺,或者扑克牌玩家脸上的一丝微表情,它往往会诉诸于幻觉或通用的猜测。
为什么会发生这种情况?为什么这些能通过律师资格考试的模型,却无法识别出《教父》中的角色快要哭出来了?
答案在于研究人员所称的 注意力缺陷障碍 (Deficit Disorder Attention, DDA) 问题。在这篇文章中,我们将剖析一篇引人入胜的新论文《MODA: MOdular Duplex Attention》 (MODA: 用于多模态感知、认知和情感理解的模块化双工注意力) ,该论文诊断了这一问题并开出了一种新颖的架构“处方”。我们将探讨在神经网络中分离“自我”与“交互”如何让 AI 掌握细粒度的感知、复杂的认知,甚至是情感理解。
诊断: 多模态大语言模型的注意力缺陷障碍
要理解解决方案,我们必须先了解病理。大多数现代多模态大语言模型都是通过将视觉编码器 (像一只数字眼睛) 拼接到巨大的大语言模型 (大脑) 上构建的。将它们维系在一起的“粘合剂”就是注意力机制。
研究人员发现,虽然这种架构在处理一般任务时有效,但它存在严重的失衡问题。
对文本的偏见
大语言模型是在浩瀚的文本海洋中预训练出来的。当你将视觉 Token (编码后的图像块) 引入其中时,模型的注意力机制会自然地倾向于它最熟悉的东西: 文本。
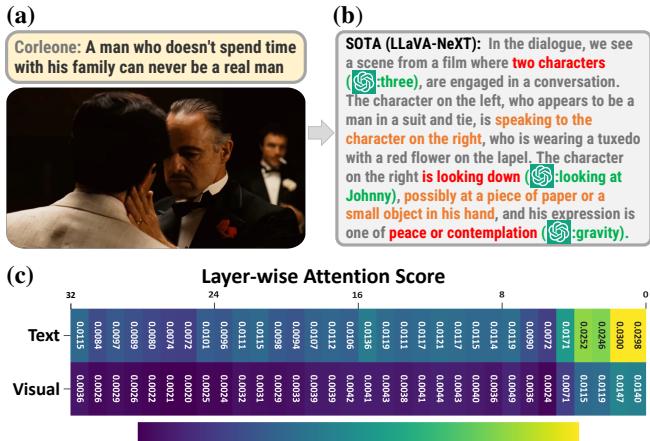
如上方的 图 1 所示,现有的最先进模型往往会遗漏细粒度的视觉线索。在《教父》的例子中,模型未能追踪角色之间具体的视觉互动,导致了对场景的“幻觉式”解释。它编造细节是因为它没有给实际的图像像素投入足够的注意力。
层级衰减现象
随着深入神经网络,问题会变得更糟。Transformer 模型由许多层堆叠而成。研究人员分析了这些层中的注意力分数——代表模型对不同输入关注程度的数值。
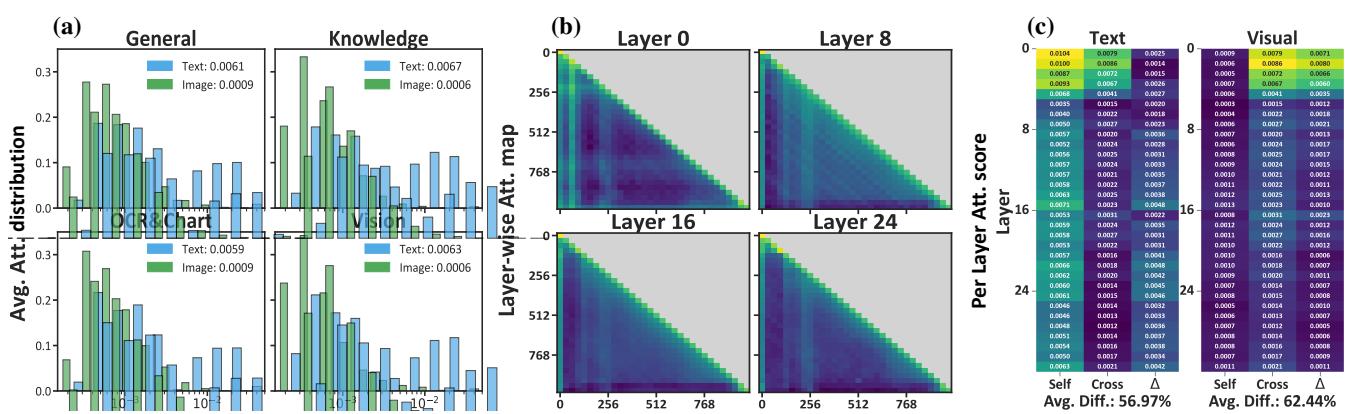
