](https://deep-paper.org/en/paper/2507.05019/images/cover.png)
超越大数据: 小而多样的数据集能教会 Transformer 更好地泛化吗?
上下文学习 (In-context learning,ICL) 听起来就像魔法: 在提示中给模型展示几个示例,它便能在不更新任何参数的情况下执行新任务。这项能力——由 GPT-3 等大型模型首次展现——改变了我们对灵活人工智能的认知。但如今,要实现可靠的 ICL,通常依赖从网络上爬取的海量、未经筛选的数据集。这些数据集存储与处理成本高昂,往往带有偏见或噪声,更重要的是——它们让我们难以判断模型究竟是真正地泛化,还是仅仅在记忆。
最近的论文《元学习 Transformer 以提升上下文泛化能力》 (Meta-Learning Transformers to Improve In-Context Generalization) 提出了一个不同的问题: 如果我们不在单一庞大语料库上训练,而是在许多更小、精心策划的特定领域数据集上训练一个基于 Transformer 的上下文学习器,会怎样?多样性与精选数据能否在域外泛化和鲁棒性上超越单纯的规模?
本文将带你了解该论文的核心思想、方法和发现。我们将解释作者提出的 GEOM 框架,说明为什么 Meta-Album 是进行这些实验的理想平台,并探讨这些结果对关注实用性、可控性及隐私感知的模型训练从业者意味着什么。
概览: 你将学到的内容
- 为什么在多个小型、精心策划的数据集上训练,可能比在单一大型、未经筛选的语料库上训练更能提升上下文泛化能力。
- 如何将少样本分类任务转化为 Transformer 编码器可以处理的非因果序列。
- GEOM 系列方法 (GEOM、GEOM-M、GEOM-S、GEOM-U) 及实验设定: 监督式留一法、序列化流式学习和无监督伪任务训练。
- 关于类别多样性与总图像数量、课程顺序,以及无监督多数据集训练卓越性能的关键实证结论。
为什么重新审视“越大越好”的信条?
大规模、未经筛选的语料库无疑有其价值: 它们让模型接触到庞大的概念空间,并且在工程得当时能展现出令人惊叹的涌现能力。但它们同时也带来问题:
- 成本: 对于许多实验室和机构而言,存储和训练 PB 级数据代价高昂。
- 数据质量与平衡性: 网络规模的数据混乱不堪,模型往往从噪声和偏斜的表示中学习。
- 隐私与污染: 大规模数据抓取可能泄露敏感内容或测试集数据,混淆对真实泛化能力的评估。
