](https://deep-paper.org/en/paper/2507.08285/images/cover.png)
想象一下,你有一张某人向左看的照片,而你希望他向右看。在现代生成式 AI (特别是“基于拖拽”的编辑) 的加持下,这应该很简单: 你点击鼻子 (手柄点/Handle Point) 并将其向右拖动 (目标点/Target Point) 。
从理论上讲,AI 应该理解面部的几何结构。它应该知道,当鼻子移动时,脸颊、耳朵和帽子也应该随之旋转。然而在实践中,当前的方法往往无法掌握这种结构完整性。AI 不会旋转头部,反而可能像拉太妃糖一样拉伸鼻子,将面部扭曲成超现实主义的噩梦。这就是所谓的几何不一致性问题 。
今天,我们将深入探讨一篇研究论文,它针对这一问题提出了一种巧妙的解决方案: FlowDrag 。 该方法认为,要准确地编辑 2D 图像,我们必须暂时步入第三维度。通过生成一个临时的 3D 网格,利用基于物理的规则对其进行变形,然后利用该结构信息引导 AI,FlowDrag 实现了在物理上合理且几何上健全的编辑效果。
2D 拖拽编辑的问题
在剖析解决方案之前,我们需要了解为什么现有的方法会面临困难。
像 DragGAN 或 DragDiffusion 这样的最先进工具通常通过优化“潜在代码” (latent codes,即 AI 大脑中图像的压缩表示) 来工作。它们使用点追踪 (point tracking) 将特定特征 (比如鼻子上的一个像素) 移向目标。
问题在于,这些模型通常将图像视为像素或特征的集合,而不理解底层的对象结构。如果你拖动自由女神像图像上的一个点,模型可能会移动那个特定的点,但把周围的结构留在原地,从而产生一种“溶解”效应。

如上图 Figure 1 所示,请看第一行 (自由女神像) 。在标准的“用户编辑 (User Edit) ”场景中,简单地拖动火炬会导致其他方法 (如 DiffEditor 或 GoodDrag) 扭曲手臂或皇冠。相比之下, FlowDrag (图 d) 保持了雕像的结构完整性。同样,在第二行中,拖动女人的鼻子来旋转她的脸通常会扭曲她的帽子和手。然而,FlowDrag 协调地旋转了整个头部组件。