在 图 2 中,特别是面板 (b) 和 (c),我们看到了一个严峻的现实。在浅层 (早期层) 中,存在一些跨模态交互。但随着信息传播到深层 (进行复杂推理的地方) ,对视觉 Token 的注意力发生了崩溃。
这就是 注意力缺陷障碍 (DDA) 问题。模型对图像的关注度逐层呈指数级衰减。当模型试图得出一个高层结论 (比如“这个人是生气还是悲伤?”) 时,它实际上已经不再看图像,而是几乎完全依赖于文本提示。
在数学上,研究人员将这种累积误差 (\(\mathbb{E}_{DDA}\)) 描述为层级对齐误差 (\(\epsilon_l\)) 与衰减因子 (\(\gamma\)) 的乘积:
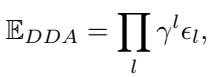
如果 \(\gamma \neq 1\) (这在文本占主导地位时是常态) ,误差就会随着深度呈指数增长。结果如何?一个在推理层对细微视觉细节功能性失明的 AI。
解决方案: 模块化双工注意力 (MODA)
为了解决这个问题,作者提出了 MODA 。 MODA 的核心理念是 解耦 。 MODA 不是让文本和视觉在一个混乱的注意力池中争夺主导地位,而是将过程拆分为两个截然不同、受控的流,并进行仔细的重新对齐。
该架构引入了一种名为 “先对齐后修正 (Correct-after-Align) ” 的策略。它由两个协同工作的主要组件组成:
- 双工注意力对齐 (Duplex Attention Alignment) : 确保各模态说同一种语言。
- 模块化注意力掩码 (Modular Attention Mask) : 强制信息的平衡流动。
让我们分解下图所示的架构。
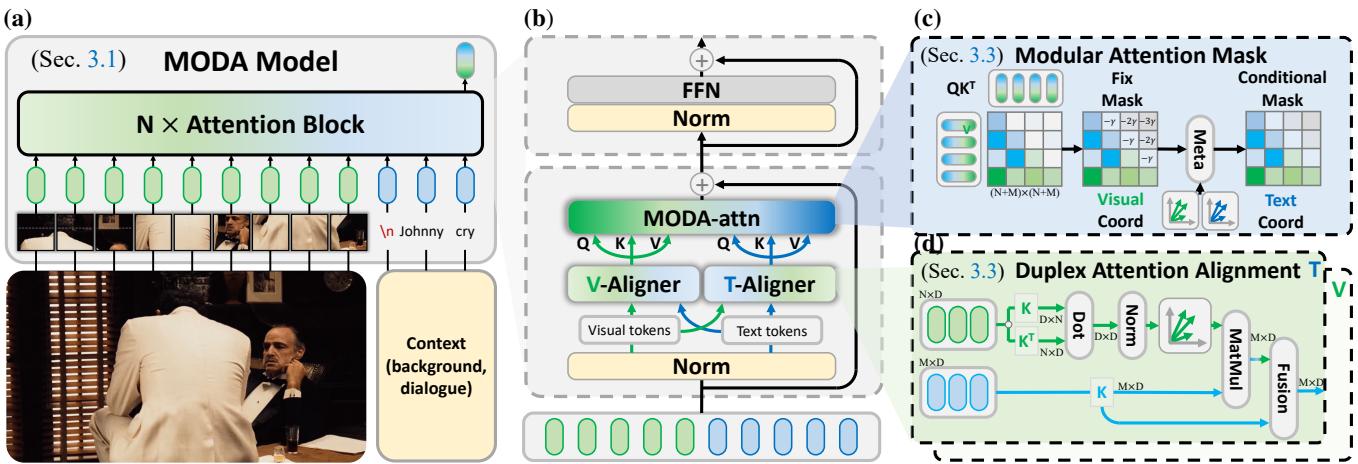
1. 双工注意力对齐
在标准的 Transformer 中,视觉 Token 和文本 Token 只是被扔在一起。因为它们来自不同的分布 (一个来自视觉编码器,一个来自文本嵌入) ,它们是错位的。