而元学习则刻意训练模型快速适应新任务。论文作者将元学习的思想与 ICL 相结合,通过在多个小型、特定领域的数据集上训练 Transformer,使其成为一个上下文学习器。核心假设是: 经过精心策划的多样性加上元学习,可以在避免网络规模预训练弊端的同时促进泛化与模块化。
核心思想: 元学习一个上下文 Transformer
核心提案——GEOM (Generalization Over Memorization) ——将元学习重构为适用于 Transformer 的非因果序列建模问题。GEOM 并不针对每个任务单独微调,而是训练 Transformer 通过上下文 (支持) 集与查询共同输入,预测查询的标签,也就是实现真正的上下文学习。
图 1 展示了实验的主要范式: 跨域留一法训练与模拟数据集随时间到达的序列化 (流式) 训练。
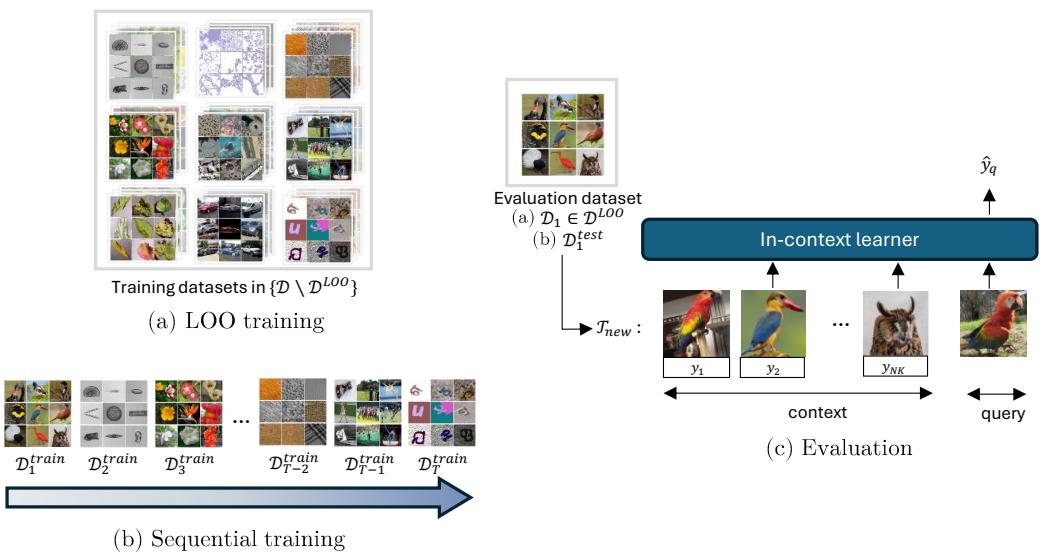
图 1: GEOM 概览。左侧: (a) 留一法 (LOO) 训练,其中一个域被留出用于评估;(b) 序列化训练,其中数据集逐个到达。右侧: 评估过程中带标签的上下文样本与查询一同输入上下文学习器以预测查询标签。
让我们具体化这些构件。
- 每个学习片段是一个 N-way K-shot 分类任务 (论文中多数实验使用 N=5, K=5) 。
- 对每个查询图像,Transformer 的输入是所有上下文 (图像、标签) 对加上查询图像嵌入的非因果拼接。这里的“非因果”意味着上下文样本的顺序无关紧要,Transformer 编码器可同时关注所有支持样本。
- GEOM 有三个核心组件:
- f_ψ: 特征提取器 (在 ImageNet-1k 上预训练的 ResNet-50) ,用于生成图像嵌入。
- g_φ: 线性标签编码器,将离散类别 ID 转换为可学习向量。
- M_θ: 非因果 Transformer 编码器,接收序列后生成查询输出以供分类头使用。
数学上,对于每个任务 i 及其 Q 个查询,查询 q 的序列为:
\[ S_{i,q} = ((f_\psi(x_1), g_\phi(y_1)), \dots, (f_\psi(x_{NK}), g_\phi(y_{NK})), f_\psi(x_q)) \]训练目标是最小化查询上的期望交叉熵损失:
\[ \min_{\theta,\phi} \mathbb{E}_{S_i} \left[ \frac{1}{Q} \sum_{q=1}^{Q} \mathcal{L}(M_\theta(S_{i,q}), y_q) \right]. \](其中 NK 是支持样本总数,y_q 是查询在支持集 N 个类别中的真实类别。)