FlowDrag 解决方案: 用 3D 思维思考
FlowDrag 论文的核心见解是,“刚性编辑 (Rigid Edits) ”——如旋转、重定位或姿态改变——需要保持几何形状,而 2D 特征图无法提供这种几何保持能力。
为了解决这个问题,研究人员提出了一个包含三个主要阶段的流程:
- 3D 网格生成: 将 2D 图像转换为 3D 网格。
- 网格引导变形: 使用物理约束使网格变形 (确保它弯曲但不断裂) 。
- 基于向量流的编辑: 将这种 3D 移动投影回 2D 以引导扩散模型。
让我们一步步来拆解这些步骤。
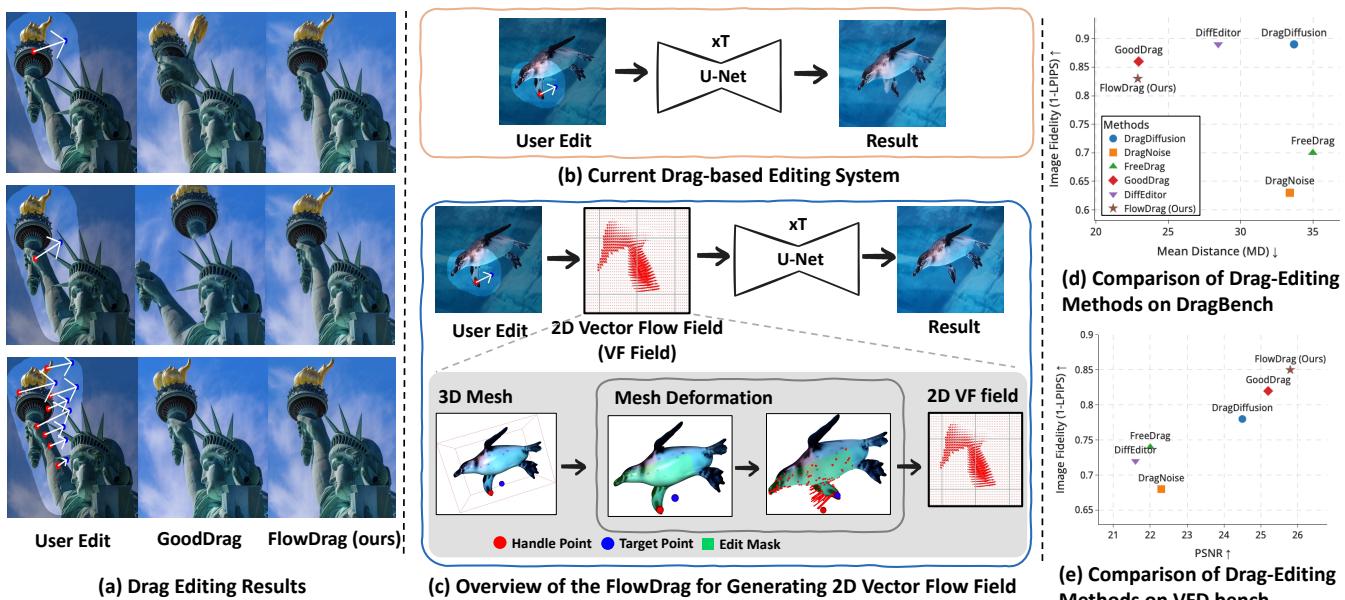
Figure 2 给出了一个高层视角的概览。图 (b) 展示了目前的标准做法: 用户编辑直接进入 U-Net。图 (c) 展示了 FlowDrag 方法: 用户编辑通知 3D 网格 (3D Mesh) , 网格生成 向量流场 (Vector Flow Field) , 然后由流场引导生成过程。
第一步: 生成 3D 网格
如果没有网格,就无法进行变形。作者提出了两种方法将 2D 图像提升到 3D 空间:
- 基于深度的方法 (DepthMesh) : 他们使用深度估计模型 (Marigold) 来猜测每个像素的距离。他们将这些像素映射到 3D 坐标 (\(x, y, z\)) 并连接相邻点以形成三角形。为了避免将前景物体与背景连接起来 (这会产生奇怪的几何“幕布”) ,他们在深度差过大的地方切断连接。
- 基于扩散的方法 (DiffMesh) : 有时深度图是不够的,因为它们看不到物体的“背面”或“侧面”。作者还利用了图像到 3D 的扩散模型 (如 Hunyuan3D) ,这些模型可以“幻构”出隐藏的几何结构,从而创建更完整的网格。
