](https://deep-paper.org/en/paper/2507.09177/images/cover.png)
想象一下,你正在教机器人煮咖啡。经过几周的训练,它终于掌握了磨豆和注水的艺术。接下来,你教它如何把碗盘装进洗碗机。它学得很快,但当你让它再次煮咖啡时,它却茫然地盯着咖啡机。它的“煮咖啡”神经元已经被“装洗碗机”的神经元完全覆盖了。
这种现象被称为灾难性遗忘 (Catastrophic Forgetting) , 它是人工智能的阿喀琉斯之踵。
在标准的深度强化学习 (Deep Reinforcement Learning, RL) 中,智能体非常擅长掌握单一任务。但在持续强化学习 (Continual Reinforcement Learning, CRL) ——即智能体必须按顺序一个接一个地学习多个任务——的场景中,标准方法往往会失败。它们面临着稳定性-可塑性困境 (stability-plasticity dilemmas) : 如果大脑的可塑性太强,它会覆盖旧的记忆 (遗忘) ;如果稳定性太强,它就无法学习新事物。
在这篇文章中,我们将深入探讨 Liu 等人发表的一篇引人入胜的论文,题为 “Continual Reinforcement Learning by Planning with Online World Models” (基于在线世界模型规划的持续强化学习) 。研究人员提出了一种视角的转变: 智能体不应专注于记忆如何行动 (策略) ,而应专注于学习世界如何运作 (世界模型) ,并使用一种在数学上保证不会遗忘的方法。
问题所在: 任务 ID 与相互冲突的现实
要理解为什么 CRL 如此困难,我们首先需要看看传统上研究人员是如何试图解决它的。在这个领域,一种常见的“作弊”手段是使用任务 ID (Task IDs) 。 当机器人从煮咖啡切换到洗碗时,环境会告诉机器人: “切换到任务 2”。然后,机器人会加载一组不同的神经权重,或者使用其大脑中分配给任务 2 的特定部分。
但在现实世界中,生活并不会给我们任务 ID。一个在厨房里移动的机器人看到的只是连续不断的感官数据流。
此外,许多以前的方法将不同的任务视为具有完全独立的物理动力学。作者使用统一动力学 (Unified Dynamics) 的概念强调了这个问题。
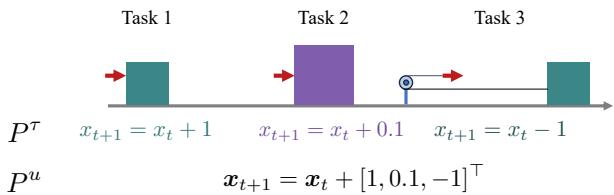
如图 1 所示,如果我们分别处理任务 (\(P^\tau\)) ,那么在相同状态下的相同动作可能会根据“任务 ID”产生不同的结果。这迫使智能体学习相互冲突的规则。然而,在现实中,物理学是一致的 (\(P^u\)) 。重力不会仅仅因为你决定切换任务而改变。
作者提出了一种在线智能体 (Online Agent, OA) 。 该智能体假设存在一个统一的世界模型。它增量地学习这个模型,并利用它来规划行动。
解决方案: 在线智能体 (OA)
在线智能体建立在三大支柱之上:
- 在线世界模型学习: 实时学习环境的物理规律。
