](https://deep-paper.org/en/paper/2508.11393/images/cover.png)
人工智能面临着信任危机。随着深度学习模型,尤其是 Transformer,在从电影情感分析到复杂的科学分类等领域占据主导地位,它们变得越来越精准——同时也越来越不透明。我们通常知道模型预测了什么,但很少知道为什么。
如果一个模型将某笔金融交易标记为欺诈,或者将某张医学扫描图诊断为阳性,仅凭一句“这是电脑算的”已经不再是可以接受的理由。我们需要理据 (rationales) ——即输入文本中解释该决策的重点部分。
在这篇文章中,我们将深入探讨 Brinner 和 Zarrieß 的一篇论文,该论文针对这一问题提出了一个新颖且优雅的解决方案: 合理化 Transformer 预测器 (Rationalized Transformer Predictor, RTP) 。 他们引入了一种方法,允许单个模型在一次操作中同时对文本进行分类并高亮显示分类依据,这得益于一种被称为端到端可微自训练 (end-to-end differentiable self-training) 的巧妙数学技巧。
如果你是一名机器学习专业的学生,并希望了解可解释人工智能 (XAI) 的最前沿技术,请倒杯咖啡。我们将详细拆解如何将一个黑盒变成透明的玻璃屋。
可解释性的现状
要理解为什么 RTP 是一个突破,我们首先需要了解研究人员传统上是如何尝试从神经网络中提取解释的。通常,这分为两大阵营: 事后解释 (Post-Hoc Explanations) 和合理化博弈 (Rationalization Games) 。
1. 事后解释
这是“事后诸葛亮”式的方法。你取一个训练好的标准分类器,输入数据,然后使用单独的算法 (如 LIME 或 Integrated Gradients) 来探测和刺激模型,看哪些词触发了输出。虽然有用,但这些方法可能很慢且计算成本高昂。更重要的是,它们是近似值;它们只是外部观察者对模型想法的猜测,并不一定是内部推理过程的忠实反映。
2. 合理化分类 (博弈方法)
这是“内置”式的方法。这里的目标是构建模型架构,使其必须提供理据才能做出预测。传统上,这被框架化为多个模型之间的合作博弈 :
- 选择器 (生成器) : 阅读文本并选择词的一个子集 (理据) 。
- 预测器: 仅接受那些被选中的词,并尝试猜测标签。
如果预测器猜对了,选择器就会得到奖励。逻辑很顺畅: 如果预测器仅凭选中的词就能对文本进行分类,那么这些词一定是重要的。
博弈法的问题
虽然博弈法听起来很完美,但它饱受训练噩梦的困扰。
- 随机采样: 为了选择一组离散的词 (保留 vs. 删除) ,模型必须做出二元选择。这种采样过程打断了梯度链 (你无法对抛硬币进行微分) ,迫使研究人员使用像 REINFORCE 这样的强化学习技术,而这些技术以不稳定著称。
- 主导的选择器: 有时选择器变得太聪明了。它可能会以一种平凡的方式编码答案 (例如,选择第一个 token 暗示“正面”,选择第二个暗示“负面”) ,这样预测器实际上并没有学习任务——它只是学会了读取选择器的作弊码。
- 连锁动态: 由于两个不同的模型同时训练,它们可能会陷入相互锁定的循环中,导致双方都无法提升。
这篇论文的作者审视了这些复杂的多人博弈,并问道: 为什么我们需要两个或三个不同的模型?难道一个模型不能完成所有工作吗?