为直观展示序列结构与目标函数,作者提供了示意图:
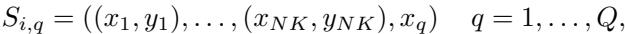
图: 从 NK 个上下文样本对和查询 x_q 构建非因果序列 S_{i,q}。
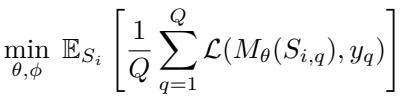
图: 在采样任务的查询上最小化训练目标。
实验平台: Meta-Album——精心策划的多域少样本数据集
实验并未使用单一庞大数据集,而采用 Meta-Album: 一个包含 30 个图像分类数据集的集合,覆盖 10 个领域 (大型动物、小型动物、植物、植物病害、显微镜学、遥感、车辆、制造业、人类动作与 OCR) 。每个领域包含三个在后续版本中添加的数据集;Meta-Album 提供 Micro / Mini / Extended 三种规模,以平衡类别多样性与每类图像数量。
由于 Meta-Album 是多域且经过精心策划的,它成为评估真正跨域泛化 (通过留一法评估) 的理想测试平台,同时也支持模拟数据逐步到达的序列化训练场景。
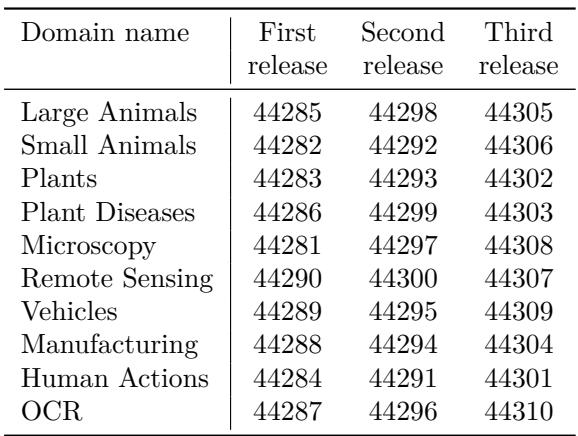
图: Meta-Album Mini 数据集 ID,按领域与版本排列 (每领域三个数据集) 。
实验: 三种现实场景
论文在三个互补设定中评估 GEOM 系列方法:
- 监督式 (离线) 留一法 (LOO) : 在九个领域的数据集上训练,留出一个领域评估跨域泛化。
- 序列化 (流式) 训练 (GEOM-S) : 数据集逐一呈现,早期数据不可再用,用于探查遗忘与终身学习行为并测试课程排序。
- 无监督训练 (GEOM-U) : 训练时无标签,通过增强与混合构造伪任务,以近似现实中大量未标记数据的情况。
在这些设定下,作者比较了多种变体:
- GEOM: 在单个 Meta-Album 数据集上训练 (从单数据集中采样任务) 。
- GEOM-M: 合并多个数据集为一个大数据集并从合并池中采样任务。
- GEOM-IN: 在 ImageNet-1k 上训练的基线。
- GEOM-S: 序列化变体,流式处理数据集。
- GEOM-U: 在未标记数据构建的伪任务上训练的无监督变体。
1) 监督式 (离线) LOO: 保持独立的数据集比简单合并更优
关键问题是: 将许多小数据集合并为一个“大数据集”更好,还是保持每个数据集独立训练更好?论文比较了 GEOM (独立) 、GEOM-M (合并) 和 GEOM-IN (ImageNet 基线) 在 LOO 设定下的效果。
