](https://deep-paper.org/en/paper/2507.08254/images/cover.png)
在人工智能飞速发展的世界里,通常有一条不成文的游戏规则: 如果你想让模型在某项特定任务上表现出色,你就必须用大量的特定数据来训练它。如果你想从 3D MRI 扫描中诊断疾病,传统智慧告诉你,需要构建一个复杂的 3D 神经网络,并喂给它成千上万个带标注的医学体数据。
但如果这个假设是错的呢?
如果你可以采用一个通用的视觉模型——一个在狗、风景和汽车照片上训练出来的模型——用它来以最先进的 (SOTA) 准确率分析复杂的 3D 医学扫描,而且完全不需要进行任何训练,那会怎样?
这就是最近一篇研究论文中提出的突破性技术 Raptor (Random Planar Tensor Reduction,随机平面张量降维) 的前提。Raptor 挑战了医学 AI 中“数据饥渴”的现状。通过巧妙地结合 2D 基础模型和名为随机投影的数学概念,Raptor 生成的 3D 体数据嵌入不仅轻量、可扩展,而且惊人地比那些专门在医学数据上训练的模型更有效。
在这篇深度文章中,我们将探索 Raptor 的工作原理、使其成为可能的数学基础,以及为什么它可能代表了医疗保健等资源受限领域中 AI 的范式转变。
问题: 3D 中的维度诅咒
要理解为什么 Raptor 是如此重大的突破,我们首先需要看看 3D 医学影像分析面临的障碍。
医学数据,如磁共振成像 (MRI) 或计算机断层扫描 (CT) 扫描,是体积数据。标准的 2D JPEG 图像是由像素组成的网格,而医学体数据则是由体素 (体积像素) 组成的网格。标准的图像可能是 \(256 \times 256\) 像素,而医学体数据则是 \(256 \times 256 \times 256\)。
这个增加的维度带来了巨大的计算代价:
- 计算成本: 处理 3D 数据需要特定的架构 (如 3D 卷积神经网络或 3D Transformer) ,这会带来立方级的计算成本。内存需求爆炸式增长,通常需要昂贵的专用硬件 (如 H100 GPU 集群) ,这对许多大学实验室和医院来说是遥不可及的。
- 数据稀缺: 现代 AI 依靠规模效应蓬勃发展。我们拥有包含数十亿张 2D 图像的数据集 (比如用于训练 DINOv2 或 CLIP 的数据) 。相比之下,最大的公共 3D 医学数据集仅包含大约 10 万到 16 万个体数据。这比有效从头训练“基础模型”所需的数量级要小好几个数量级。
由于这些限制,研究人员一直难以扩展用于医学体数据的大型模型。现有的最先进 (SOTA) 方法,如 SuPreM、MISFM 或 VoCo , 试图通过在现有医学数据集上进行预训练来解决这个问题,但它们仍然需要大量的计算资源来进行训练和微调。
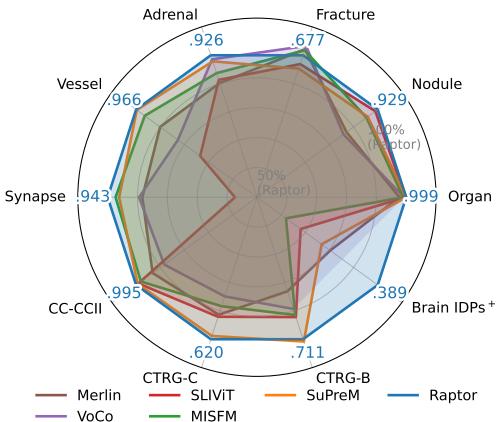
Raptor 登场了。如下图雷达图所示,这种新方法在从器官分类到结节检测等各种任务中,都优于这些专门的医学模型,而且从未在训练阶段“看”过任何医学体数据。
核心概念: 3D 世界中的 2D 模型