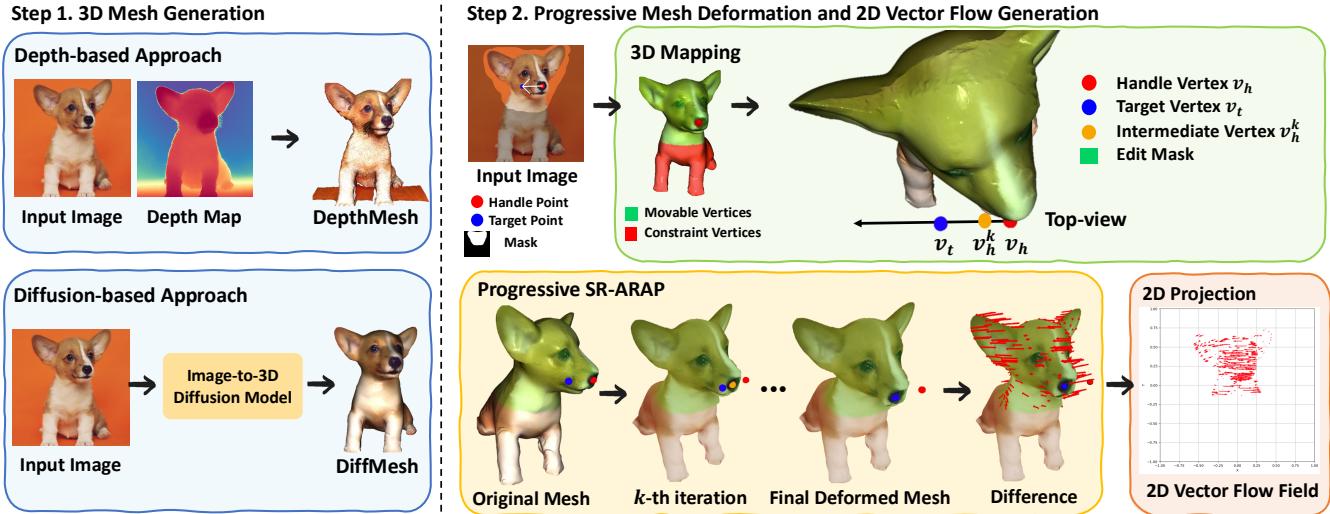
Figure 3 (步骤 1) 展示了这种选择。DepthMesh 速度较快,但在本质上类似浮雕。DiffMesh 提供了更饱满的形状,允许进行更复杂的旋转。
第二步: 渐进式网格变形 (SR-ARAP)
有了网格之后,我们该如何移动它?我们不能直接把“手柄 (handle) ”顶点瞬间传送到“目标 (target) ”顶点,否则网格会出现尖刺和扭曲。我们需要网格的其余部分自然地跟随移动。
作者采用了一种称为尽可能刚性 (As-Rigid-As-Possible, ARAP) 的技术。ARAP 的目标是将手柄点移动到目标位置,同时尽量保持网格中的每个三角形在形状和大小上与之前一致。它最小化了局部几何结构的变形 (拉伸或剪切) 。
从数学上讲,标准的 ARAP 通过最小化基于顶点旋转和位置的能量函数来工作:
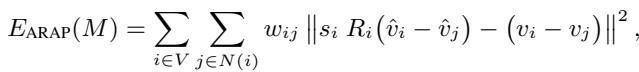
这里,\(R_i\) 是顶点 \(i\) 的旋转矩阵。该方程本质上是在问: “找到新的位置 \(\hat{v}\),使得邻居之间的关系看起来像原始关系,只是经过了旋转。”
然而,标准的 ARAP 有时会导致锯齿状的旋转。为了解决这个问题,作者使用了平滑旋转 ARAP (Smoothed Rotation ARAP, SR-ARAP) , 它增加了一个正则化项,以确保相邻顶点具有相似的旋转:
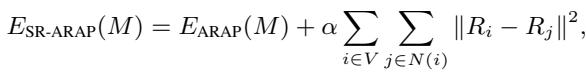
渐进式扭转: 即使使用了 SR-ARAP,一次性将点拖动很远的距离也会破坏网格。作者引入了一种渐进式变形 (Progressive Deformation) 策略。他们不一次性移动手柄点,而是分小步 (迭代) 移动。
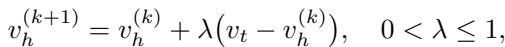