- 无悔更新 (No-Regret Updates) : 一种数学方法,确保模型随时间推移进行最优学习。
- 规划: 使用学到的模型模拟未来并选择最佳行动。
1. 架构: 浅而宽
深度神经网络 (DNN) 是 RL 的标准配置,但它们在在线学习方面表现糟糕。如果你在单个新数据点上更新 DNN,它通常会大幅改变其权重,破坏之前的知识。为了解决这个问题,你通常需要一个“经验回放缓冲区”来不断提醒网络旧的数据。这既缓慢又占用大量内存。
作者转而使用领袖跟随 (Follow-The-Leader, FTL) 浅层模型 。 他们不使用深度网络,而是使用非线性特征提取器,后接单个线性层。
- 输入: 状态 (\(s\)) 和动作 (\(a\)) 。
- 特征提取器 (\(\phi\)) : 他们使用“局部敏感稀疏编码”。想象一个巨大的高维网格。任何特定的状态-动作对只会激活这个网格中的少数几个特定“神经元”。这就像一个静态的随机投影,使数据可分离。
- 线性层 (\(W\)) : 这将特征映射到下一个状态 (\(s'\)) 。
由于最后一层是线性的,“最佳”权重可以通过闭式方程在数学上计算出来,而不是通过梯度下降进行不完美的估计。
2. 学习算法: 稀疏递归更新
奇迹发生在智能体更新其对世界理解的方式上。由于智能体在稀疏特征之上使用线性模型,它可以使用递归最小二乘法 (Recursive Least Squares) 。
这使得智能体可以在环境中的每一步之后立即更新其模型,而无需在旧数据上重新训练以防止遗忘。数学原理确保了新的更新尊重所有的历史记录。
权重 (\(W\)) 的更新规则如下所示:
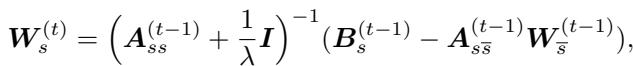
在这里,\(\boldsymbol{A}\) 代表至今为止所见的所有数据的累积协方差 (历史) ,\(\boldsymbol{B}\) 代表目标。通过维护这些矩阵,智能体拥有了对过去统计数据的“完美记忆”,这些记忆被压缩成矩阵,而不是存储数百万个原始回放帧。
3. 通过规划行动
一旦智能体拥有了运作良好的世界模型 (\(P(s'|s,a)\)) ,它就不需要学习策略网络 (这通常需要很长时间) 。相反,它进行规划 。
智能体观察当前状态,使用其世界模型构想成千上万个不同的动作序列,并评估哪个序列能产生最高的奖励。这是使用交叉熵方法 (CEM) 完成的,这是一种用于优化的强大进化算法。
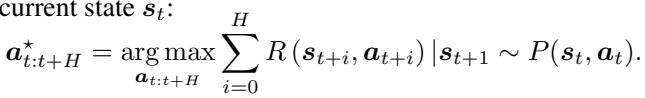
通过将动力学 (在所有任务中共享) 与奖励 (每个任务都会变化) 分离开来,智能体变得极具适应性。当任务切换时,智能体只需切换它正在规划的奖励函数,同时保留它积累的所有物理知识。
理论保证: 无悔学习
这篇论文最有力的贡献之一是理论证明。在深度 RL 中,我们通常只能祈祷网络能够收敛。在这里,作者证明了一个遗憾界 (Regret Bound) 。
遗憾是指智能体在学习过程中实际产生的误差与最佳可能的离线模型 (一次性看到所有数据) 所产生的误差之间的差异。
