](https://deep-paper.org/en/paper/2510.27246/images/cover.png)
超越百万词元: 为长上下文大语言模型构建真实测试与真实记忆
你是否曾与智能助手聊了很久,但几轮对话后它却忘记了你明确告诉过它的细节?随着模型的上下文窗口越来越大——10 万、100 万,甚至 1000 万词元——这种失忆问题变得愈发明显: 更大的上下文窗口并不意味着更好的长期对话记忆。
最近有一篇论文直面了这个问题。作者提出了两个互补的贡献:
- BEAM : 一个新的基准测试,可以生成最长达 1000 万词元的连贯单用户对话,并提供丰富的探究性问题,用于测试十种不同的记忆能力 (不仅限于回忆) 。
- LIGHT : 一个受人类认知启发的记忆框架,为大语言模型配备三种互补的记忆系统——情景记忆 (检索) 、工作记忆 (最近的轮次) 和草稿纸 (迭代总结的关键事实) 。
本文将解释作者们构建的内容、为何现有评估不够、BEAM 数据集的构建方式、LIGHT 的工作机理,以及实验揭示的大语言模型记忆能力现状。
简而言之,为什么这件事重要: 如果我们希望助手能在长期项目或多次交互中真正成为人类的合作伙伴,就需要现实的评估方式和有针对性的架构,让记忆真正发挥作用——而不仅仅是扩大上下文窗口。
以往基准测试存在的问题
现有的长上下文基准测试通常陷入三个陷阱:
- 缺乏连贯性 。 许多数据集通过拼接短小无关的聊天来模拟“长”对话。这导致人为的主题跳跃,让模型可以通过隔离片段来“作弊”,而非在一个随时间发展的叙事中进行推理。
- 领域狭窄 。 许多基准测试主要聚焦于个人生活场景,忽视了技术或专业领域的对话 (如编程、金融、健康等) 。
- 任务浅显 。 测试大多集中于简单的事实回忆,很少探测更复杂的能力,如矛盾解决、长时间间隔后的指令遵循、事件排序或跨分散对话片段的多跳推理。
作者的解决方案分为两部分: 生成连贯、多领域的超长对话并附带针对性探究问题 (BEAM) ,以及改进模型访问与整合记忆的方式 (LIGHT) 。
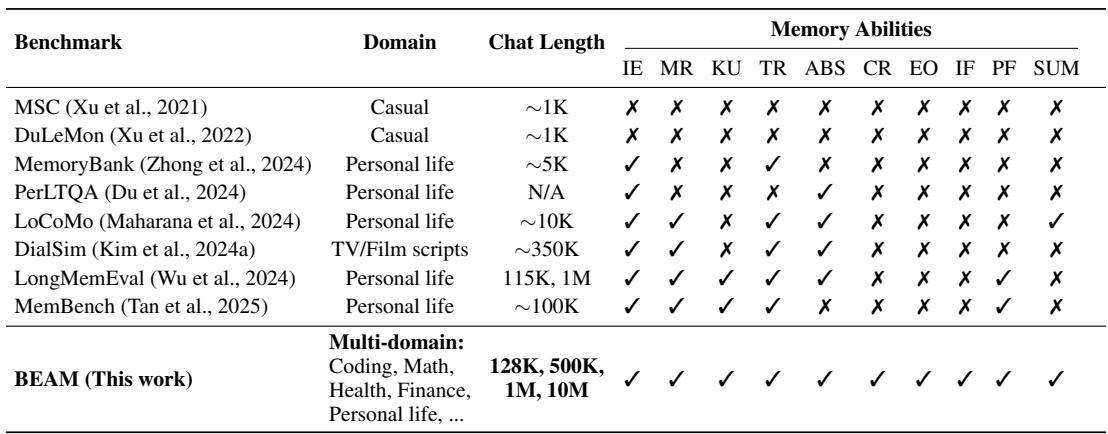