在每一步中,他们在能量函数中添加了一个“步间平滑度 (Inter-Step Smoothness) ”项,惩罚顶点移动偏离其在前一步位置过远的行为。这确保了从开始姿态到结束姿态的平滑、稳定的动画过渡。
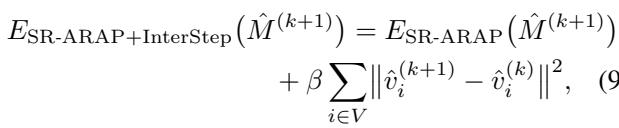
第三步: 生成向量流场
当网格在 3D 空间中成功变形后,系统需要将这种 3D 变化转化为 2D 扩散模型可以理解的指令。
作者将原始网格和变形后的网格投影回 2D 图像平面。通过比较变形前后顶点的位置,他们计算出一个2D 向量流场 (2D Vector Flow Field) (\(\Phi\))。这个场就像一张地图,上面的箭头告诉图像的每一部分应该向哪个方向移动以及移动多远。
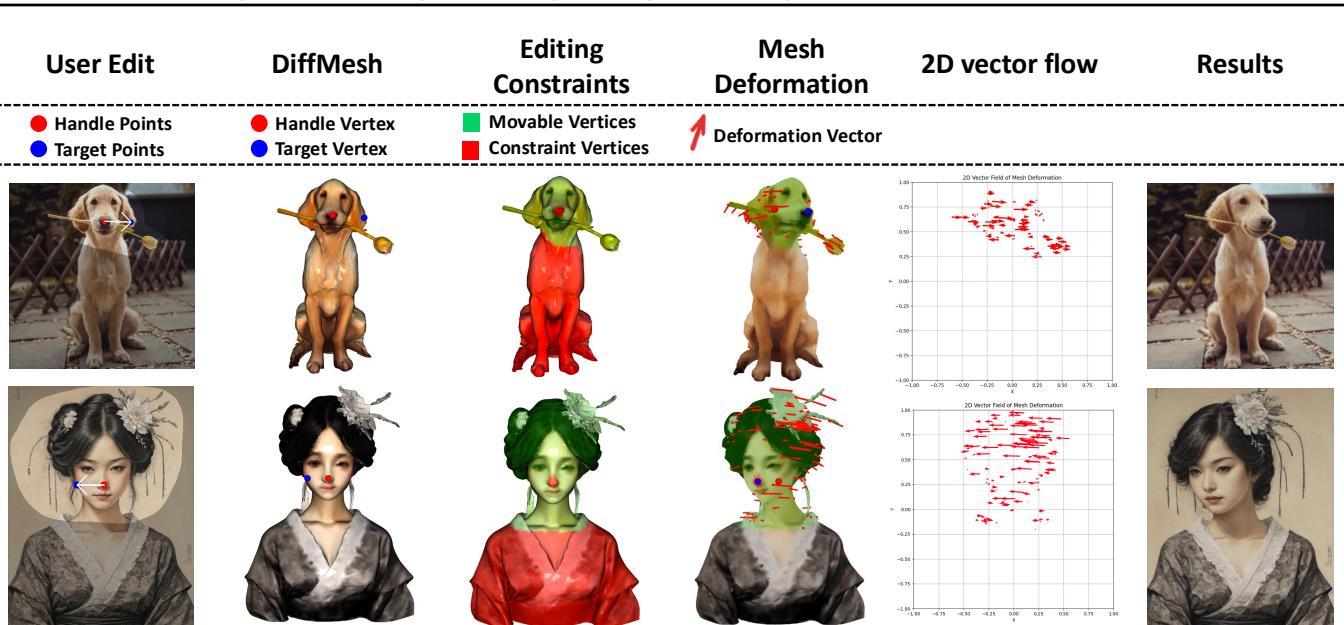
Figure 9 完美地展示了这一过程。从用户编辑 (左上) ,到网格约束 (绿/红点) ,再到变形向量,最后是 2D 向量流场 (右数第二列) 。请注意流场是如何捕捉整个头部的旋转,而不仅仅是拖动点的移动。
将“流”整合进扩散模型
现在来到编辑中的“拖拽”部分。FlowDrag 将这个向量场整合到了标准的扩散过程 (Stable Diffusion) 中。
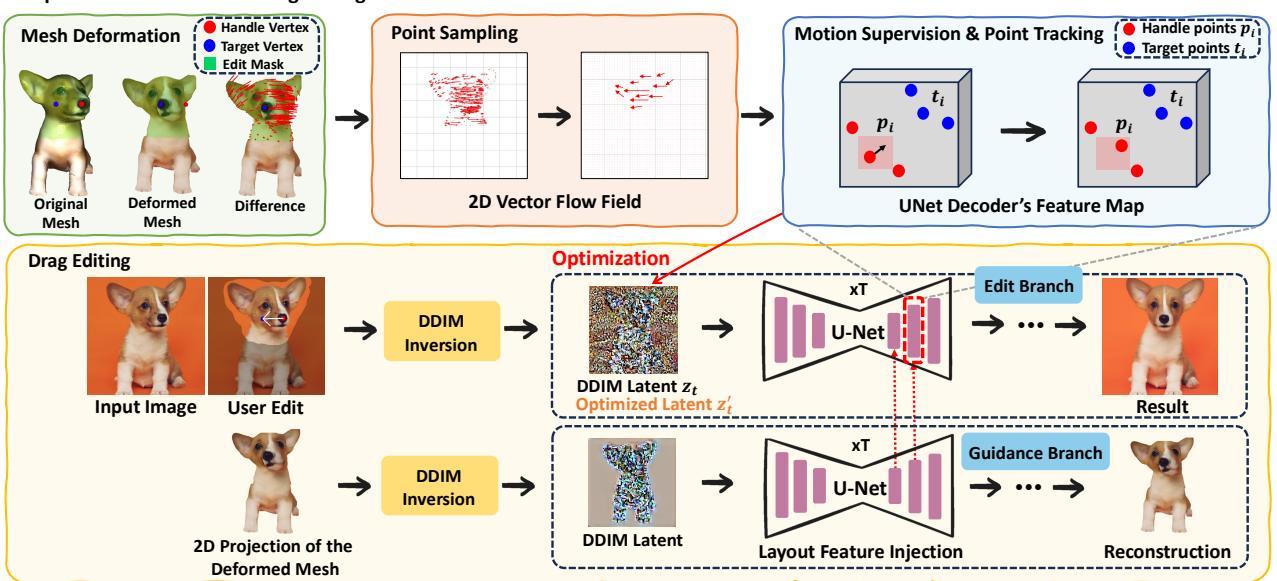
如 Figure 4 所示,架构分为两个分支:
- 引导分支 (Guidance Branch) : 该分支获取变形后网格的投影 2D 图像,并将其布局特征注入到主分支中。这给模型提供了关于新结构的强烈提示 (例如,“头现在是这样倾斜的”) 。
- 编辑分支 (Edit Branch / Motion Supervision) : 这是标准拖拽编辑循环发生的地方。
在标准方法中,模型盲目地搜索手柄点。而在 FlowDrag 中, 运动监督 (Motion Supervision) 损失是由我们之前计算的向量引导的。