作者证明,他们的稀疏在线更新规则实现了如下的遗憾:
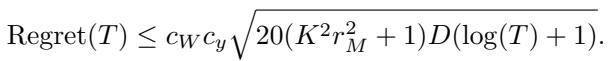
简而言之,这个方程意味着智能体的性能差距 (与完美预言机相比) 随时间迅速缩小 (\(O(\sqrt{\log T})\)) 。它保证了智能体能有效地收敛到真实的世界物理规律,而不会发生灾难性遗忘。
Continual Bench: 更好的测试场
为了测试他们的智能体,作者意识到现有的基准测试存在缺陷。许多基准测试,如“Continual-World”,实际上在任务之间“瞬移”物体或改变物理约束,使得统一的物理模型变得不可能。
如图 2 所示,如果环境对门把手 (圆周运动) 和抽屉把手 (线性运动) 使用相同的输入坐标,单一的世界模型就会感到困惑。这就构成了“物理冲突”。
为了解决这个问题,作者推出了 Continual Bench 。

在 Continual Bench (图 3) 中,任务是空间排列的。机器人位于中心,任务 (窗户、门、水龙头等) 放置在它周围。这创造了一个一致的物理世界,其中确实存在“统一动力学”。机器人可以学习窗户的物理规律,转过身去学习水龙头,并且仍然记得窗户是如何工作的,因为窗户还在那里,受同样的物理定律支配。
实验结果
研究人员将他们的在线智能体 (OA) 与几个强基线进行了比较:
- 微调 (Fine-tuning) : 一个标准的深度模型,只是不断训练 (预期会遗忘) 。
- EWC, SI, PackNet: 旨在保护权重不发生太大变化的流行持续学习方法。
- Coreset: 一种保留旧数据小缓冲区进行回放的方法。
- 完美记忆 (Perfect Memory) : 一个理想化的基线,存储所有东西并不断重新训练 (计算上的作弊) 。
1. 随时间变化的性能
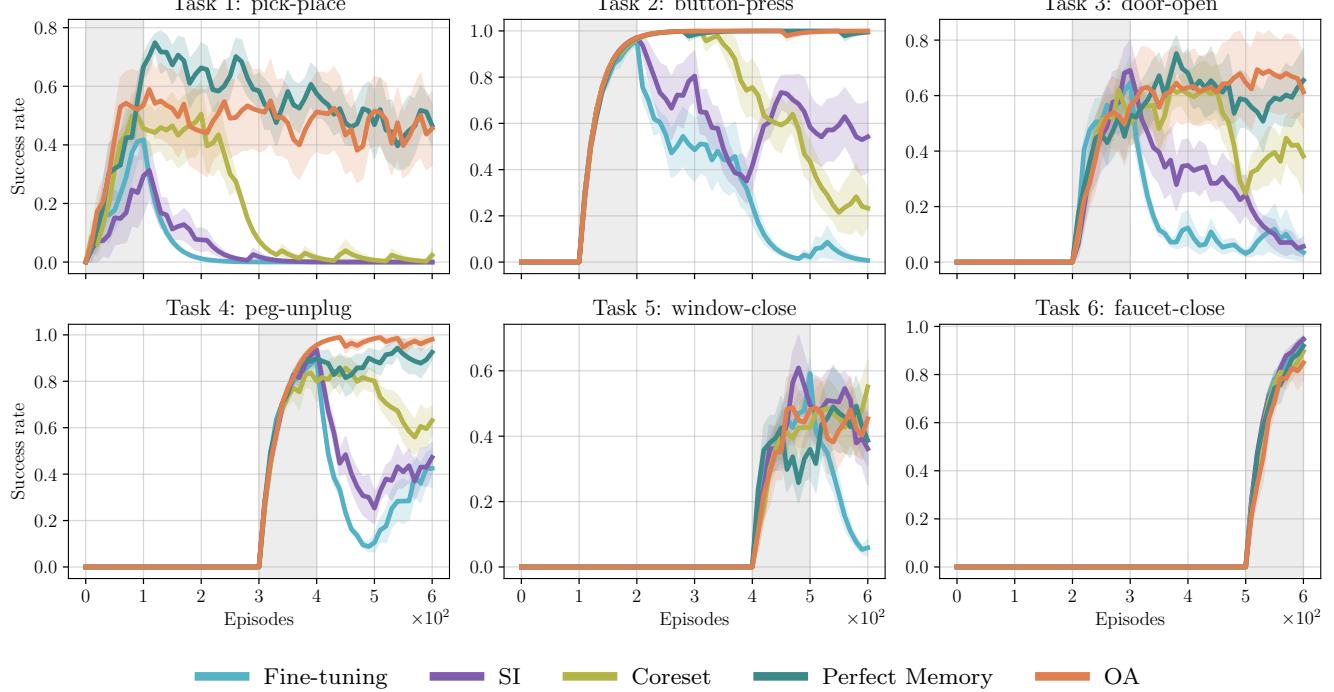
图 5 说明了主要情况。看看橙色线( OA )。
- 当新任务开始时 (灰色阴影区域) ,OA 学习得很快。
- 至关重要的是,在任务结束且机器人移动到下一个任务后,橙色线保持高位 。
- 将其与微调 (青色) 或 SI (紫色) 进行比较,后者在切换后通常会立即在旧任务上跌至零成功率。
2. 平均性能与遗憾
为了总结性能,我们可以查看至今为止所有任务的平均性能 (AP) 。
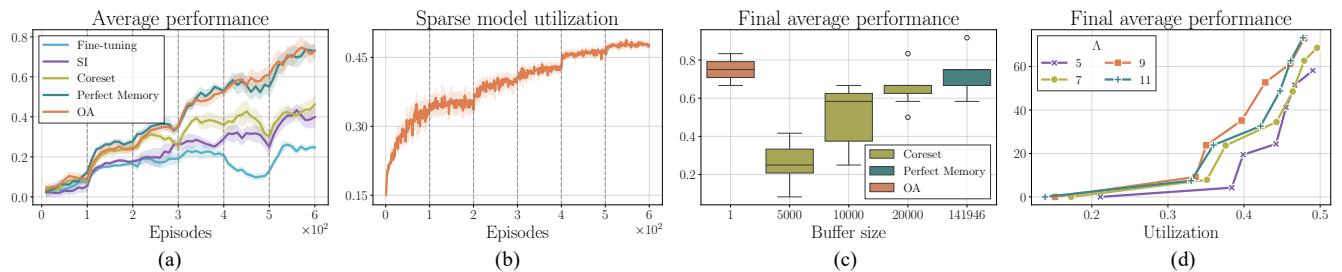
在图 6(a) 中,在线智能体 (橙色) 稳步攀升,与“完美记忆”基线 (深青色) 相匹配。这证实了轻量级的递归更新与存储整个数据集一样有效,但效率却高出无数倍。
我们还可以量化遗憾 (Regret) ——即智能体的性能与完美性能 (预言机) 之间的面积。
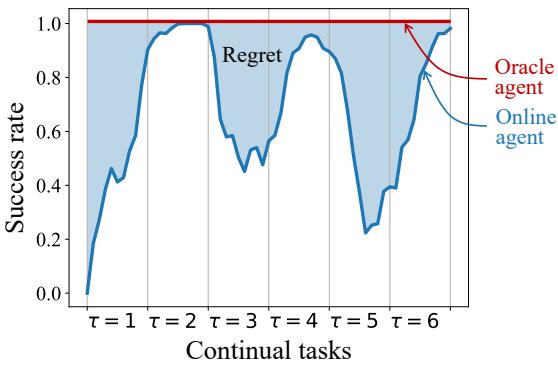
使用图 4 中定义的度量标准,OA 实现的遗憾值显著低于无模型基线,并与最佳的基于模型的基线相匹配,证明它学得更快且保留得更多。
3. 它真的记住了物理规律吗?