图: BEAM 与以往基准的比较——BEAM 覆盖多个领域,可扩展至 1000 万词元,并包含更广泛的记忆能力。
BEAM: 生成真实且超长的对话
BEAM 的核心是一个自动化、多阶段的数据生成流程,用以生成连贯多样的长对话,并自动生成针对特定记忆能力的探究性问题。
下图展示了流程概览。
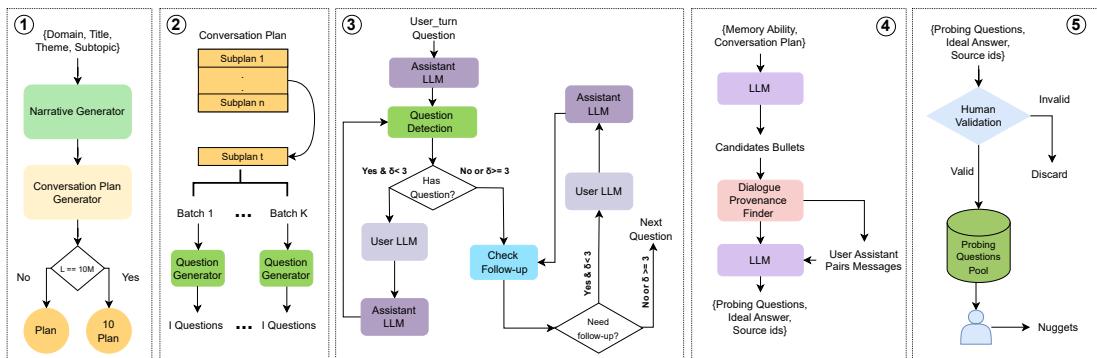
图 1: BEAM 数据生成流程。从叙事种子开始 → 对话计划 → 用户和助手轮次生成 (包含问题检测与追问模块) → 自动生成探究性问题 → 人工验证。
关键阶段如下:
对话计划 (骨架) : 每个对话都从一个详细计划开始,由模型根据种子生成,包括领域 (如“编程”“健康”) 、标题与主题、子主题、用户画像 (姓名、年龄、类似 MBTI 的特质) 、关系图及时间线。对于特别长的对话 (如 1000 万词元) ,框架会组合多个互相关联的计划 (如顺序扩展或分层分解) ,以便剧情自然演进。
用户轮次生成 : 每个子计划被分成若干批次以避免重复或跑题。每批次由模型生成与计划、时间线、先前批次和用户画像一致的用户提问。批次及问题数量根据领域和目标对话长度调节。
助手生成 (角色扮演) : 助手的回答通过角色扮演循环生成,一个模型扮演助手,另一个可扮演用户。系统包含问题检测模块,用于识别助手何时发问;追问检测模块,用于决定用户何时提出澄清。这样可以生成双向的真实互动,而非单向脚本化的问答流。
探究性问题合成与人工验证 : 在生成完整对话后,系统自动合成映射到十种记忆能力的候选探究问题 (信息提取、多跳推理、信息更新、时间推理、拒绝回答、矛盾解决、事件排序、指令遵循、偏好遵循、总结) 。人工标注人员验证并完善候选问题,并为评估制定基于小块信息的评分标准。
数据集摘要 : BEAM 共包含 100 个对话 (12.8 万至 1000 万词元不等) 和 2000 个经验证的探究性问题。人工评审者在连贯性、真实感和复杂性上对生成对话给出了高评分。