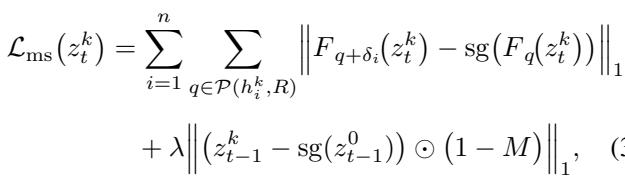
FlowDrag 不再基于简单的点位移来优化潜在代码 \(z_t\),而是对其进行优化,使得特征专门沿着我们网格导出的流向量定义的轨迹移动。
潜在代码 \(z_t\) 通过梯度下降进行更新:
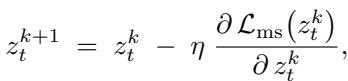
同时,在特征图中追踪手柄点,以确保它们确实落在了应该在的位置:
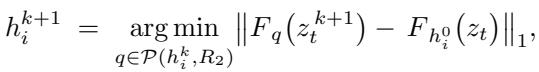
通过结合布局特征注入 (Layout Feature Injection) (给模型“形状”) 和向量流监督 (Vector Flow Supervision) (给模型“运动”) ,FlowDrag 强制扩散模型尊重物体的物理刚性。
VFD-Bench 数据集: 更好的衡量标准
这篇论文的次要贡献之一是对现有基准测试的批判。在像 DragBench 这样的数据集中,没有“真实值 (Ground Truth) ”。你有一张图片和一个“移动鼻子”的请求,但没有关于完美结果应该是什么样子的参考。
像 LPIPS (测量感知相似度) 这样的指标常用于查看图像质量是否下降。然而,如果你成功旋转了一张脸,新图像理应与原始图像看起来不同。低相似度得分实际上可能意味着一次好的编辑!
为了解决这个问题,作者推出了 VFD-Bench (视频帧拖拽基准,Video Frame Drag Benchmark) 。

他们利用视频序列 (Figure 5) 。如果视频显示一只猫从帧 A 转头到帧 B,那么帧 A 是“输入”,帧 B 是“真实值”。拖拽指令被定义为从 A 到 B 所需的移动。

这允许进行准确的测量:
- PSNR/LPIPS: 编辑后的图像看起来像视频的下一帧吗?
- 平均距离 (Mean Distance, MD) : 手柄点是否落在了目标点上?