主要结果:
- GEOM 经常与 GEOM-M 相当或表现更优。保持数据集独立性并从单数据集采样任务,能更好地提升跨域泛化。
- GEOM-IN 在与 ImageNet 类别高度重叠的领域 (如大型动物) 中占优,这更可能源于数据泄露或记忆,而非真正泛化。
- 在分布明显不同的领域 (如遥感: 航拍图像 vs 普通照片) ,GEOM 通常表现更好,因为它侧重学习适应策略,而非记忆类别。
下图总结了三种变体在 Meta-Album 数据集上的准确率以及与 ImageNet-1k 类别的重叠程度,解释了 GEOM-IN 的部分不公平优势。
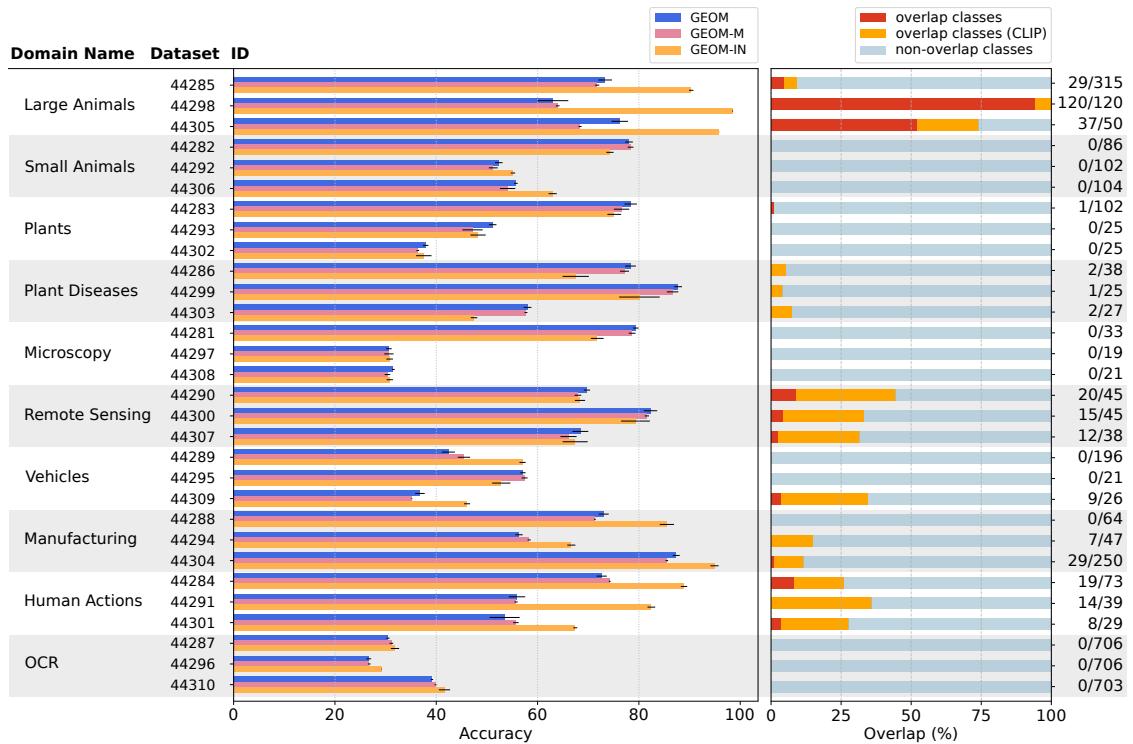
图 2: 左——在 Meta-Album Mini 数据集上的准确率比较: GEOM (蓝) 、GEOM-M (紫) 、GEOM-IN (橙) 。右——ImageNet-1k 与每个 Meta-Album 数据集之间的类别重叠比例 (红/橙表示重叠) 。
实践启示: 将不同来源的数据集混为一体会掩盖领域结构,阻碍学习可迁移的策略。若目标是跨域少样本适应,应保持数据集模块化,让元学习器接触特定领域任务。
2) 决定收益的因素: 类别多样性比图像数量更重要
对于上下文泛化而言,更重要的是类别数量还是每类图像数量?作者比较了三种 Meta-Album 规模:
- Micro: 类别少,图像数量与 Mini 相同。
- Mini: 类别更多,每类 40 张图像。
- Extended: 类别数量与 Mini 相似,但每类图像更多。
在外部基准 (CIFAR-fs、CUB、Aircraft、Meta-iNat、EuroSat、ISIC) 上评估了分布外迁移性能。
主要发现 (见论文表 2) :
- 从 Micro 变为 Mini 的提升最大——增加类别数量 (类别多样性) 效果显著。
- 图像数量增加 (Mini → Extended) 带来较小收益,并可能减慢早期收敛。
- Mini 模型初期收敛快但易过拟合,Extended 因数据更多而减轻过拟合。
这表明,元学习与 ICL 更受益于遇到多样化的任务类型,而非同类别重复曝光。
验证曲线显示 Mini 提早达到峰值后下降,而 Extended 稳步提升:
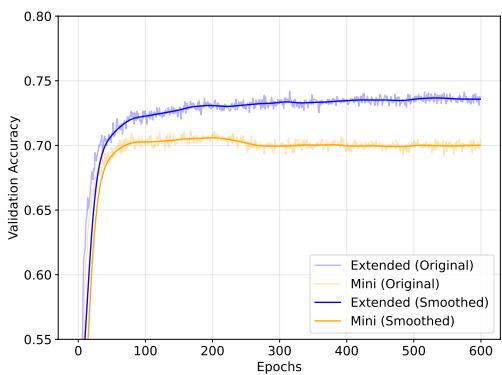
图 4: 验证性能: GEOM 在 Mini (橙色) 与 Extended (蓝色) 上的表现。Mini 早期峰值后下降 (过拟合) ,Extended 改进更持久。
