](https://deep-paper.org/en/paper/2510.27656/images/cover.png)
大语言模型 (LLMs) 正以惊人的速度演进。我们已经从单体模型发展到诸如 混合专家模型 (Mixture-of-Experts, MoE) (可高效扩展至万亿参数) 和 分离式推理 (disaggregated inference) (模型的不同执行阶段——预填充与解码——在专门的独立集群上运行) 等架构。这些新设计虽优雅,却暴露出当今机器学习基础设施中的一个关键短板: 通信 。
多年来,分布式训练和推理依赖于 集合通信 (collective communication) 库 (如 NVIDIA 的 NCCL 与 PyTorch Distributed) ,它们在同步操作 (如 AllReduce 和 Broadcast) 中表现卓越。这类操作非常适合传统的数据并行和张量并行工作负载,因为每个 GPU 都严格同步。然而,随着 MoE 路由和分离式推理等新型工作负载的出现,这种模式开始失效。这些任务具有 稀疏、动态、非均匀 的特征,需采用灵活的 点对点 (point-to-point) 通信,而非僵化的集合同步方式。
不幸的是,面向点对点通信的高性能工具——基于 远程直接内存访问 (Remote Direct Memory Access, RDMA) ——往往被绑定到特定硬件。某个在 NVIDIA ConnectX-7 网卡上表现优异的方案,可能在 AWS 的弹性光纤适配器 (Elastic Fabric Adapter, EFA) 上性能下降甚至完全失效。这种供应商锁定限制了跨云环境的可移植性与性能。
Perplexity AI 的研究团队通过 TransferEngine 成功应对了这一挑战——一个可移植的 RDMA 通信库,在异构硬件上提供统一的高速接口。本文将深入探讨 TransferEngine 的设计原理、它在 NVIDIA 与 AWS 硬件上取得的性能突破,以及它所支持的三大生产级系统:
- 分离式推理: 快速传输 KvCache,实现集群的弹性扩展。
- 强化学习 (RL) : 万亿参数模型在 1.3 秒内完成权重更新。
- 混合专家模型 (MoE) : 在 ConnectX-7 上实现最先进的解码延迟,并首次在 AWS EFA 上实现可行的 MoE 部署。
通信的分水岭: 集合通信 vs 点对点通信
RDMA 简述
现代高性能计算集群的核心是 远程直接内存访问 (RDMA) 。 RDMA 允许一台服务器的 NIC 直接读写另一台服务器的内存,绕过内核干预与 CPU 开销。通过这种内核旁路技术,可实现 亚微秒级延迟 和 高达 400 Gbps 的带宽 , 对扩展 LLM 系统至关重要。
RDMA 支持两类主要操作:
- 双边操作 (SEND/RECV) : 一种协调握手机制,接收方必须先发布
RECV缓冲区,发送方再执行SEND。 - 单边操作 (WRITE/READ) : 无需远程参与的直接访问——类似你拥有朋友家门的钥匙。