实验结果
作者将 FlowDrag 与 DiffEditor、DragDiffusion、FreeDrag 和 GoodDrag 等领先方法进行了比较。
定性结果
从视觉上看,差异是显著的。

在 Figure 6 中,看大象那一行 (第 3 行) 。用户想抬起象鼻。
- FreeDrag 和 GoodDrag 难以连贯地移动象鼻,或者引入了伪影。
- FlowDrag 自然地抬起了象鼻,保留了纹理和体积感。
同样,在最后一行 (身着传统服饰的女性) ,FlowDrag 在旋转头部的同时,保持了复杂的发饰刚性且附着在头上,而其他方法则使其扭曲。
定量结果
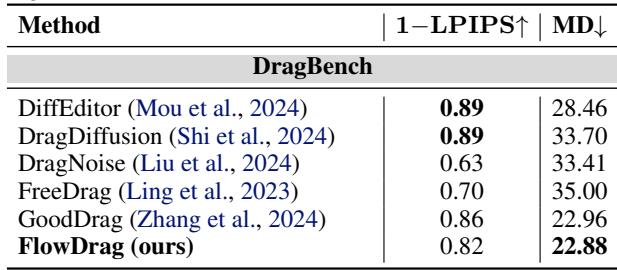
在 DragBench 上 (Table 1) ,FlowDrag 实现了最低的平均距离 (MD) (22.88) ,意味着它在将点移动到目标方面最准确。它还保持了高图像保真度。
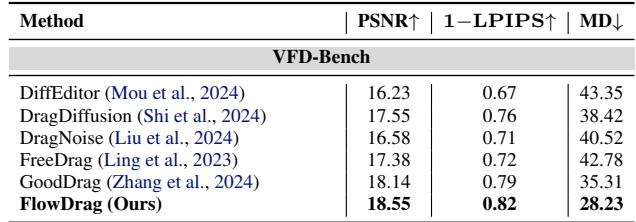
在有真实值可用的 VFD-Bench 上 (Table 2) ,结果更具决定性。FlowDrag 获得了最高的 PSNR (18.55) 和最低的 MD (28.23),证明它生成的图像既几何准确又在视觉上最接近现实。
用户研究与分析
研究人员不仅相信数字,还询问了人类的意见。
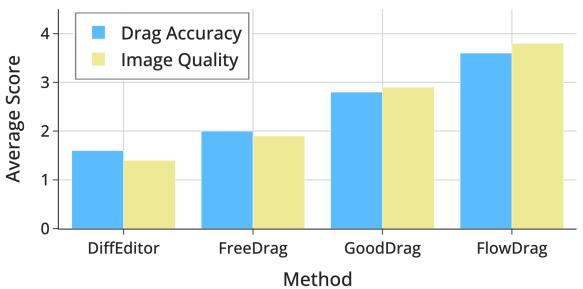
Figure 7 显示,人类评分员在“拖拽准确性”和“图像质量”两方面给 FlowDrag 的评分均持续高于竞争对手。
他们还分析了需要从流场中采样多少个向量。
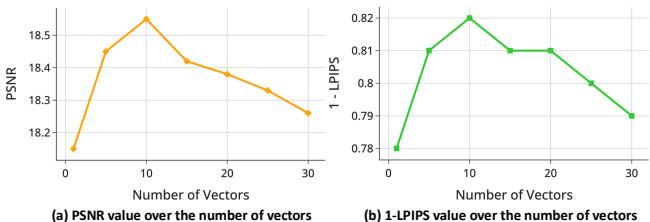
Figure 8 揭示了从流场采样大约 10 个向量是最大化峰值信噪比 (PSNR) 的“最佳点”。使用太少提供的指导不足;使用太多可能会给模型带来相互冲突的信息,造成过度约束。
网格变形的鲁棒性
一个关键问题是: 这是否过于依赖完美的网格?如果深度图很糟糕怎么办?