为何此生成过程重要 : 它产出的长对话能作为单一故事自然演进,包含来回澄清,并有意注入能测试复杂记忆能力的场景 (如被更新的事实、跨距较大的矛盾、长期偏好或指令) 。
LIGHT: 受认知科学启发的三重记忆架构
BEAM 定义了更好的评估目标,而 LIGHT 则是提升模型在这些目标上表现的策略。它借鉴人类记忆原理:
- 情景记忆 (Episodic Memory) : 类似索引的档案,用于有针对性地检索过往对话片段。
- 工作记忆 (Working Memory) : 最近轮次的对话内容,逐字保留,提供即时上下文。
- 草稿纸 (Scratchpad) : 一个不断迭代维护的高级笔记本,记录关键事实、偏好及时间线;定期语义压缩保持输入规模可控。
整体流程:
- 每轮对话后,提取器识别键值对与简短摘要,嵌入并存储至向量数据库 (情景索引) 。
- 草稿纸生成器在轮次间推理,生成摘要笔记 (其重要性、标准化日期、指令标志、偏好线索) 。当草稿纸累积过大,会被压缩为简洁语义概要。
- 推理时,给定问题 x:
- 通过密集检索获取 top-k 个相关情景片段 (E)。
- 提供最近 z 对对话作为工作记忆 (W)。
- 筛选与 x 相关的草稿纸片段,生成 S_x。
- 将 x + E + W + S_x 输入模型回答。
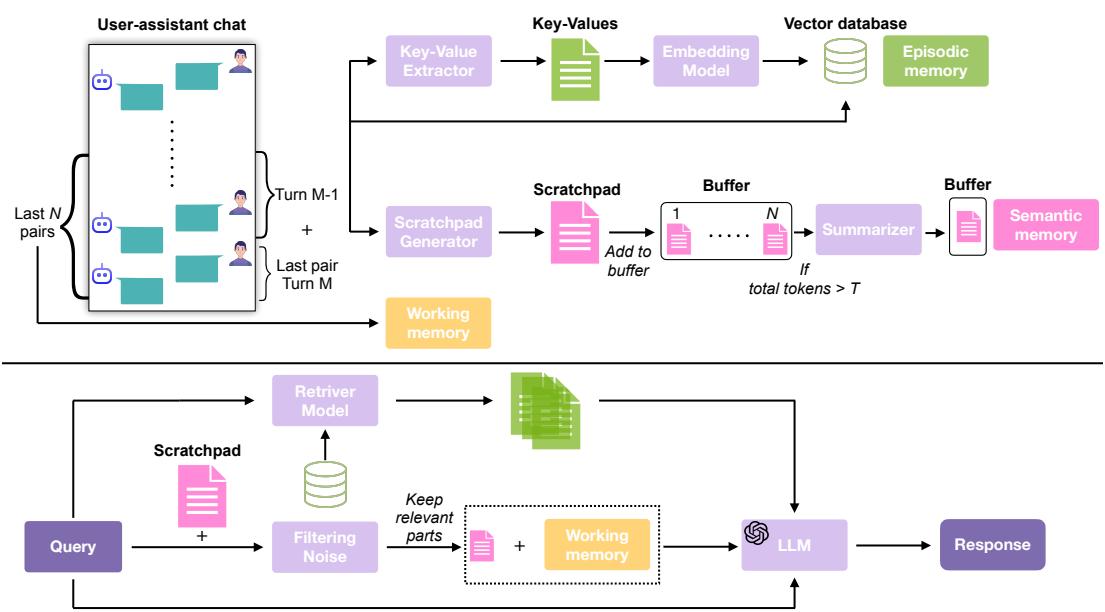
图 2: LIGHT 概览——三种互补的记忆存储,模型在回答探究性问题时共同参考。
设计要点与直觉:
- 情景检索提供精确依据 (如指向含答案段落) 。
- 工作记忆保障即时连贯 (最近澄清与对话状态) 。
- 草稿纸保持长跨度的语义事实与指令 (如“在预算问题上始终提供分项说明”) ,弥补原始长记录的脆弱性。
实践说明:
- 草稿纸不是检索数据库,而是经过语义分块和相关性过滤后直接作为上下文输入。
- 当草稿纸过大时,作者会语义摘要压缩,以保持系统高效与聚焦。
实验: 哪些方法有效,哪些仍有不足
论文将 LIGHT 与两种基线进行对比:
- 原生长上下文模型 : 在模型容量内直接输入全部历史。
- 标准 RAG 基线 : 检索 top-k 片段并与问题一起输入。