WRITEIMM在此基础上拓展,传递一个用于完成通知的 32 位“立即数”。
硬件碎片化问题
问题的关键在于: 不同 RDMA 实现的行为并不一致 。
- NVIDIA ConnectX: 采用 可靠连接 (Reliable Connection, RC) 传输方式——保持顺序且面向连接。
- AWS EFA: 使用 可扩展可靠数据报 (Scalable Reliable Datagram, SRD) ——可靠但无连接且 无序传输 。
许多 RDMA 库默认假设 RC 在严格顺序下运行。当部署到提供无序交付的 AWS EFA 上时,这类系统可能崩溃或严重降速。由此诞生了如 NVSHMEM 与 DeepEP 等高速却受限于硬件的碎片化解决方案。
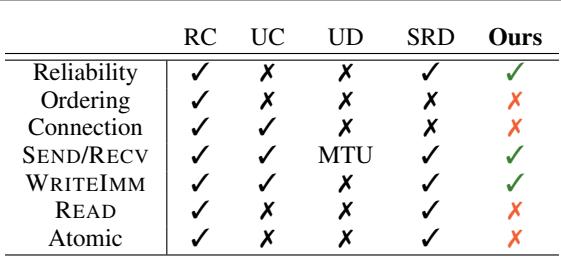
图: RDMA 传输类型对比图,展示可靠但无序的交付是跨网卡的共同基础。
作者的关键洞察是: ConnectX 与 EFA 都支持可靠传输,即便无序。 基于这一共同点,TransferEngine 在两个生态系统间实现了高性能通信。
TransferEngine: 可移植的 RDMA 抽象层
抽象而不妥协
TransferEngine 在两个截然不同的软件栈——libibverbs (用于 ConnectX) 与 libfabric (用于 EFA) ——之上提供统一接口。它暴露出简洁的 API,用于灵活的点对点数据交互: 为 RPC 风格消息提供可移植的 SEND/RECV 操作,为大批量传输提供高带宽的单边 WRITE 操作。
核心创新在于 它如何在无序网络环境中管理完成通知 (completion) 。 当上百个并行传输同时进行时,传统依赖顺序的跟踪会失效。TransferEngine 引入了新的原语: IMMCOUNTER 。
IMMCOUNTER: 无需排序的完成机制
原理如下:
- 每个 RDMA
WRITEIMM操作携带一个 32 位立即数。 - 接收方在传输完成时,通过 NIC 完成队列的原子更新,增加一个与该值关联的 IMMCOUNTER 。
- 应用程序只需等待计数器达到目标值 (例如 100) ,即可判断传输已全部完成。
这一机制巧妙绕过顺序依赖问题,确保无论传输顺序如何,都可精确确认完成,从而在无序 (EFA) 与有序 (RC) 传输中均表现一致。
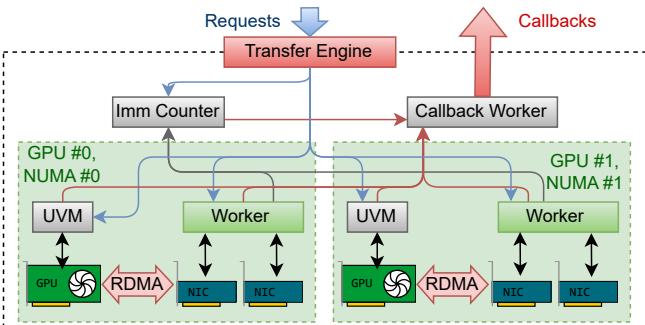
图 1. TransferEngine 跨 NUMA 节点的架构概览。
TransferEngine 为每个 GPU 创建一个工作线程并将其固定在本地 CPU 核心上。每个线程负责协调该 GPU 下所有 RDMA NIC——对需要多网卡聚合的 EFA 配置至关重要。引擎在后台透明管理这些细节,即便在云环境中也能维持接近 400 Gbps 的性能。
API 概览
以下为论文中类 Rust 风格 API 的简化示例:
| |
其中一个特别强大的机制是 UVM Watcher 。 它将 CPU 端的 RDMA 逻辑与 GPU 核函数进度关联。当 GPU 核函数准备好数据时,会写入一个统一虚拟内存 (Unified Virtual Memory) 地址,低延迟 CPU 线程通过 GDRCopy 监控此地址变化,触发相应 RDMA 操作——完美协调 GPU 计算与网络传输。
TransferEngine 的实际部署
TransferEngine 不仅仅是理论产物——它已在多种真实生产系统中发挥关键作用。
1. 分离式推理: KvCache 集群间传输
在推理中, 预填充阶段 (处理上下文) 与 解码阶段 (生成 token) 被拆分到不同集群以提升效率。瓶颈在于两者间传输庞大的键值 (KV) 缓存。
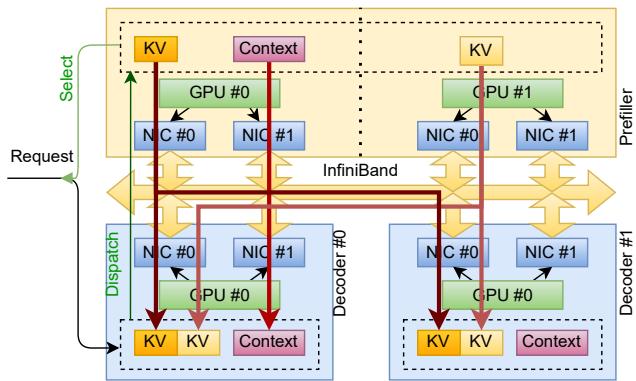
图 3. 分离式推理中预填充节点与解码节点间的 KV 缓存传输。
工作流程:
- 调度器分配预填充节点与解码节点。
- 解码节点预分配内存,并将其 RDMA 内存映射 (
MrDesc) 发送给预填充节点。 - GPU 每层完成 KV 缓存后,CUDA 核函数更新
UVM Watcher。 - TransferEngine 检测变化并触发分页 RDMA WRITE 向解码节点发送数据。
- 解码节点通过
expect_imm_count监控完成进度,KV 缓存就绪后立即开始解码生成 token。
该方法使预填充与解码集群可独立扩展,无需同步重初始化——传统集体通信框架无法实现这一点。
2. 强化学习: 万亿参数模型的极速更新
在强化学习微调过程中,训练 GPU 上的最新权重必须迅速推送到推理 GPU。传统框架往往通过单“Rank 0”节点中转,造成 NIC 带宽瓶颈。
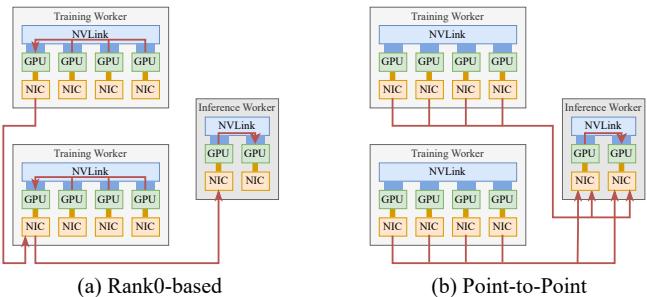
图 4. 基于 Rank0 的集合通信与直接点对点传输的架构对比。
借助 TransferEngine,每个训练 GPU 通过单边 RDMA 操作 直接写入 相应的推理 GPU,实现多 NIC 流量均衡。
团队引入 多阶段流水线 , 以重叠计算与传输过程:
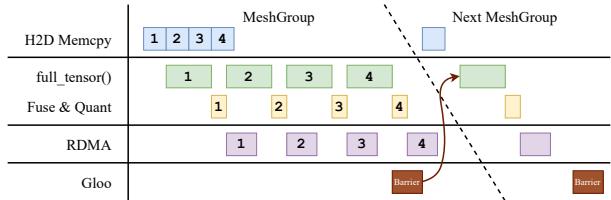
图 5. 流水线化权重传输执行流程。
结果令人惊叹——针对万亿参数模型 (如 DeepSeek-V3、Qwen3 与 Kimi-K2) , 权重更新耗时仅 1.3 秒 , 相比传统 RL 框架提速逾 100 倍 。
3. 混合专家模型: 可移植、低延迟的分发与聚合
MoE 架构在多个“专家” GPU 之间动态路由 token,通信开销对延迟极其敏感。

图 6. MoE 分发/聚合阶段的 GPU–CPU–NIC 协调机制。
TransferEngine 提供基于代理的核函数用于分发与聚合,同时支持 ConnectX 与 AWS EFA——开启了可移植专家路由的先例。代理线程利用 GDRCopy 轮询 GPU 状态,并通过 IMMCOUNTER 接口执行 RDMA 传输。