MODA 引入了一个 双工 (视觉/文本) 对齐器 (Duplex (V/T)-Aligner) (如图 3d 所示) 。其目标是在交互之前,将一个模态的 Token 映射到另一个模态的空间中。为了高效地做到这一点,作者利用了 格拉姆矩阵 (Gram Matrix) 。
在线性代数中,格拉姆矩阵表示一组向量的内积。它捕捉了特征空间的几何关系或“风格”。通过计算视觉 Token 的格拉姆矩阵,模型提取了视觉空间的“基向量”。
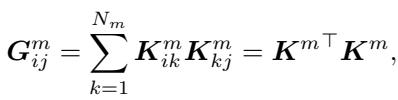
利用这个格拉姆矩阵,MODA 将来自另一个模态 (例如文本) 的 Token 投影到这个共享空间中:
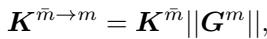
这创建了一个“共享的双模态表示空间”。这类似于翻译员不仅翻译文字 (文本) ,还翻译文化背景 (视觉风格) ,从而使对话 (注意力) 流畅进行。这确保了当文本关注图像时,它是在一个数学上对齐的向量空间中进行的。
2. 模块化注意力掩码
即使特征已经对齐,“文本偏见”仍可能导致模型在深层忽略图像。为了防止这种情况,MODA 实施了严格的 模块化注意力掩码 。
标准注意力允许每个 Token 查看其他所有 Token (\(N \times N\))。MODA 将其拆分。它明确分离了:
- 自模态注意力 (Self-Modal Attention) : 文本看文本;图像看图像。
- 跨模态注意力 (Cross-Modal Attention) : 文本看图像;图像看文本。
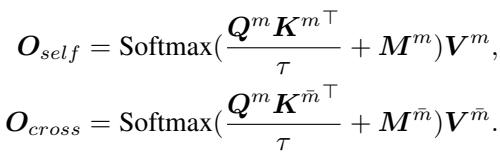
通过分离这些计算,模型可以对每一个应用不同的掩码规则。作者引入了一种“伪注意力”机制 (见下方的公式 14) ,其中多余的注意力值被存储和管理,而不是被丢弃或允许其占据主导地位。
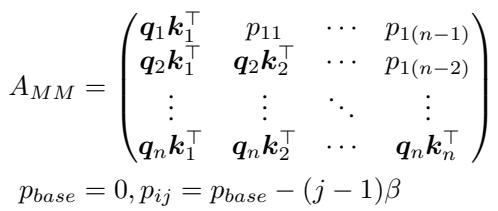