实践启示: 在训练元学习或上下文学习模型时,优先提高类别与任务多样性,而非单纯增加同类图像数量。
3) 序列化学习 (GEOM-S): 随时间学习而不遗忘
真实系统中数据常随时间逐渐出现。GEOM-S 探讨上下文学习器能否在序列化训练下保持或改进早期领域表现,而无需排练 (即不存储旧数据) 。
实验要点:
- 数据集按顺序逐一加入 (30 个 Meta-Album 数据集) 。
- 两种周期分配策略:
- 静态: 每个数据集周期相等。
- 按比例: 周期与数据集大小成正比。
- 使用改进的反向迁移 (Backward Transfer, BWT) 评估领域层面的遗忘或提升。
令人惊讶的结果: 初期调整后,GEOM-S 常表现出正向反向迁移——新领域训练提升了旧领域表现。下面的热图显示各阶段的性能变化,紫色正值表示改善。
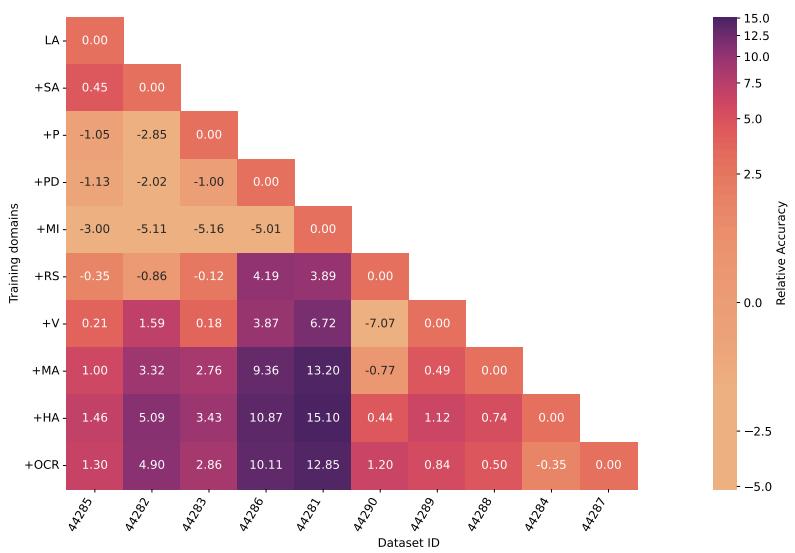
图 6: 用于计算 BWT 的热图: 每个单元格表示当训练进展到某阶段时某数据集准确率的变化。正值表示随着更多领域被学习,对早期领域的泛化提升。
为什么发生这种现象?看到更多类别与多样任务,使 GEOM-S 能提炼出适用于跨域的表示与策略。Transformer 并非灾难性遗忘,而是积累了更鲁棒的领域不变推理机制。
实践启示: 元学习的上下文学习器能跨域积累可迁移策略。在流式训练场景中,应合理分配训练时间 (尽可能按数据集大小) ,并考虑课程顺序。
课程学习: 顺序重要,且“难者先行”有时更佳
数据集顺序影响序列学习器的早期学习效果。作者实验了几种课程设定:
- 基于 TL 的课程 : 按微调难度排序 (即预训练 ResNet 在各数据集的微调效果) 。测试两种策略:
- 从易到难 (E2H)
- 从难到易 (H2E,反向课程)
- 基于 OT 的课程 : 使用最优传输数据集距离 (Optimal Transport Dataset Distance, OTDD) 衡量数据集相似性,并按局部相似度 (易到易,E2E) 或跳跃排序 (H2H、交替) 安排。
关键发现:
- 对于基于 TL 的排序,H2E (难到易) 通常优于 E2H。早期接触困难任务促使模型更充分探索参数空间,防止过早专化。
- 对于基于 OT 的排序,按相似度平滑递进 (E2E) 效果更佳,知识逐步积累可减少遗忘。
下面的图表总结了这些实验。
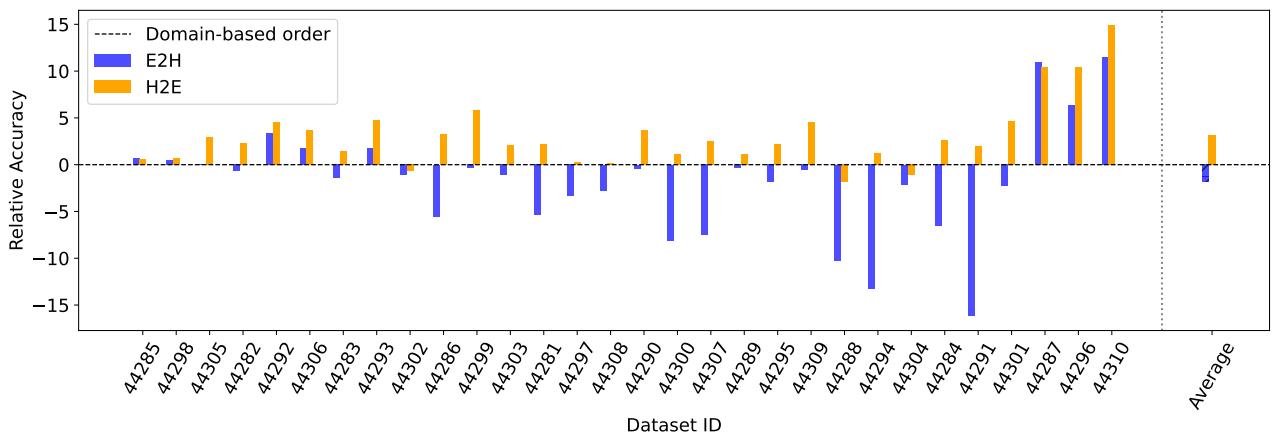