核心方法: 合理化 Transformer 预测器 (RTP)
研究人员提出了范式转变。不再是选择器和预测器之间复杂的博弈,他们使用单个 Transformer 模型同时执行这两项任务。
1. 统一架构
RTP 是一个标准的 Transformer (如 BERT) ,它接受输入序列 \(\mathbf{x}\)。在单次前向传播中,它输出两样东西:
- 分类结果 (\(\tilde{\mathbf{y}}\)): 类别的概率标签。
- 理据掩码 (\(\mathbf{m}\)): 每个 token 对应一个 0 到 1 之间的分数,表示它对该特定类别的重要性。
其形式化方程如下:
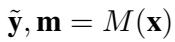
这种简单性具有欺骗性。通过连同预测一起输出掩码,模型将其自身的注意力机制暴露给了优化过程。但我们如何确保掩码实际上是有意义的呢?我们需要正确地对其进行参数化。
2. 掩码参数化
原始神经网络的输出可能充满噪声。如果我们只是让模型挑选个别的词,它可能会挑选像 “the”、“and” 或标点符号这样恰好带有统计噪声的分散 token。人类的理据通常是文本的片段 (spans) ——短语或句子。
为了强制实现这一点,作者使用了一种特定的参数化方法。模型不是直接预测掩码值,而是为每个 token 预测一个影响权重 (\(w\)) 和一个宽度 (\(\sigma\))。这些值决定了一个 token 对其邻居掩码的贡献程度。
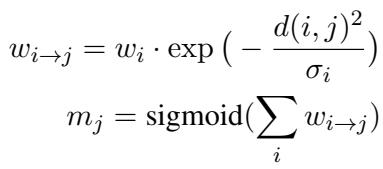
在上面的方程中:
- \(d(i, j)\) 是 token \(i\) 和 token \(j\) 之间的距离。
- 指数函数的作用类似于高斯模糊。一个词的高分会“渗透”到它的邻居,自然地形成连贯的文本片段,而不是参差不齐的孤立点。
- 最终的掩码 \(m_j\) 是这些影响之和的 sigmoid 函数,确保值保持在 0 到 1 之间。
3. 端到端可微自训练
这是论文最天才的部分。如何在没有上述不稳定的采样过程的情况下训练掩码?
作者利用模型生成的掩码创建了两个变体版本的输入 :
- 合理化输入 (\(\mathbf{x}^c\)): 原始文本与掩码混合。这保留了“重要”信息。
- 互补输入 (\(\overline{\mathbf{x}}^c\)): 原始文本与掩码的反转混合。这仅保留了“不重要”信息。
至关重要的是,他们不使用删除词语 (这是离散且不可微的) ,而是使用线性混合 。 他们根据掩码值将词嵌入与通用的“背景”嵌入进行混合。

因为这种混合是数学上的 (乘法和加法) ,梯度可以直接流过它。模型可以确切地学习如何调整掩码以最小化损失。
4. 损失函数: 充分性和全面性
那么,模型如何学习什么是“好”的理据呢?作者基于两个直观的概念定义了训练目标:
- 充分性 (Sufficiency) : 如果理据是好的,模型应该能够正确分类合理化输入 (\(\mathbf{x}^c\))。
- 全面性 (Comprehensiveness) : 如果理据有效地捕捉了所有证据,模型应该无法分类互补输入 (\(\overline{\mathbf{x}}^c\))。
这一逻辑被编纂在以下损失函数中:
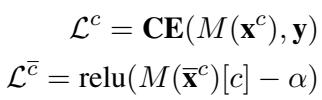
- \(\mathcal{L}^c\) 是合理化输入上的标准交叉熵 (CE) 损失。我们要最小化它 (使预测变好) 。
- \(\mathcal{L}^{\bar{c}}\) 关注互补输入。我们希望正确类别 \(c\) 的概率降至阈值 \(\alpha\) 以下。我们希望当理据被移除时,模型变得“一无所知”。
5. 整合所有部分
最终的训练目标结合了全文的标准分类损失、理据的自训练损失以及正则化项 (以鼓励稀疏性和平滑性) 。
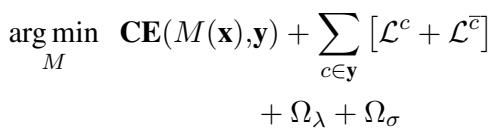
- \(\Omega_{\lambda}\) 鼓励掩码稀疏 (不要高亮整篇文本) 。
- \(\Omega_{\sigma}\) 鼓励掩码平滑 (选择连续的片段) 。
通过优化这单一的方程,RTP 学会了在对文本进行分类的同时,准确识别出文本的哪些部分驱动了该分类。
下面是一个输出示例。红色高亮代表模型生成的掩码 (理据) 。注意它是如何选择像 “confusing” (令人困惑) 、“fake” (虚假) 和 “annoying” (恼人) 这样连贯的短语来证明负面情感的。

实验与结果
研究人员将 RTP 与一系列基线模型进行了对比测试,包括标准的 3 玩家博弈方法和各种事后解释器 (如 LIME 和 Integrated Gradients) 。
他们使用了两个截然不同的数据集:
- 电影评论: 标准的正面/负面情感分析。
- INAS: 一个具有挑战性的科学数据集,模型必须根据特定的生物学假设对摘要进行分类。
成功指标
如何给解释打分?