这种结构强制执行一种“模态位置先验”。它迫使模型在所有层中保持文本和视觉之间的活跃链接,防止我们之前看到的层级衰减。
实验结果
理论听起来很扎实,但它有效吗?研究人员在 21 个基准测试上测试了 MODA,涵盖了三种截然不同的能力: 感知、认知和情感。
1. 感知: 看见细节
感知任务询问关于视觉内容的直接问题 (例如,“这个牌子上写着什么?”或“船上有几个人?”) 。
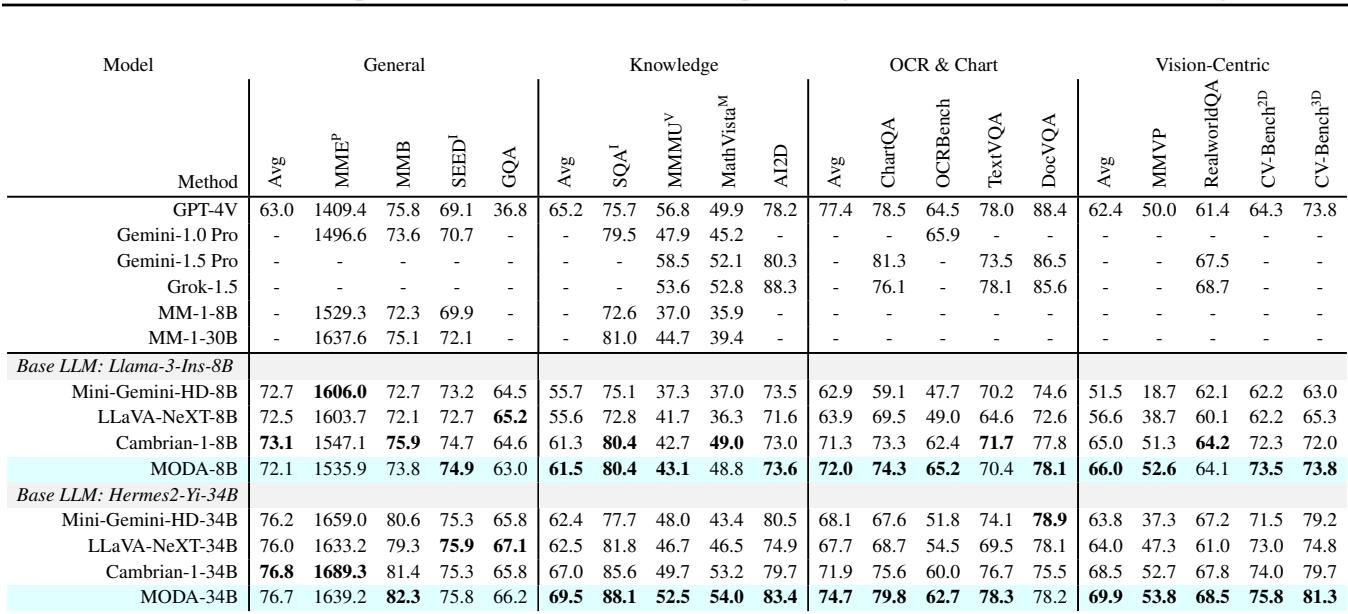
如 表 2 所示,MODA 始终优于同等规模的模型 (如 LLaVA-NeXT 和 Cambrian-1) 。值得注意的是 OCR & Chart (OCR 与图表) 和 Vision-Centric (以视觉为中心) 列。这些任务需要精确关注细小的视觉细节。MODA-8B 在这里大幅领先 LLaVA-NeXT-8B,证明了双工对齐有助于模型更准确地“阅读”图像。
2. 认知与角色扮演
认知涉及高阶推理。模型能采用某种人格吗?它能保持一致性吗?研究人员使用了 MMRole 基准来测试这一点。
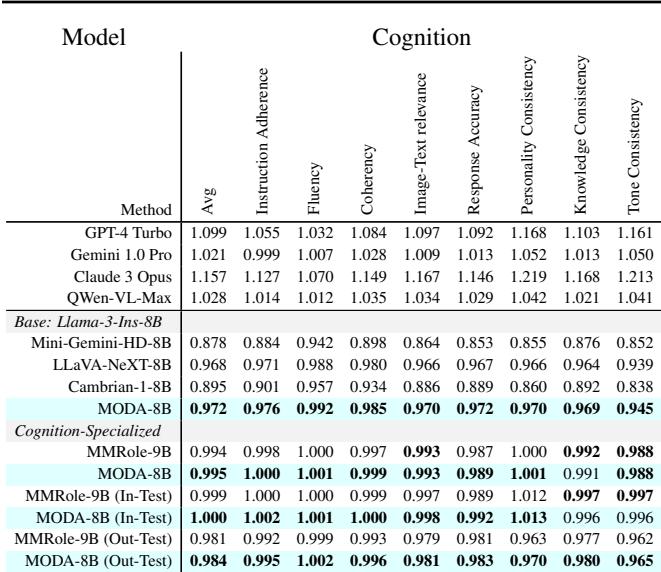
在 表 3 中,MODA 在 8B 模型中取得了最高的平均分 (0.995) ,甚至在某些指标上可以与专有的 Claude 3 Opus 媲美。它在 Instruction Adherence (指令遵循) 和 Personality Consistency (人格一致性) 方面表现出色,这表明通过更好地整合视觉背景,模型能更有效地“保持角色”。
3. 情感理解
这可能是 AI 最困难的任务。情感通常通过微妙的线索传达——扬起的眉毛、特定的调色板或物体的并置。
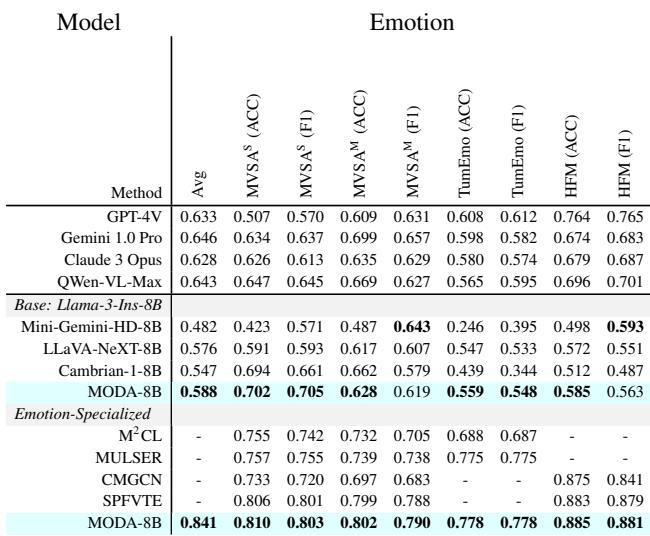
表 4 展示了 MODA 在情感计算方面的优势。在测试复杂情感和讽刺的 TumEmo 和 HFM (分层融合模型) 数据集上,MODA 优于通用 MLLMs,甚至击败了专门为情感识别设计的专用模型。