图 7: 相对准确率差异: E2H 与 H2E 相较于基线的结果。在基于 TL 的课程实验中,H2E 取得最佳平均增益。
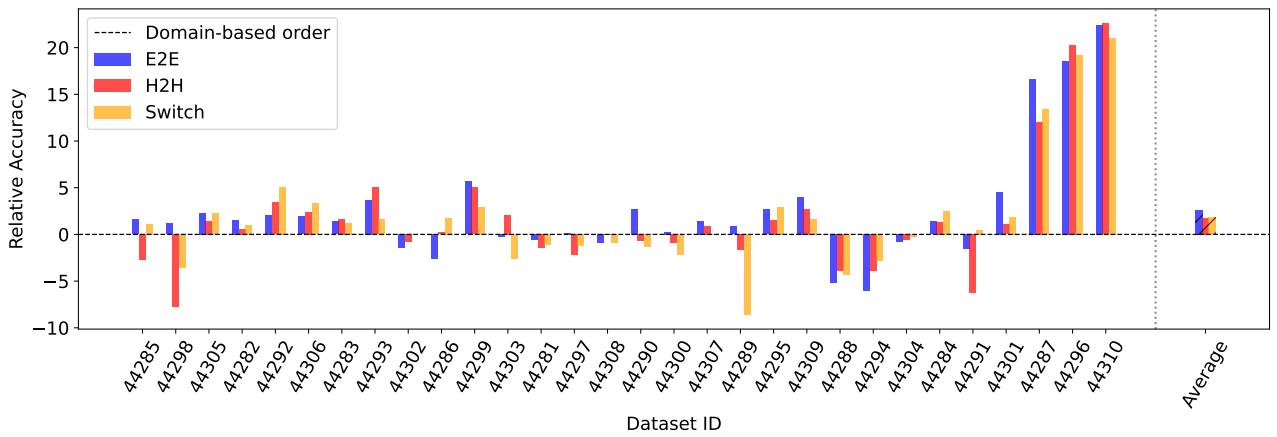
图 9: 基于 OT 的课程比较: E2E、H2H、Switch 与领域基线相比。E2E 通过顺序呈现相似数据集,往往获得稳定改进。
实践启示: 课程设计需因地制宜。当预训练特征提取器带来偏差时 (TL 排序) ,困难任务优先可促进更宽泛的表示学习;当可直接测量数据集相似性 (OTDD) 时,按相似度递进的结构化课程通常提升持久性与性能。
4) 无监督训练 (GEOM-U): 未标记的小数据集优于未标记的 ImageNet
标注数据昂贵,因此作者研究了一种受 CAMeLU 启发的无监督变体: 在未标记数据上构造伪任务,通过将同一图像的增强版本分组为伪类别,并用增强与混合 (类似 mixup) 生成查询样本。GEOM-U 在 Meta-Album Mini 上无标签训练,CAMeLU 则以相同方式在无标签的 ImageNet-1k 上训练。
结果: 在 LOO 评估中,GEOM-U 在多数 Meta-Album 域上优于 CAMeLU。跨多个多样化小数据集的多域训练比在单一庞大未标记语料库上产生更具域不变性的上下文学习器。
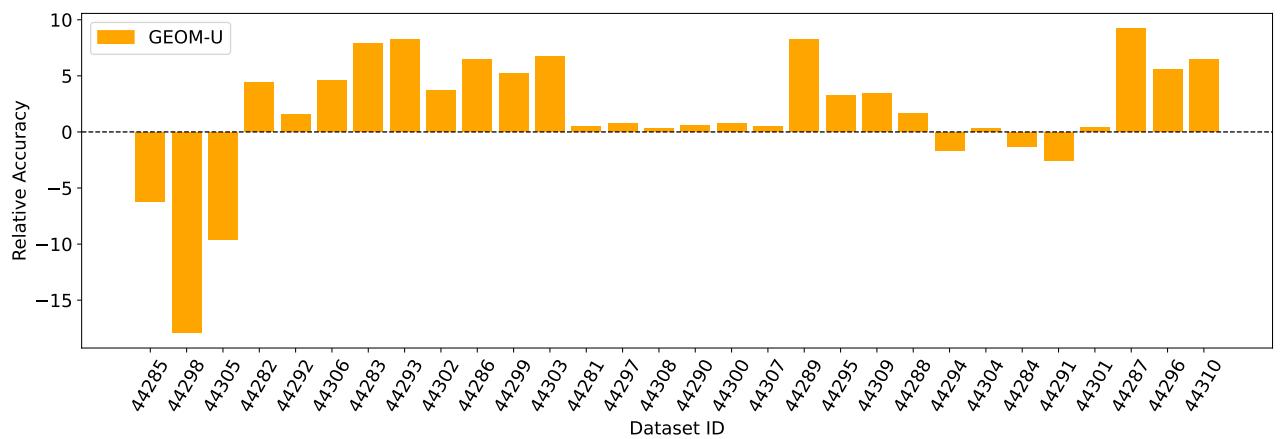
图 10: GEOM-U 与 CAMeLU (均为无监督训练) 在各域上的相对准确率差异 (GEOM-U − CAMeLU) 。除与 ImageNet-1k 高度重叠的领域外,GEOM-U 通常更优。
原因在于: 多样化小数据集迫使模型在训练中解决不同视觉识别风格与增强任务,促使学习器构建灵活的上下文映射机制,而非依赖 ImageNet 类别先验。
实践启示: 若必须进行无监督训练,优先选择多个多样化的特定领域数据集,而非单一庞大异质语料库。任务多样性是提升上下文鲁棒性的关键。
鲁棒性与标签噪声
作者还测试了支持集标签噪声下的鲁棒性: 当部分支持标签错误时会怎样?GEOM 在中等噪声比例 (如 10–25% 错误标签) 下仍保持鲁棒性。更有趣的是,少量标签噪声可起到正则化作用,有时反而提升跨域泛化,与其它鲁棒性研究一致。
实践建议
若你希望在有限资源下构建可靠的上下文学习器 (或少样本元学习器) ,这些发现提供了以下指导:
- 优先使用多个精心策划的数据集,每个数据集涵盖不同领域或模态,而非将所有数据混合为庞大无结构的数据池。