最后,作者检查了世界模型的内部误差。神经网络是真的记住了物理规律,还是只是运气好?
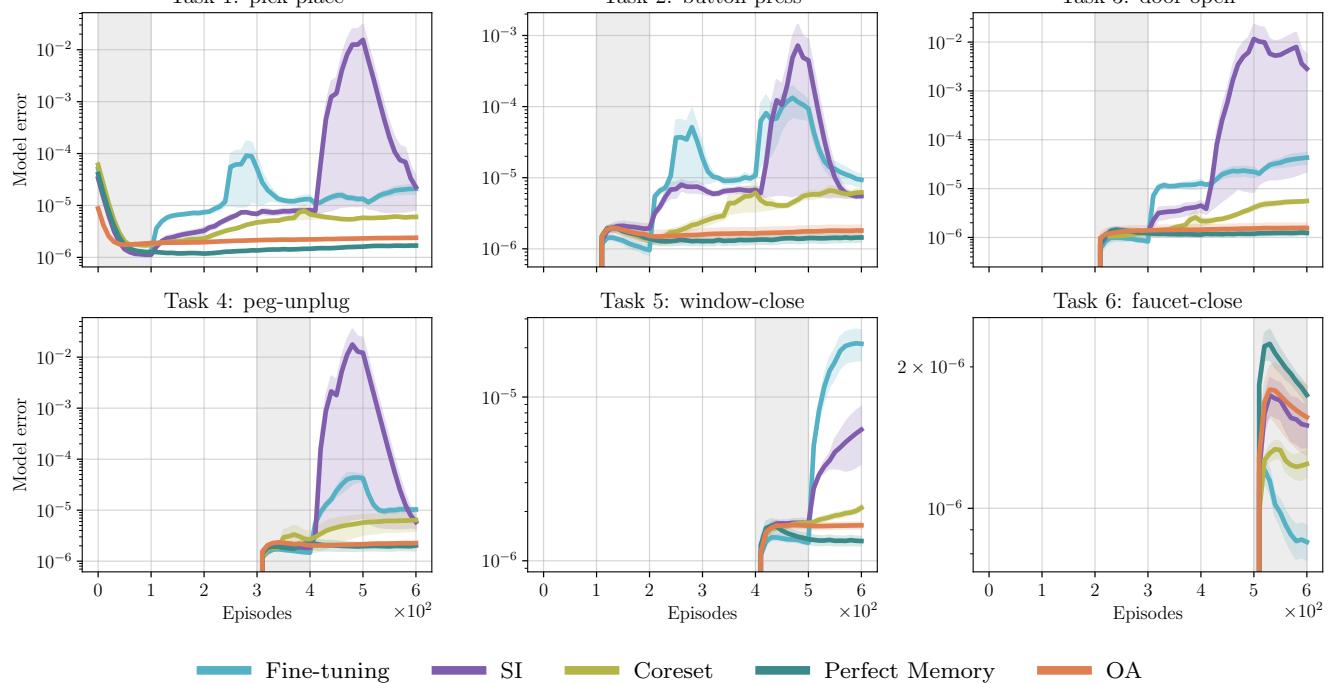
图 8 对标准深度学习方法来说可能是最致命的打击。看看任务 1 (抓取-放置) 。
- OA (橙色) 永远保持平坦、低误差的线条。
- SI (紫色) 和微调 (青色) 在开始学习任务 2、3 或 4 时,任务 1 的误差立即出现巨大的峰值。它们确实正在遗忘第一个物体的物理规律。
结论
“在线智能体”这篇论文为机器人学习的未来提出了一个令人信服的论点。通过从记忆策略的“黑盒”神经网络转向具有数学基础更新规则的基于模型的智能体 , 我们可以创建真正能够学习的系统。
主要的收获是:
- 共享动力学: 现实世界的持续学习依赖于物理规律不会改变这一事实。
- 在线更新: 递归的闭式更新 (如 FTL) 自然地防止了灾难性遗忘,无需复杂的辅助损失函数。
- 规划具有鲁棒性: 如果你知道世界是如何运作的,你只需改变你的目标,就可以零样本 (zero-shot) 地解决新任务。
这种方法让我们离通用机器人又近了一步,这种机器人可以学会装洗碗机,而不会忘记如何煮我们的早间咖啡。