- 一致性 (IoU-F1): 模型高亮的词与人工标注员高亮的一样吗?
- 忠实度 (Faithfulness): 理据是否真的解释了模型的行为?
为了定量测量忠实度,他们使用了充分性和全面性指标:
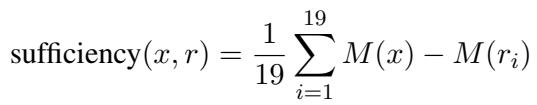
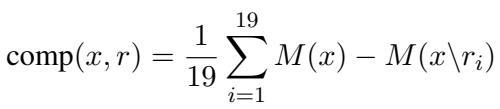
科学数据 (INAS) 上的结果
INAS 数据集很棘手,因为科学语言非常密集。下表展示了结果。
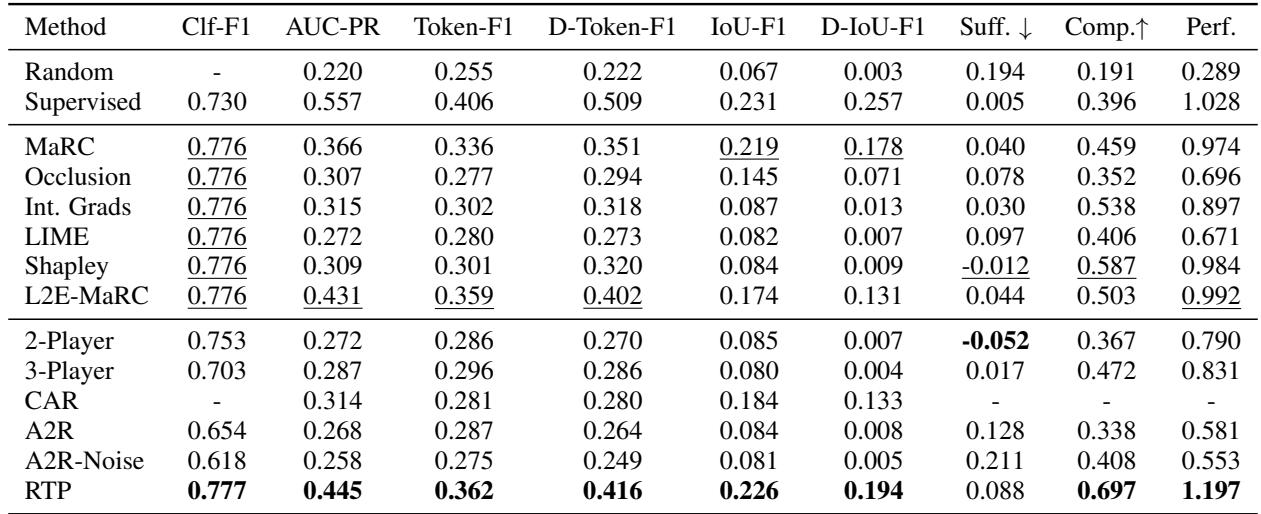
INAS 的关键结论:
- RTP (最后一行) 在几乎每个类别中都取得了最高分 (粗体数字) 。
- 看 IoU-F1 (0.226)。这衡量了与人工标注的重叠度。RTP 显著优于 3 玩家博弈 (0.080) 和像 LIME (0.082) 这样的事后方法。
- Perf. 列 (整体性能) 显示 RTP 以 1.197 的得分占据主导地位。
电影评论上的结果
对于更简单的电影评论任务,结果同样令人印象深刻。
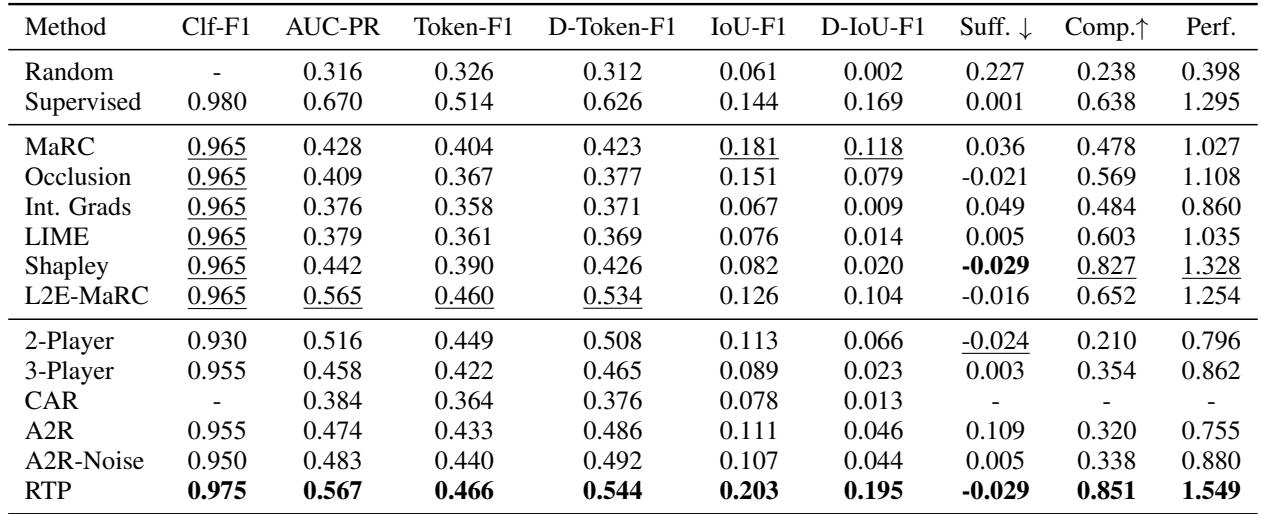
电影评论的关键结论:
- 同样, RTP 横扫榜单。