- 采集新数据时,先增加类别 (任务多样性) ,再增加每类图像数。
- 对于持续或流式学习:
- 若可行,按数据规模分配训练时间;否则采用课程学习。
- 当存在预训练骨干时,从困难数据集开始 (H2E) 更佳;若能计算数据集相似度,采用基于 OT 的逐步课程方案。
- 对于无监督训练,应聚合多样化的小型未标记数据集,并通过增强构造伪任务,而非依赖单一庞大未标记语料库。
- 保持数据集独立与模块化,以便审计、更新或移除问题数据,有助于隐私与数据治理。
局限性与开放问题
论文显示 GEOM 在多种设定下可匹敌或超越部分基线,但并非大规模预训练的万能替代。存在若干权衡:
- 某些领域 (如制造业,侧重低层特征) 在依赖纹理或低级线索的任务上仍可受益于 ImageNet 级预训练。
- 实验中许多设定冻结了 ResNet 特征提取器,若进行联合端到端训练可能改变动态 (论文提供了消融研究) 。
- 课程设计需谨慎选择度量 (TL vs OT) 且 OTDD 计算代价高。
作者指出的未来方向包括:
- 针对资源受限环境优化每类图像数量。
- 根据运行中性能动态调整顺序的自适应课程。
- 将 GEOM 扩展至因果架构及更广泛任务类型。
总结
本论文提出了一个重要而实用的反例,挑战了当前盛行的“规模至上”理念。通过在多个精心策划的特定领域数据集上元学习一个上下文 Transformer,GEOM 实现了强大的域外泛化、稳健的序列化学习,并在无监督训练中也展现出令人惊喜的性能。
如果你正构建少样本或上下文系统,并追求更高的可解释性、模块化与数据治理——或无法承担网络规模预训练的成本——这项研究提供了明确的替代思路: 当目标是可适应且泛化的上下文学习时, 精心策划的多样性胜过纯粹的规模 。
致谢: 本文讨论的实验与图表引自 Braccaioli 等人的论文《Meta-Learning Transformers to Improve In-Context Generalization》。
延伸阅读 (精选) :
- CAMeLU: 基于上下文的无监督元学习 (Vettoruzzo 等,2025)
- Context-Aware Meta-Learning (CAML, Fifty 等,2024)
- 用于数据集相似度计算的 Optimal Transport Dataset Distance (OTDD) (Alvarez-Melis & Fusi, 2020)
若要复现或扩展这些实验,论文的补充材料中提供了代码、Meta-Album (Mini/Extended) 的详细数据划分、课程顺序与训练超参数。