驱动 Raptor 的核心洞察是: 我们不一定需要一个 3D 大脑来理解一个 3D 物体。就像建筑师可以通过看平面图和立面图来理解建筑一样,AI 也可以通过分析 2D 横截面来理解体数据。
此外,我们已经拥有了极其强大的 2D“眼睛”。像 DINOv2 (Meta 训练的视觉 Transformer) 这样的基础模型已经看过了数十亿张图像。它们学会了识别边缘、纹理、形状和语义关系。Raptor 假设这些特征是通用的。无论是在跑车的挡泥板上还是在 CT 扫描中的肾脏边缘,曲线就是曲线。
Raptor 流程
Raptor 的工作流是优雅与效率的典范。它完全避免了训练神经网络。相反,它作为一个特征提取管道运行。让我们分解一下下图中可视化的架构。
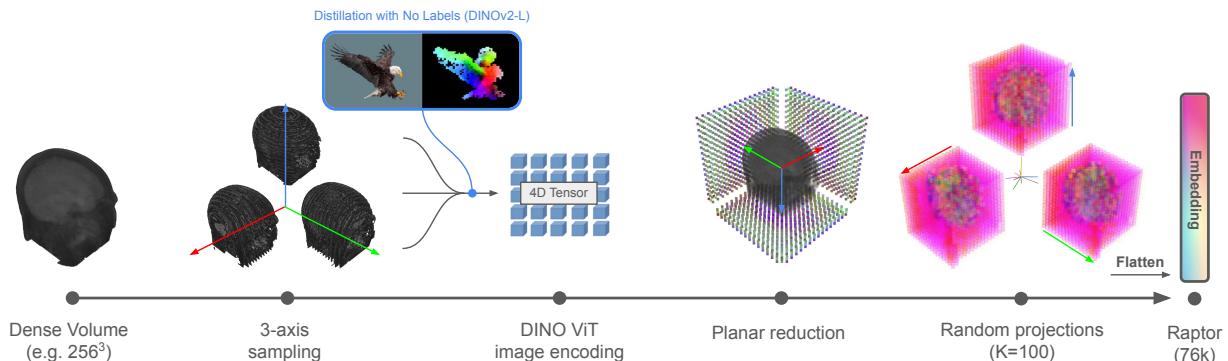
步骤 1: 三轴体积采样
密集的 3D 体数据很难一次性处理。Raptor 首先沿着三个正交轴对体积进行切片:
- 轴状面 (Axial) : 自上而下的视角 (就像低头看头顶) 。
- 冠状面 (Coronal) : 前后视角 (就像看一张脸) 。
- 矢状面 (Sagittal) : 侧视图 (就像侧面轮廓) 。
通过从这三个视角获取切片,该方法无需 3D 卷积即可捕获内部结构的几何形状。这通常被称为“三平面”方法。
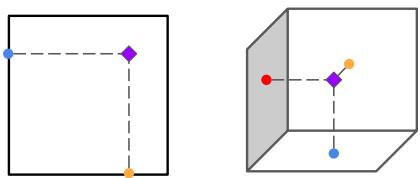
为了直观地理解为什么观察这三个平面足以重建 3D 信息,请看下面的三角测量原理图。如果你知道一个特征在“地板” (轴状面) 和“墙壁” (冠状面) 上的位置,你就可以确定它在 3D 空间中的位置。
步骤 2: 使用 DINOv2 进行特征提取
一旦体积被切片,每张 2D 图像都会被输入到一个冻结的 DINOv2-Large 图像编码器中。
“冻结”是这里的关键词。这个神经网络的权重从未更新。Raptor 完全按照下载时的原样使用该模型。该模型为图像的每个补丁输出一组特征标记 (代表视觉信息的向量) 。
然而,这产生了一个新问题: 数据爆炸。 如果你取一个 \(256^3\) 的体积并提取每个切片的深度特征,你最终会得到一个巨大的张量——可能比原始体积本身还要大。为 10 万个体积的数据集存储这些原始特征将需要数十 TB 的空间。我们需要一种在不丢失语义信息的情况下压缩这些信息的方法。
步骤 3: 随机平面张量降维
这是这篇论文的主要贡献。如何将巨大的特征张量压缩成一个小的、可用的向量?
Raptor 采用了一种两步降维策略:
- 轴向聚合: 对于特定轴 (比如轴状面) ,Raptor 对所有切片的特征取平均值。这折叠了深度维度。你可能会认为平均切片会破坏信息,模糊不同的器官。然而,由于医学解剖结构在空间上的变化相对平滑,聚合统计数据仍然具有高度的信息量。
- 随机投影: 即使经过平均,特征向量仍然是高维的。为了进一步缩小它们,Raptor 将特征向量乘以一个随机矩阵 (\(R\)) 。
数学运算如下所示:
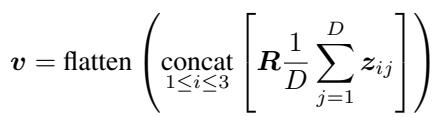
在这里,\(z_{ij}\) 代表来自视觉 Transformer 的特征,\(R\) 是一个填充了从正态分布中抽取的随机数的矩阵。
等等,随机数?