测试模型包括具有 100 万词元窗口的专有模型,以及多个开源 LLM。RAG 与 LIGHT 均采用实用检索上下文大小 (如 32K) 并使用 FAISS 构建索引。
主要结果 : 在不同聊天长度 (10 万–1000 万词元) 和记忆任务上,LIGHT 均显著优于两种基线。
亮点:
- 在 100 万词元时,LIGHT 相比原生基线最多提升 ~75.9%。
- 在 1000 万词元时 (基线无法原生处理完整历史) ,LIGHT 取得了显著增益 (部分模型相对提升超 100%) 。
- 在需整合分散信息的任务中提升尤为显著: 总结、多跳推理、偏好遵循。
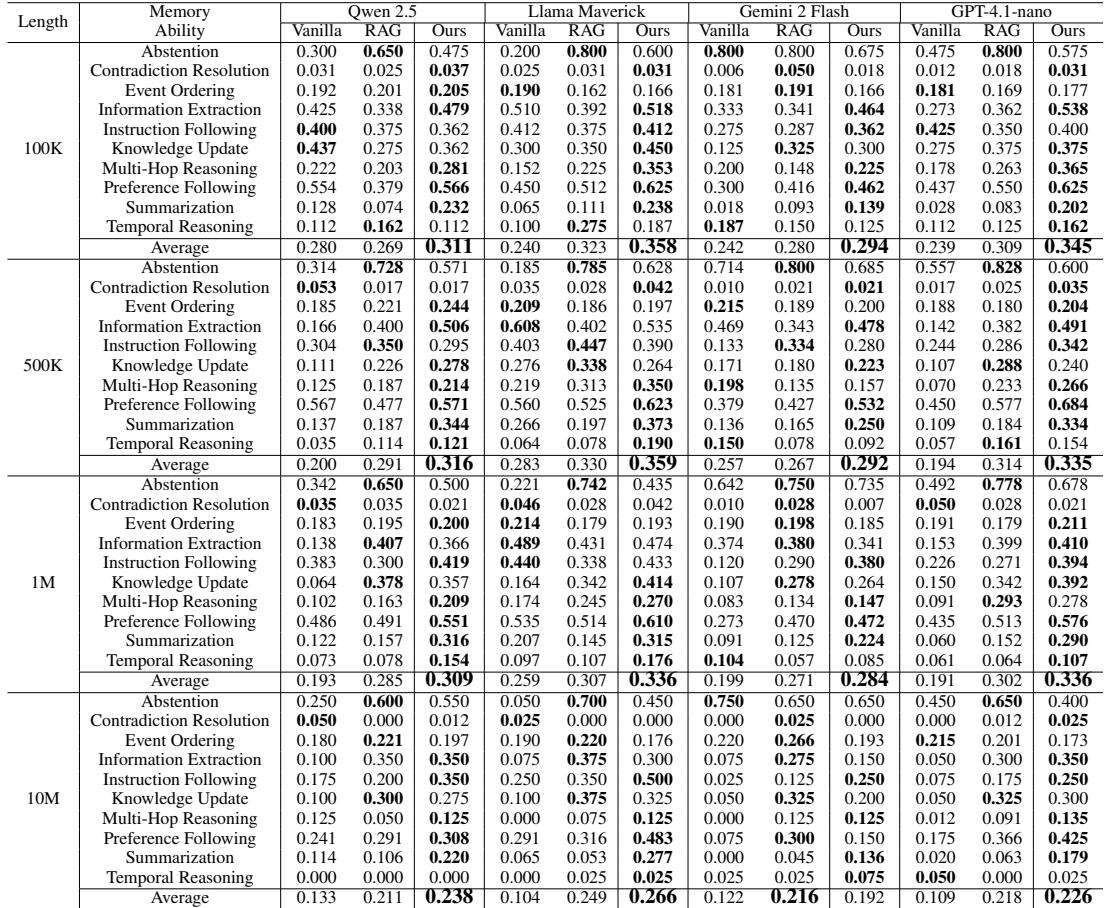
图: 总体性能比较——LIGHT (Ours) 在不同模型及长上下文中均优于 vanilla 和 RAG 基线。
消融实验与分析:
- 移除情景检索、草稿纸、工作记忆或草稿纸噪声过滤任一组件都会降低性能,且随着上下文增长影响加剧。在 1000 万词元时,移除情景检索或噪声过滤会造成显著性能下降。
- 检索预算 (k) : 从 k=5 增至 k=15 性能提升,但过度检索 (k=20) 反而增噪导致性能下降。
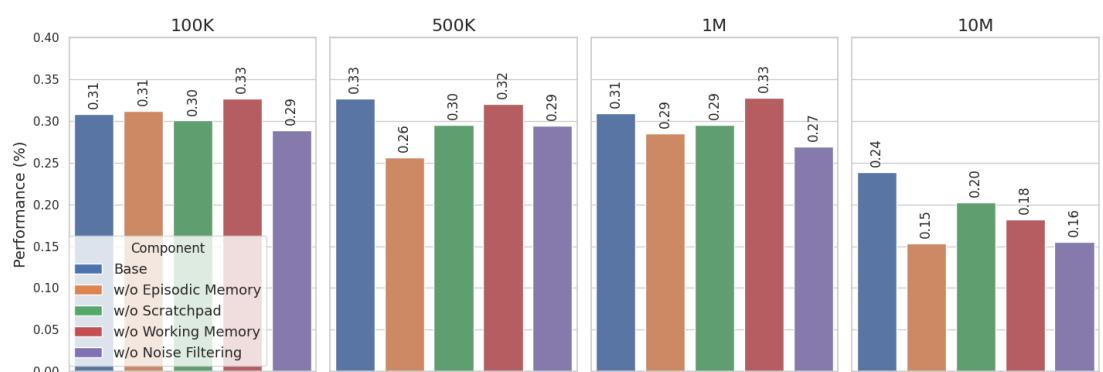
图 3: 消融结果。每个组件都至关重要,其重要性随对话长度增长而上升。
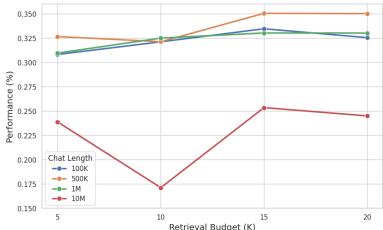
图 4: 检索预算 (K) 的影响。存在最佳点——既要覆盖远处证据,又不能让模型被噪声淹没。
更多实验洞察:
- 在较短的对话 (10 万词元) 中,仅用草稿纸有时足够,多余检索可能引入噪声;但随长度增加,检索变得至关重要。
- 矛盾解决仍是所有方法的难点——模型难以识别和调和远距回合中的矛盾陈述。
- 拒绝回答 (如回答“我不知道”) 通常表现良好;真正薄弱的是整合多证据的深度推理任务。
案例研究: 草稿纸为何有效
作者通过案例研究展示草稿纸如何增强四种能力:
- 信息提取 : 草稿纸整合分散提及的工具版本或用户属性,提升回忆精度。
- 指令遵循 : 草稿纸可存储用户的元指令 (如“讨论指导时总包含团队人数”) ,使助手在多轮后仍遵守。
- 知识更新 : 当事实在后期被修改 (如截止日期变更) ,草稿纸保留更新后的值,避免旧信息。
- 时间推理 : 草稿纸中标准化时间锚点增强日期差计算的准确性。
这些定性结论与消融实验一致: 草稿纸显著提升多项记忆任务的稳健性。
实践启示
- 光靠扩大上下文窗口不是答案。非结构化的长上下文常淹没关键信号,结构化的记忆系统 (检索、总结、过滤) 是让模型能跨超长对话推理的前提。
- 三种互补的记忆系统——情景检索供精准依据、工作记忆供即时连贯、草稿纸供关键事实与指令提炼——组合性能优于单一机制。
- 检索深度 (k) 存在最佳值: 太少漏证据,太多添噪声。调整至合适 k 至关重要。
- 部分记忆任务仍具挑战 (尤其是矛盾解决) ,值得进一步研究。
局限性与开放问题
论文在评估与方法上均有突破,但仍存在不足:
- 仍需人工验证以确保探究性问题质量——完全自动化且可靠生成仍是待解决问题。
- 数据为合成对话,尽管人评显示真实性高,但合成数据仍可能与真实多轮人类聊天存在差异。
- 矛盾检测与调和仍困难,模型难整合相互冲突的分散信息。
- 计算成本较高: 大型情景索引的维护与检索、草稿纸压缩管理均需工程优化以提高实用效率。
结语
BEAM 在衡量长对话记忆上迈出了关键一步: 评估连贯叙事、多领域复杂度以及超越回忆的多样记忆能力。LIGHT 则展示了让长上下文模型真正利用远距离信息的实用方法: 融合检索、短期上下文与迭代提炼的知识存储。
对于构建或评估长上下文系统的研发者,有两条经验尤为重要:
- 衡量正确的能力 : 测试应评估模型整合、更新与推理分布在不同时间与主题的信息的能力——而非仅测词元距离。
- 设计合适的记忆架构 : 采用互补的记忆机制,既可检索具体片段,又能保留近期讨论,并维护一份提炼的事实与指令笔记。
这些实用探索正指向能够真正成为多会话伙伴的助手: 不仅记得过去的对话,还记得发生的变化、用户的偏好,以及曾经给出的建议。