为什么有效: 分析注意力
研究人员重新审视了引言中的“热力图”以验证他们的假设。
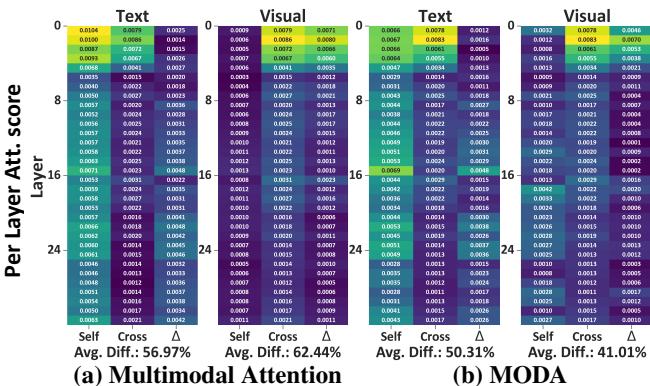
图 4 证实了修复效果。在面板 (a) 中,我们看到基线模型的视觉注意力 (图表右侧) 在深层逐渐消失在黑暗中。在面板 (b) 中, MODA 保持了高强度的注意力 (黄色/绿色) 覆盖从第 8 层到第 24 层的视觉 Token。“注意力缺陷障碍”得到了有效治疗。
案例研究: 教父
数字很棒,但定性示例向我们展示了模型是如何思考的。论文提供了一个引人注目的案例研究,使用了电影《教父》中的场景。
在这个场景中,用户要求模型解释场景,然后像教父 (唐·柯里昂) 一样规划一段对话。

洞察: 在 图 6 中,请注意 MODA 分析的深度。标准模型可能只看到“两个人在说话”。然而,MODA 识别出了“严厉的态度”和“权力动态”。它感知到了教父脸上关切的微表情。
规划: 当被要求继续对话时,MODA 模拟了角色的战略思维。它不仅生成通用的文本;它规划了一个回应,结合了同理心 (“这确实难以接受”) 与角色所期望的务实领导力 (“我们会一起想办法”) 。这需要将另一个角色的视觉情感状态 (约翰尼在哭) 与教父的人格进行综合。
结论
MODA 的开发突显了多模态 AI 演进中的一个重要教训: 仅靠规模是不够的。 单纯地把模型做得更大或在更多数据上训练,并不能自动解决像注意力缺陷这样的结构性低效问题。
通过识别特定的机制故障——深层视觉注意力的解耦——并通过 双工对齐 和 模块化掩码 设计出针对性的解决方案,研究人员解锁了 AI 理解的新粒度。
MODA 让我们更接近于那些不仅能“处理”图像,还能真正“感知”世界的智能体——识别模因中的幽默、帖子中的讽刺或电影场景中微妙的悲伤。随着多模态大语言模型继续融入我们的日常生活,这种理解人类体验细微差别的能力,将是区分机器人助手与真正智能伴侣的关键。