这看起来似乎违反直觉。将精心提取的特征乘以一个随机噪声矩阵怎么会有帮助呢?
这依赖于 Johnson-Lindenstrauss (JL) 引理 。 简单来说,JL 引理指出,高维空间中的点可以投影到低维空间中,同时近似保持它们之间的距离。
如果在 DINOv2 的高维特征空间中,两个医学扫描“语义上相距甚远” (例如,一个显示健康的肺,一个显示肿瘤) ,那么在乘以随机矩阵后,它们仍然会保持“相距甚远”。如果它们相似,它们将保持接近。
这使得 Raptor 能够大规模压缩数据——减少 90% 以上的占用空间——同时保持体积的基本“指纹”完整。研究人员发现,仅仅使用 100 的投影维度 (\(K\)) 就足以达到最先进的结果。
实验中的统治地位
研究人员将 Raptor 与医学 AI 领域最重量级的选手进行了基准测试。基线包括像 SuPreM 和 MISFM 这样的模型,这些模型是使用昂贵的 GPU 在数万个医学体积上进行预训练的。
结果令人震惊。Raptor 不仅能够匹敌这些模型;它还始终如一地击败了它们。
分类性能
在 3D Medical MNIST 基准测试 (用于分类医学图像的标准数据集集合) 中,Raptor 在 9 个数据集中的 6 个上实现了最高的准确率。当比较曲线下面积 (AUROC,一种分类稳健性指标) 时,Raptor 通常更胜一筹。
具体来说,与 SuPreM (一个专门在 5000 个 CT 体积上训练的模型) 相比,Raptor 的指标平均提高了 +2% 。 与 SLIViT (另一个预训练模型) 相比,提升幅度跃升至 +13% 。
效率与准确性对比
支持 Raptor 最有力的论据之一是它的效率。下图比较了不同模型的准确率 (AUROC) 与其内存中嵌入大小的关系。
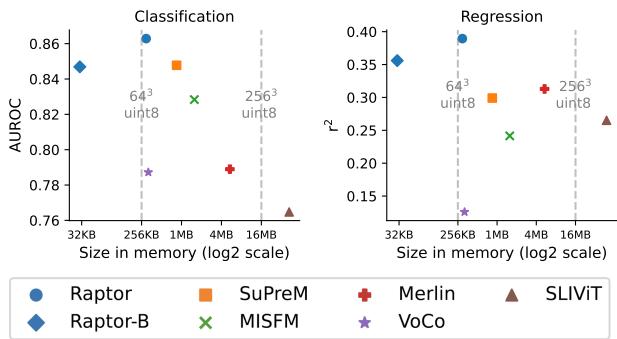
请看蓝色圆圈 (Raptor) 的位置。它们位于左上象限,这是“最佳平衡点”: 高准确率和低内存占用。
- Raptor-B (基础版): 即使使用极小的投影尺寸 (\(K=10\)) ,导致巨大的压缩率,该模型 (标记为 Raptor-B) 仍然可以与像 SuPreM 和 Merlin (橙色和红色标记) 这样经过充分训练的模型竞争或击败它们,而使用的内存仅为后者的一小部分。
少样本学习: 事半功倍
在医学领域,获取标注数据非常昂贵。放射科医生的时间很宝贵,因此对于某种特定的罕见疾病,我们通常只有 10 或 20 个带标签的扫描。