系统采用 两阶段分发 以降低延迟: 先在交换路由元数据时执行到小型私有缓冲区的推测性传输,随后进行到连续缓冲区的大规模数据分散。
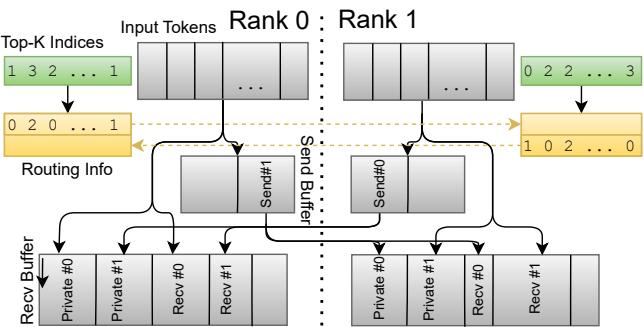
图 7. 两阶段分发: 先入私有缓冲区,再入连续缓冲区。
结果显示: 在 ConnectX 上实现了 领先的解码延迟 , 并在 EFA 上实现首个可行的 MoE 部署——突破长期硬件限制。
性能评估
吞吐量基准测试
TransferEngine 在 ConnectX 与 EFA 上均达到接近硬件峰值的性能。
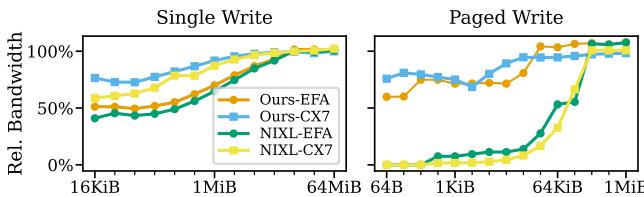
图 8. 点对点带宽对比。
对于典型负载 (KV 页大小 64 KiB,MoE 传输大小 256 KiB) ,TransferEngine 能充分利用两种网卡带宽。小消息尺寸下的性能差异主要由硬件配置决定,而非库设计。
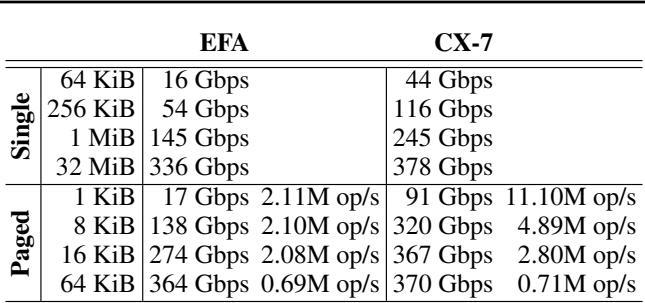
表 2. EFA 与 ConnectX-7 性能对比。
MoE 解码延迟
解码阶段检验系统在高耦合跨节点分发/聚合操作中的效率。
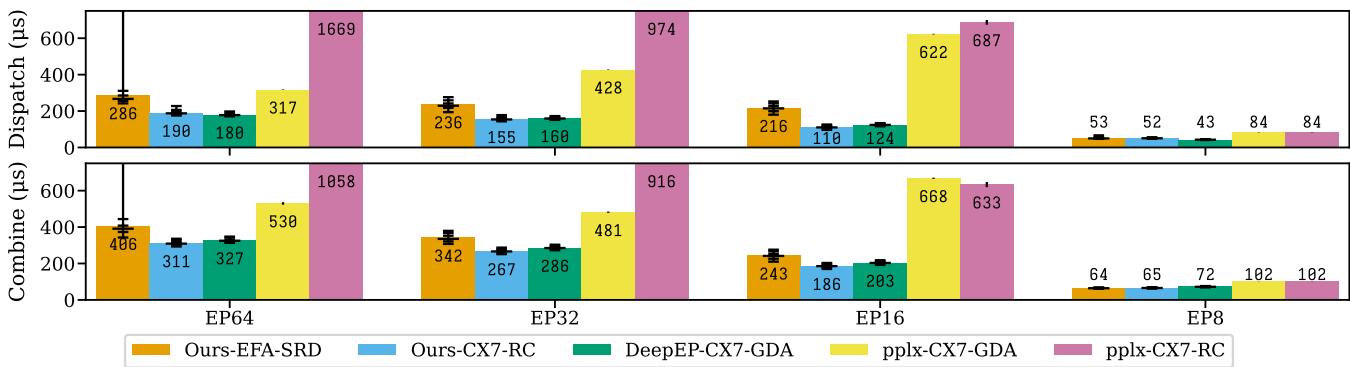
图 11. ConnectX 与 EFA 部署下的 MoE 解码延迟。
亮点:
- 在 ConnectX-7 上,TransferEngine 超越了 DeepEP 的专用 GPU 发起设计。
- 在 AWS EFA 上,它首次实现可行的低延迟 MoE 路由,仅比 ConnectX 慢约 30%。
证明主机代理方案可与 GPU-direct RDMA 相媲美甚至超越。
MoE 预填充性能
大型批量预填充任务更强调带宽利用率。

图 12. 预填充延迟对比。
此处,DeepEP 通过发送端累积略占优势,但 TransferEngine 在无硬件特定优化下依然保持稳定表现——展示出在不同 NIC 行为下的强健适应性。
结论: 为大语言模型时代打造可移植的 RDMA
随着 LLM 架构日益动态,纯集合通信的局限愈加明显。未来系统亟需灵活高速的点对点数据传输机制——且不依赖特定硬件。
TransferEngine 正好实现这一愿景。依托 ConnectX 与 EFA 共同的“可靠但无序”传输基础,并引入创新的 IMMCOUNTER 原语以实现跨平台完成通知,它消除了云硬件壁垒,同时保持顶级性能。
在分离式推理、强化学习与混合专家模型等工作负载中,TransferEngine 支撑生产级系统兼具灵活与高速,在多硬件平台上实现超过 400 Gbps 吞吐量与创纪录延迟。
结论简单明了: 可移植的点对点通信不仅可行,而且必不可少。 TransferEngine 让它成为现实,开创了云原生大语言模型基础设施的新时代——摆脱供应商锁定,迈向无限可扩展性。