- 全面性 (Comp.) 得分特别高 (0.851)。这意味着当 RTP 移除了它认为重要的词时,模型预测电影情感的能力会崩溃。这证明模型没有撒谎;它确实依赖于这些词。
视觉对比
为了可视化其与人类推理的一致性,我们可以对比“真值”标注 (绿色文本) 与模型的预测。RTP 捕捉到了长而有意义的片段,这与人类所认为的“证据”非常吻合。

为什么这很重要
合理化 Transformer 预测器代表了可解释人工智能的成熟。我们正在远离“权宜之计”式的解决方案——比如训练多个不稳定的模型,或者在决策做出后试图逆向工程一个黑盒。
相反,但这篇论文表明,可解释性可以是内在的 。 通过使理据生成可微并成为主训练循环的一部分,我们获得了两全其美的结果:
- 稳定性: 不再有强化学习的不稳定性。
- 性能: 模型学会了关注信号并忽略噪声,通常能保持甚至提高分类准确率。
- 忠实度: 理据在数学上与预测机制紧密相连。
对于进入该领域的学生和研究人员来说,RTP 凸显了归纳偏置的力量。通过告诉模型“我希望你学习片段” (通过掩码参数化) 和“我希望你解释你自己” (通过互补损失) ,我们可以引导庞大的 Transformer 不仅变得更聪明,而且更诚实。
随着我们将人工智能部署到法律和医学等高风险环境中,这种诚实不仅仅是一个特性——它是一个必要条件。