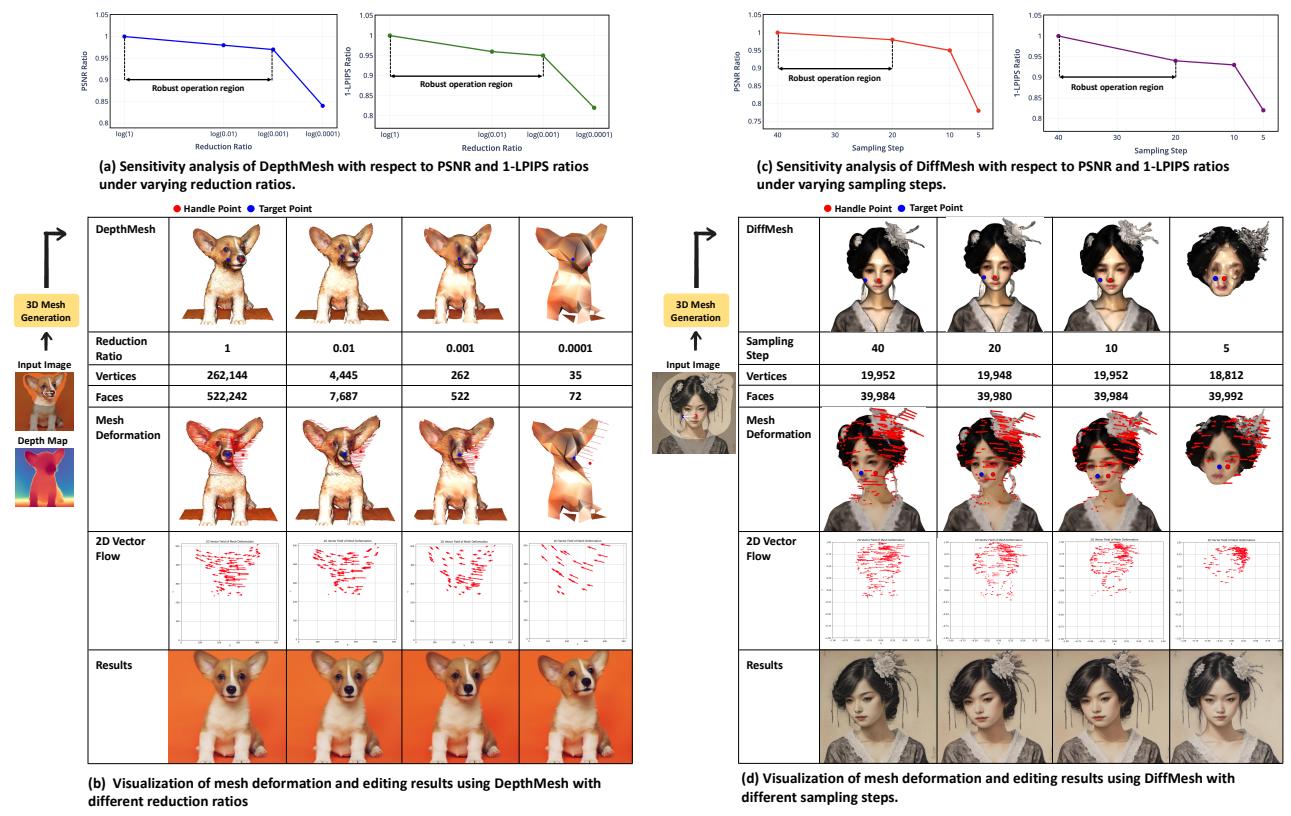
作者进行了敏感性分析( Figure 15 )。
- 图 (a) & (b): 他们显著降低了网格复杂度 (简化比率) 。即使网格简化到 0.001 的比率,系统仍然保持鲁棒。
- 图 (c) & (d): 对于基于扩散的网格 (DiffMesh) ,他们减少了采样步数。即使将生成步数从 40 减少到 10,编辑质量依然保持稳定。
这表明 FlowDrag 不需要“完美”的 3D 网格——它只需要一个“足够好”的网格来捕捉大致的几何流向。
结论
FlowDrag 通过弥合 2D 生成模型与 3D 几何之间的鸿沟,代表了 AI 图像编辑向前迈出的重要一步。通过 3D 网格 (即使是临时的、估算的网格) 显式地模拟编辑的“物理过程”,该方法避免了困扰纯 2D 方法的怪异扭曲。
关键要点:
- 几何很重要: 纯 2D 潜在优化不足以进行刚性物体操作。
- 网格引导: 在代理网格上使用 SR-ARAP 变形提供了强大的“向量流场”来引导生成。
- 更好的基准测试: 评估拖拽编辑需要真实值,而视频帧 (VFD-Bench) 可以提供这一点。
虽然 FlowDrag 目前针对刚性编辑 (旋转、姿态改变) 进行了优化,并依赖于网格生成的质量,但它为未来的工作打开了大门,即扩散模型可能天生理解 3D 结构,从而带来更直观、更逼真的创意工具。