Raptor 在这种“数据稀缺”的环境中表现出色。因为嵌入已经富含了来自基础模型的语义信息,所以在其上训练一个简单的分类器只需要很少的例子就能学会。
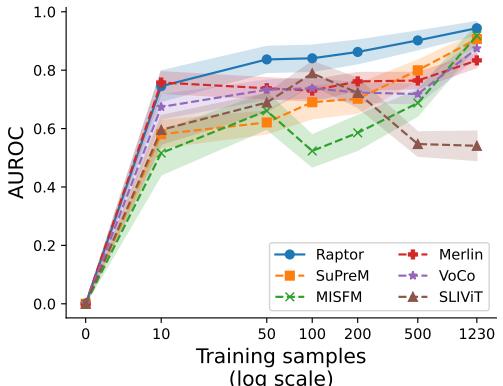
上图显示了在 Synapse 数据集上的表现。仅使用 10 个训练样本 , Raptor (蓝线) 就达到了其最大性能的近 80%。其他模型如 MISFM (绿色) 或 SLIViT (棕色) 在数据有限时表现非常挣扎,在看到数百个示例之前,表现往往并不比随机猜测好多少。
它为什么有效?平滑性的科学
Raptor 的成功依赖于医学体积是“平滑”的这一假设。这意味着如果你看切片 \(N\) 和切片 \(N+1\),它们看起来非常相似。特征不会发生剧烈跳变。
研究人员通过计算一个值 \(\alpha_j\) 来分析这一点,该值估计了特征空间中连续切片之间的对齐程度。
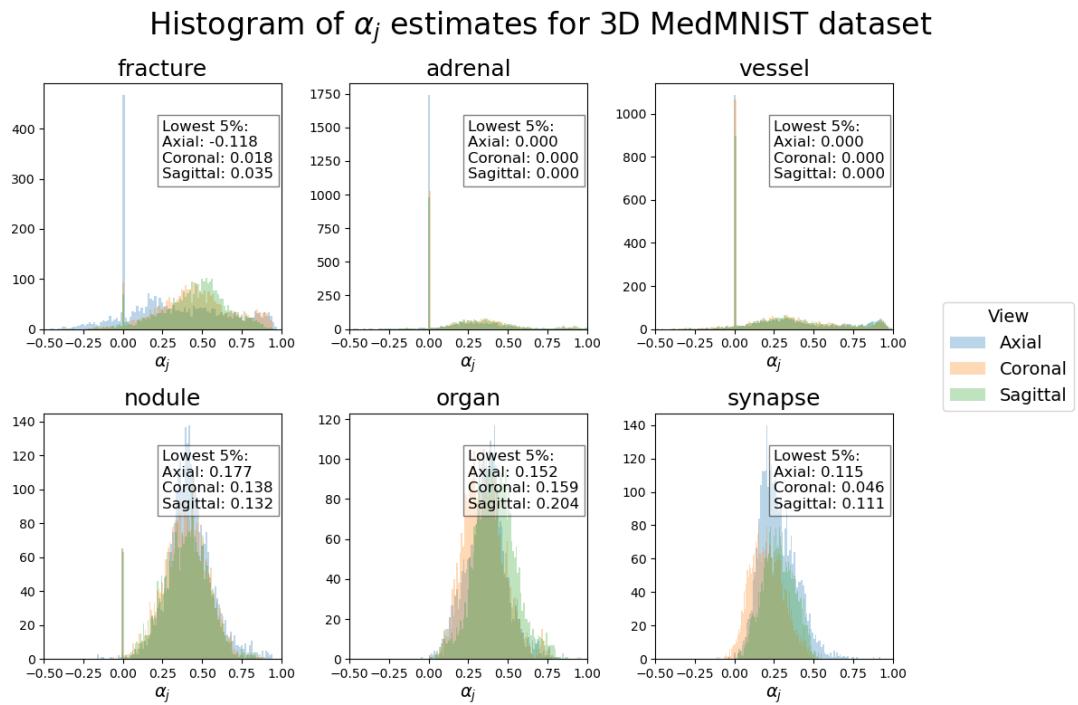
在这个直方图中,正值 (向右) 表示良好的对齐——意味着特征变化平滑。大多数数据集 (如 Organ、Nodule 和 Vessel) 显示出很强的正对齐,这解释了为什么 Raptor 效果这么好。
然而,看 Fracture (骨折) 数据集 (左上角) ,我们看到分布更广,一些值降到了零以下。根据定义,骨折是不连续的——骨结构的断裂。这种缺乏平滑性的特点使得平均切片的效果略微降低,这与实验结果一致,即 Raptor 在 Fracture 数据集上的领先优势小于其他数据集。这种诚实的分析既凸显了该方法的优势,也指出了其理论边界。
结论: 一个“免训练”的未来?
Raptor 代表了向医学 AI 普及化迈出的重要一步。通过消除对昂贵计算预训练的需求,它允许拥有标准消费级硬件 (如单个游戏 GPU) 的研究人员获得最先进的结果。
其影响是广泛的:
- 可访问性: 你不需要数据中心就能构建世界级的医学诊断工具。
- 敏捷性: 随着通用视觉模型的改进 (例如 DINOv3 或更新的架构) ,Raptor 也会即时改进。你只需替换冻结的编码器。
- 数据隐私: 由于生成嵌入不需要在敏感的医学体积本身上进行训练,因此在特征提取阶段关于患者隐私的门槛降低了。
Raptor 证明了,有时候,解决复杂的 3D 问题的最佳方法并不是构建更大、更复杂的 3D 模型。有时候,最好是从几个不同的角度——字面意思上的——来看待问题,然后让数学来完成剩下的工作。